
数ヶ月前、私たちは「単一のGPUで、1分以内の実時間で、15秒以上の高品質で整合性のある動画を生成する」という、一見単純ながらも難易度の高い目標を掲げました。Wan2.2のような現在の動画拡散モデルは、3〜5秒のクリップ生成には優れていますが、それを10秒、30秒、あるいは1分へと引き延ばそうとすると、途端に難易度が上がります。
本稿では、私たちが実際にたどった道のりを記録します。TTT、LoL、Self Forcing、Self Forcing++、Infinite Talk、Heliosという最近の論文や技術レポートで紹介されている6つのアプローチを調査し、トレードオフを測定した結果、最終的にDiffSynth EngineのTurboWanに組み込んだSVI(Stable Video Infinity)を採用するに至りました。各ルートの解説、SVIの仕組み、そして本番環境での数値について順を追って説明します。
なぜ長尺動画は難しいのか
5秒を超えると、主に3つの問題が発生します。
VRAMの壁
Wan2.2は潜在トークン数に対してO(n²)のコストがかかるフルアテンション(Full Attention)を使用しています。その計算は容赦ありません。
5秒(81フレーム): 約32.7kトークン、アテンション行列は約10 GB。 10秒(165フレーム): 約65.5kトークン、アテンション行列は約40 GB — 単一GPUの容量をすでに圧迫します。 30秒(約500フレーム): 約200kトークン、実行不可能です。
実際、Self Forcing単体でも、165フレームのKVキャッシュだけでH200の129 GBの大部分を埋め尽くしてしまいます。
時間的なドリフト
メモリが十分であっても、3つのドリフトモードが現れます。Heliosの論文ではこれらを次のように定義しています。位置シフト(被写体がフレーム内を彷徨う)、色シフト(色相と輝度の緩やかな変化)、そして復元シフト(モデルが過剰修正を行い、目に見える不連続性を生む)。
因果的整合性
標準的な動画拡散モデルは双方向フルアテンションを使用しており、すべてのフレームが他のすべてのフレームを参照します。つまり、ストリーミング出力は不可能であり、N番目のフレームが完了するまで1番目のフレームを表示することさえできません。
私たちの具体的な目標は控えめなものでした。15秒以上の動画であること、滑らかな視覚的連続性、クリップ全体で被写体が安定していること、合計待ち時間が60秒未満であること、最小限の学習で済むこと、そして既存のウェイトを再利用できることを強く優先しました。
調査結果
私たちは6つの手法を調査しました。名称は論文タイトルに基づいています。
ルート1 · TTT (Test-Time Training)
論文:One-Minute Video Generation with Test-Time Training (arXiv 2504.05298, 2025年4月)
推論中にモデルを微調整し、生成済みの内容を保持させるという手法です。すべてのTransformerブロックのアテンション層の後に小さなTTT層(2層MLP、ゲート、ローカルアテンション)を挿入し、短いクリップから1分間へと段階的に学習させます。
ブロックへの挿入: 標準的なアテンションの後に、ゲート、TTT層、ローカルアテンション、そしてLayerNormを接続します。 カリキュラム学習: 3秒 → 9秒 → 18秒 → 30秒 → 60秒と、ウィンドウサイズを長くしていきます。 コスト: H100で約50時間。
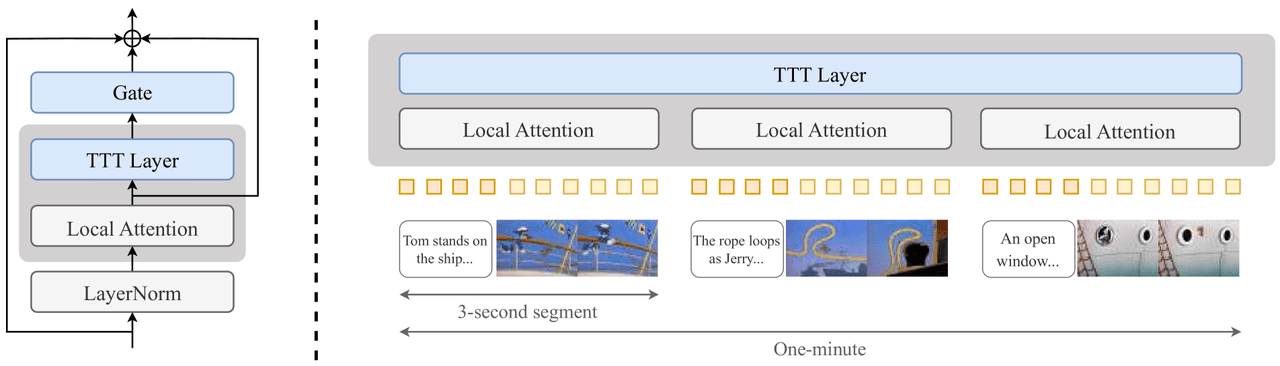
TTT — 左:挿入ポイント。右:動画を3秒のクリップに分割し、それぞれをローカルアテンションで処理しつつ、TTT層がセグメントを跨いでグローバルなメモリを保持する。
実際に1分間の生成を実現しますが、学習コストが膨大であり、実験もCogVideoX 5Bのみ(Wan2.2 14Bへの適用は未検証)であり、挿入されたTTT層が既存のカーネル最適化と競合します。結論:不採用。
ルート2 · LoL (Longer than Longer)
論文:LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914, 2026年1月)
自己回帰型の長尺動画生成における「シンク崩壊(sink-collapse)」という特定の障害に対処する手法です。アンカーフレームへの過度なアテンション集中を防ぐために、ヘッドごとにランダムな位相摂動を加える「Multi-Head RoPE Jitter」を使用します。学習不要で既存モデルに組み込み可能です。
障害モード: シンク崩壊 — 自己回帰的なRoPEにおいて、遠いフレームの位置位相がアンカーと再同期し、コンテンツがアンカーフレームの状態に戻ってしまう。 解決策: 各アテンションヘッドに独自の小さなランダム位相シフトを与える。ヘッドの崩壊を防ぐ。再学習不要。
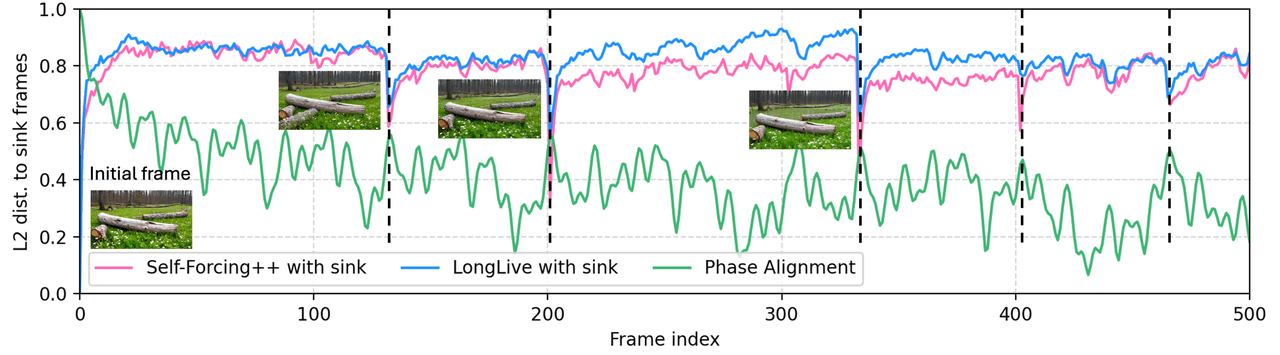
アンカーとのL2距離 vs フレームインデックス。Self-Forcing++やLongLiveではシンク崩壊により何度もアンカー状態に引き戻されるが、LoLのPhase Alignmentはこれを解消する。
CogVideoX等で12時間の動画生成を可能にしますが、デモの多くは静的なシーンです。ダンスやスポーツのような激しい動きへの耐性が不明であり、Wan2.2のアテンション構造を変更する必要があるため、工数対効果の観点から今回は見送りました。結論:不採用。
ルート3 · Self Forcing (Causal Wan2.2)
論文:Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009, NeurIPS 2025 Spotlight)
Wan2.2の双方向フルアテンションを「因果的アテンション(causal attention)」に置き換えます。これによりストリーミング生成が可能になります。最初のチャンクが完了した瞬間にデコード・出力が可能です。
双方向: 40ステップ完了後にしか映像が出ない。因果的: 過去を参照するため、チャンク完了直後にストリーミング可能。
この手法は、推論プロセスそのものをKVキャッシュで再現しながら学習することで、推論時の分布と学習時の分布を一致させる点に特徴があります。
生成ループ: KVキャッシュを条件として、圧縮されたステップスケジュールで次のクリップをデノイズ。 ストリーム: チャンク完了と同時にVAEデコードして出力。 キャリーオーバー: 新しいチャンクの潜在表現をKVキャッシュへ追加。
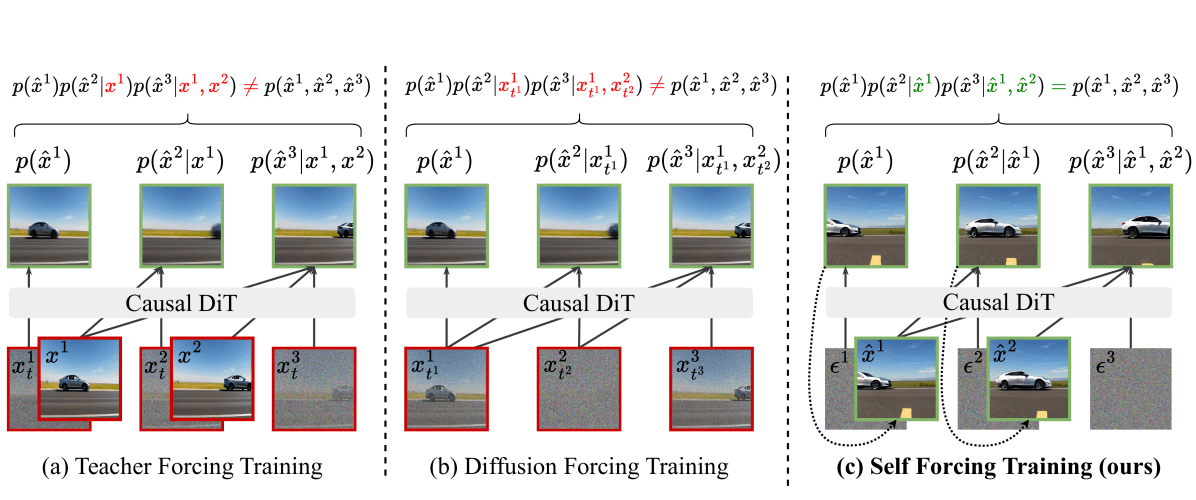
3つの学習パラダイムの比較:Self Forcingは実際の推論プロセスを完全に再現し、学習と推論の乖離を解消している。
H200での測定結果:
| 長さ | フレーム数 | 時間 | VRAM |
|---|---|---|---|
| 5s | 81フレーム | 70s | — |
| 10s | 165フレーム | 168s | 129 GB (容量ギリギリ) |
| 20s | 321フレーム | 287s | 129 GB (KVキャッシュを42フレームに制限) |
アーキテクチャとしては最もクリーンですが、10秒でVRAMを使い切り、165フレームを超えると品質が低下します。現状のコミュニティの動向を待つこととし、今回は採用を見送りました。
ルート4 · Self Forcing++
論文:Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283, 2025年10月)
Self Forcingを拡張し、チャンク間の不連続性を解消する「Backward Noise Initialization」、教師モデルの出力に合わせる「Extended DMD alignment」、動的な動きを強化する「GRPO」を導入しています。
1.3BのWan2.1で分単位の生成を実現する素晴らしい論文ですが、コードやウェイトが公開されておらず、また静的コンテンツ中心であるため、今回は採用を見送りました。
ルート5 · Infinite Talk (A2V)
音声をトリガーにして、話者の動画を際限なく生成する手法です。参照画像でアイデンティティを保ち、前のフレームとの境界を接続します。
特定の用途(トーク映像)には非常に優れていますが、汎用シーンへの応用は難しいため、今回は採用を見送りました。
ルート6 · Helios
論文:Helios: Real Real-Time Long Video Generation Model (arXiv 2603.04379, 2026年3月)
現在、長尺動画生成のSOTAです。過去のフレームを3層ピラミッドで圧縮し、現在のフレームに注入することで、長さに関わらずトークン消費量を一定に保ちます。
14Bモデルの完全な再学習が必要であり、現状では重みが公開されていないため、直ちに導入することはできません。しかし、将来的な最有力候補です。
アプローチの比較まとめ
最終的に選択したSVIを加えた比較表です:
| アプローチ | 最大継続時間 | 品質 | 学習の必要性 | 工数難易度 | 汎用性 | 推奨 |
|---|---|---|---|---|---|---|
| TTT | 1分 | 高 | 重い学習が必要 | 高 | 中 | ★★☆ |
| LoL | 数時間 | 中 (静的のみ) | 必要 | 中 | 中 | ★★☆ |
| Self Forcing | 理論上無制限 | 中 (10s超で低下) | 既存モデル利用 | 高 (VRAM問題) | 高 | ★★★ |
| Self Forcing++ | 1分単位 | 低 (静的) | 必要 | 非常に高 (コードなし) | 高 | ★☆☆ |
| Infinite Talk | 無制限 | 高 (トーク映像) | 必要 | 高 | 低 | ★★☆ |
| Helios | 理論上無制限 | 高 (SOTA) | 完全再学習 | 非常に高 (重みなし) | 高 | ★★★☆ |
| SVI | 無制限 | 中〜高 | オープンソースLoRA | 中 | 高 | ★★★★ |
調査で得られた分類
今回の調査から、長尺動画生成手法は以下の3つのバケツに分類できることがわかりました。
タイプA — アテンション範囲の拡張 (Self Forcing, LoL, TTT)。モデルが直接長いシーケンスを処理する。理論上の品質は最高だが、VRAM消費が二次関数的に増えるため10秒付近で限界が来る。
タイプB — 階層的履歴圧縮 (Helios)。過去フレームを圧縮して条件付けに使う。VRAM問題を回避するが、大規模な再学習が必要。
タイプC — ステートフルなローリング生成 (SVI, Infinite Talk)。長い動画をオーバーラップする短いクリップに分解する。VRAM消費が一定で無制限に生成可能。LoRAのみの学習で済む。
今期、私たちは「タイプC」を採用しました。来年に向けて「タイプB」の進展を注視しています。
次回の投稿では、15秒以上の動画生成をどのように実装したか、なぜSVIを選んだのか、そして実際のパフォーマンス数値について詳しく解説します。第2部を読む →






