DeepSeek LLM Models
DeepSeek, developed by the deepseek-ai team, is a cutting-edge series of open-source generative AI models engineered to democratize access to high-performance computing through a cost-effective and efficiency-first strategy. Its flagship reasoning model, DeepSeek-R1, made waves by rivaling top-tier proprietary models in mathematics, programming, and complex logical deduction, while the DeepSeek-V3.2, is designed for seamless daily interaction and autonomous Agent workflows. By significantly lowering the barrier to entry for advanced AI, DeepSeek has become a cornerstone for the "vibe coding" movement and a transformative tool in specialized fields like academic research and high-level technical problem-solving.
Explorar Modelos Líderes
O Atlas Cloud oferece os modelos criativos mais avançados e inovadores do setor.
O Que Faz DeepSeek LLM Models Se Destacar
Atlas Cloud fornece os modelos criativos líderes da indústria mais recentes.

Potência Aberta
Modelos de primeira linha totalmente open-source, garantindo transparência e controle.

Eficiência arquitetural
Utiliza a avançada tecnologia Mixture-of-Experts (MoE) para um desempenho líder a uma fração do custo.

Versatilidade projetada especificamente
Do versátil V3.1 ao raciocínio especializado do R1, a DeepSeek oferece modelos para todas as tarefas.

Liberdade centrada no desenvolvedor
Licenciado permissivamente para uso comercial irrestrito, promovendo a inovação sem barreiras.

Desempenho comprovado
Alcança consistentemente resultados de estado da arte em benchmarks da indústria para programação e raciocínio.

A alternativa prática
Oferece a potência dos principais modelos proprietários com a acessibilidade e a flexibilidade do código aberto.
Peak speed
Lowest cost
| Modalidade | Descrição |
|---|---|
| DeepSeek V3.2 | O DeepSeek V3.2 é um LLM emblemático de uso geral, integrando mecanismos de atenção esparsa com robustas capacidades de processamento de contexto de 163.8K; com preços base altamente competitivos, serve como a pedra angular para fluxos de trabalho diários, incluindo raciocínio geral complexo e a construção de Agents de agendamento de tarefas em várias etapas. |
| DeepSeek V3.2 Speciale | O DeepSeek V3.2 Speciale posiciona-se como um LLM personalizado de alto desempenho, apresentando uma enorme janela de contexto de 163.8K e uma estrutura de preços escalonada premium ($0.4 entrada / $1.2 saída), especificamente projetado para nós de negócios essenciais sensíveis à latência que exigem qualidade de saída definitiva, como atendimento inteligente ao cliente para clientes de alto patrimônio ou análise quantitativa em nível de milissegundo. |
| DeepSeek V3.2 Exp | O DeepSeek V3.2 Exp é uma versão experimental de ponta baseada na arquitetura V3.2, integrando os mais recentes recursos algorítmicos enquanto mantém um contexto de 163.8K e custos comparáveis, tornando-o ideal para equipes de P&D que realizam pré-pesquisa técnica e testes canary para validar preventivamente o poder diferenciador das capacidades de IA de próxima geração para produtos futuros. |
| DeepSeek-V3.1 | O DeepSeek-V3.1 é a mais recente geração de modelos de ecossistema de código aberto de alto desempenho, alcançando um novo equilíbrio entre desempenho e custo dentro de um contexto de 131.1K; como a principal escolha para projetos de implementação comercial, atua como a espinha dorsal para cenários que exigem tanto geração de alta qualidade quanto custos controláveis. |
| DeepSeek V3.1 Terminus | O DeepSeek V3.1 Terminus serve como a forma definitiva e estável a longo prazo da série V3.1. O DeepSeek V3.1 Terminus mantém parâmetros e preços idênticos à versão padrão, visando fornecer um estilo de saída e lógica perpetuamente estáveis para serviços de endpoint em ambientes de produção contínuos e voltados ao consumidor. |
| DeepSeek-V3-0324 | DeepSeek-V3-0324 é uma versão de snapshot histórico específica que apresenta um contexto de 131.1K e o menor custo de entrada de texto disponível, aplicada principalmente na manutenção de sistemas legados que exigem consistência comportamental absoluta, ou tarefas de processamento em lote com rendimento de entrada massivo, mas requisitos de lógica de saída moderados. |
| DeepSeek-R1-0528 | O DeepSeek-R1-0528 posiciona-se como um modelo de raciocínio profundo de topo, utilizando um contexto de 131.1K e exigindo o custo computacional mais elevado ($0.55/$2.15), representando o auge das capacidades dialéticas lógicas, utilizado exclusivamente para tarefas críticas de "brainstorming", como modelação matemática complexa e geração de arquitetura de código avançada. |
| DeepSeek OCR | O DeepSeek OCR é um LLM multimodal visual dedicado que suporta entrada de via dupla imagem-texto com um contexto curto de 8.2K e custos de uso ultrabaixos, perfeitamente adaptado para cenários de pipeline de entrada de dados automatizada, como a digitalização de documentos digitalizados massivos e extração estruturada de recibos financeiros. |
Novos recursos de DeepSeek LLM Models + Showcase
A combinação de modelos avançados com a plataforma acelerada por GPU do Atlas Cloud oferece velocidade, escalabilidade e controle criativo incomparáveis para geração de imagens e vídeos.
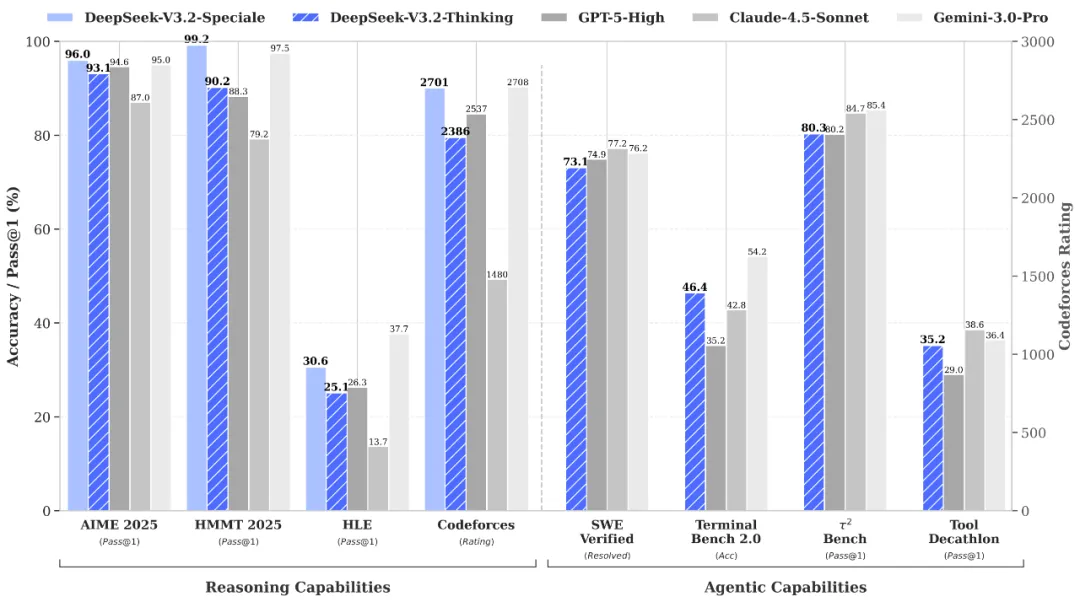
Raciocínio e Verificação de Classe Mundial via API DeepSeek-V3.2-Speciale
DeepSeek-V3.2-Speciale is the "long-thought" enhanced variant of the V3.2 architecture, integrating advanced theorem-proving capabilities from DeepSeek-Math-V2. Engineered for extreme precision, this model excels in rigorous mathematical proofing, complex logical verification, and superior instruction following, rivaling the performance of Gemini-3.0-Pro in mainstream reasoning benchmarks. It is the premier choice for academic research, automated formal verification, and high-stakes technical problem-solving where logical integrity is non-negotiable.
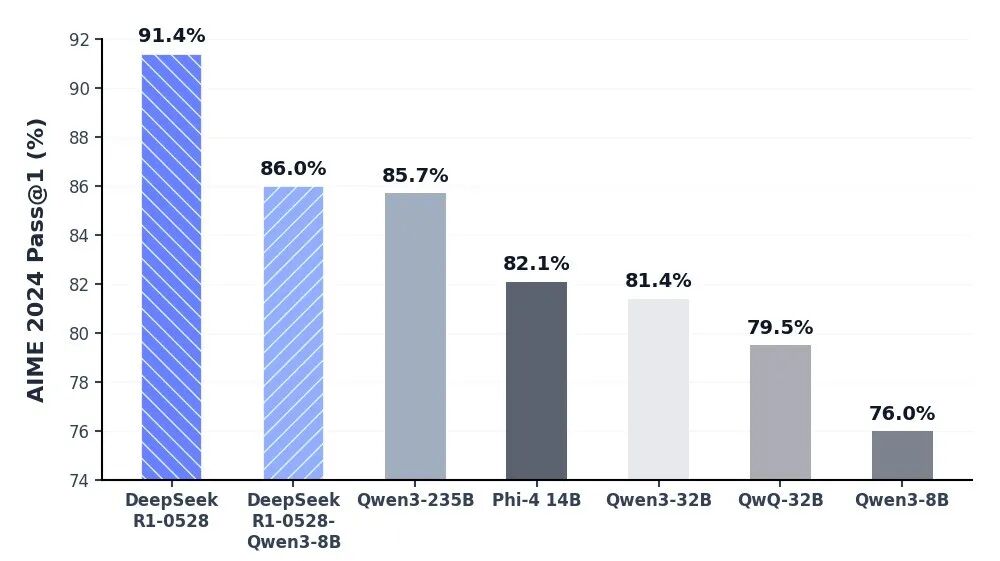
Profundidade cognitiva inigualável via DeepSeek-R1 API
O modelo DeepSeek-R1 está na vanguarda da IA de raciocínio, oferecendo desempenho líder do setor em matemática, programação e lógica geral. Ao alcançar a paridade com modelos globais de elite, como o o3 da OpenAI e o Gemini-2.5-Pro, o R1 redefiniu as capacidades da inteligência de código aberto. Ele é otimizado especificamente para tarefas de pensamento profundo, incluindo desenvolvimento algorítmico complexo, síntese de dados sofisticada e fluxos de trabalho cognitivos avançados que exigem raciocínio dedutivo em vários estágios.
Interação diária fluida com fluxos de trabalho de agentes autônomos usando a API DeepSeek V3.2
O DeepSeek-V3.2 atinge o equilíbrio perfeito entre profundidade de raciocínio e velocidade de execução, projetado para alimentar interações diárias contínuas e ecossistemas de agentes autônomos. Com latência significativamente reduzida e controle de saída otimizado, ele serve como um motor robusto para orquestração de tarefas em várias etapas e assistentes de IA de uso geral. Seja na implementação de automação em escala empresarial ou ferramentas interativas de alta frequência, o V3.2 garante uma experiência de usuário fluida, eficiente e econômica.
Descoberta Científica Rigorosa e Verificação Formal com DeepSeek-V3.2-Speciale API
The DeepSeek-V3.2-Speciale API is engineered for tasks that demand absolute logical precision and multi-step reasoning. By integrating advanced theorem-proving capabilities, it enables researchers and engineers to execute complex mathematical inductions, verify formal logic, and solve high-tier competitive programming challenges. Perfect for academic R&D, automated code auditing, and cryptographic analysis, this API transforms abstract complexity into verifiable results with the performance of top-tier global models.
Advanced Algorithmic Synthesis & Strategic Reasoning using the DeepSeek-R1 API
DeepSeek-R1 empowers developers to build applications centered on deep cognitive workflows and strategic decision-making. Ranking at the forefront of global reasoning benchmarks, the R1 API excels in synthesizing sophisticated code architectures, processing dense technical documentation, and generating innovative solutions for open-ended logical puzzles. It is the ideal engine for AI-driven software engineering, long-form data synthesis, and any scenario where "thinking fast and slow" requires a powerful, reasoning-first foundation.
Orquestração perfeita de agentes autônomos com a API DeepSeek-V3.2
For high-velocity, sensory-driven AI applications, the DeepSeek-V3.2 API provides the perfect equilibrium between reasoning depth and ultra-low latency. It is optimized for building autonomous Agents that can navigate multi-step workflows, manage real-time user interactions, and execute general-purpose tasks with GPT-5 level intelligence. This use case is tailor-made for enterprise-scale automation, intelligent customer ecosystems, and developers looking to deploy responsive, cost-effective AI assistants at scale.
Comparação de Modelos
Veja como os modelos de diferentes provedores se comparam — compare desempenho, preços e pontos fortes exclusivos para tomar uma decisão informada.
| Modelo | Contexto | Saída máxima | Entrada | Posicionamento |
|---|---|---|---|---|
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Geral de Referência |
| DeepSeek V3.2 Speciale | 163.84K | 163.84K | Text | Personalizado de alto desempenho |
| DeepSeek V3.2 Exp | 163.84K | 163.84K | Text | Compilação experimental |
| DeepSeek-V3.1 | 131.07K | 65.54K | Text | Backbone de código aberto |
| DeepSeek V3.1 Terminus | 131.07K | 65.54K | Text | Estável a Longo Prazo (LTS) |
| DeepSeek-V3-0324 | 131.07K | 32.77K | Text | Instantâneo histórico |
| DeepSeek-R1-0528 | 131.07K | 131.07K | Text | Raciocínio de alto nível |
| DeepSeek OCR | 8.19K | 8.19K | Text | Multimodal dedicado |
| GLM-5 | 200K | 128K | Text | Modelo de fundação principal |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | Codificação agêntica SOTA |
How to Use DeepSeek LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Por Que Usar DeepSeek LLM Models no Atlas Cloud
Combine modelos avançados de DeepSeek LLM Models com a plataforma acelerada por GPU do Atlas Cloud, fornecendo desempenho, escalabilidade e experiência de desenvolvimento incomparáveis.
Desempenho e Flexibilidade
Baixa Latência:
Inferência otimizada por GPU para respostas em tempo real.
API Unificada:
Uma única integração para acessar DeepSeek LLM Models, GPT, Gemini e DeepSeek.
Preços Transparentes:
Faturamento por Token, suporta modo Serverless.
Empresa e Escala
Experiência do Desenvolvedor:
SDK, análise de dados, ferramentas de ajuste fino e modelos tudo em um.
Confiabilidade:
99.99% de disponibilidade, controle de permissões RBAC, logs de conformidade.
Segurança e Conformidade:
Certificação SOC 2 Type II, conformidade HIPAA, soberania de dados nos EUA.
Perguntas Frequentes sobre DeepSeek LLM Models
O DeepSeek oferece transparência de código aberto e eficiência de custos superior. Com capacidades de raciocínio (R1 e V3.2) que rivalizam com o GPT-5, proporciona uma alternativa de alto desempenho e menor custo com a flexibilidade da implantação privada.
Isso reflete a "capacidade cerebral" total do modelo. O design MoE da DeepSeek combina uma contagem total massiva de parâmetros (por exemplo, 671B) para inteligência profunda com uma contagem "ativa" otimizada para máxima eficiência operacional.
Explorar Mais Séries
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


