GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Utforska de Ledande Modellerna
Atlas Cloud förser dig med de senaste branschledande kreativa modellerna.
Vad Som Gör GLM LLM Models Unik
Atlas Cloud ger dig de senaste branschledande kreativa modellerna.

Advanced Reasoning
Tuned for strong logical reasoning, structured analysis, and multi-step problem solving.

Cost-Efficiency
Optimized architectures keep latency and costs under control.

Safety & Governance
Built-in content filters, auditing tools, and policy controls help teams deploy.

Enterprise Reliability
Production-ready SLAs, monitoring, and governance features help teams confidently ship applications.

Chinese–English Excellence
Native-strength Chinese and fluent English support enable high-quality bilingual chat, search, and generation.

Developer-Friendly Ecosystem
Clean APIs, SDKs, and tooling make it easy to integrate, fine-tune, and operate Z.ai across products and platforms.
Topphastighet
Lägsta kostnad
| Model | Description |
|---|---|
| GLM-5 | GLM-5 is Z.ai's flagship LLM featuring a massive 202.75K context window optimized for complex systems and long-horizon agentic tasks. Outperforming elite closed-source models in benchmarks like Humanity’s Last Exam and BrowseComp, it provides robust programming and stable multi-step reasoning at highly competitive baseline pricing. |
| GLM-4.7 | GLM-4.7 is a high-performance LLM with a 202.75K context window specifically engineered for real-world intelligent agents, advanced reasoning, and professional coding. Fast, smart, and reliable, it serves as the ideal engine for building complex websites and automating sophisticated professional workflows with precision. |
| GLM-4.6 | GLM-4.6 is a powerful MoE LLM with a 202.75K context window designed for rapid data analysis and instant, high-fidelity answers. This dependable model excels at high-efficiency tasks like creating professional slides and web content, offering a smart balance of speed and enterprise-grade performance. |
Nya funktioner för GLM LLM Models + Showcase
Kombinationen av avancerade modeller med Atlas Clouds GPU-accelererade plattform ger oöverträffad hastighet, skalbarhet och kreativ kontroll för bild- och videogenerering.
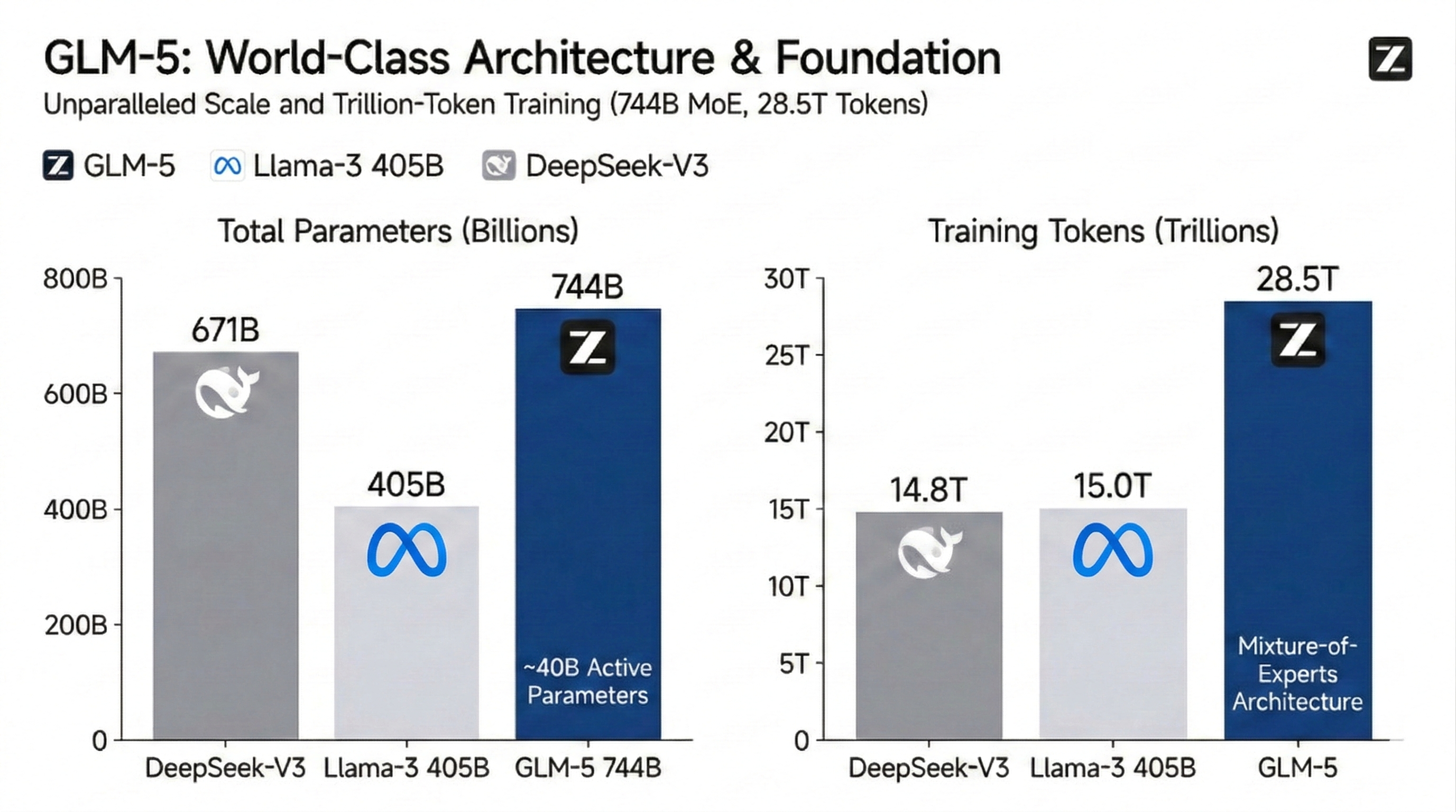
Massiv 744B MoE-arkitektur och universell kunskapsbas
GLM-5-modellen utnyttjar en Mixture-of-Experts (MoE)-arkitektur med 744 miljarder parametrar tränad på häpnadsväckande 28,5 biljoner tokens för att omdefiniera taket för öppen källkodsprestanda. Genom att optimera 40 miljarder aktiva parametrar möjliggör den ett enormt språng i världskunskapsdensitet och sökprecision. Det är den främsta grunden för storskaliga kognitiva uppgifter och komplex datasyntes.
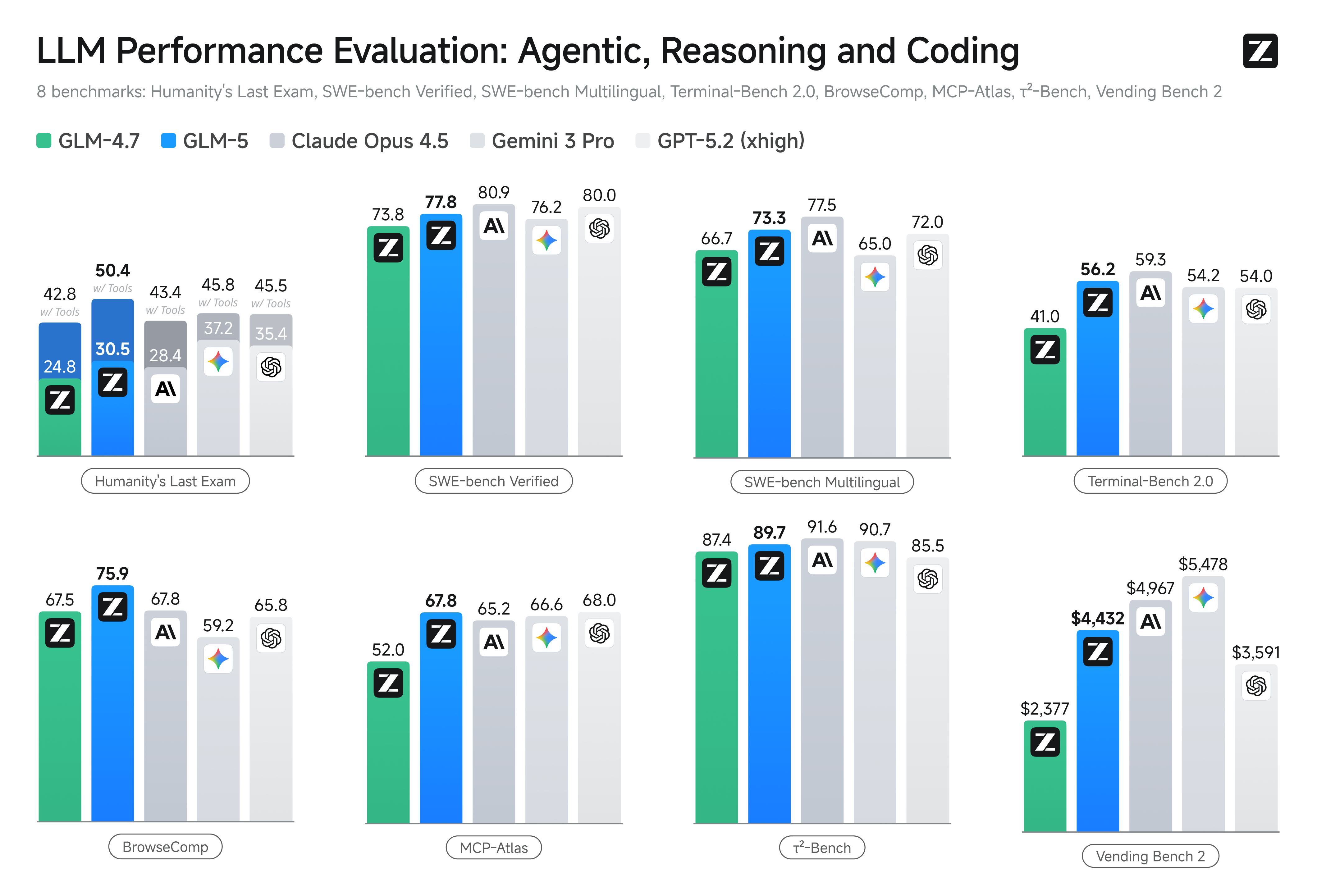
Banbrytande agentbaserad systemteknik med GLM-5
GLM-5 introducerar avancerade agentiska förmågor utformade för långsiktigt, systemiskt uppförande av uppgifter i miljöer för flerstegsresonemang. Genom att integrera sofistikerad planeringslogik i sin kärnarkitektur bibehåller modellen exceptionell stabilitet under automatiserad mjukvaruutveckling och professionell juridisk utformning. Den fungerar som den definitiva motorn för autonoma arbetsflöden som kräver extrem precision och långsiktig konsekvens.
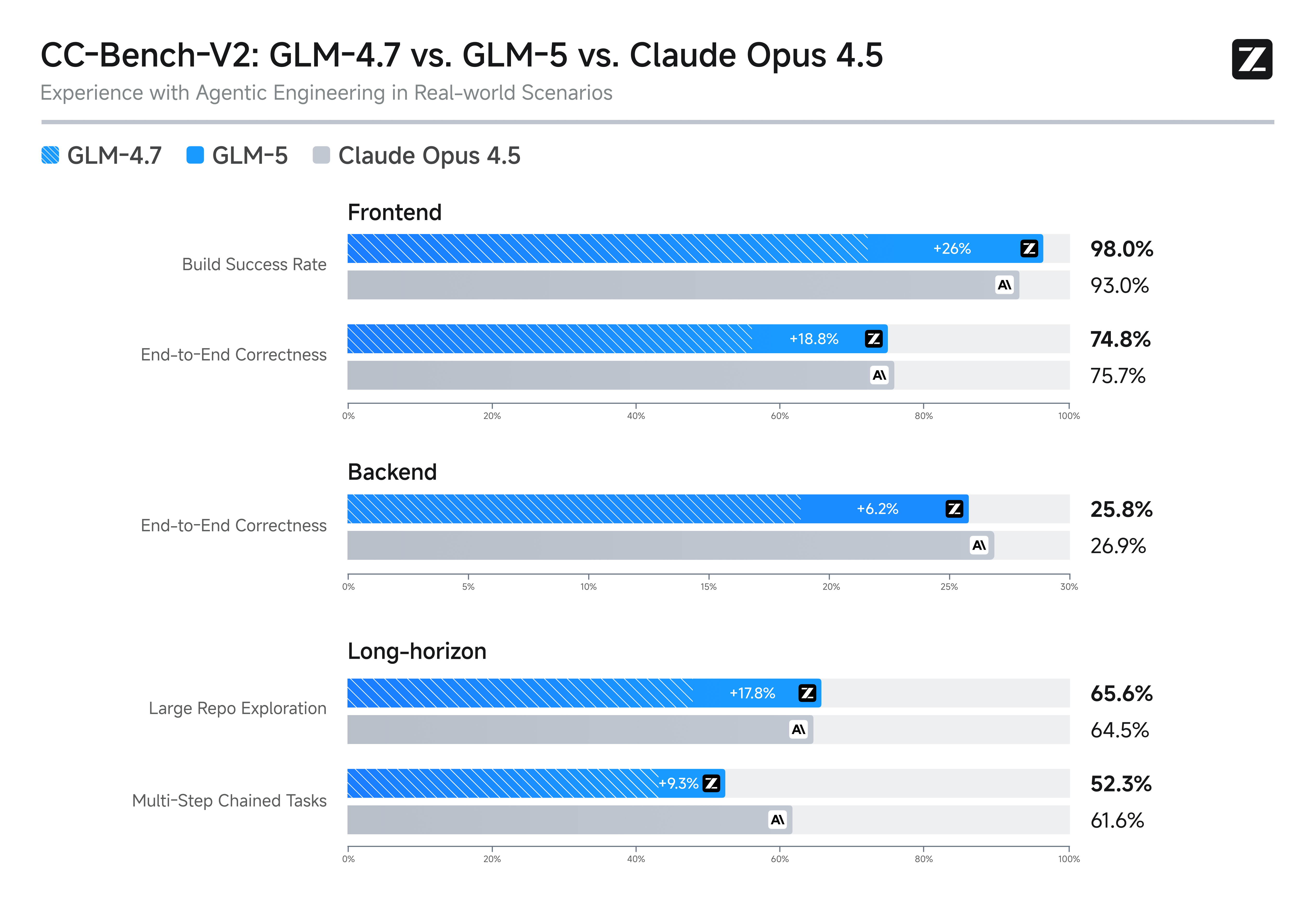
Slime Asynkron förstärkningsinlärning och logikevolution
GLM-5 använder den innovativa infrastrukturen "Slime" för asynkront förstärkningslärande för att revolutionera effektiviteten efter träning och den logiska stringensen. Detta genombrott förbättrar avsevärt kvaliteten på kodgenerering och algoritmiska resonemang, överträffar tidigare riktmärken och säkrar dess rang som en förstklassig öppen källkodsmodell. Det är den ultimata lösningen för full-stack-utveckling och problemlösning på hög nivå.
Vad Du Kan Göra med GLM LLM Models
Upptäck praktiska användningsfall och arbetsflöden du kan bygga med denna modellfamilj — från innehållsskapande och automatisering till produktionsklara applikationer.
Omfattande repository-intelligens med GLM-5
GLM-5 API:et ger utvecklare möjlighet att mata in hela kodbaser för djup logisk analys och strukturell refaktorisering. Genom att kartlägga beroendegrafer och spåra komplexa asynkrona dataflöden identifierar det race conditions i gränsfall och dold teknisk skuld. Perfekt för snabb onboarding av team, automatiserade PR-granskningar och underhåll av skalbara, högpresterande mikrotjänstarkitekturer.
Omedelbar Full-Stack-prototypning med GLM-5
För "vibe-driven" utveckling omvandlar GLM-5 abstrakta visuella skisser och fragmenterade anteckningar till distributionsklara React- eller Next.js-komponenter. Den hanterar det tunga arbetet med generering av boilerplate-kod, Tailwind CSS-styling och tillståndshantering samtidigt som den säkerställer konsekvens över sidorna. Perfekt för ensamgrundare, UX-experimentörer och för att leverera funktionella MVP:er blixtsnabbt.
Autonom orkestrering av arbetsflöden med GLM-5
GLM-5 utmärker sig på att hantera långsiktiga forskningsuppgifter som kräver resonemang i flera steg och verktygsintegration i realtid. Den kan självständigt syntetisera marknadsdata från flera källor, utarbeta kompatibla juridiska sammanfattningar och automatisera komplex plattformsoberoende schemaläggning utan att tappa sammanhanget. Detta användningsfall passar projektledare, jurister och alla som behöver en mycket pålitlig digital agent för systematiska operationer.
Modelljämförelse
Se hur modeller från olika leverantörer står sig — jämför prestanda, priser och unika styrkor för ett välgrundat beslut.
| Model | Context | Max Output | Input | Positioning |
|---|---|---|---|---|
| GLM-5 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.7 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.6 | 202.75K | 202.75K | Text | Efficient MoE Model |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flagship General |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA Agentic Coding |
How to Use GLM LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Varför Använda GLM LLM Models på Atlas Cloud
Att kombinera de avancerade GLM LLM Models-modellerna med Atlas Clouds GPU-accelererade plattform ger oöverträffad prestanda, skalbarhet och utvecklarupplevelse.
Prestanda & flexibilitet
Låg Latens:
GPU-optimerad inferens för realtidsresonemang.
Enhetligt API:
Kör GLM LLM Models, GPT, Gemini och DeepSeek med en integration.
Transparent Prissättning:
Förutsägbar fakturering per token med serverlösa alternativ.
Företag & Skala
Utvecklarupplevelse:
SDK:er, analys, finjusteringsverktyg och mallar.
Tillförlitlighet:
99.99% drifttid, RBAC och efterlevnadsredo loggning.
Säkerhet & Efterlevnad:
SOC 2 Type II, HIPAA-anpassning, datasuveränitet i USA.
Vanliga Frågor om GLM LLM Models
Med 28,5 biljoner tokens träningsdata och fantastiska benchmarkresultat betraktas GLM-5 allmänt som "taket för open source". Den konkurrerar med eller överträffar globala kommersiella toppmodeller i kapacitet och logik, och erbjuder en kraftfull, högpresterande grund för det globala utvecklerekosystemet.
HLE är ett riktmärke med hög svårighetsgrad utformat för att testa om AI besitter mänsklig kunskap och resonemangsförmåga på expertnivå. Att GLM-5 uppnår högsta poäng innebär att dess behärskning av spetsforskning och komplex logik har nått eller överträffat nivån hos ledande stängda källkodsmodeller.
BrowseComp är en definitiv topplista för "Agentic"-förmågor, med fokus på komplex uppgiftsplanering och utförande i verkliga webbmiljöer. Den högsta poängen representerar GLM-5:s förmåga att autonomt navigera i webbläsare och integrera information över sidor, vilket markerar den som den främsta Web Agent-motorn.
Denna arkitektur tillhandahåller en massiv "kunskapsbas" på 744 miljarder parametrar samtidigt som endast ~40 miljarder aktiveras under inferens. För utvecklare innebär detta kunskapstäthet och resonemangsdjup i världsklass – som överträffar täta modeller som Llama-3 405B – till lägre latens och kostnad.
Totala parametrar representerar modellens "kunskapskapacitet", där 744B möjliggör en enorm lagring av världsfakta och expertlogik. Aktiva parametrar representerar den "beräkningskraft" som används per inferens. Tack vare MoE-arkitekturen levererar GLM-5 intelligens på 744B-nivå med endast 40B beräkning, vilket balanserar en massiv kunskapsbas med höghastighets- och kostnadseffektiv prestanda.
Volymen av förträningsdata avgör en modells "synfält". 28,5T tokens är en av de största datamängderna globalt (ungefär dubbelt så stor som Llama-3:s), och omfattar sällsynta språk, specialiserade akademiska artiklar och omfattande kod av hög kvalitet. Detta säkerställer att GLM-5 besitter överlägsen noggrannhet och generaliseringsförmåga vid hantering av komplexa long-tail-frågor, tvärkulturella nyanser och systemprogrammering på låg nivå.
Utforska Fler Familjer
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


