
パート1では、長尺動画生成の6つのアプローチ(TTT、LoL、Self Forcing、Self Forcing++、Infinite Talk、Helios)を調査し、14Bモデルの再学習なしで現在実用化できる唯一のパスとしてSVIに注目しました。本稿では、実際にSVIを用いて構築した際の体験を共有します。クリップをつなぎ合わせるループの仕組み、なぜ「エラーリサイクル(Error-Recycling)」が重要なのか、そしてTurboWanでの最初のデプロイにおける本番環境の数値について解説します。
選択肢:SVI (Stable Video Infinity)
SVIの核となる考え方は、無限の長さの生成を、メモリ転送を綿密に設計した有限の短尺クリップを継ぎ合わせるプロセスへと変換することです。シンプルに聞こえますが、これによりエンジニアリング上の課題のほとんどを一挙に解決できます。ベースモデルの再学習は不要(TurboWan上に小さなLoRAをマウント)、VRAM使用量は一定、既存の速度蒸留(speed-distillation)と組み合わせ可能であり、公式LoRAウェイトも公開されています。
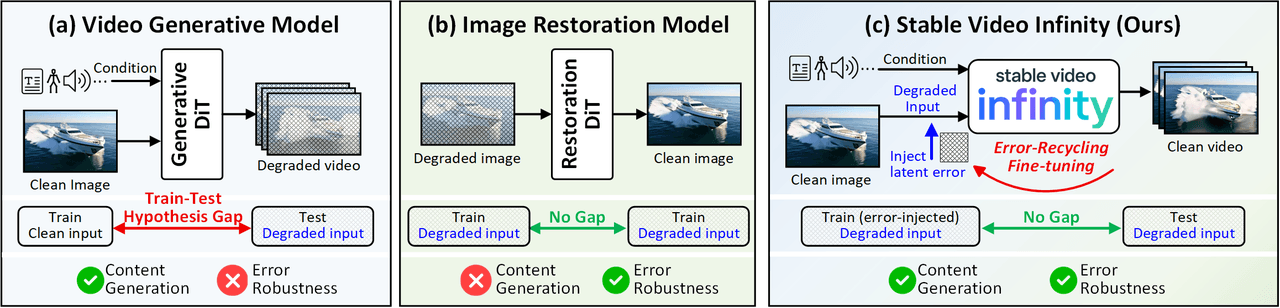
SVIの概念モデル。(a) 標準的な動画生成モデルには「学習時と推論時の仮説のギャップ」があります。学習時はきれいな入力を使いますが、推論時にはエラーが蓄積したノイズ混じりの入力を扱うことになるためです。(b) 画像復元モデルはエラーに対して堅牢ですが、新しいコンテンツを生成できません。(c) SVIのエラーリサイクル微調整(Error-Recycling Fine-Tuning)は、自己生成されたエラーを教師信号として使用することで、モデルが自身の生成エラーを特定し修正することを能動的に学習し、両者の橋渡しをします。
クリップを継ぎ合わせる仕組み
各クリップは81フレーム(16fpsで5秒間)です。生成はループで行われます。グローバルなIDアンカーと、前のクリップからの短期的モーションブリッジを用いて次のクリップを条件付けし、連結していきます。
クリップ1: 入力は参照画像+空のモーションメモリ。出力は5秒のクリップ。モーションメモリ(最後の4フレームの潜在表現)を抽出。 クリップ2: 入力は参照画像+クリップ1からのモーションメモリ。出力は5秒のクリップ。末尾からモーションメモリを抽出。 ... N個のクリップで繰り返し、最後にクリップ1+クリップ2+…+クリップNを連結して長尺動画にします。
優れた点は、DiTのアテンション修正が不要なことです。過去の文脈は潜在表現(latent)として入力レベルで連結され、小さなLoRAがそのプレフィックスを実際に活用するようモデルを教え込みます。
アンカー潜在表現(Anchor latent): ユーザーが提供した参照画像。VAEでエンコードし、被写体やキャラクターの見た目を全体的に一貫させます。 モーション潜在表現(Motion latent): 前のクリップの最後の4/8/12フレームの潜在表現。前のセグメントがどのように終わったかをモデルに伝えます。 パディング(Padding): DiTがアンカー、モーション、パディングという整理された連結シーケンスを認識できるよう入力形状を整えます。
エラーリサイクル微調整(Error-Recycling Fine-Tuning)
SVIが多くのクリップにわたって安定性を維持できる理由は、そのLoRAの学習方法にあります。標準的な推論は常に純粋なガウスノイズからデノイズを開始しますが、長尺動画の継ぎ合わせでは、初期クリップでのエラーが後のクリップの条件付けに悪影響を及ぼします。きれいな参照入力のみで学習していると、学習時と推論時のギャップが埋まりません。
標準的な学習: すべてのクリップの参照入力はクリーンな正解データ。モデルは推論時に直面するようなノイズ混じりの過去の文脈を見ることがなく、不連続性が蓄積します。
エラーリサイクル: 学習中、モデル自身の過去のエラーを意図的に参照入力に注入します。これにより、LoRAはノイズ混じりの過去の文脈で動作することを明示的に学習し、クリップ境界での視覚的な不連続性が大幅に低下します。
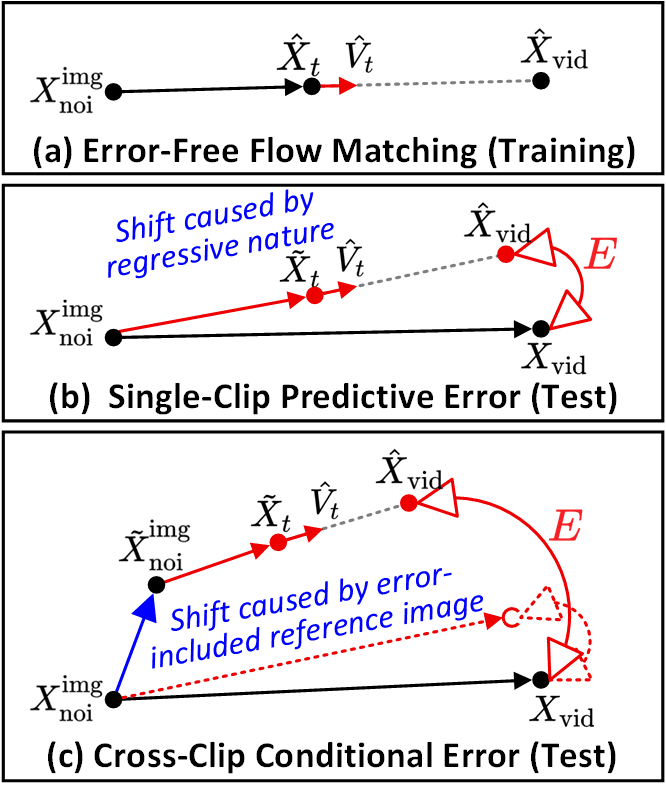
SVIが特定する2つの主要なエラータイプ。(a) Error-Free Flow Matchingは学習時の軌道。(b) 単一クリップ予測エラー(Single-Clip Predictive Error):デノイズ経路と理想的な軌道の間のクリップごとのドリフト。(c) クリップ間条件付きエラー(Cross-Clip Conditional Error):エラーを含んだ参照画像が原因でクリップ全体に連鎖するドリフト。エラーリサイクルは両方を明示的に注入します。
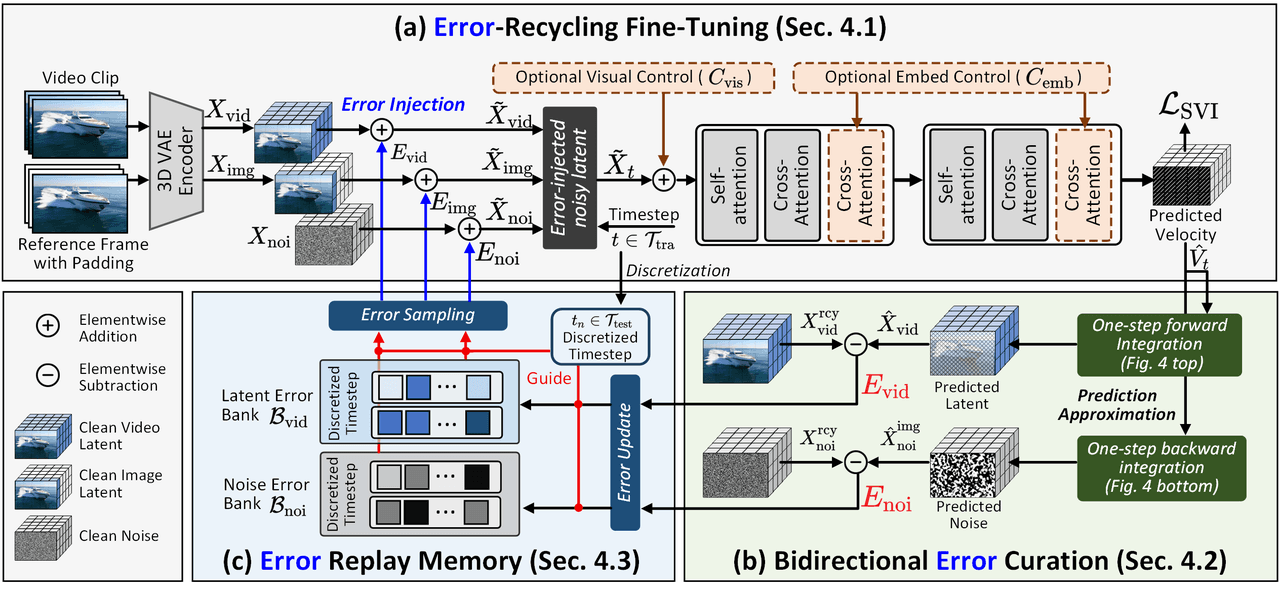
SVIの学習フレームワーク。(a) DiTの自己生成エラーを潜在空間に注入し、エラーフリーという前提を打ち破る。(b) 1ステップの前方/後方積分を通じて双方向エラーを効率的に計算。(c) エラーをReplay Memoryに保存し、再利用のために動的に再サンプリングし、閉ループのエラー監視サイクルを形成します。
SVIは2つのエラータイプを分離します。「単一クリップ予測エラー」はデノイズ経路と理想的な軌道の間のクリップごとのドリフトであり、「クリップ間条件付きエラー」はエラーを含んだ参照画像が次のクリップに渡されることで発生する連鎖的なドリフトです。エラーリサイクルはこれら両方を注入するため、LoRAは明確なエラー許容範囲を学習します。
LoRAバリエーション
SVIには3つのバリエーションがあります。静止画像から短尺クリップを生成する「SVI-Shot」、人間の動き(ポーズシーケンス入力も可能)に対応する「SVI-Dance」、そしてマルチショットやシーン転換を含む長尺動画向けの「SVI-Film」です。ハイパーパラメータ:クリップあたり81フレーム、num_motion_frames ∈ {4, 8, 12}、LoRAランクは通常16〜64。
TurboWan上でのスタック
私たちはSVIのLoRAをTurboWan(Atlasによって最適化されたWanの高速化バージョン)の上にマウントし、スタック内にスタイル制御用の専門的なLoRAを保持しています。推論時には複数のLoRAウェイトが同時に重ね合わせられます。
ベース: TurboWan LoRA 1: 専門的なLoRA(コンテンツ/スタイル制御)。 LoRA 2: SVI LoRA(長尺動画の一貫性)。 結合: TurboWanの速度+SVIの長尺動画の一貫性+Spicyなスタイルを、1回の推論パスで実行。
フル推論フローはシンプルです。参照画像→アンカー潜在表現へエンコード、それを前のクリップのモーション潜在表現およびパディングと連結し、TurboWanのデノイズを実行、デコード、連結、そして新しく生成されたクリップの末尾からモーション潜在表現を更新します。N回繰り返した後、すべてを一つの動画に連結します。
1. 参照画像をエンコード → アンカー潜在表現。 2. y = concat(アンカー潜在表現, モーション潜在表現, パディング)。 3. yとテキスト埋め込みを条件としてTurboWanの5ステップデノイズを実行。 4. クリップをVAEデコードし、出力リストに追加。 5. モーション潜在表現 = 直前に生成されたクリップの末尾(num_motion_frames分)に設定。 6. Nクリップ分繰り返し、すべてを連結。
本番環境の数値
標準テスト:単一の参照画像と3つのプロンプトを用い、約15秒の出力(5秒×3クリップ)を生成。
| 項目 | 数値 |
|---|---|
| 生成時間 | 15秒(3クリップ) |
| クリップごとの推論時間 | 約14秒(TurboWan fp8、シングルGPU) |
| 推論時間合計 | 約42秒 |
| 被写体の一貫性 | 良好 |
事例:猫の冒険(Cat Adventure)
クリップ間の挙動を具体化するため、1つの参照と3つのショットで15秒のケースを実行しました。スタイルプロンプトでPixar風かつ暖かみのある照明を指定。キャラクターは大きな好奇心に満ちた目をしたオレンジのトラ猫。3つのショットでは、窓辺から歩道へ、そしてゴールデンレトリバーに出会うまでを、それぞれ異なるカメラワークで撮影しました。

クリップ1(0〜5秒):窓辺のPixar風オレンジ子猫。カメラがクローズアップからゆっくりと引いていく。スタイルとキャラクターはフレーム間で安定している。

クリップ2(5〜10秒)の境界:子猫の見た目はクリップ1と一致しており、飛び降りる際に姿勢を変える。モーション潜在表現が境界を越えてモーションの状態を伝えている。

クリップ3(10〜15秒):ゴールデンレトリバーが登場し、室内から屋外へのシーン転換。子猫のPixarスタイルは3つのクリップすべてを通じて安定している。
この実行の集計指標:
| 項目 | 数値 |
|---|---|
| 合計時間 | 15秒(3クリップ×5秒) |
| 合計フレーム数 | 240フレーム(16fps) |
| 推論時間合計 | 33秒(TurboWan、シングルGPU) |
| 動画生成比率 | 2.2 s/s |
| 被写体の一貫性 | Pixar風オレンジ子猫が終始安定 |
| クリップ境界の不連続性 | 明らかなジャンプカットなし |
これは、シングルGPUで33秒の間に、クリップ間の被写体の一貫性を保ちつつ15秒の動画を生成できたことを意味します。これは私たちが目標とした「60秒以内の待ち時間」を十分にクリアしています。14件の内部テストセットのうち9件で明らかな問題が発生しませんでした(成功率64%)。
結論として、動画生成における速度、長さ、品質は「鉄の三角形」の3つの頂点のようなものです。現在、これらすべてを同時にトップレベルで実現できるアプローチはありません。興味深いのは、今日のハードウェアと学習予算を考慮した上で、どの頂点をどれだけ妥協するかを選択することです。SVIは長さと境界の品質をわずかに譲る代わりに、Wan2.2クラスの忠実度を誇る長尺動画を、今すぐ1台のGPUで実現します。






