DeepSeek LLM Models
DeepSeek, developed by the deepseek-ai team, is a cutting-edge series of open-source generative AI models engineered to democratize access to high-performance computing through a cost-effective and efficiency-first strategy. Its flagship reasoning model, DeepSeek-R1, made waves by rivaling top-tier proprietary models in mathematics, programming, and complex logical deduction, while the DeepSeek-V3.2, is designed for seamless daily interaction and autonomous Agent workflows. By significantly lowering the barrier to entry for advanced AI, DeepSeek has become a cornerstone for the "vibe coding" movement and a transformative tool in specialized fields like academic research and high-level technical problem-solving.
Poznaj Wiodące Modele
Atlas Cloud zapewnia najnowsze, wiodące w branży modele kreatywne.
Co Wyróżnia DeepSeek LLM Models
Atlas Cloud zapewnia najnowsze, wiodące w branży modele kreatywne.

Otwarta Moc
Najwyższej klasy modele w pełni open-source, zapewniające przejrzystość i kontrolę.

Efektywność architektury
Wykorzystuje zaawansowaną architekturę Mixture-of-Experts (MoE), zapewniając wiodącą wydajność za ułamek kosztów.

Specjalnie zaprojektowana wszechstronność
Od wszechstronnego V3.1 po wyspecjalizowane rozumowanie R1, DeepSeek oferuje modele do każdego zadania.

Wolność zorientowana na programistę
Udostępniony na licencji permisywnej do nieograniczonego użytku komercyjnego, wspierając innowacje bez barier.

Sprawdzona wydajność
Konsekwentnie osiąga najlepsze wyniki w branżowych testach porównawczych dotyczących kodowania i rozumowania.

Praktyczna alternatywa
Zapewnia moc wiodących modeli zamkniętych przy przystępności cenowej i elastyczności rozwiązań open source.
Peak speed
Lowest cost
| Modalność | Opis |
|---|---|
| DeepSeek V3.2 | DeepSeek V3.2 to flagowy model LLM ogólnego przeznaczenia, integrujący mechanizmy rzadkiej uwagi (sparse attention) z solidnymi możliwościami przetwarzania kontekstu 163.8K; dzięki wysoce konkurencyjnym cenom bazowym służy jako kamień węgielny codziennych przepływów pracy, w tym złożonego wnioskowania ogólnego i budowania wieloetapowych Agents harmonogramowania zadań. |
| DeepSeek V3.2 Speciale | DeepSeek V3.2 Speciale jest pozycjonowany jako wysokowydajny, niestandardowy model LLM, wyposażony w ogromne okno kontekstowe 163,8K i strukturę cenową premium ($0,4 wejście / $1,2 wyjście), zaprojektowany specjalnie dla wrażliwych na opóźnienia kluczowych węzłów biznesowych wymagających najwyższej jakości wyników, takich jak inteligentna obsługa klienta dla zamożnych klientów lub analiza ilościowa na poziomie milisekund. |
| DeepSeek V3.2 Exp | DeepSeek V3.2 Exp to najnowocześniejsza wersja eksperymentalna oparta na architekturze V3.2, integrująca najnowsze funkcje algorytmiczne przy zachowaniu kontekstu 163.8K i porównywalnych kosztów. Czyni to ją idealną dla zespołów R&D prowadzących wstępne badania techniczne i testy typu canary, aby prewencyjnie zweryfikować różnicującą moc możliwości AI nowej generacji dla przyszłych produktów. |
| DeepSeek-V3.1 | DeepSeek-V3.1 to najnowsza generacja wysokowydajnych modeli ekosystemu open-source, osiągająca nową równowagę między wydajnością a kosztami w kontekście 131.1K; jako najlepszy wybór dla komercyjnych projektów wdrożeniowych, stanowi kręgosłup dla scenariuszy wymagających zarówno wysokiej jakości generowania treści, jak i kontrolowanych kosztów. |
| DeepSeek V3.1 Terminus | DeepSeek V3.1 Terminus służy jako długoterminowa, stabilna i ostateczna forma serii V3.1. DeepSeek V3.1 Terminus zachowuje identyczne parametry i ceny jak wersja standardowa, mając na celu zapewnienie trwale stabilnego stylu wyjściowego i logiki dla płynnych, skierowanych do konsumenta usług punktów końcowych (endpoint) w środowisku produkcyjnym. |
| DeepSeek-V3-0324 | DeepSeek-V3-0324 to specyficzna historyczna wersja migawkowa (snapshot) charakteryzująca się kontekstem 131,1K i najniższym dostępnym kosztem wprowadzania tekstu, stosowana głównie w utrzymaniu starszych systemów (legacy) wymagających absolutnej spójności zachowania lub w zadaniach przetwarzania wsadowego z ogromną przepustowością danych wejściowych, ale umiarkowanymi wymaganiami dotyczącymi logiki wyjściowej. |
| DeepSeek-R1-0528 | DeepSeek-R1-0528 jest pozycjonowany jako najwyższej klasy model głębokiego wnioskowania, wykorzystujący kontekst 131,1K i generujący najwyższe koszty obliczeniowe (0,55 USD/2,15 USD). Reprezentuje szczyt logicznych zdolności dialektycznych i jest wykorzystywany wyłącznie do krytycznych zadań typu "burza mózgów", takich jak złożone modelowanie matematyczne i generowanie zaawansowanej architektury kodu. |
| DeepSeek OCR | DeepSeek OCR to dedykowany wizualny multimodalny model LLM, który obsługuje dwuścieżkowe wprowadzanie obrazu i tekstu z krótkim kontekstem 8,2 tys. tokenów i bardzo niskimi kosztami użytkowania, idealnie dostosowany do scenariuszy zautomatyzowanych potoków wprowadzania danych, takich jak cyfryzacja ogromnych ilości zeskanowanych dokumentów i strukturalne wyodrębnianie danych z paragonów finansowych. |
Nowe funkcje DeepSeek LLM Models + Showcase
Połączenie zaawansowanych modeli z platformą Atlas Cloud z akceleracją GPU zapewnia niezrównaną szybkość, skalowalność i kreatywną kontrolę w generowaniu obrazów i wideo.
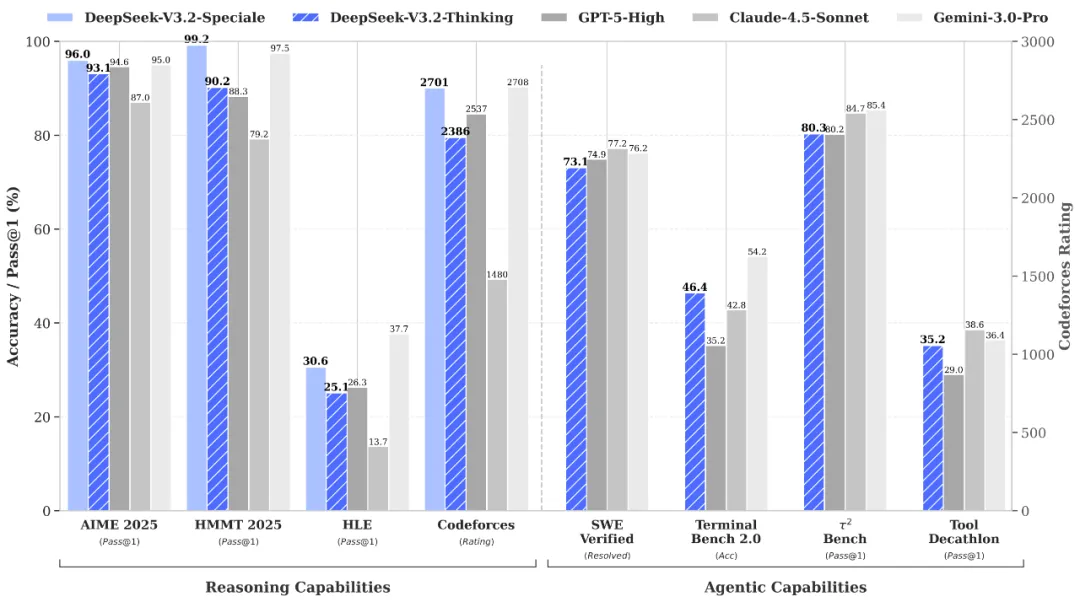
Światowej klasy rozumowanie i weryfikacja za pośrednictwem DeepSeek-V3.2-Speciale API
DeepSeek-V3.2-Speciale is the "long-thought" enhanced variant of the V3.2 architecture, integrating advanced theorem-proving capabilities from DeepSeek-Math-V2. Engineered for extreme precision, this model excels in rigorous mathematical proofing, complex logical verification, and superior instruction following, rivaling the performance of Gemini-3.0-Pro in mainstream reasoning benchmarks. It is the premier choice for academic research, automated formal verification, and high-stakes technical problem-solving where logical integrity is non-negotiable.
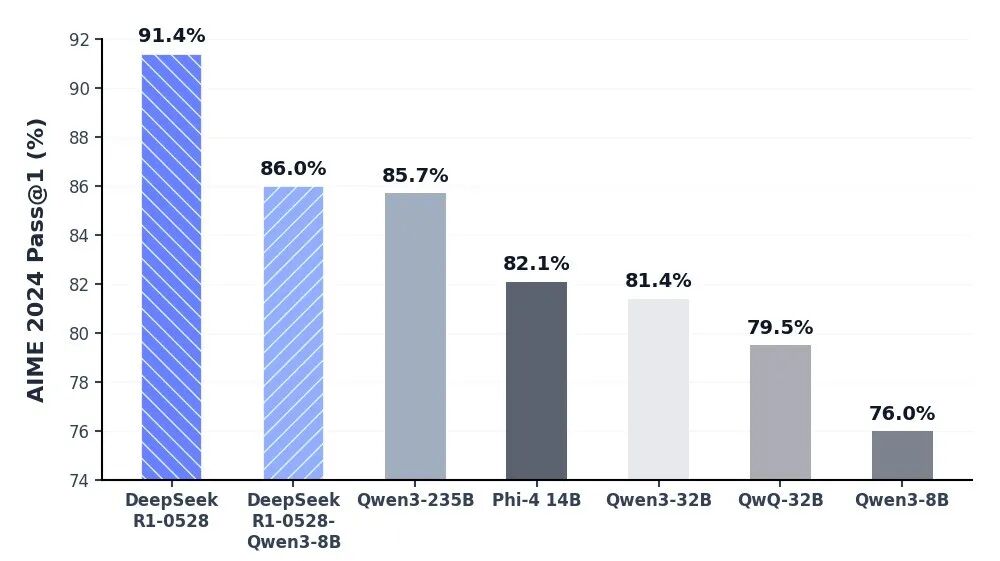
Niezrównana głębia poznawcza dzięki DeepSeek-R1 API
Model DeepSeek-R1 stoi na czele sztucznej inteligencji opartej na wnioskowaniu, zapewniając wiodącą w branży wydajność w matematyce, programowaniu i ogólnej logice. Osiągając parytet z elitarnymi światowymi modelami, takimi jak o3 od OpenAI i Gemini-2.5-Pro, R1 na nowo zdefiniował możliwości inteligencji open-source. Jest on specjalnie zoptymalizowany do zadań wymagających głębokiego myślenia, w tym złożonego tworzenia algorytmów, zaawansowanej syntezy danych i zaawansowanych procesów poznawczych wymagających wieloetapowego wnioskowania dedukcyjnego.
Płynna codzienna interakcja z przepływami pracy autonomicznych agentów przy użyciu DeepSeek V3.2 API
DeepSeek-V3.2 zapewnia idealną równowagę między głębokością rozumowania a szybkością wykonywania, zaprojektowany z myślą o obsłudze płynnych, codziennych interakcji i autonomicznych ekosystemów agentów. Dzięki znacznie zmniejszonemu opóźnieniu i zoptymalizowanej kontroli wyników, służy jako solidny silnik do orkiestracji wieloetapowych zadań i ogólnych asystentów AI. Niezależnie od tego, czy wdrażana jest automatyzacja na skalę przedsiębiorstwa, czy narzędzia interaktywne o wysokiej częstotliwości, V3.2 zapewnia płynne, wydajne i opłacalne doświadczenie użytkownika.
Rygorystyczne odkrycia naukowe i weryfikacja formalna z DeepSeek-V3.2-Speciale API
The DeepSeek-V3.2-Speciale API is engineered for tasks that demand absolute logical precision and multi-step reasoning. By integrating advanced theorem-proving capabilities, it enables researchers and engineers to execute complex mathematical inductions, verify formal logic, and solve high-tier competitive programming challenges. Perfect for academic R&D, automated code auditing, and cryptographic analysis, this API transforms abstract complexity into verifiable results with the performance of top-tier global models.
Advanced Algorithmic Synthesis & Strategic Reasoning using the DeepSeek-R1 API
DeepSeek-R1 empowers developers to build applications centered on deep cognitive workflows and strategic decision-making. Ranking at the forefront of global reasoning benchmarks, the R1 API excels in synthesizing sophisticated code architectures, processing dense technical documentation, and generating innovative solutions for open-ended logical puzzles. It is the ideal engine for AI-driven software engineering, long-form data synthesis, and any scenario where "thinking fast and slow" requires a powerful, reasoning-first foundation.
Płynna orkiestracja agentów autonomicznych za pomocą API DeepSeek-V3.2
For high-velocity, sensory-driven AI applications, the DeepSeek-V3.2 API provides the perfect equilibrium between reasoning depth and ultra-low latency. It is optimized for building autonomous Agents that can navigate multi-step workflows, manage real-time user interactions, and execute general-purpose tasks with GPT-5 level intelligence. This use case is tailor-made for enterprise-scale automation, intelligent customer ecosystems, and developers looking to deploy responsive, cost-effective AI assistants at scale.
Porównanie Modeli
Zobacz, jak wypadają modele różnych dostawców — porównaj wydajność, ceny i unikalne mocne strony, aby podjąć świadomą decyzję.
| Model | Kontekst | Maksymalne wyjście | Wejście | Pozycjonowanie |
|---|---|---|---|---|
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flagowy ogólny |
| DeepSeek V3.2 Speciale | 163.84K | 163.84K | Text | Niestandardowy o wysokiej wydajności |
| DeepSeek V3.2 Exp | 163.84K | 163.84K | Text | Kompilacja eksperymentalna |
| DeepSeek-V3.1 | 131.07K | 65.54K | Text | Szkielet open source |
| DeepSeek V3.1 Terminus | 131.07K | 65.54K | Text | Stabilny długoterminowo (LTS) |
| DeepSeek-V3-0324 | 131.07K | 32.77K | Text | Migawka historyczna |
| DeepSeek-R1-0528 | 131.07K | 131.07K | Text | Rozumowanie najwyższej klasy |
| DeepSeek OCR | 8.19K | 8.19K | Text | Dedykowany multimodalny |
| GLM-5 | 200K | 128K | Text | Flagowy model fundamentowy |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | Programowanie agentowe SOTA |
How to Use DeepSeek LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Dlaczego Używać DeepSeek LLM Models na Atlas Cloud
Połączenie zaawansowanych modeli DeepSeek LLM Models z platformą GPU-akcelerowaną Atlas Cloud zapewnia niezrównaną wydajność, skalowalność i doświadczenie deweloperskie.
Wydajność i Elastyczność
Niska Latencja:
Inferencja zoptymalizowana pod GPU dla rozumowania w czasie rzeczywistym.
Zunifikowane API:
Uruchamiaj DeepSeek LLM Models, GPT, Gemini i DeepSeek za pomocą jednej integracji.
Przejrzysta Wycena:
Przewidywalne rozliczenia za token z opcjami serverless.
Przedsiębiorstwo i Skala
Doświadczenie Dewelopera:
SDK, analityka, narzędzia dostrajania i szablony.
Niezawodność:
99,99% dostępności, RBAC i logowanie gotowe na zgodność.
Bezpieczeństwo i Zgodność:
SOC 2 Type II, zgodność z HIPAA, suwerenność danych w USA.
Często Zadawane Pytania o DeepSeek LLM Models
DeepSeek oferuje przejrzystość open-source i doskonałą efektywność kosztową. Dzięki możliwościom rozumowania (R1 i V3.2) rywalizującym z GPT-5, zapewnia wydajną, tańszą alternatywę z elastycznością prywatnego wdrażania.
Odzwierciedla to całkowitą „pojemność mózgu” modelu. Projekt MoE firmy DeepSeek łączy ogromną całkowitą liczbę parametrów (np. 671B) zapewniającą głęboką inteligencję z usprawnioną liczbą parametrów „aktywnych” w celu uzyskania maksymalnej wydajności operacyjnej.
Poznaj Więcej Rodzin
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


