DeepSeek v4:全貌解読 – 特徴、リリース日、Atlas Cloudでの利用方法
はじめに:DeepSeek v4とは?
Atlas Cloudは、生成AIポートフォリオを拡充し、新たにDeepSeek v4を追加します。
- DeepSeek v4とは: DeepSeekチームが贈る最新のフラッグシップモデルです。DeepSeek v3.2がコスト効率の高いオープンソース・コーディングモデルの基準を打ち立てたのに対し、v4は独自の**Manifold-Constrained Hyper-Connections (mHC)技術とEngram Memory(エングラムメモリ)**技術を採用することで、論理推論とメモリの境界を押し広げました。
- 主なメリット: 単なるコード生成にとどまらず、シニアアーキテクトのようにリポジトリ構造全体を把握し、ファイル横断的な推論や複雑なバグ修正を行うことができます。
- ステータス: 近日リリース予定(2026年2月中旬予定 — DeepSeek V4の展望に関する詳細記事をご覧ください)。
DeepSeek v4が業界を変革すると確信している理由は、「AIがプロジェクトの論理構造を記憶・理解する必要がある」という業界最大の課題を解決したからです。
📣 更新 — 2026年4月24日: DeepSeek-V4が正式にローンチされました。新しいスパースアテンション(Sparse Attention)アーキテクチャ、1Mトークンのコンテキスト、Agentベンチマーク結果を含む全容については、DeepSeek-V4 プレビューローンチをご覧ください。
技術解説:主な機能
Claude Opus 4.5に対抗するため、DeepSeekはモデルを根本から再構築しました。公開された論文によると、メモリ管理と論理的安定性の処理において抜本的な変化が見られます。今回のアップデートの4つの柱を解説します。
アーキテクチャ:優れた論理推論
-
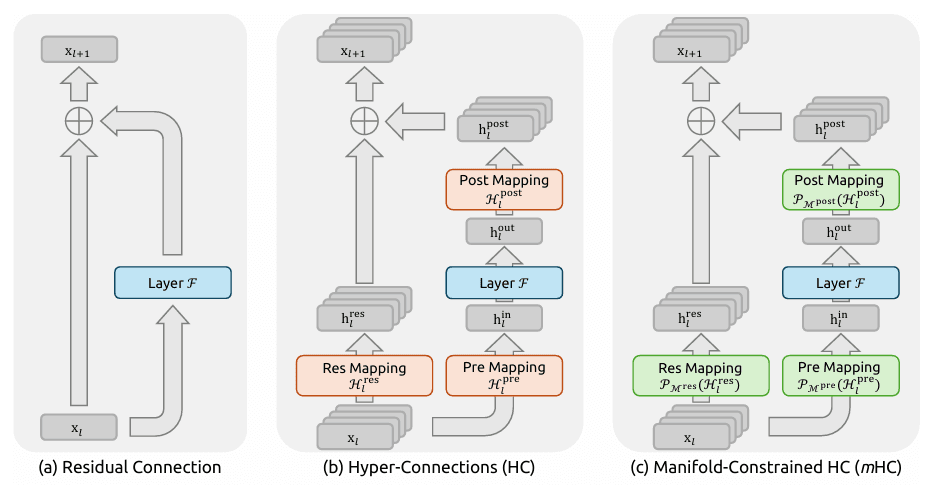
Manifold-Constrained Hyper-Connections (mHC)
- コンセプト: AIの脳にとっての「論理的スーパーハイウェイ」のような役割を果たす、新しい「ニューラル配線」手法です。
- 結果: 数千行におよぶコードのリファクタリングなど、複雑な論理を扱う際、学習効率が向上し、論理的整合性が高まります。これにより、長いコンテキスト生成で発生しがちな「論理ハルシネーション」や不整合を排除します。
効率性:推論コストの削減
-
Mixture-of-Experts (MoE) 2.0
- コンセプト: 数千億のパラメータを持つ巨大モデルでありながら、最適化されたMoEアーキテクチャを採用し、各トークンに対して最も関連性の高い「専門家(エキスパート)」のみをアクティブ化します。
- 結果: 「高い性能(巨大な知識ベース)」と「効率的なスケーリング(軽量モデルのような動作)」の完璧なバランスを実現しています。
-
スパースアテンション (Sparse Attention)
- コンセプト: すべてのテキストを力技でスキャンするのではなく、重要な情報のみをインテリジェントに抽出します。これにより、計算コストを大幅に削減し、長大なコンテキスト処理を高速化します。
メモリ:インテリジェントなコンテキスト管理
-
Engram Memory(選択的保存と想起)
- コンセプト: 単なる丸暗記ではなく「理解」に焦点を当てます。プロジェクト構造を認識し、命名規則(snake_case対camelCaseなど)に従い、チーム特有の設計パターンを学習します。
- 結果: 熟練したエンジニアのようにコーディングを行います。
-
Multi-Head Latent Attention (MLA)
- コンセプト: 情報の「超速記法」といえます。他のモデルが情報を保持するために100トークン必要な場合でも、MLAは10個の主要シンボルに圧縮します。
- 結果: 想起が必要な際には、数学的に元の意味を損失なく再構築します。これにより、VRAM使用量を大幅に抑えつつ、驚異的な詳細保持力を実現します。
アプリケーション:現場でのエンジニアリング
- リポジトリレベルの理解とバグ修正
- 目標はコードを書くだけでなく、コードベース全体を制御することです。SWE-benchテストにおいて、DeepSeek v4はファイル間の依存関係を理解することで、複雑な現実的課題の80.9%以上を解決することを目指しています。
ユースケース:コスト削減と効率化
DeepSeek v4は本格的なエンジニアリングのために構築されました。競合モデルとの比較は以下の通りです。
レガシーコードのリファクタリング
ドキュメント化されていない複雑なレガシーシステムにおいて、mHCアーキテクチャは強力なツールとなります。遠隔的な論理依存関係を追跡し、安全なリファクタリングを支援します。
- 対 GPT-4o: GPT-4oはコンテキストが10kトークンを超えると「論理ハルシネーション(存在しない関数呼び出しの生成)」を起こすことがありますが、DeepSeek v4は長いコンテキスト全体で論理的整合性を100%維持します。
- 対 Claude 3.5 Sonnet: Sonnetは高品質ですが、大規模なリファクタリング作業では低速かつ高コストです。DeepSeek v4のMoEアーキテクチャは、Atlas Cloud上で約40%高速な推論速度と低コストを提供します。
リポジトリ単位の機能開発
成熟したプロジェクトに新しいAPIを追加する際、v4は「Engram Memory」を使用してコンテキストを瞬時に把握します。
- 対 従来のオートコンプリート: 標準ツールはプロジェクト特有のルールを無視しがちですが、DeepSeek v4は既存のコードベースを完璧に模倣し、まるで優秀な開発者が書いたかのようなコードを生成します。
フルリンクのバグトラッキング
SWE-benchでの80.9%の成功率という目標は、フロントエンド、バックエンド、データベースにまたがるバグの解決を意味します。
- 対 Claude Opus 4.5(予定): Opus 4.5は強力ですが高額になる見込みです。DeepSeek v4は、予算を圧迫することなく反復的な「リフレクション(熟考)と修正」のループを可能にする価格で、SOTA(最先端)に近いパフォーマンスを提供します。
📉 まとめ:チームにもたらすROI
スタートアップや開発チームにとって、DeepSeek v4とAtlas Cloudの組み合わせは明確なROIをもたらします。
- 生産性: シニア開発者のコーディング時間を30〜50%削減。
- コスト: 2基のRTX 4090サーバーをレンタルしたり、クローズドソースのAPIに支払う費用と比較して、Atlas Cloudの統合APIは総合的なコンピューティングコストを60%以上削減可能です。
ハードウェアの現実:ローカルホスティングの落とし穴
「コーディングの神」を自分のPCで動かしたいと思うかもしれませんが、現実を直視する必要があります。パフォーマンスには代償が伴います。
- 最低条件:RTX 4090 × 2基
- 現実:市場で最も高価なGPUを2基購入し、接続する必要があります。GPU代だけでiPhone 17 Pro Max 3台分(または程度が良い中古車1台分)に相当します。
- 推奨:RTX 5090 × 1基(2026年フラッグシップ)
- 現実:GPU界の「フェラーリ」です。価格が高騰するだけでなく、入手も困難です。
GPU価格が高止まりする中、たった1つのモデルを動かすために数千ドルを費やし、ファンノイズや排熱、複雑な環境構築に悩まされる価値があるでしょうか?
スマートな解決策:Atlas CloudでDay 0から利用
DeepSeek v4を使うために金持ちである必要はありません。賢くあればいいのです。価値が下がる「電子ゴミ」を買うのではなく、クラウドを選びましょう。
Atlas Cloudはローンチの準備ができています:
-
私たちの約束: 休日を楽しんでください。デプロイの面倒な作業は私たちにお任せください。公式リリースチャンネルを24時間365日監視しています。
-
主な利点:
- 即時アクセス: オープンソースウェイトが公開され次第、API統合がライブになります。
- 障壁ゼロ: 高価なハードウェアやCUDAの地獄のような依存関係は不要です。プロンプトを用意するだけです。
- 妥協のない体験: 完全なコンテキストサポートを提供し、「Engram」メモリ機能が量子化による損失なく100%の能力を発揮できるようにします。
Atlas Cloudでの利用方法
Atlas Cloudでは、モデルを並べて使用したり(プレイグラウンド)、単一のAPI経由で利用したりできます。
方法1:Atlas Cloudプレイグラウンドで直接利用する
方法2:API経由でアクセスする
ステップ1:APIキーを取得する
コンソールでAPIキーを作成し、コピーします。
ステップ2:APIドキュメントを確認する
APIドキュメントで、エンドポイント、リクエストパラメータ、認証方法を確認します。
ステップ3:最初のリクエストを送る(Pythonの例)
例:DeepSeek v3.2を使用したリクエスト
python1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "deepseek-ai/deepseek-v3.2", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "what is difference between http and https" 14 } 15 ], 16 "max_tokens": 32768, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())






