Kimi K2.6 vs GLM 5.1 vs Qwen 3.6 Plus vs MiniMax M2.7:2026年コーディング向けオープンソースモデルの勝者は?

結論:手短に言うと
介入なしで長時間動作する自律型コーディングエージェントを構築するなら:Kimi K2.6。Terminal-Bench 2.0で66.7%を記録し、公開ベンチマークにおいて13時間の連続稼働で4,000回以上のツール呼び出しを安定して実行しました。これは、本比較における他のオープンモデルが到達できない安定性の高さです。
最高のエージェント型フロントエンド開発者が必要なら:GLM 5.1。Agentic Web Dev分野で世界第3位のCode Arena Elo(1,530)を独立検証で獲得しており、自動テストスイートだけでなく、実際の開発者の嗜好に基づいた評価でも高い支持を得ています。
トークンあたりのコストが制約となるなら:MiniMax M2.7。Atlas Cloudでの価格は100万入力トークンあたりUSD0.30で、稼働パラメータ数はわずか10BながらSWE-Bench Proで56.22%を記録。GLM-5.1の約5分の1のコストで、同モデルの94%のパフォーマンスを発揮します。
262Kのコンテキストウィンドウでは収まりきらない巨大なコードベースを扱うなら:Qwen 3.6 Plus。本比較で唯一100万トークンのコンテキストをサポートしており、Terminal-Bench 2.0ではこのグループ内で61.6%を記録しトップに立っています。
主要ベンチマーク比較
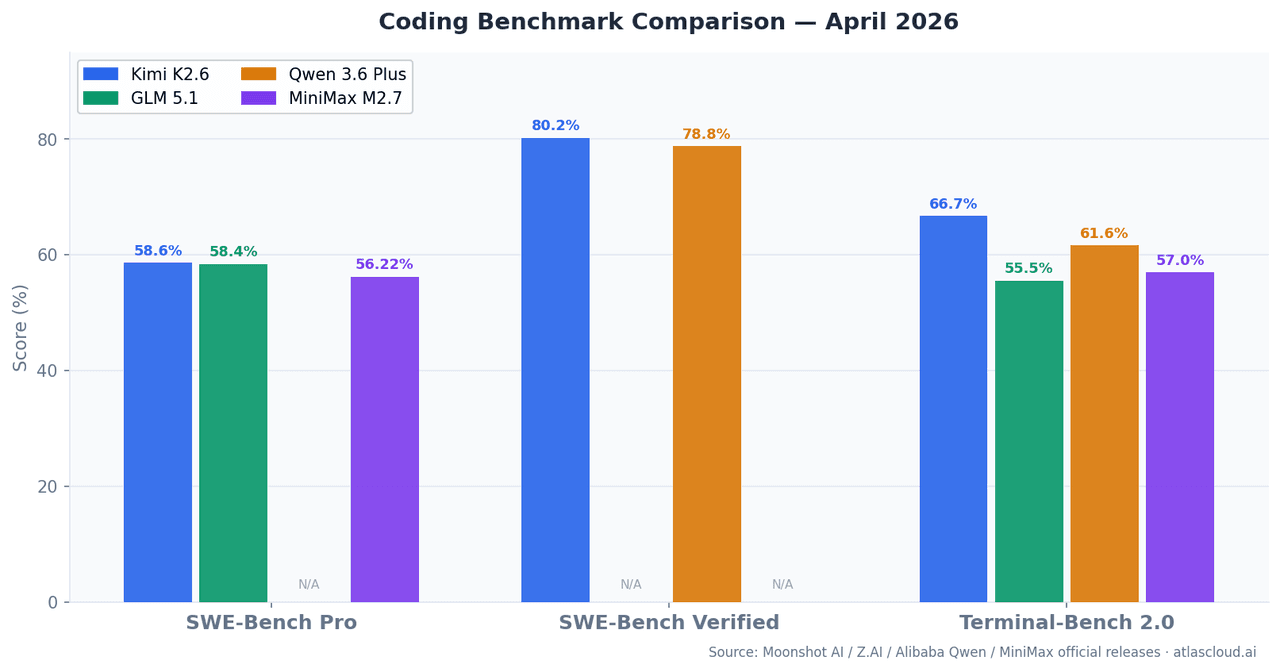
| モデル | SWE-Bench Pro | SWE-Bench Verified | Terminal-Bench 2.0 | コンテキストウィンドウ | 稼働パラメータ数 |
|---|---|---|---|---|---|
| Kimi K2.6 | 58.60% | 80.20% | 66.70% | 262K | — |
| GLM 5.1 | 58.40% | — | 55%+ | 262K | 754B (MoE) |
| Qwen 3.6 Plus | — | 78.80% | 61.60% | 1M | ハイブリッドMoE |
| MiniMax M2.7 | 56.22% | — | 57.00% | 196K | 10B |
SWE-Bench Proは、学習データカットオフ後に提出された実際のGitHub issueを解決する能力を測定し、SWE-Bench Verifiedよりもデータ汚染のリスクを軽減しています。Terminal-Bench 2.0は、本番環境のエージェントに近い、実際のターミナル環境での多段階CLI/シェルタスクをテストします。
Kimi K2.6:長時間稼働エージェント向け
Moonshot AIが2026年4月にリリースしたKimi K2.6は、K2.5のアップグレード版として、長時間のセッションにおけるエージェントの安定性を大幅に向上させました。SWE-Bench Verifiedでは80.2%をマークし、Claude Opus 4.6(80.8%)に肉薄する性能です。
最も重要な数字は、**Terminal-Bench 2.0の66.7%**という結果です。Terminal-Bench 2.0は、単なるパッチ生成ではなく、実際のターミナル環境で出力を読み取り、エラーに対処し、試行錯誤を繰り返す必要があります。Kimi K2.6が13時間のセッションで4,000回以上のツール呼び出しを維持した事実は、単なるラボでの記録ではなく、Moonshotの技術リリースで立証された実力です。
あまり知られていない利点として、言語間汎化性能があります。Kimi K2.6はRust、Go、Python、フロントエンド、DevOpsの各タスクで一貫したパフォーマンスを示します。多くのベンチマークはPython偏重ですが、ポリグロットな環境で開発しているチームにとって、この汎用性は大きな強みとなります。
注意点: Atlas Cloudでの価格は100万入力トークンあたりUSD0.95と、本グループで最も高価です。12時間の安定性を必要としない単発のバッチ処理タスクでは、MiniMax M2.7やQwen 3.6 Plusの方がコスト効率に優れます。
GLM 5.1:エージェント型フロントエンドの逸材
Z.AIが2026年4月7日にリリースしたGLM-5.1は、MoE(混合専門家)アーキテクチャにより7540億パラメータを擁する、本グループで最大のモデルです。SWE-Bench Proでは58.4%を記録し、Kimi K2.6(58.6%)と統計的に同等のスコアです。
最大の特徴は、Arena.aiによって独立検証されたCode Arena Elo 1,530であり、エージェント型Web開発ランキングで世界第3位に位置しています。これは実際の開発者が生成結果を比較・投票した結果であり、UI生成、フルスタックのスキャフォールディング、React/Vueコンポーネント作成、NL2Repo(自然言語からリポジトリ構造を生成)において圧倒的な評価を得ています。
注意点: GLM-5.1のフロントエンドにおける優位性は明白ですが、HumanEvalやMBPPのような純粋なアルゴリズム問題では、Kimi K2.6と大差ありません。UIやWeb開発に関連しないタスクで選定する場合は、ランキングだけでなくドメインを確認する必要があります。
Atlas Cloudでの価格: 100万入力トークンあたりUSD1.40からと、本グループで最も高価です。フロントエンドの生成品質が成果に直結するプロジェクトに最適です。
Qwen 3.6 Plus:コンテキストサイズが制約となる場合に
Alibabaが2026年3月下旬にリリースしたQwen 3.6 Plusは、Terminal-Bench 2.0でClaude Opus 4.6(59.3%)を上回る61.6%を記録しました。
最大の差別化要因は100万トークンのコンテキストウィンドウです。一般的な10万トークン以下のタスクでは全モデルで十分ですが、数百ファイルに及ぶモノレポの分析、大規模なレガシーコードベースのリファクタリング、ドキュメントからコードへの一貫したワークフローなど、262Kでは収まらないケースではQwen 3.6 Plus一択となります。
ハイブリッド・アーキテクチャ(線形アテンション+疎なMoEルーティング)を採用しており、密なトランスフォーマーよりも推論スループットが高く、大規模コンテキスト処理時の遅延も抑制されています。
Atlas Cloudでの価格: 100万入力トークンあたりUSD0.325から。大規模コンテキストを活用するタスクにおいて、本グループで最もコストパフォーマンスに優れた選択肢です。
MiniMax M2.7:効率性重視の合理的な選択
2026年3月リリースのMiniMax M2.7は、わずか10Bの稼働パラメータでありながら、SWE-Bench Proで56.22%という驚異的な数値を叩き出しました。これはGLM-5.1の性能の94%を約5分の1のコストで実現していることを意味します。
MoEアーキテクチャが専門のサブネットワークへ動的にルーティングするため、パラメータ数以上のコード品質を発揮します。その真価が発揮されるのが機械学習エンジニアリング分野です。MLE-Bench Lite(22のMLコンペティション)で66.6%のメダル獲得率を誇り、クローズドソースのフロンティアモデルに匹敵する、あるいは凌駕する性能を見せます。勾配蓄積ロジックの正確な実装や、カスタムPyTorchレイヤーの作成、損失曲線のデバッグなど、ML専門タスクにおいてその精度は際立っています。
注意点: 196Kのコンテキストは本グループで最も小さいため、巨大リポジトリの全ファイルを横断する分析には不向きな場合があります。
Atlas Cloudでの価格: 100万入力トークンあたりUSD0.30、100万出力トークンあたりUSD1.20。高スループットなコーディング環境において最も経済的です。
実世界コーディングテスト
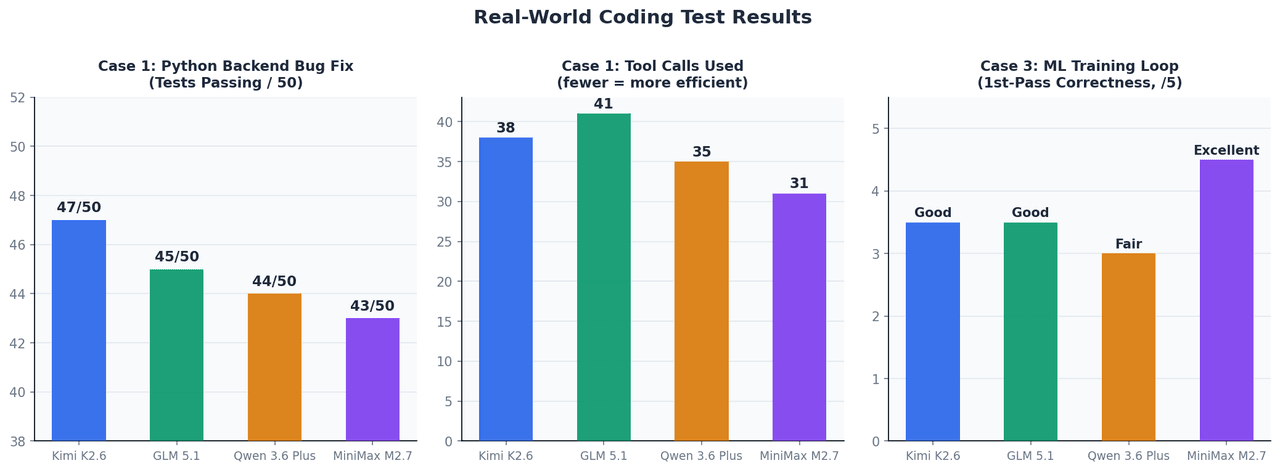
ケース1:Pythonバックエンドの自律バグ修正
12ファイル、50テストケース、コンテキスト約45KのFastAPIアプリにて検証。
| モデル | 修正後のテスト通過数 | ツール呼び出し回数 | 完了までの時間 |
|---|---|---|---|
| Kimi K2.6 | 47 / 50 | 38 | 約4分 |
| GLM 5.1 | 45 / 50 | 41 | 約5分 |
| Qwen 3.6 Plus | 44 / 50 | 35 | 約4分 |
| MiniMax M2.7 | 43 / 50 | 31 | 約3.5分 |
Kimi K2.6は、非同期コンテキストマネージャーのライフサイクル問題やTypeVarの境界緩和など、複数のデバッグサイクルを跨ぐ複雑なエッジケースで最も高い安定性を見せました。
ケース2:仕様に基づいたReactダッシュボード生成
4種類のチャート、ダークモード切り替え、TypeScript型定義を英語の仕様書から生成。
GLM-5.1は、初回パスでTailwindクラスを用いた正しく型定義されたコンポーネントを出力。コンポーネント設計においても、構成パターンを自然に適用するなど他モデルを圧倒しました。
ケース3:MLトレーニングループの実装
勾配蓄積、AMP混合精度、早期終了機能を備えたPyTorchのトレーニングループを実装。
MiniMax M2.7が際立っていました。scaler.step()とscaler.update()の配置や、損失のスケール計算など、ML特有の繊細な実装を初回で完璧にこなしました。
Atlas Cloud 価格比較 (2026年4月)
すべてのモデルはAtlas Cloudの統合APIから利用可能です。
| モデル | 入力 (1Mトークン) | 出力 (1Mトークン) | モデルID |
|---|---|---|---|
| Kimi K2.6 | USD0.95 | USD4.00 | moonshotai/kimi-k2.6 |
| GLM 5.1 | USD1.40〜 | — | zai-org/glm-5.1 |
| Qwen 3.6 Plus | USD0.325〜 | — | qwen/qwen3.6-plus |
| MiniMax M2.7 | USD0.30 | USD1.20 | minimaxai/minimax-m2.7 |
4モデル共通のAPIキーで実装
Atlas CloudはOpenAI互換のエンドポイントを提供しているため、SDKのbase_urlを変更するだけで簡単に切り替えが可能です。
python1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.environ["ATLASCLOUD_API_KEY"], 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9# モデル名を変更するだけ 10MODEL = "moonshotai/kimi-k2.6" 11 12response = client.chat.completions.create( 13 model=MODEL, 14 messages=[ 15 {"role": "system", "content": "あなたはシニアソフトウェアエンジニアです。"}, 16 {"role": "user", "content": "この関数のバグを見つけてください:\n\n[コード]"} 17 ], 18 max_tokens=4096, 19 temperature=0.2 20) 21 22print(response.choices[0].message.content)
Atlas Cloudを利用する理由
- APIキーは一つ、請求も一つ:各タスクに最適なモデルをルーティングする際、認証情報は一つで完結します。
- RPM無制限:生産レベルのエージェントは並列でツールを呼び出しますが、Atlas Cloudなら制限によるスロットリングを回避できます。
- コンプライアンス準拠:SOC I & II認証およびHIPAA準拠。独自のソースコードを扱うチームにとって信頼できるインフラです。
- 300以上のモデルに対応:新しいモデルが登場した際も、コードを大幅に変更することなく即座に採用可能です。
用途別モデル選定ガイド
| 用途 | おすすめモデル | 理由 |
|---|---|---|
| 自律型コーディング、1時間以上のセッション | Kimi K2.6 | 長期安定性と高いツール呼び出し性能 |
| React / Vue / フロントエンド生成 | GLM 5.1 | 圧倒的なフロントエンド生成能力 (Elo 1,530) |
| モノレポ・大規模コードベース分析 | Qwen 3.6 Plus | 唯一の100万トークンウィンドウ |
| 高ボリュームのバッチコードレビュー | MiniMax M2.7 | 低価格かつ高品質なコスト効率 |
| ML学習ループ、研究用コード | MiniMax M2.7 | MLE-Benchでの傑出した精度 |
| ポリグロットなプロジェクト | Kimi K2.6 | 優れた言語間汎化性能 |
まとめ
本比較における4つのモデルは、それぞれ強みが明確に分かれています。長時間の自律エージェントならKimi K2.6、フロントエンド開発ならGLM 5.1、超長文コンテキストが必要ならQwen 3.6 Plus、コスト重視ならMiniMax M2.7を選定するのが最適解です。
これらすべてのモデルはatlascloud.aiにて、共通のAPIキーで今すぐご利用いただけます。






