GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Verken Toonaangevende Modellen
Atlas Cloud biedt u de nieuwste toonaangevende creatieve modellen in de industrie.
Wat GLM LLM Models Onderscheidt
Atlas Cloud biedt u de nieuwste toonaangevende creatieve modellen uit de industrie.

Advanced Reasoning
Tuned for strong logical reasoning, structured analysis, and multi-step problem solving.

Cost-Efficiency
Optimized architectures keep latency and costs under control.

Safety & Governance
Built-in content filters, auditing tools, and policy controls help teams deploy.

Enterprise Reliability
Production-ready SLAs, monitoring, and governance features help teams confidently ship applications.

Chinese–English Excellence
Native-strength Chinese and fluent English support enable high-quality bilingual chat, search, and generation.

Developer-Friendly Ecosystem
Clean APIs, SDKs, and tooling make it easy to integrate, fine-tune, and operate Z.ai across products and platforms.
Pieksnelheid
Laagste kosten
| Model | Description |
|---|---|
| GLM-5 | GLM-5 is Z.ai's flagship LLM featuring a massive 202.75K context window optimized for complex systems and long-horizon agentic tasks. Outperforming elite closed-source models in benchmarks like Humanity’s Last Exam and BrowseComp, it provides robust programming and stable multi-step reasoning at highly competitive baseline pricing. |
| GLM-4.7 | GLM-4.7 is a high-performance LLM with a 202.75K context window specifically engineered for real-world intelligent agents, advanced reasoning, and professional coding. Fast, smart, and reliable, it serves as the ideal engine for building complex websites and automating sophisticated professional workflows with precision. |
| GLM-4.6 | GLM-4.6 is a powerful MoE LLM with a 202.75K context window designed for rapid data analysis and instant, high-fidelity answers. This dependable model excels at high-efficiency tasks like creating professional slides and web content, offering a smart balance of speed and enterprise-grade performance. |
Nieuwe functies van GLM LLM Models + Showcase
De combinatie van geavanceerde modellen met het GPU-versnelde platform van Atlas Cloud biedt ongeëvenaarde snelheid, schaalbaarheid en creatieve controle voor beeld- en videogeneratie.
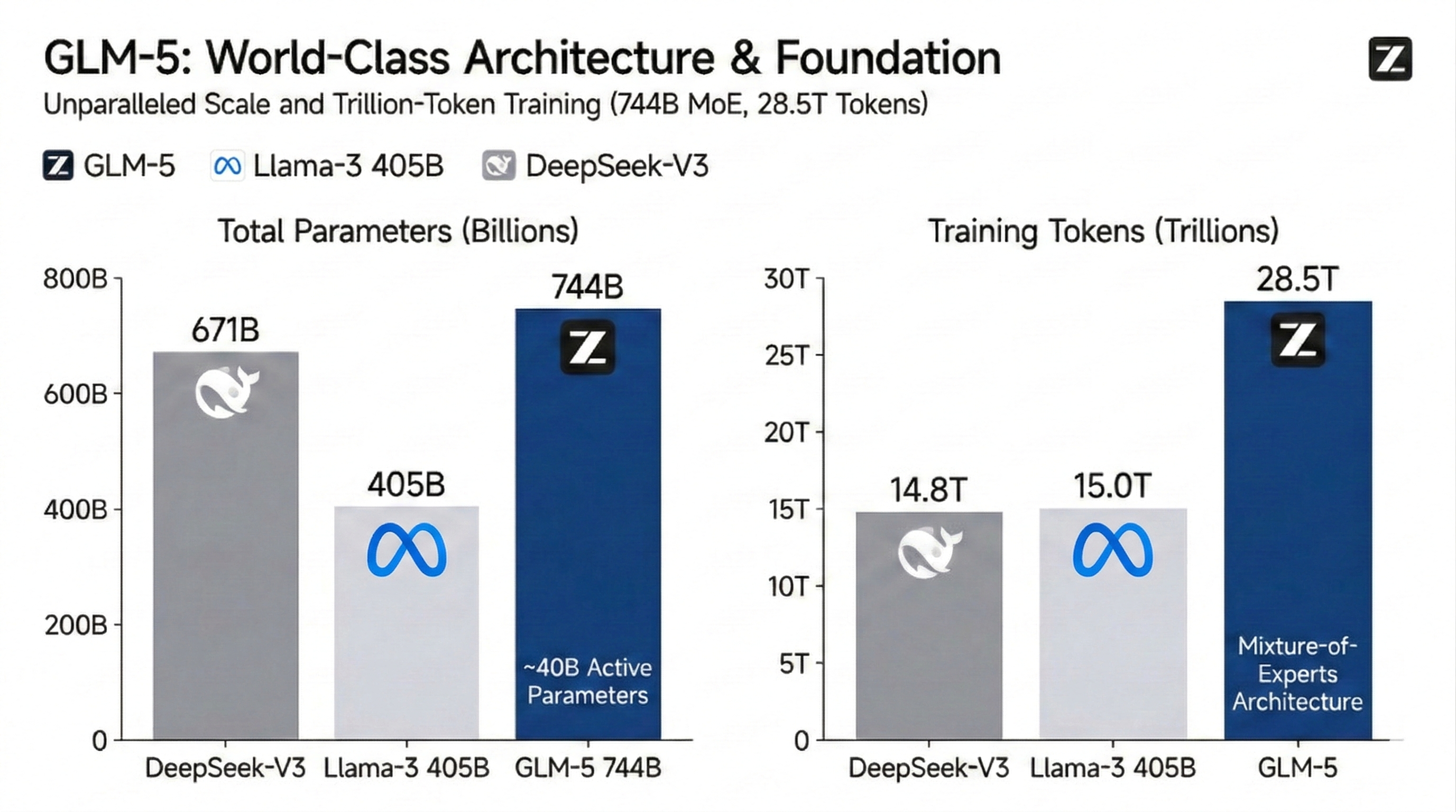
Enorme 744B MoE-architectuur en universele kennisbank
Het GLM-5-model maakt gebruik van een Mixture-of-Experts (MoE)-architectuur met 744 miljard parameters, getraind op een duizelingwekkende 28,5 biljoen tokens om de prestatieplafonds van open-source opnieuw te definiëren. Door 40 miljard actieve parameters te optimaliseren, faciliteert het een enorme sprong in wereldkennisdichtheid en retrieval-precisie. Het is de voornaamste basis voor grootschalige cognitieve taken en complexe gegevenssynthese.
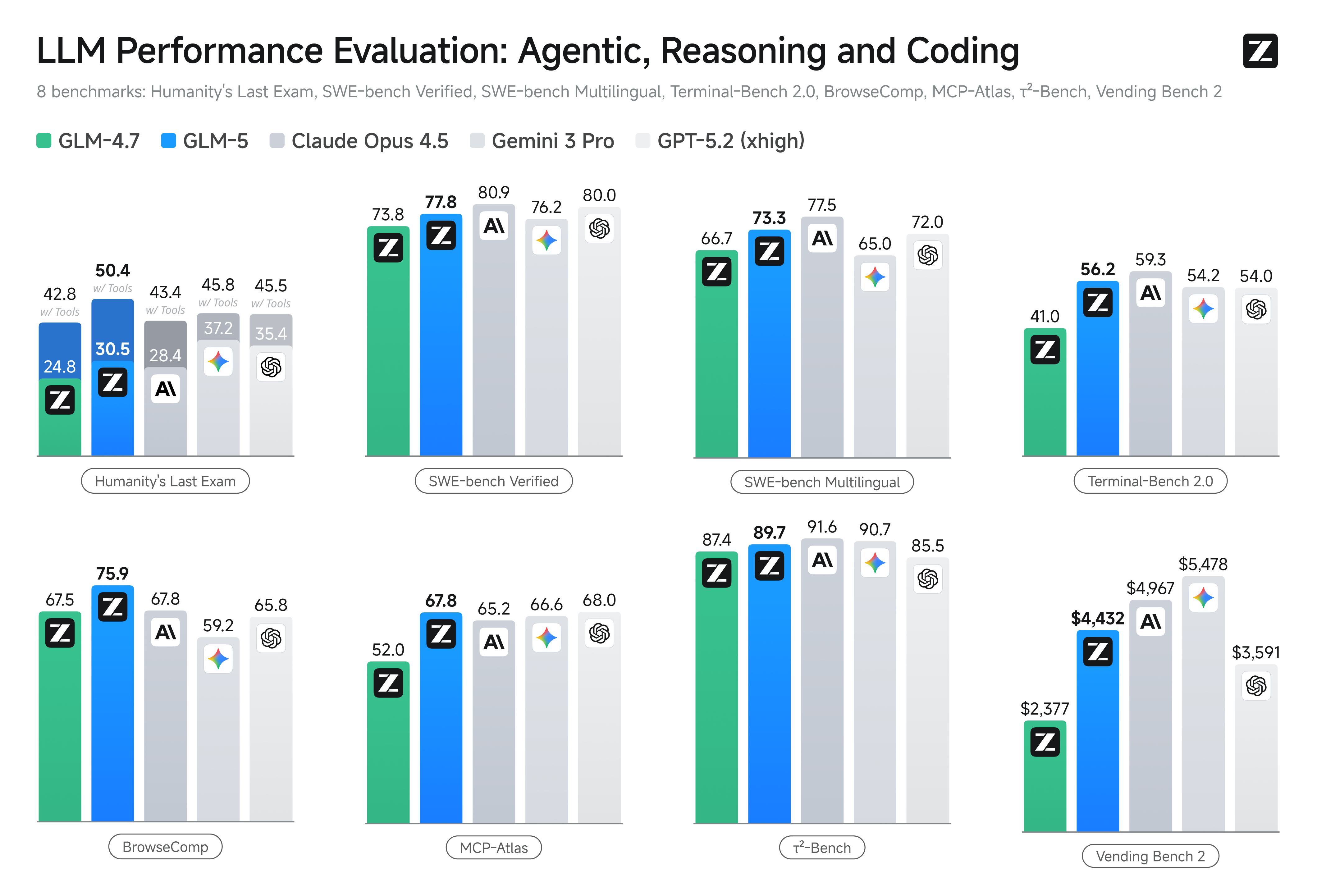
Baanbrekende Agentic System Engineering met GLM-5
GLM-5 introduceert geavanceerde agentische capaciteiten die zijn ontworpen voor langdurige, systemische taakuitvoering in omgevingen met meerstaps redenering. Door geavanceerde planningslogica in de kernarchitectuur te integreren, behoudt het model uitzonderlijke stabiliteit tijdens geautomatiseerde softwareontwikkeling en professionele juridische conceptvorming. Het dient als de definitieve motor voor autonome workflows die extreme precisie en consistentie op lange termijn vereisen.
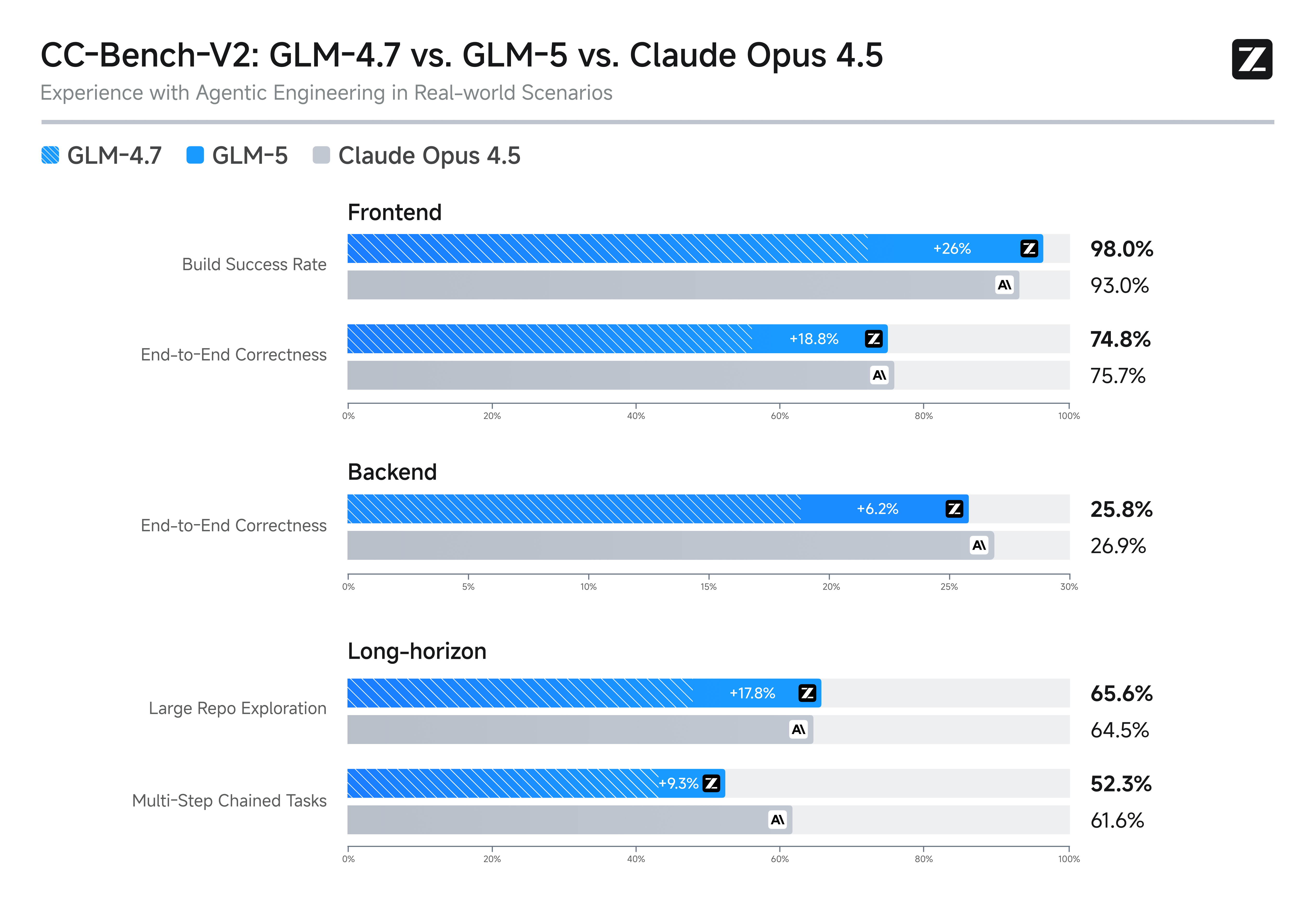
Slime Asynchroon Versterkend Leren en Logica-evolutie
GLM-5 maakt gebruik van de innovatieve "Slime" asynchrone reinforcement learning-infrastructuur om de efficiëntie van post-training en logische nauwkeurigheid radicaal te verbeteren. Deze doorbraak verhoogt de kwaliteit van codegeneratie en algoritmisch redeneren aanzienlijk, overtreft eerdere benchmarks en verzekert zijn positie als toonaangevend open-source model. Het is de ultieme oplossing voor full-stack ontwikkeling en het oplossen van structurele problemen op hoog niveau.
Wat U Kunt Doen met GLM LLM Models
Ontdek praktische use cases en workflows die u kunt bouwen met deze modelfamilie — van contentcreatie en automatisering tot productie-grade applicaties.
Uitgebreide repository-intelligentie met GLM-5
De GLM-5 API stelt ontwikkelaars in staat om volledige codebases in te nemen voor diepgaande logische analyse en structurele refactoring. Door afhankelijkheidsgrafieken in kaart te brengen en complexe asynchrone datastromen te traceren, identificeert het race conditions in randgevallen en verborgen technische schuld. Perfect voor snelle team-onboarding, geautomatiseerde PR-reviews en het onderhouden van schaalbare, krachtige microservices-architecturen.
Direct Full-Stack prototyping met GLM-5
Voor vibe-gedreven ontwikkeling zet GLM-5 abstracte visuele mockups en gefragmenteerde notities om in implementeerbare React- of Next.js-componenten. Het neemt het zware werk van boilerplate-generatie, Tailwind CSS-styling en state management uit handen, terwijl de consistentie over verschillende pagina's wordt gewaarborgd. Ideaal voor solo-oprichters, UX-experimenteerders en het razendsnel lanceren van functionele MVP's.
Autonome workflow-orkestratie met GLM-5
GLM-5 blinkt uit in het beheren van langlopende onderzoekstaken die redenering in meerdere stappen en realtime toolintegratie vereisen. Het kan zelfstandig marktgegevens uit meerdere bronnen synthetiseren, juridische samenvattingen opstellen die aan de regels voldoen en complexe cross-platform planning automatiseren zonder de context te verliezen. Deze use case is geschikt voor projectmanagers, juridische professionals en iedereen die een zeer betrouwbare digitale agent nodig heeft voor systemische operaties.
Modelvergelijking
Bekijk hoe modellen van verschillende aanbieders zich verhouden — vergelijk prestaties, prijzen en unieke sterke punten voor een weloverwogen beslissing.
| Model | Context | Max Output | Input | Positioning |
|---|---|---|---|---|
| GLM-5 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.7 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.6 | 202.75K | 202.75K | Text | Efficient MoE Model |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flagship General |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA Agentic Coding |
How to Use GLM LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Waarom GLM LLM Models Gebruiken Op Atlas Cloud
De combinatie van GLM LLM Models's geavanceerde modellen met het GPU-versnelde platform van Atlas Cloud biedt ongeëvenaarde prestaties, schaalbaarheid en ontwikkelaarservaring.
Prestatie & Flexibiliteit
Lage Latentie:
GPU-geoptimaliseerde inferentie voor realtime reasoning.
Uniforme API:
Voer GLM LLM Models, GPT, Gemini en DeepSeek uit met één integratie.
Transparante Prijzen:
Voorspelbare op tokens gebaseerde facturering met serverloze opties.
Onderneming & Schaling
Ontwikkelaarservaring:
SDK's, analytics, fine-tuning tools en sjablonen.
Betrouwbaarheid:
99,99% beschikbaarheid, RBAC en compliance-ready logging.
Beveiliging & Compliance:
SOC 2 Type II, HIPAA-afstemming, gegevenssoevereiniteit in VS.
Veelgestelde Vragen over GLM LLM Models
Met 28,5T tokens aan trainingsdata en stellaire benchmarkresultaten wordt GLM-5 breed beschouwd als het "plafond van open-source". Het evenaart of overtreft wereldwijde commerciële topmodellen in capaciteit en logica, en biedt een krachtige, hoogwaardige basis voor het wereldwijde ecosysteem van ontwikkelaars.
HLE is een benchmark met een hoge moeilijkheidsgraad, ontworpen om te testen of AI beschikt over menselijke kennis en redeneervermogen op expertniveau. Dat GLM-5 de hoogste score behaalt, betekent dat zijn beheersing van grensverleggende wetenschap en complexe logica het niveau van toonaangevende closed-source modellen heeft bereikt of overtroffen.
BrowseComp is een toonaangevend leaderboard voor "Agentic" capaciteiten, gericht op complexe taakplanning en uitvoering in real-world webomgevingen. De hoogste score vertegenwoordigt het vermogen van GLM-5 om autonoom door browsers te navigeren en informatie over pagina's heen te integreren, wat het markeert als de voornaamste Web Agent-engine.
Deze architectuur biedt een enorme "kennisbank" van 744 miljard parameters, terwijl er tijdens inferentie slechts ~40 miljard worden geactiveerd. Voor ontwikkelaars vertaalt zich dit in kennisdichtheid en redeneerdiepte van wereldklasse—die dense modellen zoals Llama-3 405B overtreffen—tegen lagere latency en kosten.
Het totaal aantal parameters vertegenwoordigt de "kenniscapaciteit" van het model, waarbij 744B zorgt voor een enorme opslag van wereldfeiten en expertlogica. Actieve parameters vertegenwoordigen de "rekenkracht" die per inferentie wordt gebruikt. Dankzij de MoE-architectuur levert GLM-5 intelligentie op 744B-niveau met slechts 40B aan rekenkracht, waardoor een enorme kennisbasis in evenwicht wordt gebracht met snelle, kosteneffectieve prestaties.
Het volume aan pre-trainingsdata bepaalt de "blikveldbreedte" van een model. 28,5T tokens is een van de grootste datasets wereldwijd (ongeveer het dubbele van die van Llama-3) en omvat zeldzame talen, gespecialiseerde academische papers en enorme hoeveelheden hoogwaardige code. Dit zorgt ervoor dat GLM-5 beschikt over superieure nauwkeurigheid en generalisatie bij het aanpakken van complexe long-tail queries, interculturele nuances en low-level systeemprogrammering.
Verken Meer Families
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


