プロンプトが拒否された場合、それは有害だからではなく、キーワードがフィルターに触れたためです。
Ollamaコミュニティの開発者は、これを「拒否ベクトル(refusal vectors)」と呼んでいます。これは、実際の害とは無関係にキーワードによってブロックされる現象です。セキュリティ研究のためのマルウェアのリバースエンジニアリング、医療症例研究のドキュメント作成、アダルトコンテンツの制作、ダークフィクションの執筆など、主流のAIはこれらすべてをブロックします。本記事では、マーケティングコピーではなく、実際のコミュニティデータに基づき、2026年現在の最高のアンセンサード(検閲なし)AIモデルをランキング形式で紹介します。内容は、テキストおよびコード向けのアンセンサードLLMモデル、プライベートなハードウェア環境にデプロイ可能な最高のアンセンサードローカルAIモデル、そしてAPI経由で画像・動画生成が可能なアンセンサードAIモデルの3つのカテゴリーをカバーしています。すべての数値は2026年5月時点のデータに基づいています。
より広範なツール群の概要については、この分野の初心者向けに、特定のモデルを選択する前の足がかりとなるアンセンサードAI画像生成ガイドが役立ちます。
2026年最高のアンセンサードAIモデルのランキング方法
2026年現在、Ollamaからのコミュニティダウンロード数は、プレスリリース用に選別されたベンチマークスコアよりも、実世界でのパフォーマンスを示す信頼性の高い指標となっています(Ollama, uncensored model search, 2026)。数百万回のプル(ダウンロード)は、何千ものハードウェア構成や多様なプロンプトタイプを反映しており、操作されやすい評価セットよりも信頼性が高いと言えます。
本記事では3つのランキング指標を使用しています。Ollamaのアンセンサードモデルについては、2026年5月時点のollama.comからのプル回数を主な指標としています。OpenRouterモデルについては、プル回数が公開されていないため、パラメータ数とコンテキストウィンドウを基準にランク付けしています。画像・動画モデルについては、出力あたりのコストを基準とし、グループ内で低コストな順に掲載しています。
ほとんどの2026年版アンセンサードAIモデルは、「ファインチューニング」と「アブリテレーション(Abliteration)」という2つの技術カテゴリーに分類されます。Dolphinシリーズのようなファインチューニングモデルは、拒否行動を強化しないデータセットで学習されています。一方、アブリテレーションモデルは、拒否のための重みを外科的に除去したものです。コミュニティでは、多様なプロンプトタイプに対してファインチューニングモデルの方が安定しているという評価が定着しています。
実際、ダウンロード数はモデルの安定性とも相関しています。100万回以上のプルを記録したモデルは、広範なハードウェア構成でテストされており、小規模なテストグループでは見過ごされるようなバグや不安定さが解消されています。
Ollamaで最もダウンロードされているアンセンサードモデル・トップ5
2026年、Ollamaのアンセンサードモデル・トップ5の総ダウンロード数は920万回を超え、llama2-uncensoredが260万回で首位となっています(Ollama, uncensored model search, 2026)。これらはベンチマークではなく、コミュニティの検証によって選ばれた2026年最高のアンセンサードOllamaモデルです。ユーザーが最初に適用するフィルターはハードウェアであり、VRAM要件は4GB未満から40GBまで多岐にわたります。
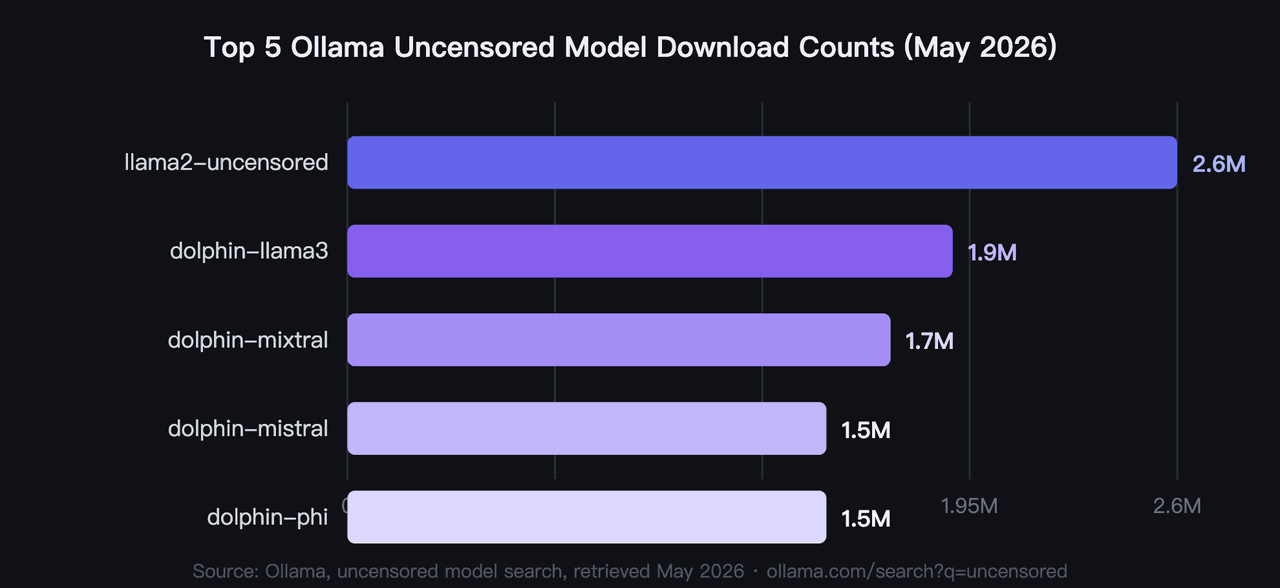
1. llama2-uncensored: Ollamaで最もダウンロードされたアンセンサードAIモデル
アンセンサードローカルAIにおけるコミュニティの原点となるベンチマークです。George Sung氏とJarrad Hope氏が、Llama 2の一般的な能力を損なうことなく拒否行動のみを除去するためにリリースしたファインチューンモデルです。多くの開発者が最初に触れるモデルであり、260万回というプル回数は2年以上にわたる実運用の実績を反映しています。このダウンロード数に並ぶアンセンサードLLMは他にありません。
- パラメータ数: 7Bまたは70B
- VRAM: 約6GB (7B); 約40GB (70B)
- 用途: 汎用的な制限のないチャットおよびコンテンツ生成
- プラットフォーム: Ollama
2. dolphin-llama3: エージェントワークフローに最適なアンセンサードLlama 3 LLM
Eric Hartford氏によるLlama 3ベースのDolphinは、現代的なアーキテクチャ上で構築された最もダウンロードされているアンセンサードモデルで、190万回のプルを記録しています(Ollama, dolphin-llama3 model page, 2026)。関数呼び出し(Function calling)をサポートし、設定に応じて8Kから256Kトークンまでのコンテキストウィンドウに対応します。8Bモデルは4.7GBと軽量で、一般的なミッドレンジGPUで動作します。
- パラメータ数: 8Bまたは70B
- VRAM: 約5GB (8B); 約40GB (70B)
- 用途: コーディング、エージェントワークフロー、関数呼び出し
- プラットフォーム: Ollama
3. dolphin-mixtral 8x7B: 複雑な推論に適したアンセンサードMoE AIモデル
Mixture-of-Experts(混合エキスパート)アーキテクチャを採用し、各トークンを8つのエキスパート層の一部で処理します。これにより、同等パラメータ数の密なモデルよりも低い推論コストで、70Bクラスに近い推論品質を実現しています。Eric Hartford氏によるアンセンサードなファインチューニングが施されており、強力なコーディング能力を維持しています。
- パラメータ数: 8x7B(推論時のアクティブパラメータ数は総数より大幅に少ない)
- VRAM: 量子化により約12〜16GB
- 用途: 複雑なコーディングタスク、技術的推論、長い指示連鎖
- プラットフォーム: Ollama
4. dolphin-mistral: 高速レスポンスを実現するアンセンサード7BローカルAIモデル
CPU制約のあるハードウェアでもdolphin-mixtralより軽量で高速に動作します。ハイエンドGPUを必要とせずにコード補完のための応答性の高いローカルモデルを求める開発者から、150万回のプルを得ています。Mistralベースのアーキテクチャにより、7Bモデルとしては非常に高い性能対サイズ比を実現しています。
- パラメータ数: 7B
- VRAM: 約5〜6GB
- 用途: 軽量なコーディング支援、高速なチャット応答
- プラットフォーム: Ollama
5. dolphin-phi 2.7B: 最軽量のアンセンサードローカルAIモデル
MicrosoftのPhiベースアーキテクチャを採用し、2.7Bというパラメータ数の中に高い推論能力を凝縮しています。Eric Hartford氏のファインチューニングにより、その効率性が維持されています。VRAM 4GB未満で動作するため、ディスクリートGPUを搭載したほとんどのコンシューマー向けノートPCで利用可能です。2026年最高のアンセンサードローカルAIへの入り口となるモデルです。
- パラメータ数: 2.7B
- VRAM: 4GB未満
- 用途: ノートPCでの運用、迅速なテスト、ハードウェア制約環境
- プラットフォーム: Ollama
アンセンサードLLMモデル 6〜10位:コーディング、ロールプレイ、長文コンテキスト
2026年現在、OllamaのアンセンサードカタログにおいてDolphinシリーズが上位10位中5つを占めています。これは、Eric Hartford氏が一貫した手法を多様なベースアーキテクチャに適用していることの証です(Ollama, hermes3 model page, 2026)。6位から10位のモデルは、ロールプレイ、一般的な会話、開発者ツール、指示追従、拡張コンテキストなど、メインストリームAIの拒否行動が最も障害となる領域をカバーしています。
6. hermes3: ロールプレイとエージェントタスク向けのアンセンサードAIモデル
Nous Researchがロールプレイの深みと構造化されたツール利用を目的に開発しました。3Bから405Bまで4つのサイズが提供されており、本リストで最も幅広い選択肢があります。8Bバージョンは130万回のプルを記録しており、クリエイティブな執筆やエージェントタスク計画に非常に実用的なモデルです(Ollama, hermes3 model page, 2026)。
- パラメータ数: 3B, 8B, 70B, または 405B
- VRAM: 約2GB (3B); 約5GB (8B); 約40GB (70B)
- 用途: ロールプレイ、創作小説、エージェントタスク計画
- プラットフォーム: Ollama
7. wizard-vicuna-uncensored: 汎用向けマルチサイズ・アンセンサードAIモデル
Llama 2ベースの古くからある実績あるモデルで、最大30Bまでの3サイズ展開です。120万回のプルは、より幅広いパラメータ範囲で信頼できるアンセンサードオプションを求めるユーザーによるものです。dolphin-llama3のようなコンテキストウィンドウ機能はありませんが、一般的な会話やクリエイティブなコンテンツ作成において安定しています。
- パラメータ数: 7B, 13B, または 30B
- VRAM: 約5GB (7B); 約9GB (13B); 約20GB (30B)
- 用途: 汎用的な会話および複数のサイズオプションでのコンテンツ生成
- プラットフォーム: Ollama
8. dolphincoder: StarCoder2ベースのアンセンサードAIコーディングモデル
StarCoder2をベースに採用した、純粋なプログラミング特化モデルです。他のDolphinモデルがアンセンサードファインチューニングされた汎用モデルであるのに対し、本モデルはソフトウェア開発をターゲットとしています。94.3万回のプルは、クリエイティブユーザーではなく開発者によるものがほとんどです。15Bバージョンは、7Bよりも大規模なコードベースを扱うことができます。
- パラメータ数: 7B または 15B
- VRAM: 約5GB (7B); 約10GB (15B)
- 用途: コード生成、デバッグ、技術ドキュメント作成
- プラットフォーム: Ollama
9. wizardlm-uncensored: 研究ワークフロー向け指示追従型LLM
61万回のプルを誇る13Bの指示追従モデルです。強みは、ヘッジング(曖昧な回答)やサブタスクの拒否をすることなく、複雑なマルチステップの指示に従う点です。一つの拒否が長いチェーンを中断させてしまう研究ワークフローにおいて、その信頼性は直接的な生産性につながります。最新のアーキテクチャではありませんが、指示追従のタスクを確実に遂行します。
- パラメータ数: 13B
- VRAM: 約9GB
- 用途: 複雑なマルチステップ指示連鎖および研究ワークフロー
- プラットフォーム: Ollama
10. everythinglm: 16Kコンテキストウィンドウを備えたアンセンサードLLM
最大の特長は、Llama 2ベースでありながら16Kのコンテキストウィンドウを備えている点です。ほとんどの7Bモデルが4Kまたは8Kトークンに制限される中、この広大なコンテキストにより、コードベース全体や長いドキュメント、拡張された会話履歴を切り捨てずに処理できます。53.6万回のプルは本リストの中では控えめですが、このサイズで他のモデルがカバーできない領域を埋めています。
- パラメータ数: 13B
- VRAM: 約9GB
- 用途: 長文ドキュメント分析、拡張コンテキストチャット、コードベース全体レビュー
- プラットフォーム: Ollama
DolphinシリーズがOllamaのダウンロード数で圧倒的なのは、単一の作者による一貫したファインチューニング手法が、一過性のアブリテレーションの試みを上回るというコミュニティで立証された事実を反映しています。アブリテレーションは単一モデルから拒否の重みを削除しますが、ファインチューニングは多様なプロンプトタイプに対して安定したアンセンサード行動を定着させます。この一貫性こそが、トップ10の半分をEric Hartford氏のモデルが占める理由です。
Ollamaのアンセンサードモデルをローカルにセットアップする方法
2026年現在、Mac, Linux, WindowsでのOllamaインストールは3つのコマンドで完了します。ollama.comからOllamaをインストールし、ollama pull [モデル名]でダウンロードし、ollama run [モデル名]で実行するだけです(Ollama documentation, 2026)。APIキーは不要で、外部のコンテンツモデレーションも一切適用されません。プロンプトがハードウェアから外に出ることはありません。
例えばdolphin-llama3の場合、ollama pull dolphin-llama3で4.7GBの8Bファイルをダウンロードし、ollama run dolphin-llama3でインタラクティブなプロンプトが開きます。推論処理のすべてがローカルのGPUまたはCPU上で行われます。
ターミナル操作を好まないユーザーには、デスクトップGUIであるLM Studioがおすすめです。Ollamaと同じGGUFモデルファイルを使用しており、モデル選択やパラメータ調整を視覚的に行えます。両ツールのエンジンであるllama.cppは、量子化レベルやコンテキスト長の設定を細かく制御したい場合に直接コマンドラインから使用可能です。
コンシューマー向けGPUで最高のアンセンサードローカルAIモデルを動かすための具体的なハードウェア要件や量子化設定については、完全なローカルセットアップガイドで最小VRAM構成や設定エラーの詳細を網羅しています。
ローカルGPUがない場合に使えるOpenRouterのアンセンサードモデル
2026年現在、OpenRouterはAPI経由でアンセンサードLLMを提供しており、GPUの必要性を完全になくしています。venice/uncensoredモデルは無料層で提供されており、入力・出力トークンあたり0ドルです(OpenRouter, venice/uncensored model page, 2026)。これにより、専用ハードウェアを持たないユーザーにとってもアンセンサードモデルの利用が現実的になっています。
トレードオフはシンプルで、OpenRouterのインフラストラクチャを経由するため、ローカルモデルのようなプライバシーは保証されません。どちらのアプローチが優れているかは、ユーザーの脅威モデルとハードウェアの可用性次第です。
11. venice/uncensored: 無料のアンセンサードOpenRouterモデル
OpenRouterの無料層で提供されるVenice Uncensoredモデルです。24BのMistral-Smallをベースに、Cognitive ComputationsがVenice.aiと協力してアンセンサード出力用にファインチューニングしたものです。32Kのコンテキストウィンドウを備え、トークン費用は無料です。OpenRouterの無料層には、プラットフォーム全体で1日あたり200リクエストという制限が適用されます。
- パラメータ数: 24B
- VRAM: 不要(クラウドホスト)
- 用途: ローカルハードウェアなしでアンセンサードLLMをテストしたい場合
- プラットフォーム: OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B: OpenRouter経由の大規模アンセンサードモデル
Sao10kによる70Bのクリエイティブ・ロールプレイおよび指示追従モデルです。Llama 3.3 70Bをベースにし、131Kコンテキストを備えています。OpenRouterで積極的にメンテナンスされており、プラットフォーム内の検索から名前で簡単に見つけることができます。
- パラメータ数: 70B
- VRAM: 不要(クラウドホスト)
- 用途: ローカルハードウェアなしでの複雑な創作、ロールプレイ、長い指示連鎖
- プラットフォーム: OpenRouter
13. Sao10K: Llama 3 8B Lunaris: OpenRouter経由の軽量アンセンサードモデル
Lunaris 8Bは、Llama 3 8BをベースにしたSao10kによる汎用およびロールプレイモデルです。創造性と論理的思考、一般知識のバランスを取るために複数のモデルを戦略的にマージしています。Stheno v3.2の体験を向上させ、より高い創造性と推論力を提供します。OpenRouterで最も低コストなアンセンサードオプションであり、100万トークンあたり0.04ドル/0.05ドルという低価格で提供されています。
- パラメータ数: 8B
- VRAM: 不要(クラウドホスト)
- 用途: 最低限のコストで利用できる軽量なアンセンサード会話および創作
- プラットフォーム: OpenRouter
14. TheDrummer: Cydonia 24B V4.1: OpenRouter経由のアンセンサード創作モデル
Cydonia 24B V4.1は、TheDrummerによる Mistral Small 3.2 24Bベースのアンセンサード創作モデルで、優れた記憶力、プロンプト順守能力、知性を備えています。131Kコンテキストウィンドウに対応しており、OpenRouter上で積極的にメンテナンスされています。
- パラメータ数: 24B
- VRAM: 不要(クラウドホスト)
- 用途: ローカルハードウェアなしでのアンセンサードな創作およびロールプレイ
- プラットフォーム: OpenRouter
Atlas Cloudでアンセンサード画像・動画モデルにアクセスする方法
2026年現在、メインストリームのクラウドプロバイダーはNSFW出力をブロックするコンテンツフィルターを適用しているため、ほとんどのアンセンサード画像・動画モデルの利用にはローカルGPUまたは専用APIプラットフォームが必要です。Atlas Cloudは、この制約を取り除くために構築されたモデルAPIプラットフォームで、テキスト、画像、動画、音声にわたり300以上の厳選されたモデルをカバーしています。
利用開始までの3ステップ:
- atlascloud.aiでアカウントを作成
- ダッシュボードからAPIキーを生成
- キーを使用してモデルエンドポイントを呼び出す(画像・動画モデルは独自のREST形式を使用。LLMエンドポイントはOpenAIのChat Completions形式に準拠)
Atlas Cloudがアンセンサード用途に選ばれる理由:
- プラットフォームのプライバシーポリシーには「生成されたコンテンツはトレーニングに使用されず、第三者に閲覧されることもありません」と明記されています。これは単なるデフォルト設定ではなく、明示的な公約です。
- カタログ内のどのモデルにも1日の生成上限はありません。
- アンセンサード画像カタログには33のテキストから画像への生成モデルがあり、1枚あたり0.003ドルから利用可能です。
- アンセンサード動画カタログには10以上のNSFW動画モデルがあり、1秒あたり0.01ドルから利用可能です。
アンセンサードモデルの全カタログはUncensored AIから閲覧可能です。以下の15位から20位までのモデルはすべて、一つのAtlas Cloud APIキーでアクセスできます。
NSFWや成人向けコンテンツ生成に最適なアンセンサード画像AIモデル
2026年現在、高品質なアンセンサード画像生成の大部分はFLUXアーキテクチャが担っており、Atlas Cloud API経由で利用可能です(Atlas Cloud, text-to-image model list, 2026)。Atlas Cloudは合計33のテキストから画像への生成モデルをカタログ化しています。ファインアート、キャラクターデザイン、成人向けポートレート、ゲームアセット、大量のイラスト生成などに利用されています。
Atlas Cloudのホームページでは「テキスト、画像、動画、音声にわたり300以上の厳選されたモデル」を提供していると謳っており、プライバシーポリシーにはコンテンツが学習に使用されないことが明記されています。
ブラウザベースおよびAPIのアンセンサード画像ツールについては、最高のアンセンサードNSFW AI画像生成ガイドが機能比較を詳しくカバーしています。特にFLUXアーキテクチャに重点を置く開発者は、FLUXのアンセンサード画像生成ガイドでファインチューニングやワークフローの詳細を確認できます。
既存の画像から開始するワークフローについては、アンセンサードAI画像to画像ガイドや最高のアンセンサードAI画像エディターガイドで、画像変換や編集パイプラインを解説しています。アニメスタイルやイラストキャラクターを出力したいチームは、アンセンサードアニメAI画像生成ガイドで専用モデルを探すことができます。
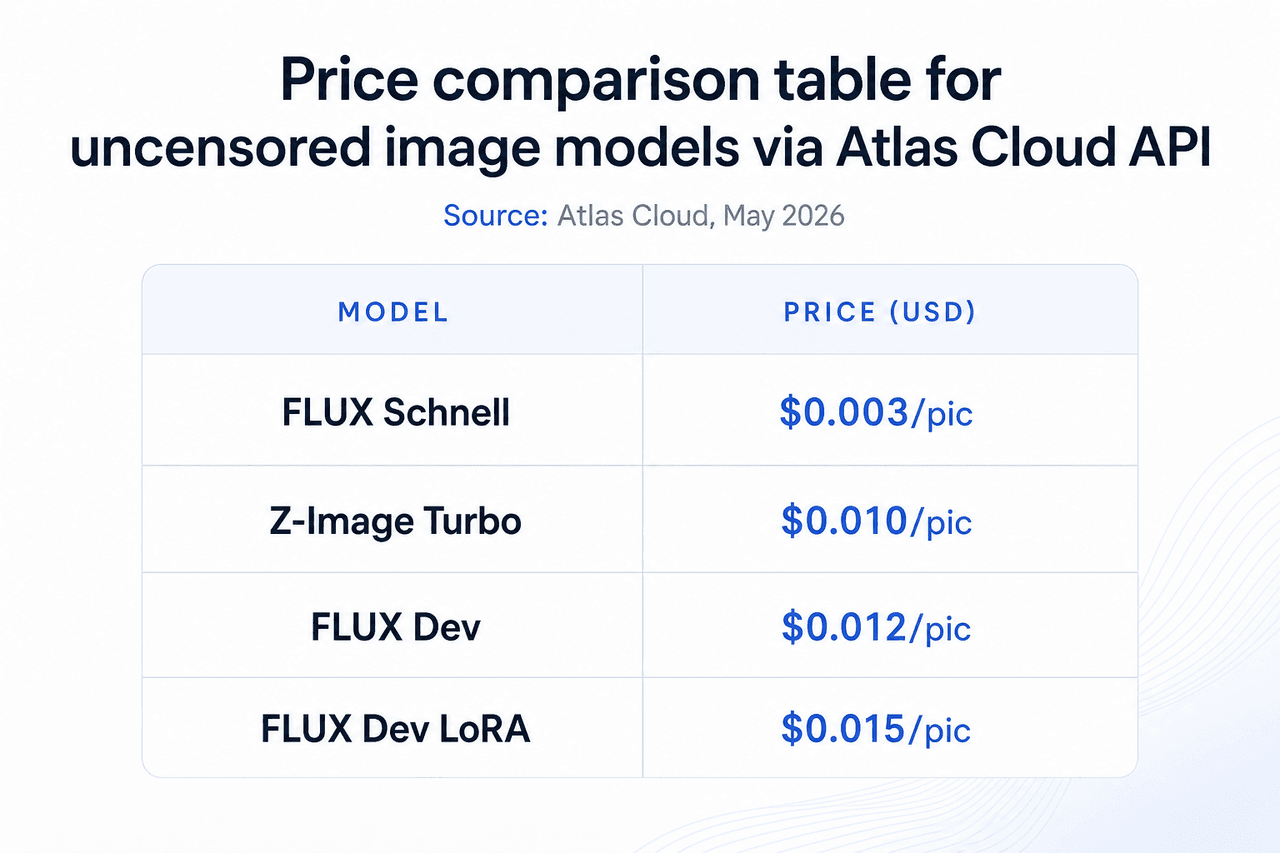
15. FLUX Schnell: バッチ生成向けの最速アンセンサード画像AIモデル
Atlas Cloudカタログで最も安価なオプションです。1枚あたり0.003ドルという価格は、細部の精度よりもスピードと量が求められるバッチ生成ワークフローに最適です。1日の上限はなく、学習にコンテンツが保存されることもありません。
- 価格: 0.003ドル/枚
- VRAM: 不要(APIアクセス)
- 用途: バッチ画像生成、迅速なプロトタイプ作成、大量のアンセンサード出力
- プラットフォーム: Atlas Cloud API
0.003ドルの場合、3ドルで1,000枚の画像を生成できます。これは多くのクラウドストレージ費用よりも安く、かつて夜通しで高価なローカルGPUを稼働させていたスタジオの経済性を完全に変えてしまいます。
16. FLUX Dev: 最終生産物向けの最高品質アンセンサード画像AIモデル
FLUX Schnellの4倍のコストですが、解剖学的な正確さ、照明、テクスチャの細部において明らかに優れています。1枚の画像の質が重要となる最終的な出力には、0.012ドルの価格帯が実用的です。ポートフォリオ作品、商用の成人向けコンテンツ、品質が最優先される制作アセットに適しています。
- 価格: 0.012ドル/枚
- VRAM: 不要(APIアクセス)
- 用途: 高品質な単一画像、ポートフォリオ作品、最終生産用アセット
- プラットフォーム: Atlas Cloud API
17. FLUX Dev LoRA: カスタムスタイル学習対応のアンセンサード画像モデル
LoRAファインチューニングにより、特定のスタイル、キャラクターの外見、対象物をFLUX Devベースに注入できます。バッチ全体で一貫したキャラクターの外見が必要な場合や、セット内のすべての画像に独自のブランドスタイルを適用したい場合に最適なモデルです。Atlas CloudはLoRAの読み込みをサーバーサイドで処理します。
- 価格: 0.015ドル/枚
- VRAM: 不要(APIアクセス)
- 用途: キャラクターの一貫性確保、カスタムスタイル学習、ブランディングされた画像シリーズ
- プラットフォーム: Atlas Cloud API
18. Z-Image Turbo: 中価格帯で品質を両立したアンセンサード画像AIモデル
FLUX SchnellとFLUX Devの価格・品質曲線の間に位置します。1枚0.01ドルのZ-Image Turboは、Schnellのような簡略化を行わずに高速化するように最適化されたアーキテクチャを採用しています。Schnellでは品質が不足し、FLUX Devのコストが高すぎると感じる場合の現実的な選択肢です。
- 価格: 0.01ドル/枚
- VRAM: 不要(APIアクセス)
- 用途: 品質とコストのバランスが必要な中程度のボリュームの生成
- プラットフォーム: Atlas Cloud API
2026年最高のNSFWアニメーション向けアンセンサード動画AIモデル
2026年現在、アンセンサード動画生成には画像生成とは別のパイプラインが必要です。なぜなら、主要な動画プラットフォームは同一のコンテンツフィルターを適用しており、ソース画像がどこで生成されたかに関わらず、NSFWコンテンツのアニメーション化を拒否するからです(Atlas Cloud, uncensored model catalog, 2026)。Atlas Cloudのアンセンサード動画ページには「制限のないクリエイティブな自由。フィルターなし。制限なし。」と掲げられており、Wan 2.6, Wan 2.5, Vanシリーズを含む10以上のNSFW動画モデルが提供されています。
19. Wan 2.2 Turbo Spicy Infinite I2V: 最安のアンセンサード動画モデル
静止画からNSFWアニメーションを作成するためのエントリーモデルです。1秒あたり0.01ドルという価格で、静止画をNSFW動画コンテンツにアニメーション化する最も費用対効果の高い方法です。解像度は1080pまで到達し、クリップの長さを可変できるため、予算重視の制作パイプラインに適しています。
- 価格: 0.01ドル/秒
- 解像度: 1080p
- 期間: 可変
- 用途: 費用対効果の高いNSFWアニメーション、モーションコンセプトのプレビュー
- プラットフォーム: Atlas Cloud API
20. Seedance v1.5 Spicy: 最終出力向けの最高品質アンセンサード動画AIモデル
カタログ内で映画品質を提供するオプションです。1秒あたり0.049ドルはWan 2.2 Turbo Spicy Infiniteの約2.5倍ですが、より滑らかなモーション、フレーム間の一貫性、自然なトランジションを実現します。視覚的な忠実度が最優先される最終品質のNSFW動画出力において、Atlas Cloudのラインナップで最高峰のモデルです。
- 価格: 0.049ドル/秒
- 解像度: 720p
- 期間: 5秒
- 用途: 最終品質のNSFW動画、プロ用成人向けコンテンツ、納品可能な出力
- プラットフォーム: Atlas Cloud API
最高のアンセンサードAI画像to動画生成ガイドでは、Wan 2.7およびWan 2.2 Spicyシリーズの全モデルについて、期間や解像度のオプションを含めて解説しています。
アンセンサードAIモデル簡易比較表
| ニーズ | 推奨モデル |
|---|---|
| 総合的に最高のアンセンサードLLM | llama2-uncensored または dolphin-llama3 |
| コーディングタスク | dolphin-mixtral 8x7B または dolphincoder |
| ロールプレイおよびクリエイティブ執筆 | hermes3 |
| 4GB未満のVRAM | dolphin-phi 2.7B |
| アンセンサード画像生成 | FLUX Schnell (Atlas Cloud経由: 0.003ドル/枚) |
| 画像からのNSFW動画生成 | Wan 2.2 Turbo Spicy Infinite (Atlas Cloud経由: 0.01ドル/秒) |
アンセンサードAIモデルに関するよくある質問(FAQ)
2026年現在、最もアンセンサードなAIモデルは何ですか?
Ollamaのダウンロード数で見ると、llama2-uncensoredが260万回のプルを記録し、コミュニティから最も信頼されているアンセンサードAIモデルです(Ollama, uncensored model search, 2026)。純粋な能力では、関数呼び出し、最大256Kのコンテキスト、Llama 3ベースアーキテクチャを持つdolphin-llama3が優れています。どちらを選択するかは、安定性を重視するか、現代的な能力を重視するかによって異なります。
Ollamaで動作するアンセンサードモデルはどれですか?
リストにあるllama2-uncensored, dolphin-llama3, dolphin-mixtral, dolphin-mistral, dolphin-phi, hermes3, wizard-vicuna-uncensored, dolphincoder, wizardlm-uncensored, everythinglmの10モデルが動作します。また、多言語対応としてjaahas/qwen3.5-uncensoredもOllamaで動作します。すべてollama pull [モデル名]でインストール可能です。
OpenRouterで利用可能なアンセンサードモデルは?
2026年現在、OpenRouterはGPU不要のAPI形式で提供しています。無料枠のvenice/uncensoredモデル(1日200リクエスト制限)に加え、Sao10K Euryale 70B, Lunaris 8B, TheDrummer Cydonia 24Bなどの有料モデルがあります(OpenRouter, venice/uncensored model page, 2026)。
アブリテレーションとファインチューニングモデルの違いは何ですか?
アブリテレーションはモデルの重みレベルで拒否のための重みを外科的に削除します。一方でDolphinシリーズのようなファインチューニングモデルは、そもそも拒否行動を強化しないデータセットで学習されています。コミュニティではファインチューニングモデルの方が一貫した出力を得られると評価されており、これがDolphinモデルがOllamaで圧倒的な人気を誇る理由です。
ノートPCでローカルにアンセンサードAIモデルを実行できますか?
はい。dolphin-phi 2.7Bは4GB未満のVRAMで動作し、ディスクリートGPU搭載ノートPCであれば実行可能です。6〜8GBのVRAMがあれば、本リストのすべての7Bモデルが動作します。統合グラフィックスでは動作しません。詳細はローカルセットアップガイドをご覧ください。
結論
2026年における最高のアンセンサードAIモデルは、用途によって異なります。一般的なLLMタスクにはdolphin-llama3が最も高性能です。ノートPC用途にはVRAM 4GB未満で動作するdolphin-phiが最適です。ハードウェアを持たずクラウドで利用したい場合は、OpenRouterの無料枠であるvenice/uncensoredがトークン料金ゼロで利用可能です。大規模な画像生成にはAtlas Cloud経由のFLUX Schnell(0.003ドル/枚、上限なし)が適しており、NSFW動画に関しては同社が提供する1秒あたり0.01ドルからのサービスが、トレーニングや閲覧を一切行わないポリシーのもとで最高です。
アンセンサードAIツール全般の概観を探している方は、アンセンサードAI画像生成ガイドを参照してください。






