DeepSeek LLM Models
DeepSeek, developed by the deepseek-ai team, is a cutting-edge series of open-source generative AI models engineered to democratize access to high-performance computing through a cost-effective and efficiency-first strategy. Its flagship reasoning model, DeepSeek-R1, made waves by rivaling top-tier proprietary models in mathematics, programming, and complex logical deduction, while the DeepSeek-V3.2, is designed for seamless daily interaction and autonomous Agent workflows. By significantly lowering the barrier to entry for advanced AI, DeepSeek has become a cornerstone for the "vibe coding" movement and a transformative tool in specialized fields like academic research and high-level technical problem-solving.
Utforska de Ledande Modellerna
Atlas Cloud förser dig med de senaste branschledande kreativa modellerna.
Vad Som Gör DeepSeek LLM Models Unik
Atlas Cloud ger dig de senaste branschledande kreativa modellerna.

Öppen Kraft
Förstklassiga modeller som är helt open source, vilket garanterar transparens och kontroll.

Arkitektonisk effektivitet
Använder avancerad Mixture-of-Experts (MoE) för ledande prestanda till en bråkdel av kostnaden.

Ändamålsenlig mångsidighet
Från den mångsidiga V3.1 till det specialiserade resonemanget hos R1 erbjuder DeepSeek modeller för varje uppgift.

Utvecklarorienterad frihet
Permissivt licensierad för obegränsad kommersiell användning, vilket främjar innovation utan hinder.

Beprövad prestanda
Uppnår konsekvent toppresultat i branschstandarder för kodning och resonemang.

Det praktiska alternativet
Levererar kraften hos ledande proprietära modeller med prisvärdheten och flexibiliteten hos open source.
Peak speed
Lowest cost
| Modalitet | Beskrivning |
|---|---|
| DeepSeek V3.2 | DeepSeek V3.2 är en ledande LLM för allmänna ändamål, som integrerar glesa uppmärksamhetsmekanismer (sparse attention) med robusta 163.8K kontextbehandlingsfunktioner; med mycket konkurrenskraftiga baspriser fungerar den som hörnstenen för dagliga arbetsflöden, inklusive komplexa allmänna resonemang och byggande av flerstegs schemaläggnings-Agents. |
| DeepSeek V3.2 Speciale | DeepSeek V3.2 Speciale positioneras som en högpresterande anpassad LLM, med ett massivt kontextfönster på 163,8K och en premium-nivå prissättningsstruktur ($0,4 input / $1,2 output), specifikt utformad för latenskänsliga kärnverksamhetsnoder som kräver ultimat utdatakvalitet, såsom intelligent kundtjänst för förmögna kunder eller kvantitativ analys på millisekunder. |
| DeepSeek V3.2 Exp | DeepSeek V3.2 Exp är en banbrytande experimentell version baserad på V3.2-arkitekturen, som integrerar de senaste algoritmiska funktionerna samtidigt som den behåller en kontext på 163.8K och jämförbara kostnader. Detta gör den idealisk för FoU-team som utför teknisk förforskning och canary-tester för att i förebyggande syfte validera den differentierande kraften hos nästa generations AI-kapacitet för framtida produkter. |
| DeepSeek-V3.1 | DeepSeek-V3.1 är den senaste generationen av högpresterande open source-ekosystemmodeller, som uppnår en ny balans mellan prestanda och kostnad inom en 131.1K-kontext; som det främsta valet för kommersiella implementeringsprojekt fungerar den som ryggraden för scenarier som kräver både högkvalitativ generering och kontrollerbara kostnader. |
| DeepSeek V3.1 Terminus | DeepSeek V3.1 Terminus fungerar som den långsiktigt stabila, ultimata formen av V3.1-serien. DeepSeek V3.1 Terminus behåller identiska parametrar och prissättning som standardversionen, med syftet att tillhandahålla en ständigt stabil utdatastil och logik för sömlösa, konsumentinriktade slutpunktstjänster i produktionsmiljö. |
| DeepSeek-V3-0324 | DeepSeek-V3-0324 är en specifik historisk ögonblicksbildsversion med en kontext på 131,1K och den lägsta tillgängliga textinmatningskostnaden, främst tillämpad vid underhåll av äldre system som kräver absolut beteendekonsekvens, eller batchbearbetningsuppgifter med massiv inmatningsgenomströmning men måttliga krav på utdatalogik. |
| DeepSeek-R1-0528 | DeepSeek-R1-0528 positioneras som en förstklassig modell för djupgående resonemang, med en kontext på 131,1K och den högsta beräkningskostnaden ($0,55/$2,15). Den representerar höjdpunkten av logisk dialektisk förmåga och används uteslutande för kritiska "brainstorming"-uppgifter som komplex matematisk modellering och generering av avancerad kodarkitektur. |
| DeepSeek OCR | DeepSeek OCR är en dedikerad visuell multimodal LLM som stöder dubbelspårig bild-textinmatning med en kort 8,2K-kontext och ultralåga användningskostnader, perfekt anpassad för scenarier med automatiserade datainmatningsflöden såsom digitalisering av massiva skannade dokument och strukturerad extrahering av finansiella kvitton. |
Nya funktioner för DeepSeek LLM Models + Showcase
Kombinationen av avancerade modeller med Atlas Clouds GPU-accelererade plattform ger oöverträffad hastighet, skalbarhet och kreativ kontroll för bild- och videogenerering.
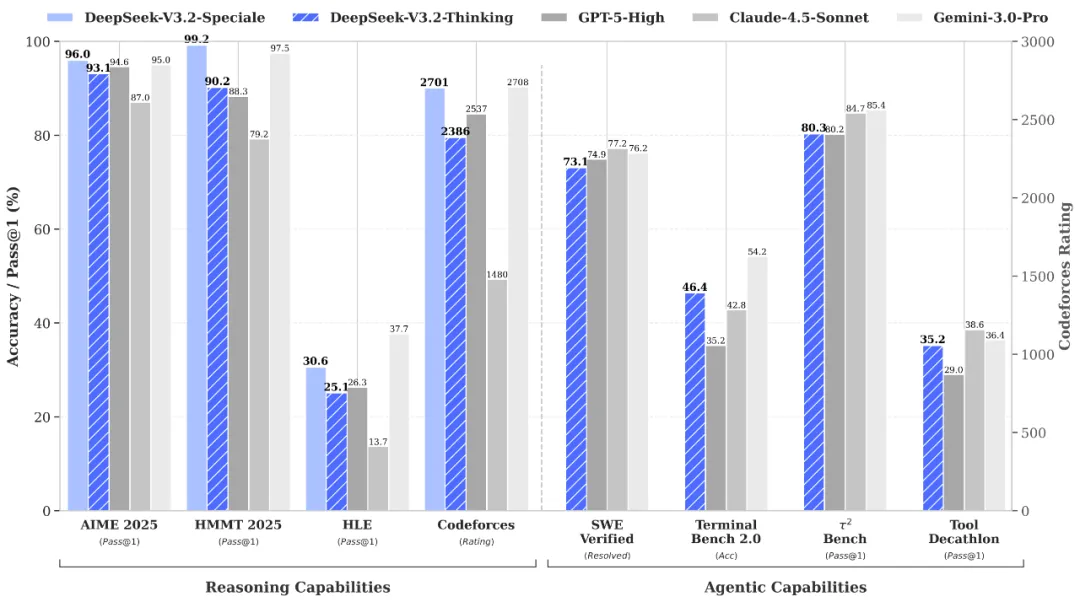
Resonemang och verifiering i världsklass via DeepSeek-V3.2-Speciale API
DeepSeek-V3.2-Speciale is the "long-thought" enhanced variant of the V3.2 architecture, integrating advanced theorem-proving capabilities from DeepSeek-Math-V2. Engineered for extreme precision, this model excels in rigorous mathematical proofing, complex logical verification, and superior instruction following, rivaling the performance of Gemini-3.0-Pro in mainstream reasoning benchmarks. It is the premier choice for academic research, automated formal verification, and high-stakes technical problem-solving where logical integrity is non-negotiable.
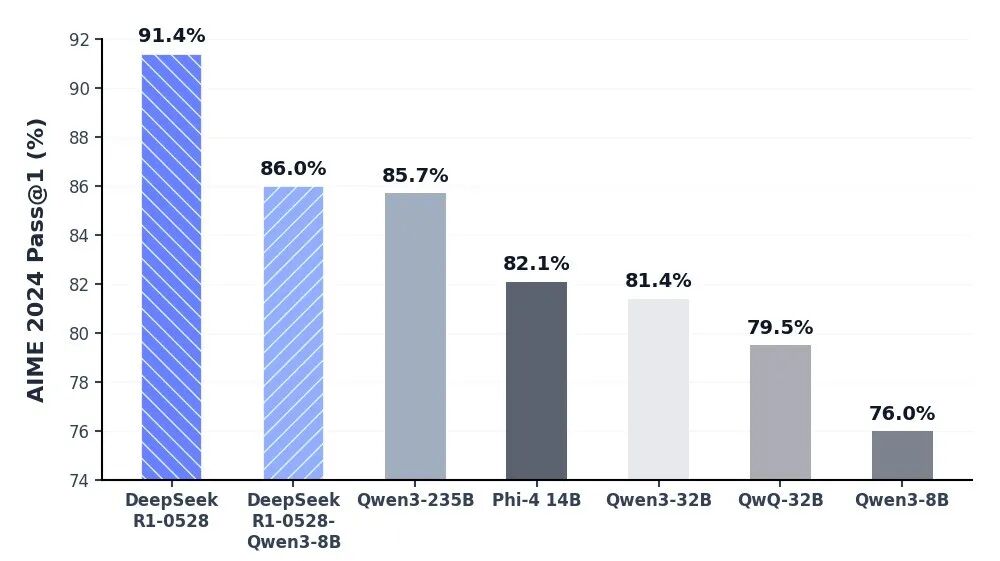
Oöverträffat kognitivt djup via DeepSeek-R1 API
Modellen DeepSeek-R1 står i framkant inom resonerande AI och levererar branschledande prestanda inom matematik, programmering och allmän logik. Genom att uppnå paritet med globala elitmodeller som OpenAI:s o3 och Gemini-2.5-Pro har R1 omdefinierat kapaciteten för intelligens med öppen källkod. Den är specifikt optimerad för uppgifter som kräver djupt tänkande, inklusive komplex algoritmutveckling, sofistikerad datasyntes och avancerade kognitiva arbetsflöden som kräver deduktivt resonemang i flera steg.
Sömlös daglig interaktion med autonoma agent-arbetsflöden med hjälp av DeepSeek V3.2 API
DeepSeek-V3.2 träffar den perfekta balansen mellan resonemangsdjup och exekveringshastighet, designad för att driva sömlösa dagliga interaktioner och autonoma agent-ekosystem. Med avsevärt minskad latens och optimerad utdatakontroll fungerar den som en robust motor för orkestrering av flerstegsuppgifter och generella AI-assistenter. Oavsett om det gäller implementering av automation i företagsskala eller högfrekventa interaktiva verktyg, säkerställer V3.2 en flytande, effektiv och kostnadseffektiv användarupplevelse.
Rigorös vetenskaplig upptäckt och formell verifiering med DeepSeek-V3.2-Speciale API
The DeepSeek-V3.2-Speciale API is engineered for tasks that demand absolute logical precision and multi-step reasoning. By integrating advanced theorem-proving capabilities, it enables researchers and engineers to execute complex mathematical inductions, verify formal logic, and solve high-tier competitive programming challenges. Perfect for academic R&D, automated code auditing, and cryptographic analysis, this API transforms abstract complexity into verifiable results with the performance of top-tier global models.
Advanced Algorithmic Synthesis & Strategic Reasoning using the DeepSeek-R1 API
DeepSeek-R1 empowers developers to build applications centered on deep cognitive workflows and strategic decision-making. Ranking at the forefront of global reasoning benchmarks, the R1 API excels in synthesizing sophisticated code architectures, processing dense technical documentation, and generating innovative solutions for open-ended logical puzzles. It is the ideal engine for AI-driven software engineering, long-form data synthesis, and any scenario where "thinking fast and slow" requires a powerful, reasoning-first foundation.
Sömlös orkestrering av autonoma agenter med DeepSeek-V3.2 API
For high-velocity, sensory-driven AI applications, the DeepSeek-V3.2 API provides the perfect equilibrium between reasoning depth and ultra-low latency. It is optimized for building autonomous Agents that can navigate multi-step workflows, manage real-time user interactions, and execute general-purpose tasks with GPT-5 level intelligence. This use case is tailor-made for enterprise-scale automation, intelligent customer ecosystems, and developers looking to deploy responsive, cost-effective AI assistants at scale.
Modelljämförelse
Se hur modeller från olika leverantörer står sig — jämför prestanda, priser och unika styrkor för ett välgrundat beslut.
| Modell | Kontext | Maximal utdata | Indata | Positionering |
|---|---|---|---|---|
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flaggskepp Allmän |
| DeepSeek V3.2 Speciale | 163.84K | 163.84K | Text | Högpresterande anpassad |
| DeepSeek V3.2 Exp | 163.84K | 163.84K | Text | Experimentell build |
| DeepSeek-V3.1 | 131.07K | 65.54K | Text | Open source-backbone |
| DeepSeek V3.1 Terminus | 131.07K | 65.54K | Text | Långtidsstabil (LTS) |
| DeepSeek-V3-0324 | 131.07K | 32.77K | Text | Historisk ögonblicksbild |
| DeepSeek-R1-0528 | 131.07K | 131.07K | Text | Resonemang i toppklass |
| DeepSeek OCR | 8.19K | 8.19K | Text | Dedikerad multimodal |
| GLM-5 | 200K | 128K | Text | Flaggskeppsgrundmodell |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA agentbaserad kodning |
How to Use DeepSeek LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Varför Använda DeepSeek LLM Models på Atlas Cloud
Att kombinera de avancerade DeepSeek LLM Models-modellerna med Atlas Clouds GPU-accelererade plattform ger oöverträffad prestanda, skalbarhet och utvecklarupplevelse.
Prestanda & flexibilitet
Låg Latens:
GPU-optimerad inferens för realtidsresonemang.
Enhetligt API:
Kör DeepSeek LLM Models, GPT, Gemini och DeepSeek med en integration.
Transparent Prissättning:
Förutsägbar fakturering per token med serverlösa alternativ.
Företag & Skala
Utvecklarupplevelse:
SDK:er, analys, finjusteringsverktyg och mallar.
Tillförlitlighet:
99.99% drifttid, RBAC och efterlevnadsredo loggning.
Säkerhet & Efterlevnad:
SOC 2 Type II, HIPAA-anpassning, datasuveränitet i USA.
Vanliga Frågor om DeepSeek LLM Models
DeepSeek erbjuder transparens genom öppen källkod och överlägsen kostnadseffektivitet. Med resonemangsförmågor (R1 & V3.2) som konkurrerar med GPT-5, tillhandahåller det ett högpresterande, billigare alternativ med flexibiliteten för privat driftsättning.
Detta återspeglar modellens totala "hjärnkapacitet". DeepSeeks MoE-design kombinerar ett massivt totalt antal parametrar (t.ex. 671B) för djup intelligens med ett strömlinjeformat "aktivt" antal för maximal operativ effektivitet.
Utforska Fler Familjer
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


