OpenAI LLM Models
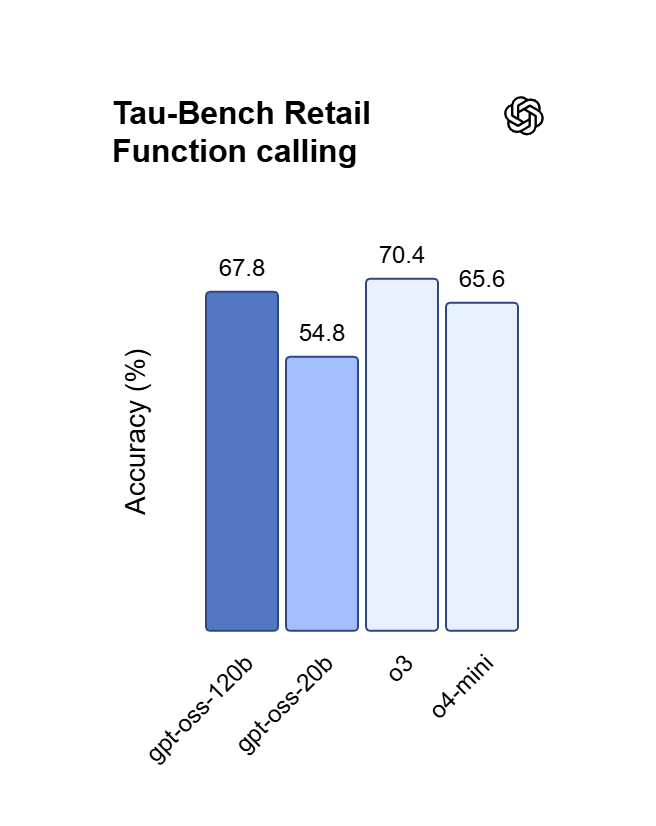
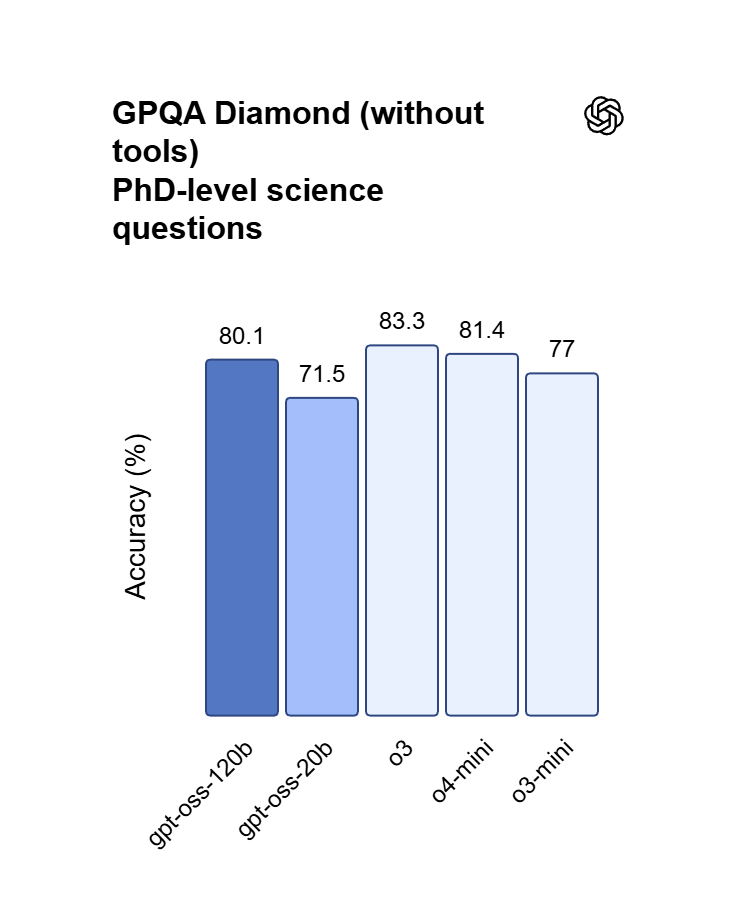
OpenAI’s premier GPT model family leads the industry, highlighted by the GPT OSS 120B which achieves near-parity with OpenAI o4-mini on core reasoning benchmarks while running efficiently on a single 80GB GPU. Perfectly optimized for vibecoding and complex logic operations, this model balances top-tier intelligence with hardware accessibility for modern developers and AI-driven web development.
Modele Wkrótce Dostępne
Kończymy pracę nad tą kolekcją — w międzyczasie zapoznaj się z podobnymi kolekcjami poniżej.
Poznaj Więcej Rodzin
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
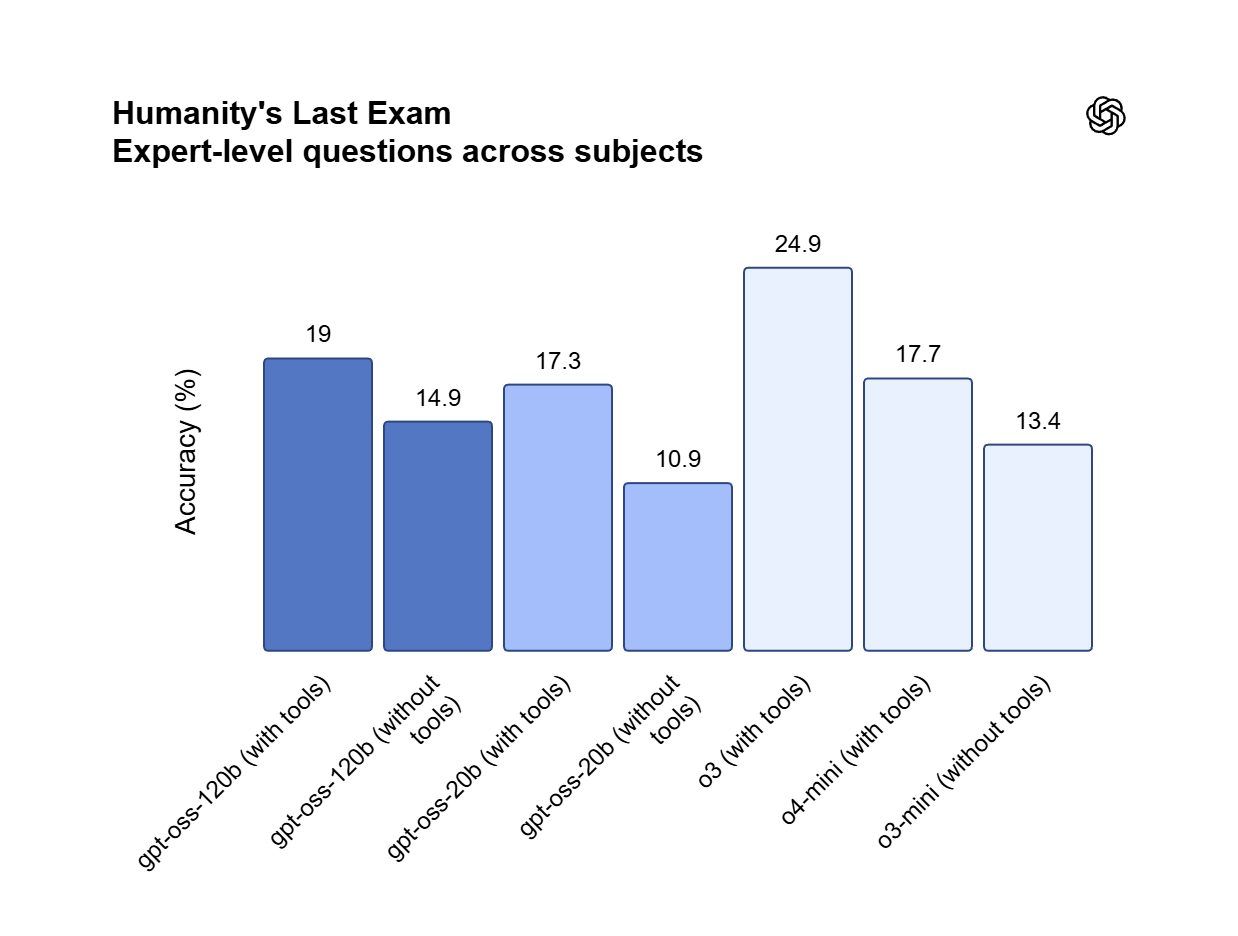
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Co Wyróżnia OpenAI LLM Models
Atlas Cloud zapewnia najnowsze, wiodące w branży modele kreatywne.

Frontier Research
Cutting-edge models that set global benchmarks in reasoning, multimodality, and AI safety.

Cost-Efficient Performance
Optimized families like GPT-4.1 mini and GPT-5 nano balance accuracy, speed, and cost.

Developer Ecosystem
APIs powering millions of daily requests across diverse platforms and industries.

Flexible Model Sizes
Choice of flagship, mini, and nano models for every workload and budget.

Enterprise Reliability
SLAs, monitoring, and compliance-ready logging trusted by Fortune 500 companies.

Open Model Options
Access to open-source models (gpt-oss-20b, gpt-oss-120b) for transparency and customization.
Prędkość szczytowa
Najniższy koszt
| Model | Opis |
|---|---|
| GPT OSS 120B | GPT OSS 120B to wysokowydajny model LLM skoncentrowany na wnioskowaniu, integrujący zoptymalizowaną architekturę z solidnymi możliwościami przetwarzania kontekstu 131.07K; osiągając niemal równorzędność z OpenAI o4-mini na pojedynczym GPU 80 GB, służy jako silnik do szybkiego rozwoju iteracyjnego, w tym vibecodingu i wykonywania złożonych przepływów pracy opartych na logice. |
Nowe funkcje OpenAI LLM Models + Showcase
Połączenie zaawansowanych modeli z platformą Atlas Cloud z akceleracją GPU zapewnia niezrównaną szybkość, skalowalność i kreatywną kontrolę w generowaniu obrazów i wideo.
Precyzyjne wykonywanie instrukcji poprzez GPT OSS 120B
GPT OSS 120B wykazuje wyjątkową sterowność, ściśle przestrzegając złożonych promptów systemowych, aby zapewnić absolutną niezawodność wyników. Wykorzystując precyzyjnie dostrojoną architekturę dostosowania (fine-tuned alignment), użytkownicy mogą wymuszać określone formaty, ograniczenia i niuanse stylistyczne bez żadnych odchyleń znakowych. Jest to ostateczny wybór dla autonomicznych agentów, ekstrakcji danych strukturalnych i krytycznych środowisk produkcyjnych.
Suwerenność komercyjna na licencji Apache 2.0
GPT OSS 120B jest dystrybuowany na licencji Apache 2.0, co pozwala na nieograniczone wykorzystanie komercyjne i prywatne dostrajanie (fine-tuning) bez opłat za token. W przeciwieństwie do zamkniętych interfejsów API, umożliwia lokalny hosting na pojedynczym procesorze GPU 80 GB, co pozwala na przechowywanie wrażliwych danych zastrzeżonych w pełni lokalnie (on-premises). Struktura ta zapewnia prawną i techniczną swobodę budowania, modyfikowania i skalowania stosów oprogramowania opartych na sztucznej inteligencji.
Wysokowydajna logika i Vibecoding przy użyciu GPT OSS 120B
Osiągając niemal równy poziom z OpenAI o4-mini, ten model o 120 miliardach parametrów wyróżnia się w obsłudze złożonej syntezy kodu i dowodów matematycznych. Programiści mogą wykorzystać jego silnik wnioskowania do „vibe coding” – tłumaczenia pomysłów wyrażonych w języku naturalnym bezpośrednio na funkcjonalne aplikacje internetowe poprzez iteracyjne promptowanie. Jest to szybkie rozwiązanie do debugowania zagnieżdżonej logiki i orkiestracji zaawansowanych przepływów pracy związanych z harmonogramowaniem zadań.
Co Możesz Zrobić z OpenAI LLM Models
Odkryj praktyczne przypadki użycia i przepływy pracy, które możesz zbudować z tą rodziną modeli — od tworzenia treści i automatyzacji po aplikacje klasy produkcyjnej.
Debugowanie głębokiej logiki i prototypowanie przy użyciu GPT OSS 120B
GPT OSS 120B umożliwia inżynierom rozwiązywanie wyzwań związanych z „vibecodingiem” poprzez tłumaczenie wysokopoziomowych pomysłów architektonicznych na gotowe do produkcji komponenty Python lub React. Jego silnik wnioskowania obsługuje zagnieżdżone zależności i przypadki brzegowe, które często sprawiają trudność mini-modelom, zapewniając funkcjonalność wieloetapowej syntezy kodu. Obsługując dowody algorytmiczne i złożone harmonogramowanie zadań, jest idealnym narzędziem do budowania technicznych MVP, zautomatyzowanych skryptów QA i aplikacji internetowych intensywnie przetwarzających dane.
Narzędzia własnościowe offline wykorzystujące GPT OSS 120B
W ramach licencji Apache 2.0 zespoły mogą hostować GPT OSS 120B na pojedynczym procesorze GPU 80 GB, aby przetwarzać wrażliwe dane wewnętrzne bez ryzyka wycieku do chmury. Taka konfiguracja umożliwia stałe, lokalne dostrajanie (fine-tuning) na niszowych wewnętrznych bazach kodu lub logach medycznych bez ponoszenia cyklicznych kosztów API za token. Model ten, idealny dla narzędzi wewnętrznych o wysokim poziomie bezpieczeństwa i pomocy AI w trybie offline, zapewnia pełną suwerenność wag, wspierając prywatne systemy RAG i dostosowane stosy oprogramowania własnościowego.
Perfekcyjna schematowo ekstrakcja danych z GPT OSS 120B
GPT OSS 120B umożliwia programistom przekształcanie nieuporządkowanych, niestrukturalnych dokumentów w ściśle sformatowany JSON lub Markdown bez „dryfowania instrukcji”. Dzięki zakotwiczeniu okna kontekstowego 131.07K za pomocą sztywnych reguł systemowych, model zapewnia, że pola nigdy nie są halucynowane ani pomijane podczas przetwarzania długich form. Idealny do automatyzacji CRM i automatycznego tagowania treści, utrzymuje logiczne bariery ochronne w ogromnych zbiorach danych, wspierając niezawodne integracje API i wypełnianie baz danych.
Porównanie Modeli
Zobacz, jak wypadają modele różnych dostawców — porównaj wydajność, ceny i unikalne mocne strony, aby podjąć świadomą decyzję.
| Model | Kontekst | Maksymalne wyjście | Wejście | Pozycjonowanie |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Tekst | LLM o wysokiej wydajności wnioskowania |
| GLM-5 | 202.75K | 202.75K | Tekst | Flagowy model fundacyjny |
| DeepSeek V3.2 | 163.84K | 163.84K | Tekst | Flagowy ogólny |
| MiniMax-M2.5 | 204.8K | 196.6K | Tekst | Programowanie agentowe SOTA |
How to Use OpenAI LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Dlaczego Używać OpenAI LLM Models na Atlas Cloud
Połączenie zaawansowanych modeli OpenAI LLM Models z platformą GPU-akcelerowaną Atlas Cloud zapewnia niezrównaną wydajność, skalowalność i doświadczenie deweloperskie.
Wydajność i Elastyczność
Niska Latencja:
Inferencja zoptymalizowana pod GPU dla rozumowania w czasie rzeczywistym.
Zunifikowane API:
Uruchamiaj OpenAI LLM Models, GPT, Gemini i DeepSeek za pomocą jednej integracji.
Przejrzysta Wycena:
Przewidywalne rozliczenia za token z opcjami serverless.
Przedsiębiorstwo i Skala
Doświadczenie Dewelopera:
SDK, analityka, narzędzia dostrajania i szablony.
Niezawodność:
99,99% dostępności, RBAC i logowanie gotowe na zgodność.
Bezpieczeństwo i Zgodność:
SOC 2 Type II, zgodność z HIPAA, suwerenność danych w USA.
Często Zadawane Pytania o OpenAI LLM Models
Osiąga niemal parytet z OpenAI o4-mini w testach porównawczych dotyczących kluczowego rozumowania i matematyki. Podczas gdy o4-mini jest zamkniętym API, OSS 120B oferuje porównywalną głębię logiczną z dodatkową korzyścią w postaci pełnego dostępu do wag modelu.
Model jest zoptymalizowany dla pojedynczego procesora GPU 80 GB, unikając złożoności systemów wielowęzłowych. Jednak w celu uzyskania natychmiastowej skalowalności i zerowej konserwacji zalecamy dostęp za pośrednictwem API w Atlas Cloud.
Tak. Jest on udostępniany na licencji Apache 2.0, która zezwala na nieograniczone wykorzystanie komercyjne, modyfikację i dystrybucję bez opłat licencyjnych za token ani uzależnienia od dostawcy (vendor lock-in).
Okno kontekstowe 131.07K zaprojektowano z myślą o precyzji wyszukiwania typu „igła w stogu siana”. Może przetwarzać całe katalogi projektów lub ponad 100-stronicowe instrukcje techniczne, zachowując logiczną spójność w całym wprowadzonym materiale.
Wyjątkowo. Jego silnik wnioskowania został dostrojony do iteracyjnej syntezy kodu. Obsługuje zagnieżdżone komponenty React i złożone backendy w języku Python bardziej niezawodnie niż standardowe modele klasy 70B, co czyni go idealnym rozwiązaniem dla przepływów pracy typu „natural language-to-app”.


