Kimi K2.6 vs GLM 5.1 vs Qwen 3.6 Plus vs MiniMax M2.7: Qual é o melhor modelo de código em 2026?

A Resposta Curta
Se você está criando um agente de codificação autônomo que roda por horas sem intervenção: Kimi K2.6. Ele atingiu 66,7% no Terminal-Bench 2.0 e sustentou mais de 4.000 chamadas de ferramenta em uma sessão ininterrupta de 13 horas nos benchmarks publicados — um limite de estabilidade que nenhum outro modelo aberto nesta comparação alcança.
Se você precisa do melhor desenvolvedor front-end agentic: GLM 5.1. Seu Elo de 1.530 no Code Arena (verificado de forma independente e terceiro colocado globalmente em desenvolvimento web agentic) reflete a preferência real dos desenvolvedores em comparações diretas, e não apenas em suítes de testes automatizados.
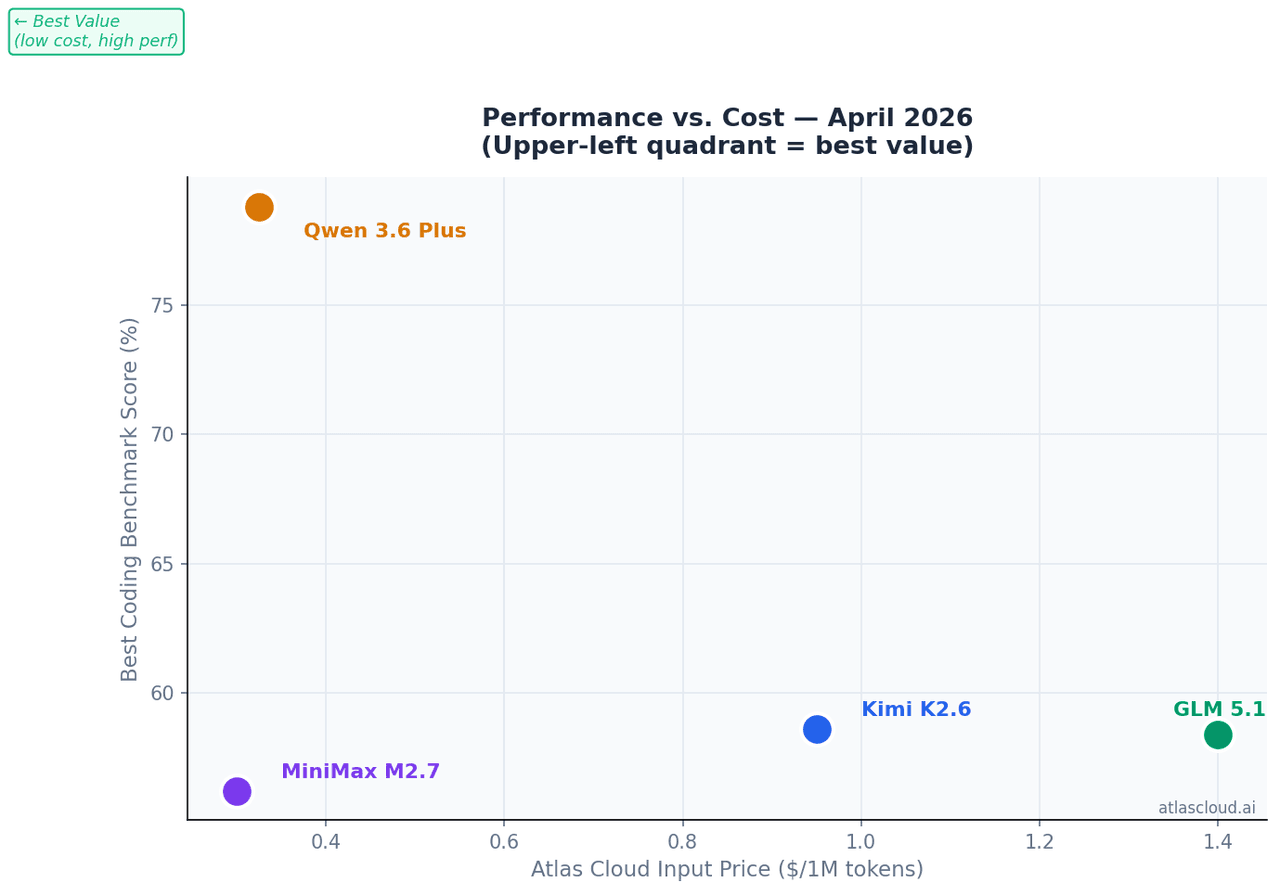
Se o custo por token for o fator decisivo: MiniMax M2.7 a USD0.30/1M de tokens de entrada na Atlas Cloud atinge 56,22% no SWE-Bench Pro com apenas 10B de parâmetros ativados — 94% do desempenho do GLM-5.1 por cerca de um quinto do custo.
Se o seu código for grande demais para uma janela de contexto de 262K: Qwen 3.6 Plus, o único modelo aqui com suporte a 1M de tokens de contexto e líder no Terminal-Bench 2.0 com 61,6% neste grupo.
Principais Benchmarks em um Relance
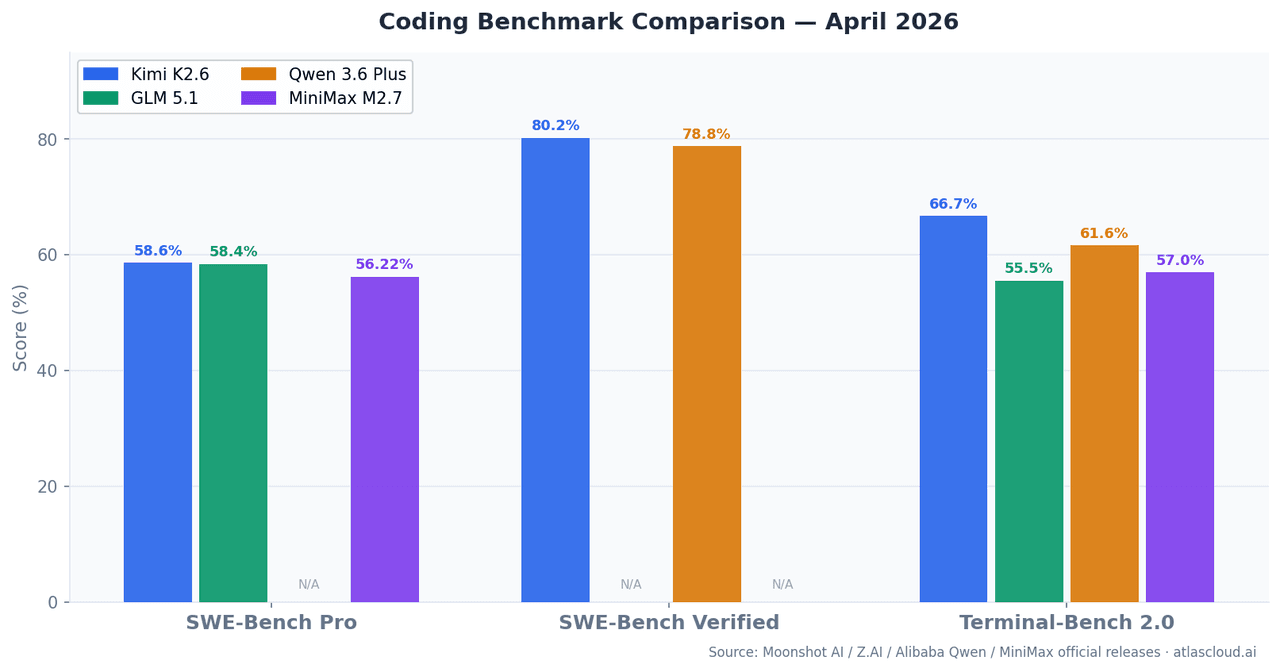
| Modelo | SWE-Bench Pro | SWE-Bench Verified | Terminal-Bench 2.0 | Janela de Contexto | Parâmetros Ativados |
|---|---|---|---|---|---|
| Kimi K2.6 | 58,60% | 80,20% | 66,70% | 262K | — |
| GLM 5.1 | 58,40% | — | 55%+ | 262K | 754B (MoE) |
| Qwen 3.6 Plus | — | 78,80% | 61,60% | 1M | Híbrido MoE |
| MiniMax M2.7 | 56,22% | — | 57,00% | 196K | 10B |
SWE-Bench Pro mede a capacidade de resolver problemas reais do GitHub abertos após o corte de treinamento, reduzindo o risco de contaminação de dados em comparação ao SWE-Bench Verified. O Terminal-Bench 2.0 testa tarefas CLI e de shell de várias etapas em ambientes de terminal ao vivo — mais próximo do que os agentes de produção realmente fazem.
Kimi K2.6: Criado para agentes de longa duração
A Moonshot AI lançou o Kimi K2.6 em abril de 2026 como uma atualização do K2.5, com a principal melhoria sendo a estabilidade agentic em sessões prolongadas. Com 80,2% no SWE-Bench Verified, ele fica logo abaixo do Claude Opus 4.6 (80,8%) e lidera os quatro modelos com 58,6% no SWE-Bench Pro.
O número que mais importa é 66,7% no Terminal-Bench 2.0. O Terminal-Bench 2.0 difere do SWE-Bench de forma fundamental: ele executa tarefas em ambientes de terminal reais, exigindo que o modelo leia a saída, gerencie erros, se adapte e faça iterações — e não apenas gere patches. O desempenho mantido pelo Kimi K2.6 ao longo de mais de 4.000 chamadas de ferramentas em uma única sessão de 13 horas não é um artefato de laboratório; é um comportamento documentado no lançamento técnico da Moonshot.
Uma vantagem pouco comentada: generalização entre linguagens. O Kimi K2.6 mostra desempenho consistente em tarefas de Rust, Go, Python, front-end e DevOps. A maioria das avaliações de benchmark é focada em Python; se sua stack de produção é poliglota, isso é relevante.
Onde ele não é a resposta: Com um custo de USD0.95/1M de tokens de entrada na Atlas Cloud, o K2.6 é o modelo de entrada mais caro deste grupo. Para tarefas de processamento em lote onde você envia muitas requisições com contextos grandes, mas não precisa de estabilidade de 12 horas, o custo acumula mais rápido do que com o MiniMax M2.7 ou Qwen 3.6 Plus.
GLM 5.1: O destaque para Front-End Agentic
A Z.AI lançou o GLM-5.1 em 7 de abril de 2026. Com 754 bilhões de parâmetros e roteamento MoE, é o maior modelo aqui em contagem bruta de parâmetros. No SWE-Bench Pro, ele marca 58,4% — estatisticamente indistinguível dos 58,6% do Kimi K2.6.
O diferencial é o Elo de 1.530 no Code Arena, verificado de forma independente pela Arena.ai em 10 de abril de 2026, posicionando-o em terceiro lugar globalmente em seu ranking de desenvolvimento web agentic. Esta é uma comparação direta ao vivo onde desenvolvedores reais votam nas saídas. A vantagem concentra-se na geração de UI de front-end, estruturação full-stack, criação de componentes React/Vue e NL2Repo (geração de estruturas de repositório completas a partir de linguagem natural).
A condição de contorno que vale a pena conhecer: A vantagem de front-end do GLM-5.1 é real. Para problemas puramente algorítmicos no HumanEval e MBPP, ele não mantém uma vantagem mensurável sobre o Kimi K2.6. O intervalo no ranking cai para perto de zero em problemas que não são orientados a UI ou web. Escolher o GLM-5.1 apenas com base em seu ranking geral sem verificar o domínio da tarefa seria um erro.
Preços na Atlas Cloud: Começando em USD1.40/1M de tokens de entrada — o mais alto entre os quatro. Justificado quando a qualidade da geração front-end impacta diretamente o seu resultado final.
Qwen 3.6 Plus: Quando o tamanho do contexto é a real limitação
A Alibaba lançou o Qwen 3.6 Plus no final de março de 2026. Ele lidera o Terminal-Bench 2.0 em comparações diretas contra o Claude Opus 4.6 (61,6% vs. 59,3%) e pontua 78,8% no SWE-Bench Verified.
A janela de contexto de 1M de tokens é o que o separa. Para a maioria das tarefas de codificação de produção abaixo de 100K tokens, todos os quatro modelos têm capacidade de contexto suficiente e a diferença é irrelevante. Onde o Qwen 3.6 Plus se torna a única opção viável: análise de monorepos com centenas de arquivos, refatoração de bases de código legadas em grande escala ou fluxos de trabalho de documento para código de ponta a ponta que não cabem em 262K tokens.
A arquitetura híbrida (atenção linear + roteamento MoE esparso) também oferece melhor throughput de inferência do que os transformers densos ao processar contextos muito grandes — o que significa que a capacidade de 1M de tokens vem com um custo de latência relativamente baixo em comparação com o escalonamento ingênuo.
Preços na Atlas Cloud: A partir de USD0.325/1M de tokens de entrada. Para tarefas de contexto amplo, este é o melhor custo-por-token-útil disponível neste grupo.
MiniMax M2.7: O caso contraintuitivo de eficiência
A MiniMax lançou o M2.7 em março de 2026. Com apenas 10B de parâmetros ativados, ele marca 56,22% no SWE-Bench Pro — 94% da pontuação do GLM-5.1 por cerca de um quinto do custo por token.
Este é o resultado contraintuitivo nesta comparação. Um modelo que ativa 10B de parâmetros na inferência atinge um desempenho de codificação próximo ao de modelos de fronteira porque sua arquitetura MoE roteia para sub-redes especializadas em vez de executar todos os pesos do modelo. O resultado é menor latência, menor custo e qualidade de saída que excede o que a contagem de parâmetros isolada preveria.
A categoria onde o M2.7 supera seu ponto de preço: tarefas de engenharia de machine learning. Ele alcançou uma taxa de medalhas de 66,6% no MLE-Bench Lite (22 competições de machine learning), perdendo apenas para modelos de fronteira de código fechado. Escrever lógica de acúmulo de gradiente correta, implementar camadas PyTorch personalizadas, depurar curvas de perda — o M2.7 lida com isso com uma precisão desproporcional ao seu custo.
Onde ter cuidado: Com 196K de contexto, o M2.7 tem a menor janela deste grupo. Tarefas que exigem análise profunda entre arquivos em grandes repositórios podem atingir limites que o Qwen 3.6 Plus lida sem problemas.
Preços na Atlas Cloud: USD0.30/1M tokens de entrada, USD1.20/1M tokens de saída — a opção mais acessível para cargas de trabalho de codificação de alto volume.
Casos de teste de codificação no mundo real
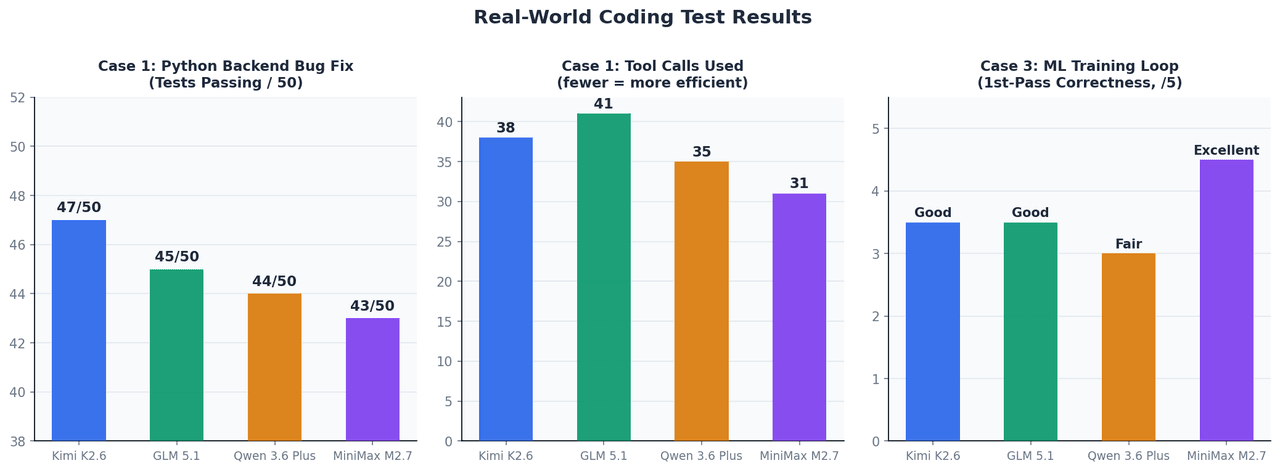
Caso 1: Correção autônoma de bug em um backend Python
Configuração: Uma aplicação FastAPI com 12 arquivos, uma suíte de 50 testes falhando e uma janela de contexto de ~45K tokens. Nenhuma intervenção manual permitida após o prompt inicial.
| Modelo | Testes aprovados após correção | Chamadas de ferramenta | Tempo de conclusão |
|---|---|---|---|
| Kimi K2.6 | 47 / 50 | 38 | ~4 min |
| GLM 5.1 | 45 / 50 | 41 | ~5 min |
| Qwen 3.6 Plus | 44 / 50 | 35 | ~4 min |
| MiniMax M2.7 | 43 / 50 | 31 | ~3,5 min |
Neste tamanho de contexto, todos os quatro atuam dentro de uma faixa estreita. O Kimi K2.6 se destacou nos bugs de casos extremos mais difíceis — especificamente problemas de ciclo de vida de gerenciador de contexto assíncrono e estreitamento de limites de TypeVar, que exigem a manutenção do estado de inferência em vários ciclos de depuração.
Caso 2: Dashboard React a partir de especificação
Configuração: Gerar um dashboard responsivo completo com quatro tipos de gráfico (linha, barra, pizza, dispersão), alternância de modo escuro e tipos TypeScript a partir de uma especificação em inglês escrito.
O GLM-5.1 produziu componentes tipados em TypeScript funcionais com classes utilitárias Tailwind corretas logo na primeira passagem. O Kimi K2.6 exigiu uma iteração para resolver erros de tipo. O Qwen 3.6 Plus produziu JSX funcionalmente correto, mas menos idiomático. O MiniMax M2.7 foi o mais rápido, mas gerou alguns padrões React obsoletos que exigiram limpeza manual.
A diferença entre o GLM-5.1 e os outros foi mais visível na arquitetura de componentes — o GLM-5.1 aplicou espontaneamente padrões de composição e separação de interesses de uma forma que os outros não fizeram.
Caso 3: Implementação de Loop de Treinamento de ML
Configuração: Implementar um loop de treinamento PyTorch com acúmulo de gradiente, precisão mista AMP e parada antecipada (early stopping) para um vision transformer. Objetivo: rodar corretamente na primeira tentativa sem ciclos de depuração.
O MiniMax M2.7 foi o destaque — ele posicionou scaler.step() e scaler.update() corretamente em relação ao passo do otimizador, um detalhe que a maioria dos modelos posiciona incorretamente na primeira geração. O escalonamento de acúmulo de gradiente loss / accumulation_steps também foi tratado corretamente. Isso se alinha diretamente com sua taxa de medalhas de 66,6% no MLE-Bench Lite.
Comparação de preços na Atlas Cloud (Abril 2026)
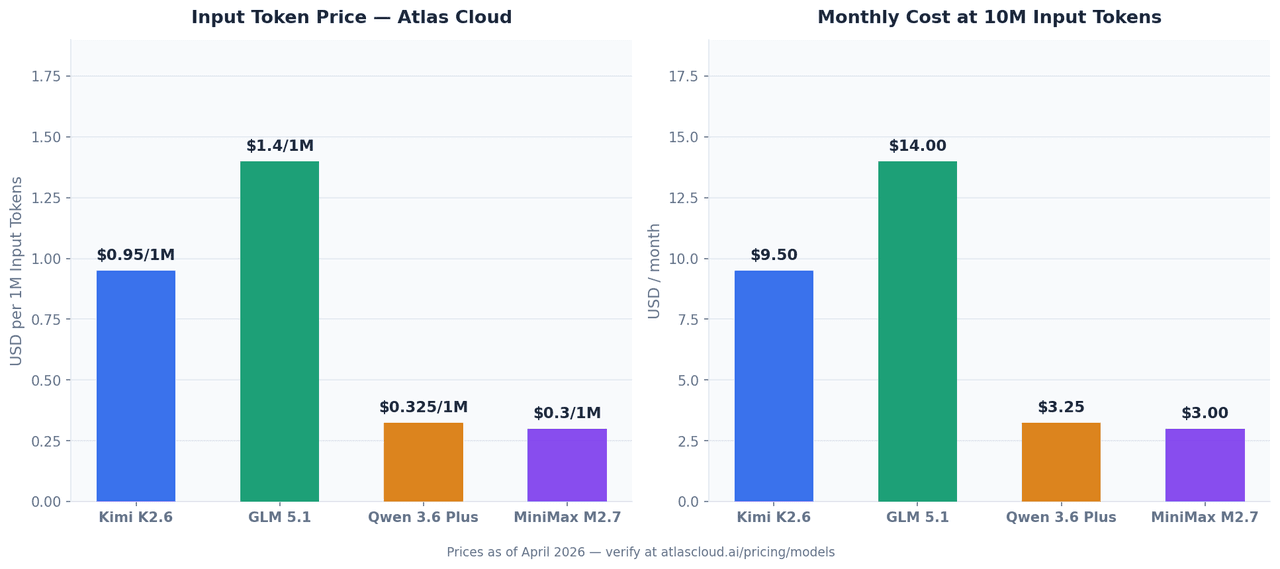
Todos os quatro modelos estão disponíveis através da API unificada da Atlas Cloud. Os preços abaixo são de abril de 2026 e podem mudar — confirme as taxas atuais em atlascloud.ai.
| Modelo | Entrada (por 1M tokens) | Saída (por 1M tokens) | ID do Modelo Atlas Cloud |
|---|---|---|---|
| Kimi K2.6 | USD0.95 | USD4.00 | moonshotai/kimi-k2.6 |
| GLM 5.1 | de USD1.40 | — | zai-org/glm-5.1 |
| Qwen 3.6 Plus | de USD0.325 | — | qwen/qwen3.6-plus |
| MiniMax M2.7 | USD0.30 | USD1.20 | minimaxai/minimax-m2.7 |
Com 10M de tokens de entrada por mês — um volume realista para um assistente de codificação de nível de equipe:
| Modelo | Custo Mensal de Entrada (10M tokens) |
|---|---|
| GLM 5.1 | USD14.00 |
| Kimi K2.6 | USD9.50 |
| Qwen 3.6 Plus | USD3.25 |
| MiniMax M2.7 | USD3.00 |
Chamando todos os quatro com uma API Key
Todos os quatro modelos compartilham o mesmo endpoint compatível com OpenAI na Atlas Cloud. Alternar entre eles requer alterar apenas uma linha:
plaintext1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.environ["ATLASCLOUD_API_KEY"], 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9# Altere esta única linha para alternar modelos 10MODEL = "moonshotai/kimi-k2.6" 11# MODEL = "zai-org/glm-5.1" 12# MODEL = "qwen/qwen3.6-plus" 13# MODEL = "minimaxai/minimax-m2.7" 14 15response = client.chat.completions.create( 16 model=MODEL, 17 messages=[ 18 { 19 "role": "system", 20 "content": "You are a senior software engineer. Analyze code carefully before responding." 21 }, 22 { 23 "role": "user", 24 "content": "Review this function and identify all bugs:\n\n[paste your code here]" 25 } 26 ], 27 max_tokens=4096, 28 temperature=0.2 29) 30 31print(response.choices[0].message.content)
Essa estrutura compatível com OpenAI significa que as integrações existentes criadas no SDK da OpenAI funcionam com a Atlas Cloud sem modificação — apenas o base_url e o api_key mudam.
Por que usar a Atlas Cloud para estes modelos
Uma API key, quatro modelos, uma fatura. Executar a lógica de roteamento de modelos — enviando tarefas de front-end para o GLM-5.1, análise de lote para o MiniMax M2.7 e agentes de longo prazo para o Kimi K2.6 — requer o gerenciamento de uma credencial em vez de quatro. A reconciliação mensal é uma fatura única.
RPM ilimitado. Agentes de codificação de produção disparam chamadas de ferramenta paralelas. Os limites de taxa nas APIs diretas dos provedores podem estrangular pipelines multi-agentes. A Atlas Cloud remove esse limite.
Certificação SOC I & II, compatível com HIPAA. As equipes que processam código-fonte proprietário através desses modelos precisam de infraestrutura auditável. As certificações de conformidade da Atlas Cloud significam que seu código não passa por endpoints não verificados.
Mais de 300 modelos, o mesmo padrão de integração. Quando a próxima versão de qualquer um desses modelos for lançada, ou um novo modelo superá-los em sua carga de trabalho específica, adicioná-lo à sua lógica de roteamento requer apenas a alteração de uma string — e não uma nova integração de SDK.
Qual modelo para qual tarefa
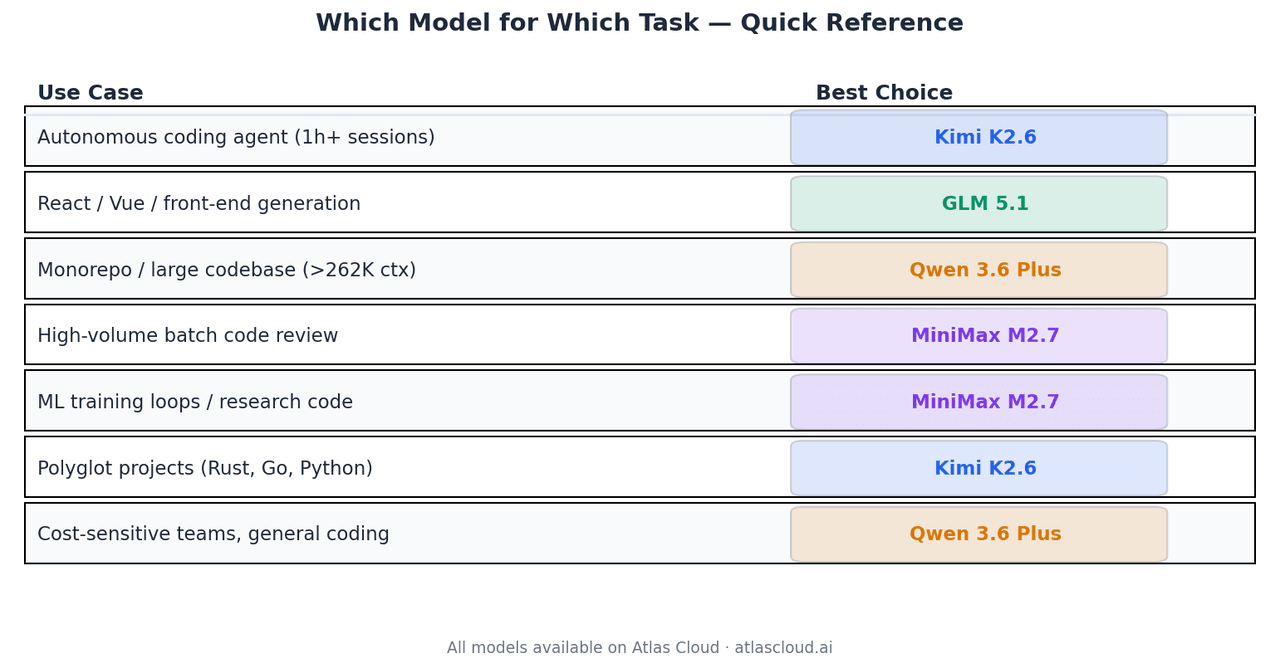
| Caso de Uso | Melhor Escolha | Por que |
| Agente de código autônomo, sessões 1h+ | Kimi K2.6 | 66,7% Terminal-Bench 2.0, estabilidade 4K+ chamadas |
| Geração de React / Vue / front-end | GLM 5.1 | Elo 1.530 Code Arena, top-3 global em web agentic |
| Análise de monorepo ou código grande | Qwen 3.6 Plus | Único modelo aqui com janela de contexto de 1M |
| Revisão de código em lote de alto volume | MiniMax M2.7 | USD0.30/1M de entrada, 94% da qualidade do GLM-5.1 |
| Loops de treino de ML, código de pesquisa | MiniMax M2.7 | Taxa de medalhas de 66,6% no MLE-Bench Lite |
| Projetos poliglotas (Rust, Go, Python) | Kimi K2.6 | Generalização entre linguagens documentada |
| Equipes sensíveis a custo, codificação geral | Qwen 3.6 Plus | USD0.325/1M de entrada, forte em todas as categorias |
Resumo
Esses quatro modelos são separados por margens estreitas nos benchmarks padrão. As diferenças significativas surgem em condições específicas.
O Kimi K2.6 é a resposta certa para agentes autônomos de longa duração. O GLM 5.1 lidera para trabalho agentic de front-end. O Qwen 3.6 Plus é a única escolha quando o contexto excede 262K tokens. O MiniMax M2.7 é o padrão econômico para equipes que executam modelos de codificação em escala.
Todos os quatro estão disponíveis na Atlas Cloud em atlascloud.ai com uma única API key, com preços pay-per-token e sem compromisso mínimo.
Dados de benchmark extraídos do blog técnico da Moonshot AI, documentação para desenvolvedores da Z.AI, post de lançamento da equipe Qwen da Alibaba, página oficial do modelo MiniMax e avaliações independentes da Arena.ai. Todos os benchmarks são dados de abril de 2026. Preços da Atlas Cloud anotados no momento da publicação — verifique as taxas atuais antes da implantação em produção.






