사진을 가지고 있습니다. AI를 사용해 얼굴은 유지하면서 비키니, 란제리 버전이나 더 노골적인 버전으로 변환하고 싶습니다. Midjourney를 시도했지만 거부당했습니다. DALL-E는 이미지를 부드럽게 만들거나 필터링했습니다. 기본 설정의 Stable Diffusion을 시도했지만, 생성이 시작되기도 전에 안전 필터에 의해 차단되었습니다.
이는 도구의 실패가 아니라 설계 결정입니다. 모든 주류 플랫폼은 모델 수준에서 콘텐츠 조정 계층을 적용합니다. 사람들이 '검열되지 않은 이미지 투 이미지 AI(uncensored image to image ai)'를 검색할 때 사용하는 '검열되지 않은(uncensored)'이라는 단어는 바로 이 조정 계층을 제거한다는 의미입니다. 도구는 이미 존재합니다. 문제는 콘텐츠가 변경되는 동안 어떤 모델이 정체성을 올바르게 유지하느냐 하는 것입니다.
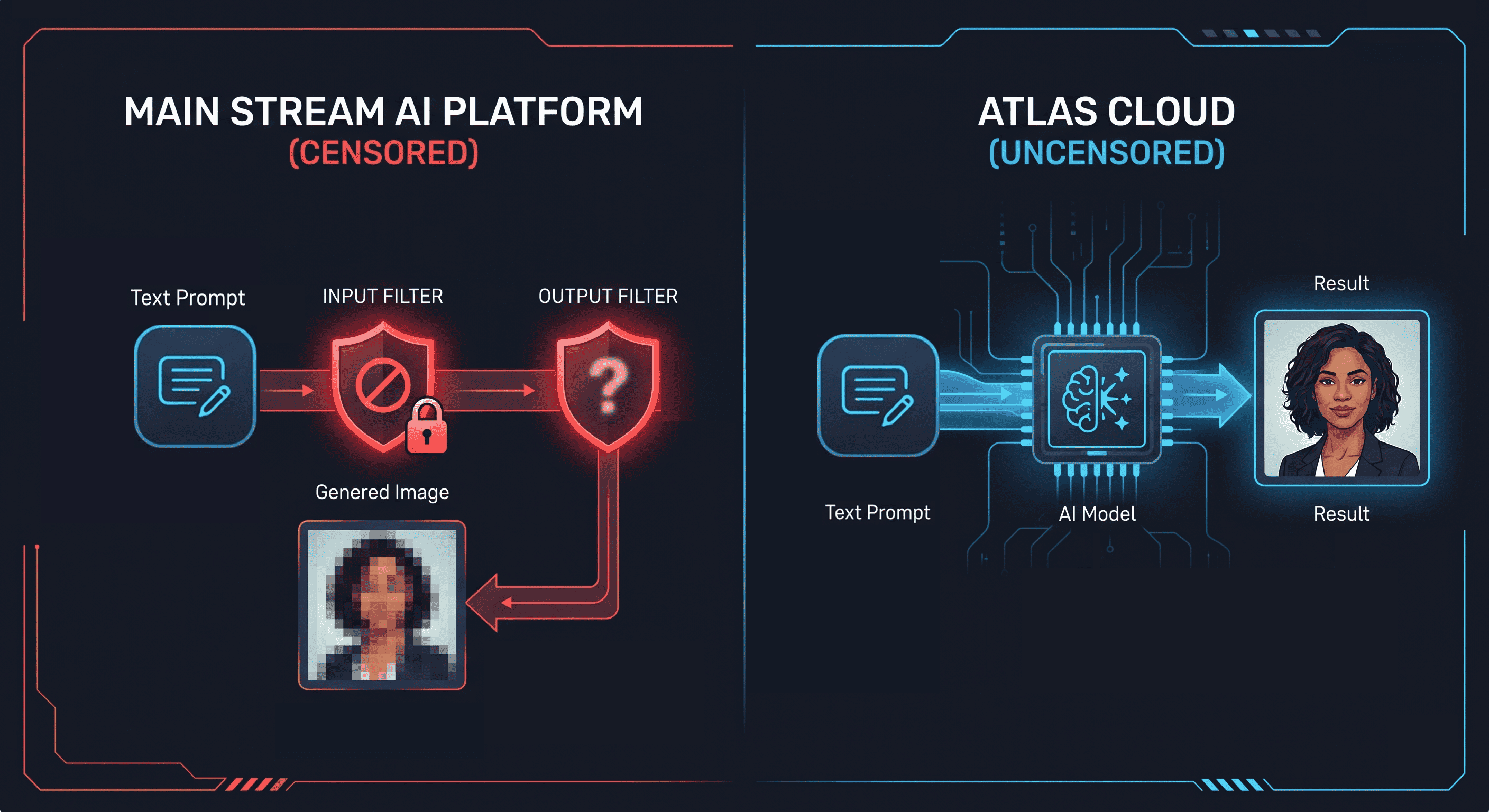
주류 이미지 투 이미지 AI 생성기가 검열되지 않은 콘텐츠를 차단하는 이유
모든 주요 이미지 생성 플랫폼은 프롬프트 입력 계층과 모델 출력 계층이라는 두 가지 단계에서 콘텐츠 필터링을 적용합니다. NSFW(후방 주의) 용어가 포함된 프롬프트를 제출하면 모델이 실행되기 전에 입력 필터가 이를 거부합니다. 프롬프트가 필터를 통과하더라도 출력 필터가 생성된 이미지를 감지하여 결과를 억제하거나 흐리게 만듭니다.
이는 기능의 부족이 아닙니다. 대부분의 이미지 투 이미지 도구를 구동하는 아키텍처인 Stable Diffusion에는 NSFW 출력에 대한 기술적인 제한이 없습니다. 필터링은 플랫폼 운영자가 모델 위에 적용하는 것입니다. 필터를 제거하면 기본 모델이 해당 콘텐츠를 생성합니다.
가격 및 필터 제거 여부에 따른 최고의 NSFW 지원 생성기 순위 비교는 최고의 검열되지 않은 NSFW AI 이미지 생성기 가이드에서 모든 계층의 클라우드 API 및 로컬 옵션을 확인할 수 있습니다.
이미지 투 이미지 AI 생성기 맥락에서 '검열되지 않은(Uncensored)'이란 콘텐츠 조정 계층이 제거되었음을 의미합니다. 모델은 생성할 콘텐츠에 대해 능동적인 개입 없이 프롬프트와 이미지를 처리합니다. Atlas Cloud의 이미지 투 이미지 카탈로그는 이 구성으로 모델을 실행하며, 여기에는 얼굴 보존을 위해 특별히 설계된 인물 편집용 Seedream 제품군이 포함됩니다.
변환 중 얼굴 정체성이 깨지는 두 번째 문제는 콘텐츠 필터링과는 별개의 문제입니다. 이는 모델 학습의 문제입니다. 이 가이드의 나머지 부분에서는 이 문제를 다룹니다.
검열되지 않은 AI 이미지 투 이미지 생성에서 얼굴이 변하는 이유와 해결 방법
사진을 업로드하고 콘텐츠 변환 프롬프트를 작성할 때, 모델은 이미지의 어떤 부분이 수정 불가능한지 알지 못합니다. 모델은 의미론적 가중치에 따라 전역적으로 변경 사항을 적용합니다. 인물 사진에서 의미론적 가중치가 가장 높은 영역인 얼굴은 모델의 집중적인 관심을 받게 되며, 이는 곧 다른 모든 부분과 함께 얼굴이 다시 그려진다는 것을 의미합니다.
얼굴이 얼마나 변할지는 두 가지 변수에 의해 결정됩니다:
guidance_scale은 모델이 원본 이미지를 존중하는 것보다 프롬프트를 얼마나 공격적으로 따를지를 결정합니다. 낮은 값은 원본을 유지하고, 높은 값은 프롬프트가 원본을 대체하게 합니다. guidance_scale 10 이상에서는 프롬프트가 출력을 거의 완전히 제어합니다. 얼굴은 원본 이미지와 상관없이 프롬프트가 암시하는 대로 변하게 됩니다.
모델 아키텍처는 더 큰 요인입니다. 대부분의 이미지 편집 모델은 변환 중에 얼굴 정체성을 분리하도록 학습되지 않았습니다. Seedream 제품군은 다릅니다. 이 모델의 학습은 콘텐츠 생성과 얼굴 보존을 명시적으로 분리하므로, 모델은 원본의 얼굴 특징, 피부 톤, 조명을 유지하면서 의상과 장면을 변경할 수 있습니다.
실질적인 조합: Seedream 모델 + 5~7 사이의 guidance_scale을 설정하면 가벼운 작업부터 무거운 콘텐츠 변환까지 얼굴이 안정적인 출력을 얻을 수 있습니다.
검열되지 않은 이미지 투 이미지 AI 생성기를 위한 모델 선택
| 모델 | 가격 | 얼굴 보존 | 권장 용도 |
|---|---|---|---|
| Seedream v5.0 Lite Edit | $0.032/장 | ★★★★★ | 가벼운 작업부터 무거운 변환까지, 메인 도구 |
| Seedream v5.0 Pro Edit | $0.054/장 | ★★★★★ | 프로급 편집, 레이어 분리, 영역 및 앵커 제어 |
| Seedream v5.0 Lite Edit Sequential | $0.032/장 | ★★★★★ | 원본 사진 1장에서 배치 변형 생성 |
| Seedream v4.5 Edit | $0.036/장 | ★★★★★ | 최종 결과물 렌더링, 최대 디테일 |
| Flux Kontext Dev | $0.025/장 | ★★★☆☆ | 텍스트로 기술 가능한 특정 장면 변경 |
| GPT Image-1 Mini Edit | $0.004/장 | ★★☆☆☆ | 프롬프트 개념 테스트 전용 |
Seedream v5.0 Lite Edit은 가장 추천하는 기본 모델입니다. Atlas Cloud의 공식 설명에 따르면 "얼굴 특징, 조명, 색조를 보존하면서 전문적인 품질의 수정을 가능하게 합니다." 대부분의 검열되지 않은 이미지 투 이미지 사용 사례에서는 이 모델로 시작한 후, 최종 결과물에 더 높은 해상도가 필요할 때 v4.5로 이동하십시오.
Lite Edit만으로 부족할 경우, Seedream 5.0 Pro Edit를 사용해 보십시오. 동일한 검열되지 않은 이미지 투 이미지 기능을 기반으로 영역 및 앵커 제어, 정확한 색상 및 재질 매칭, 투명 PNG 레이어 분리 기능을 제공하는 프로급 단계입니다.
검열되지 않은 AI 프롬프트 가이드는 이 가이드에 포함된 세 가지 콘텐츠 계층 전체에 적용되는 5요소 공식을 다룹니다.
워크플로우 1: 검열되지 않은 이미지 투 이미지 — 수영복 및 란제리 (가벼운 변환)
guidance_scale: 6
num_inference_steps: 25
가벼운 계층은 의상을 수영복, 비키니, 란제리 등으로 교체하는 출력을 다룹니다. 내용은 노골적일 수 있지만 변환 범위는 보통 수준입니다. 신체는 가려져 있으며 변화는 그 신체를 무엇으로 덮느냐에 집중됩니다.
guidance_scale 6에서 Seedream v5.0 Lite는 원본 이미지를 1차 참조로 사용하고 프롬프트를 변경 사항 정의에 활용합니다. 얼굴, 신체 비율, 피부 톤, 조명은 모두 원본에서 그대로 유지됩니다. 오직 의상 영역만 변환됩니다.
프롬프트 구조:
plaintext1[상세한 의상 묘사], 사실적인 사진, 동일한 얼굴, 동일한 신체 비율, 동일한 피부 톤, 동일한 조명 2
작동하는 프롬프트 예시:
plaintext1검은색 레이스 란제리 세트 착용, 사실적인 사진, 높은 디테일, 동일한 얼굴, 동일한 신체 비율, 동일한 피부 톤, 원본과 동일한 조명 방향 2
이 계층에서 얼굴이 일그러지는 원인:
- guidance_scale 8 이상 설정 시. 이 값을 초과하면 Seedream 모델이라 할지라도 프롬프트가 원본 이미지의 정체성 신호를 덮어쓰기 시작합니다.
- 원본 상태를 묘사하는 경우. "의상 제거"와 같은 용어를 추가하면 모델의 주의력이 의상 영역으로 쏠리며 얼굴을 포함한 주변 영역이 불안정해집니다.
- 모호한 신체 묘사. "섹시한 몸매"와 같은 단어는 모델이 비율을 재해석할 여지를 줍니다. 신체 묘사는 "동일한 신체 비율"과 같이 원본에 고정하십시오.
API 호출:
plaintext1import requests 2 3# 1단계: 참조 이미지 업로드 4upload = requests.post( 5 "https://api.atlascloud.ai/api/v1/model/uploadMedia", 6 headers={"Authorization": "Bearer YOUR_KEY"}, 7 files={"file": open("reference.jpg", "rb")} 8) 9image_url = upload.json()["url"] 10 11# 2단계: 생성 12response = requests.post( 13 "https://api.atlascloud.ai/api/v1/model/generateImage", 14 headers={"Authorization": "Bearer YOUR_KEY"}, 15 json={ 16 "model": "bytedance/seedream-v5-0-lite-edit", 17 "image": image_url, 18 "prompt": "wearing a black lace lingerie set, photorealistic, same face, same body proportions, same skin tone, same lighting direction as source", 19 "guidance_scale": 6, 20 "num_inference_steps": 25 21 } 22) 23
워크플로우 2: 검열되지 않은 이미지 투 이미지 — 스타일 노출 (중간 변환)
guidance_scale: 7
num_inference_steps: 28
중간 계층은 시스루 원단, 부분적인 가림, 노출이 많은 컷 등 피부 노출이 더 많은 출력을 다룹니다. 모델이 보수적인 해석을 기본값으로 선택하게 만드는 모호함을 유발하지 않으면서 적절한 노출 수준을 프롬프트로 전달해야 합니다.
guidance_scale을 7로 높이십시오. 원본 이미지의 원래 의상과 충돌하면서도 이 정도 수준의 변환을 적용하려면 프롬프트의 영향력이 더 필요합니다. 이 설정에서는 프롬프트 내의 정체성 고정(Identity anchors)이 더욱 중요해집니다. 모델이 프롬프트를 전반적으로 더 많이 따르고 있기 때문에, 무엇을 유지해야 하는지 명시적으로 지시하는 것이 중요합니다.
프롬프트 구조:
plaintext1[적절한 커버리지 디테일이 포함된 특정 의상], 사실적인 사진, 초고해상도, 동일한 얼굴, 동일한 얼굴 특징, 동일한 신체 비율, 동일한 피부 톤, 부드러운 자연광 2
작동하는 프롬프트 예시:
plaintext1속옷을 입지 않은 시스루 흰색 미니 원피스 착용, 천을 통해 보이는 모습, 사실적인 사진, 초고해상도, 동일한 얼굴, 동일한 얼굴 특징, 동일한 신체 비율, 동일한 피부 톤, 부드러운 자연광 2
이 계층의 프롬프트 전략:
직접적으로 누드를 묘사하기보다는 의상이 무엇인지, 무엇을 드러내는지 설명하십시오. "시스루 원단, 투명하게 보이는"과 같은 표현은 의상 묘사로 인식됩니다. 이는 모델에게 일관된 시각적 목표를 제공합니다. "더 노골적으로 만들어줘"와 같은 추상적인 지시는 구체적인 시각 상태를 묘사하지 않기 때문에 모델이 일관성 없게 해석합니다.
중간 계층에서 얼굴이 일그러질 경우:
guidance_scale 7로 올린 후 얼굴이 변한다면, 정체성 고정 문구를 프롬프트 뒷부분이 아닌 앞부분으로 옮기십시오. 모델은 앞쪽 토큰에 더 높은 가중치를 둡니다. 순서를 다음과 같이 변경하십시오:
plaintext1원본과 동일한 얼굴, 동일한 얼굴 특징, [의상 묘사], 사실적인 사진, 동일한 신체 비율, 동일한 피부 톤 2
워크플로우 3: 검열되지 않은 AI 이미지 투 이미지 — 노골적인 콘텐츠 (무거운 변환)
guidance_scale: 5
num_inference_steps: 30
무거운 계층은 완전한 누드, 노골적인 포즈 등 가장 수위가 높은 출력을 다룹니다. 이 수준에서는 원본 이미지에서 가장 많이 벗어난 결과를 요구하게 되며, 모델은 원본을 덮어쓰라는 압박을 가장 크게 받습니다. 이때 얼굴 정체성이 가장 큰 위험에 처합니다.
역설적이게도 해결책은 guidance_scale을 올리는 것이 아니라 5로 낮추는 것입니다. 콘텐츠 변환이 극단적일수록 모델은 정체성 신호를 위해 원본 이미지를 참조할 더 많은 공간이 필요합니다. 원본 이미지가 얼굴을 고정하도록 두고, 프롬프트는 콘텐츠를 유도하게 하십시오.
이 계층에서는 v5.0 Lite 대신 Seedream v4.5 Edit($0.036/장)를 사용하십시오. v4.5 아키텍처는 더 세밀한 얼굴 디테일을 포함하여 고해상도 출력을 생성하며, 이미지의 나머지 부분이 최대치로 변환될 때 이는 매우 중요합니다. 얼굴이 동일 인물로 읽히려면 더 높은 정의가 필요합니다.
작동하는 프롬프트 예시:
plaintext1누드, 전신, 사실적인 사진, 4k, 원본과 동일한 얼굴, 동일한 얼굴 특징, 동일한 신체 비율, 동일한 피부 톤, 동일한 머리카락, 자연광 2
무거운 계층의 얼굴 고정 위치:
guidance_scale 5에서는 정체성 고정 문구가 대부분의 역할을 수행합니다. 콘텐츠 묘사 직후에 배치하십시오:
plaintext1[콘텐츠], 원본과 동일한 얼굴, 동일한 얼굴 특징, 동일한 신체 비율, 동일한 피부 톤, 동일한 머리카락, [품질/조명] 2
콘텐츠 묘사와 품질 용어 사이에 얼굴 고정 문구를 배치하면 프롬프트 중간에서 가장 높은 가중치를 가진 제약 조건으로 인식됩니다. 이 배치는 guidance_scale이 낮을 때 문구를 마지막에 두는 것보다 훨씬 일관된 결과를 냅니다.

사진 한 장으로 검열되지 않은 AI 이미지 투 이미지 배치 변형 생성하기
모델: Seedream v5.0 Lite Edit Sequential
guidance_scale: 6
num_inference_steps: 25
동일한 원본 사진에서 여러 출력물(다른 의상, 다른 노출 수준, 다른 장면 등)이 필요할 때, 시퀀셜(Sequential) 모델은 전체 배치에 걸쳐 얼굴 정체성의 일관성을 유지합니다. 단일 이미지 호출을 별도로 여러 번 실행하면 작은 정체성 변화들이 누적됩니다. 시퀀셜 모델은 모든 출력을 동일한 원본에 고정합니다.
plaintext1from concurrent.futures import ThreadPoolExecutor 2import requests 3 4API_KEY = "YOUR_KEY" 5IMAGE_URL = "UPLOADED_IMAGE_URL" # 한 번 업로드하고 재사용 6 7prompts = [ 8 "wearing a red bikini, photorealistic, same face, same body proportions, same skin tone, beach lighting", 9 "wearing black lingerie, photorealistic, same face, same body proportions, same skin tone, soft studio lighting", 10 "wearing a sheer dress, photorealistic, same face, same body proportions, same skin tone, natural daylight", 11] 12 13def generate(prompt): 14 return requests.post( 15 "https://api.atlascloud.ai/api/v1/model/generateImage", 16 headers={"Authorization": f"Bearer {API_KEY}"}, 17 json={ 18 "model": "bytedance/seedream-v5-0-lite-edit-sequential", 19 "image": IMAGE_URL, 20 "prompt": prompt, 21 "guidance_scale": 6, 22 "num_inference_steps": 25 23 } 24 ).json() 25 26with ThreadPoolExecutor(max_workers=5) as executor: 27 results = list(executor.map(generate, prompts)) 28
원본 이미지를 한 번 업로드하고 반환된 URL을 모든 호출에서 재사용하십시오. 시퀀셜 모델은 $0.032/장으로 단일 이미지 호출 가격과 동일합니다. 일관성 향상을 위한 추가 비용은 없습니다.
무료 검열되지 않은 AI 이미지 투 이미지 생성기 옵션
무료 검열되지 않은 이미지 투 이미지 AI 생성기도 존재하지만, 이 사용 사례에는 세 가지 구조적 한계가 있습니다:
얼굴 보존 아키텍처 부재. 무료 계층 모델은 일반적으로 Seedream급의 얼굴 분리 학습이 적용되지 않은 구버전이거나 더 작은 모델입니다. 중간 및 무거운 콘텐츠 변환 수준에서는 guidance_scale 설정과 무관하게 얼굴이 변합니다. 모델에 얼굴을 분리할 메커니즘이 없기 때문입니다.
512x512 또는 768x768 해상도 제한. 해당 해상도에서의 얼굴 디테일은 동일 인물로 읽히기에 부족합니다. 얼굴 정체성은 눈 모양, 턱선, 피부 질감과 같은 미세한 디테일에 있는데, 저해상도에서는 이러한 디테일이 사라집니다.
30초에서 수 분에 달하는 대기열. 프롬프트 변형과 guidance_scale 설정을 반복하려면 빠른 피드백이 필요합니다. 생성당 2분의 대기열은 파라미터 테스트를 비효율적으로 만듭니다.
Seedream 실행 전 프롬프트를 검증하려면, Atlas Cloud에서 $0.004/장인 GPT Image-1 Mini Edit가 무료 도구보다 더 나은 옵션입니다. $0.05 미만으로 10~15번의 테스트 생성을 수행할 수 있으며, 대기열 없이 일관된 응답 시간을 보장합니다.
생성 유형 전반에 걸친 검열되지 않은 AI 도구의 전체 비교는 완벽한 검열되지 않은 AI 이미지 생성기 가이드에서 확인하십시오.
자주 묻는 질문(FAQ)
Atlas Cloud는 NSFW 및 노골적인 콘텐츠 생성을 지원하나요?
네. Seedream 제품군과 Flux Kontext Dev를 포함한 Atlas Cloud의 검열되지 않은 이미지 투 이미지 모델은 콘텐츠 조정 필터 없이 실행됩니다. 노골적인 콘텐츠 생성이 지원됩니다. 모델 가격 및 가용성은 Atlas Cloud 이미지 투 이미지 모델 카탈로그에 나열되어 있습니다.
세 가지 콘텐츠 계층 모두에서 얼굴을 안정적으로 유지하는 guidance_scale은 무엇인가요?
가벼운 변환(수영복/란제리)은 6, 중간(노출)은 7, 무거운 변환(노골적인 콘텐츠)은 5입니다. 무거운 계층일수록 콘텐츠 변환이 모델에 원본을 덮어쓰라는 압박을 크게 주므로 더 낮은 값을 요구합니다. guidance_scale을 낮추면 원본 이미지가 얼굴을 고정하는 데 더 큰 가중치를 갖게 됩니다.
신체 비율은 변했지만 얼굴은 유지되었습니다. 신체를 고정하려면 어떻게 하나요?
프롬프트의 정체성 고정 섹션에 "동일한 신체 비율"과 "원본과 동일한 신체 유형"을 추가하십시오. 신체 비율은 Seedream 모델에서도 얼굴보다 덜 보호받는데, 생성되는 의상과 더 밀접하게 결합되어 있기 때문입니다. 프롬프트에 명시적인 신체 고정 문구를 추가하면 이러한 변형을 줄일 수 있습니다.
여러 호출에서 동일한 원본 이미지 URL을 다시 업로드하지 않고 재사용할 수 있나요?
네. Atlas Cloud 미디어 업로드 엔드포인트를 사용하여 한 번 업로드하고 반환된 URL을 저장하십시오. 해당 URL은 후속 생성 호출에 유효합니다. 배치 실행의 경우, ThreadPoolExecutor 내의 모든 호출에 동일한 URL을 전달하십시오. 시퀀셜 모델은 모든 작업 프롬프트에 적용되는 단일 원본 URL을 허용합니다.
전체 배치를 실행하기 전에 적절한 프롬프트를 찾는 가장 저렴한 방법은 무엇인가요?
$0.004/장인 GPT Image-1 Mini Edit를 사용하십시오. 가벼운, 중간, 무거운 콘텐츠 계층에서 프롬프트를 실행하여 모델이 설명을 어떻게 해석하는지 확인하십시오. 얼굴이 일그러지는 지점을 파악하고 Seedream 배치로 넘어가기 전에 고정 문구 배치를 조정하십시오. 5가지 변형에 대한 전체 프롬프트 테스트 비용은 $0.02입니다.
결론
검열되지 않은 이미지 투 이미지 생성의 장벽은 기술적인 것이 아닙니다. 주류 도구는 기능이 아니라 정책에 의해 콘텐츠를 필터링합니다. 필터를 제거하면 모든 주요 이미지 도구를 구동하는 동일한 확산 아키텍처가 제한 없이 콘텐츠를 생성합니다.
남은 문제는 얼굴 정체성입니다. 일반 모델은 변환 중에 얼굴을 분리하지 않습니다. Seedream v5.0 Lite Edit는 다릅니다. 가벼운 콘텐츠에는 guidance_scale 6으로 시작하고, 중간 노출 출력에는 7로, 최대 프롬프트 압박 하에서 원본 이미지의 정체성을 고정해야 하는 노골적인 변환에는 5로 낮추십시오.
$0.004/장인 GPT Image-1 Mini Edit에서 테스트 프롬프트를 실행하십시오. 일관된 생산 결과물을 위해 Seedream v5.0 Lite Edit로 이동하십시오. 최종 렌더링에 세밀한 얼굴 디테일이 중요하다면 Seedream v4.5 Edit를 사용하십시오. 사진 한 장에서 여러 변형이 필요한 경우, Seedream v5.0 Lite Edit Sequential이 동일한 장당 가격으로 배치를 처리합니다.
모델 평가 및 도구 비교는 최고의 검열되지 않은 AI 이미지 편집기 가이드에서 자세히 다룹니다.






