DeepSeek LLM Models
DeepSeek, developed by the deepseek-ai team, is a cutting-edge series of open-source generative AI models engineered to democratize access to high-performance computing through a cost-effective and efficiency-first strategy. Its flagship reasoning model, DeepSeek-R1, made waves by rivaling top-tier proprietary models in mathematics, programming, and complex logical deduction, while the DeepSeek-V3.2, is designed for seamless daily interaction and autonomous Agent workflows. By significantly lowering the barrier to entry for advanced AI, DeepSeek has become a cornerstone for the "vibe coding" movement and a transformative tool in specialized fields like academic research and high-level technical problem-solving.
Önde Gelen Modelleri Keşfedin
Atlas Cloud size sektörün en yeni ve önde gelen yaratıcı modellerini sunar.
DeepSeek LLM Models'i Öne Çıkaran Nedir
Atlas Cloud size sektörün en yeni öncü yaratıcı modellerini sunar.

Açık Güç
Şeffaflık ve kontrol sağlayan, tamamen açık kaynaklı üst düzey modeller.

Mimari Verimlilik
Maliyetin çok küçük bir kısmına lider performans sağlamak için gelişmiş Mixture-of-Experts (MoE) teknolojisinden yararlanır.

Amaca yönelik çok yönlülük
Çok yönlü V3.1'den R1'in uzmanlaşmış akıl yürütme yeteneğine kadar, DeepSeek her görev için modeller sunar.

Geliştirici Odaklı Özgürlük
Sınırsız ticari kullanım için esnek lisanslı, engelsiz inovasyonu teşvik eder.

Kanıtlanmış Performans
Kodlama ve akıl yürütme için endüstri kıyaslamalarında tutarlı bir şekilde en son teknoloji sonuçlar elde eder.

Pratik Alternatif
Açık kaynağın uygun maliyeti ve esnekliği ile önde gelen tescilli modellerin gücünü sunar.
Peak speed
Lowest cost
| Modalite | Açıklama |
|---|---|
| DeepSeek V3.2 | DeepSeek V3.2, seyrek dikkat mekanizmalarını (sparse attention) güçlü 163.8K bağlam işleme yetenekleriyle bütünleştiren amiral gemisi bir genel amaçlı LLM'dir; son derece rekabetçi taban fiyatlandırmasıyla, karmaşık genel akıl yürütme ve çok adımlı görev zamanlama Agents oluşturma dahil olmak üzere günlük iş akışları için temel taşı görevi görür. |
| DeepSeek V3.2 Speciale | DeepSeek V3.2 Speciale, devasa 163.8K bağlam penceresi ve premium katmanlı fiyatlandırma yapısı (giriş $0.4 / çıkış $1.2) ile yüksek performanslı, özel bir LLM olarak konumlandırılmıştır. Yüksek net değere sahip müşteriler için akıllı müşteri hizmetleri veya milisaniye düzeyinde nicel analiz gibi en üst düzeyde çıktı kalitesi gerektiren, gecikmeye duyarlı temel iş düğümleri için özel olarak tasarlanmıştır. |
| DeepSeek V3.2 Exp | DeepSeek V3.2 Exp, V3.2 mimarisine dayanan, 163.8K bağlam ve benzer maliyetleri korurken en son algoritmik özellikleri entegre eden son teknoloji bir deneysel sürümdür. Gelecekteki ürünler için yeni nesil yapay zeka yeteneklerinin ayırt edici gücünü önceden doğrulamak amacıyla teknik ön araştırma ve kanarya testleri (canary testing) yürüten Ar-Ge ekipleri için idealdir. |
| DeepSeek-V3.1 | DeepSeek-V3.1, 131.1K bağlamında performans ve maliyet arasında yeni bir denge sağlayan, yüksek performanslı açık kaynak ekosistem modellerinin en son neslidir; ticari uygulama projeleri için en iyi seçenek olarak, hem yüksek kaliteli üretim hem de kontrol edilebilir maliyetler gerektiren senaryolar için omurga görevi görür. |
| DeepSeek V3.1 Terminus | DeepSeek V3.1 Terminus, V3.1 serisinin uzun vadeli kararlı nihai formu olarak hizmet vermektedir. DeepSeek V3.1 Terminus, standart sürümle aynı parametreleri ve fiyatlandırmayı koruyarak, sorunsuz, tüketiciye yönelik üretim ortamı uç nokta (endpoint) hizmetleri için kalıcı olarak kararlı bir çıktı stili ve mantığı sağlamayı amaçlamaktadır. |
| DeepSeek-V3-0324 | DeepSeek-V3-0324, 131.1K bağlam ve mevcut en düşük metin giriş maliyetine sahip, öncelikle mutlak davranışsal tutarlılık gerektiren eski sistem bakımında veya muazzam giriş verimi ancak orta düzey çıktı mantığı gereksinimleri olan toplu işlem görevlerinde uygulanan belirli bir geçmiş anlık görüntü sürümüdür. |
| DeepSeek-R1-0528 | DeepSeek-R1-0528, 131.1K bağlam kullanan ve en yüksek işlem maliyetine ($0.55/$2.15) sahip, üst düzey bir derin akıl yürütme modeli olarak konumlandırılmıştır. Mantıksal diyalektik yeteneklerin zirvesini temsil eder ve karmaşık matematiksel modelleme ve gelişmiş kod mimarisi oluşturma gibi kritik "beyin fırtınası" görevleri için özel olarak kullanılır. |
| DeepSeek OCR | DeepSeek OCR, kısa 8.2K bağlam ve ultra düşük kullanım maliyetleri ile çift kanallı görüntü-metin girişini destekleyen, büyük taranmış belgelerin dijitalleştirilmesi ve finansal makbuzların yapılandırılmış çıkarımı gibi otomatik veri girişi hattı senaryoları için mükemmel bir şekilde uyarlanmış, özel bir görsel çok modlu LLM'dir. |
DeepSeek LLM Models Yeni Özellikleri + Vitrin
Gelişmiş modelleri Atlas Cloud'un GPU hızlandırmalı platformuyla birleştirmek, görüntü ve video üretimi için benzersiz hız, ölçeklenebilirlik ve yaratıcı kontrol sunar.
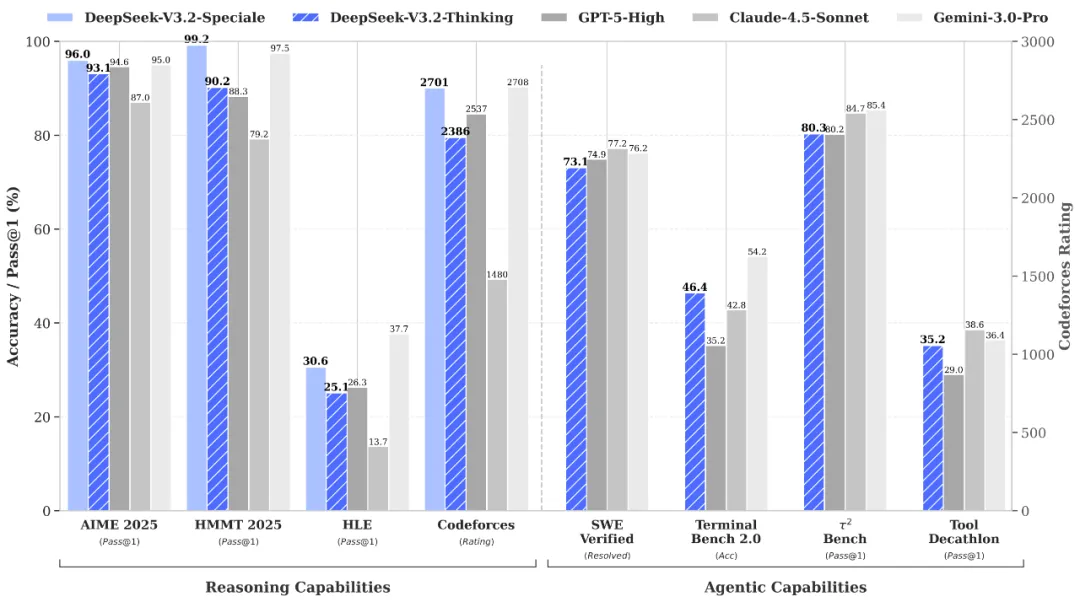
DeepSeek-V3.2-Speciale API aracılığıyla Dünya Klasmanında Akıl Yürütme ve Doğrulama
DeepSeek-V3.2-Speciale is the "long-thought" enhanced variant of the V3.2 architecture, integrating advanced theorem-proving capabilities from DeepSeek-Math-V2. Engineered for extreme precision, this model excels in rigorous mathematical proofing, complex logical verification, and superior instruction following, rivaling the performance of Gemini-3.0-Pro in mainstream reasoning benchmarks. It is the premier choice for academic research, automated formal verification, and high-stakes technical problem-solving where logical integrity is non-negotiable.
DeepSeek-R1 API ile Rakipsiz Bilişsel Derinlik
DeepSeek-R1 modeli, matematik, programlama ve genel mantık alanlarında endüstri lideri performans sunarak akıl yürütme yapay zekasının (reasoning AI) ön saflarında yer almaktadır. OpenAI'nin o3 ve Gemini-2.5-Pro gibi elit küresel modelleriyle eşdeğerliğe ulaşan R1, açık kaynaklı zekanın yeteneklerini yeniden tanımlamıştır. Karmaşık algoritmik geliştirme, sofistike veri sentezi ve çok aşamalı tümdengelimli akıl yürütme gerektiren gelişmiş bilişsel iş akışları dahil olmak üzere derin düşünme görevleri için özel olarak optimize edilmiştir.
DeepSeek V3.2 API kullanarak otonom Ajan iş akışlarıyla sorunsuz günlük etkileşim
DeepSeek-V3.2, akıl yürütme derinliği ile yürütme hızı arasında mükemmel bir denge kurarak kesintisiz günlük etkileşimleri ve otonom ajan ekosistemlerini güçlendirmek için tasarlanmıştır. Önemli ölçüde azaltılmış gecikme süresi ve optimize edilmiş çıktı kontrolü ile çok adımlı görev orkestrasyonu ve genel amaçlı yapay zeka asistanları için sağlam bir motor görevi görür. İster kurumsal ölçekli otomasyon ister yüksek frekanslı etkileşimli araçlar dağıtılıyor olsun, V3.2 akıcı, verimli ve uygun maliyetli bir kullanıcı deneyimi sağlar.
DeepSeek-V3.2-Speciale API ile Titiz Bilimsel Keşif ve Biçimsel Doğrulama
The DeepSeek-V3.2-Speciale API is engineered for tasks that demand absolute logical precision and multi-step reasoning. By integrating advanced theorem-proving capabilities, it enables researchers and engineers to execute complex mathematical inductions, verify formal logic, and solve high-tier competitive programming challenges. Perfect for academic R&D, automated code auditing, and cryptographic analysis, this API transforms abstract complexity into verifiable results with the performance of top-tier global models.
Advanced Algorithmic Synthesis & Strategic Reasoning using the DeepSeek-R1 API
DeepSeek-R1 empowers developers to build applications centered on deep cognitive workflows and strategic decision-making. Ranking at the forefront of global reasoning benchmarks, the R1 API excels in synthesizing sophisticated code architectures, processing dense technical documentation, and generating innovative solutions for open-ended logical puzzles. It is the ideal engine for AI-driven software engineering, long-form data synthesis, and any scenario where "thinking fast and slow" requires a powerful, reasoning-first foundation.
DeepSeek-V3.2 API ile Sorunsuz Otonom Ajan Orkestrasyonu
For high-velocity, sensory-driven AI applications, the DeepSeek-V3.2 API provides the perfect equilibrium between reasoning depth and ultra-low latency. It is optimized for building autonomous Agents that can navigate multi-step workflows, manage real-time user interactions, and execute general-purpose tasks with GPT-5 level intelligence. This use case is tailor-made for enterprise-scale automation, intelligent customer ecosystems, and developers looking to deploy responsive, cost-effective AI assistants at scale.
Model Karşılaştırma
Farklı sağlayıcıların modellerinin nasıl karşılaştırıldığını görün — performans, fiyatlandırma ve benzersiz güçlü yönleri karşılaştırarak bilinçli bir karar verin.
| Model | Bağlam | Maksimum Çıktı | Girdi | Konumlandırma |
|---|---|---|---|---|
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Amiral Gemisi Genel |
| DeepSeek V3.2 Speciale | 163.84K | 163.84K | Text | Yüksek Performanslı Özel |
| DeepSeek V3.2 Exp | 163.84K | 163.84K | Text | Deneysel Yapı |
| DeepSeek-V3.1 | 131.07K | 65.54K | Text | Açık Kaynak Omurga |
| DeepSeek V3.1 Terminus | 131.07K | 65.54K | Text | Uzun Vadeli Kararlı (LTS) |
| DeepSeek-V3-0324 | 131.07K | 32.77K | Text | Tarihsel Anlık Görüntü |
| DeepSeek-R1-0528 | 131.07K | 131.07K | Text | Üst Düzey Muhakeme |
| DeepSeek OCR | 8.19K | 8.19K | Text | Özel Multimodal |
| GLM-5 | 200K | 128K | Text | Amiral gemisi temel model |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA Ajan Tabanlı Kodlama |
How to Use DeepSeek LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Atlas Cloud'da DeepSeek LLM Models'i Neden Kullanmalı
DeepSeek LLM Models'in gelişmiş modellerinin Atlas Cloud'un GPU hızlandırmalı platformuyla birleşimi, benzersiz performans, ölçeklenebilirlik ve geliştirici deneyimi sunar.
Performans ve Esneklik
Düşük Gecikme:
Gerçek zamanlı akıl yürütme için GPU optimize çıkarım.
Birleşik API:
DeepSeek LLM Models, GPT, Gemini ve DeepSeek'i tek entegrasyonla çalıştırın.
Şeffaf Fiyatlandırma:
Sunucusuz seçeneklerle öngörülebilir token tabanlı faturalandırma.
Kurumsal ve Ölçekleme
Geliştirici Deneyimi:
SDK'lar, analitik, ince ayar araçları ve şablonlar.
Güvenilirlik:
%99,99 kullanılabilirlik, RBAC ve uyumluluk için hazır günlükleme.
Güvenlik ve Uyumluluk:
SOC 2 Type II, HIPAA uyumluluğu, ABD'de veri egemenliği.
Sıkça Sorulan Sorular - DeepSeek LLM Models
DeepSeek, açık kaynak şeffaflığı ve üstün maliyet verimliliği sunar. GPT-5 ile rekabet eden muhakeme yetenekleri (R1 ve V3.2) ile, özel dağıtım esnekliğine sahip, yüksek performanslı ve düşük maliyetli bir alternatif sağlar.
Bu, modelin toplam "beyin kapasitesini" yansıtır. DeepSeek'in MoE tasarımı, derin zeka için devasa bir toplam parametre sayısını (örneğin, 671B) maksimum operasyonel verimlilik için modernize edilmiş "aktif" bir sayıyla birleştirir.
Daha Fazla Aile Keşfedin
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


