
ChatGPT API for Frontier GPT 5.6 Reasoning
ChatGPT API trên Atlas Cloud đưa dòng GPT 5.6 mới nhất của OpenAI vào một tích hợp duy nhất, bao gồm Sol cho suy luận tiên phong chuyên sâu, Terra cho các tác vụ sản xuất thực tế, và Luna cho hội thoại tự nhiên cùng tạo nội dung. Định tuyến mọi model qua một khóa tương thích OpenAI duy nhất, tin cậy vào thời gian hoạt động đạt chuẩn production, và thanh toán theo mức giá trả theo mức sử dụng minh bạch, bắt đầu từ $1 cho mỗi triệu token đầu vào. Bắt đầu xây dựng ngay hôm nay.
Khám phá Mô hình Hàng đầu
Atlas Cloud cung cấp cho bạn các mô hình sáng tạo tiên tiến nhất trong ngành.
Chọn đúng mô hình ChatGPT API: So sánh mọi endpoint
Năm endpoint tạo văn bản, từ suy luận tiên phong đến hội thoại tiết kiệm chi phí, tất cả được phục vụ qua một khóa tương thích OpenAI với mức giá trả theo mức dùng minh bạch.
| Phương thức | Mô tả |
|---|---|
| GPT 5.6 Sol API (Text to Text) | Được xây dựng cho các khối lượng công việc AI tiên phong, GPT 5.6 Sol biến các prompt văn bản phức tạp thành đầu ra suy luận sâu, nhiều bước cho những bài toán tham vọng. Giá tiêu chuẩn là $5 cho mỗi triệu token đầu vào và $30 cho mỗi triệu token đầu ra, phù hợp làm lựa chọn flagship khi chất lượng câu trả lời quan trọng hơn chi phí. |
| GPT 5.6 Terra API (Text to Text) | Cần một lựa chọn mặc định đáng tin cậy cho production? GPT 5.6 Terra chuyển prompt thành văn bản thực tế, có nền tảng vững chắc cho các workflow và pipeline phân tích trong thực tế, với giá $2.50 đầu vào và $15 đầu ra cho mỗi triệu token. Các đội ngũ triển khai mô hình này trong ứng dụng hướng khách hàng, nơi tính nhất quán quan trọng hơn độ sâu thử nghiệm. |
| GPT 5.6 Luna API (Text to Text) | Hãy định tuyến lưu lượng hội thoại và sáng tạo đến GPT 5.6 Luna, một mô hình văn bản được tinh chỉnh cho đối thoại tự nhiên, tạo nội dung và trải nghiệm AI cá nhân hóa. Với giá $1 đầu vào và $6 đầu ra cho mỗi triệu token, đây là điểm khởi đầu kinh tế nhất trong dòng ChatGPT API này, rất phù hợp cho sản phẩm chat và tạo nội dung quảng cáo ở quy mô lớn. |
| GPT 5.4 API (Text to Text) | GPT 5.4 xử lý hướng dẫn văn bản thành code đáng tin cậy, nội dung dài và đầu ra giải quyết vấn đề có cấu trúc với độ chính xác cao. Được thiết kế là một mô hình đa phương thức nâng cao, mô hình này nằm ở mức giá tầm trung: $2.50 đầu vào và $15 đầu ra cho mỗi triệu token, phù hợp thực tế cho trợ lý lập trình và nền tảng nội dung. |
| GPT 5.5 API (Text to Text) | Khi các bài toán khó xứng đáng với mức chi premium, GPT 5.5 cung cấp khả năng suy luận nâng cao, lập trình và tạo nội dung từ một endpoint văn bản duy nhất. Với giá $5 đầu vào và $30 đầu ra cho mỗi triệu token, mô hình này hướng đến các khối lượng công việc phức tạp, đòi hỏi độ tin cậy cao như điều phối agent và phân tích kỹ thuật. |
ChatGPT API: các bậc GPT 5.x và trọng số mở
Truy cập toàn bộ dòng GPT 5.x và GPT OSS 120B trọng số mở thông qua một ChatGPT API duy nhất, tinh chỉnh mức nỗ lực suy luận từ low đến xhigh, kết hợp văn bản, hình ảnh và tệp trong một lệnh gọi, đồng thời gọi các công cụ native với tìm kiếm web trực tiếp bằng một key tương thích OpenAI.
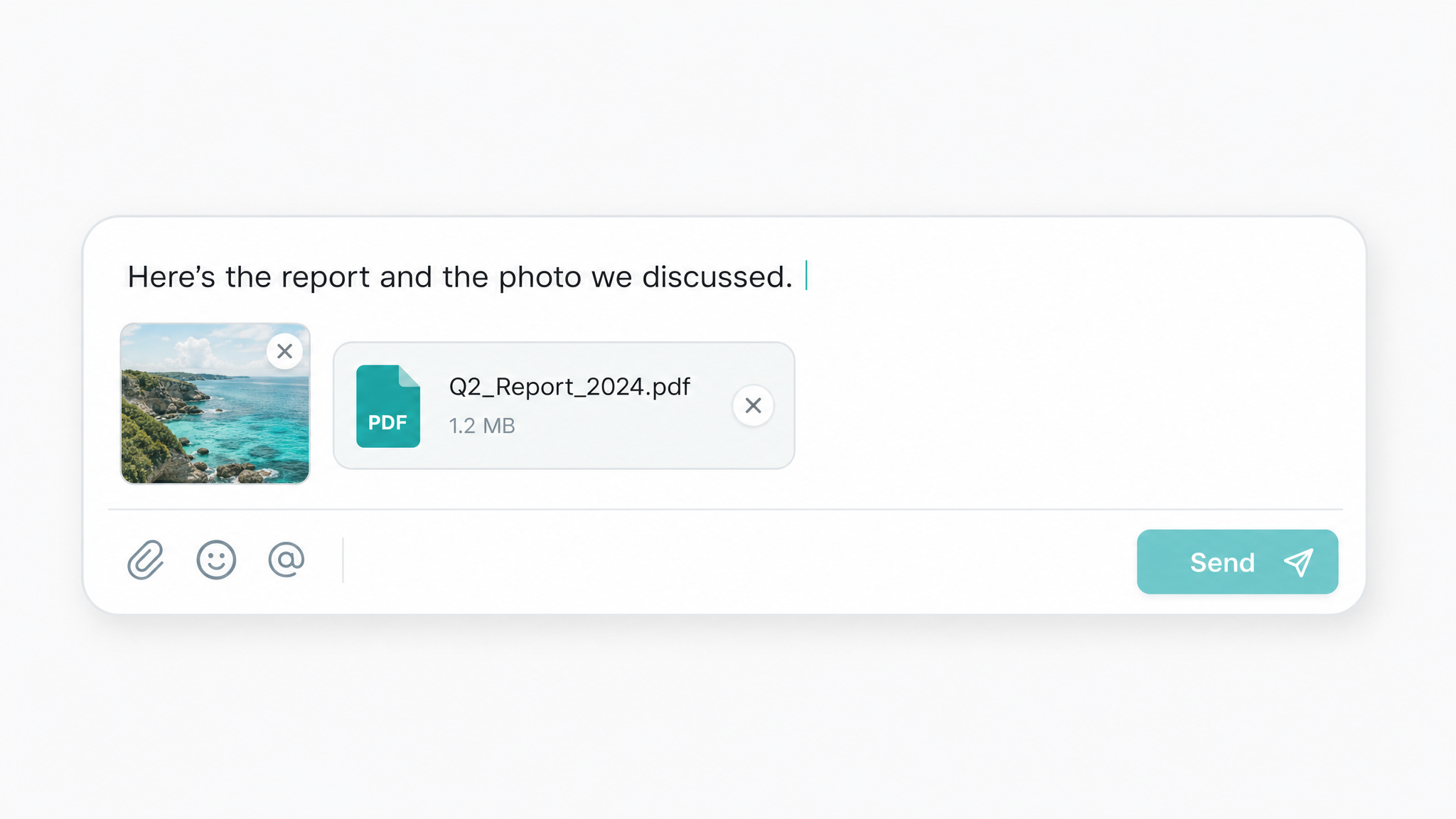
Văn bản, hình ảnh và tệp trong một lệnh gọi ChatGPT API
Một yêu cầu ChatGPT API duy nhất có thể kết hợp văn bản thuần, URL hình ảnh và tệp tài liệu trong cùng một message. Nhờ đó không cần các dịch vụ OCR hoặc thị giác riêng biệt, nên bạn có thể tóm tắt hợp đồng được quét hoặc đọc ảnh chụp màn hình chỉ trong một lượt.
Độ bám sát chỉ dẫn trên ChatGPT API
GPT OSS 120B tuân thủ các system prompt nhiều lớp, giữ cho định dạng, ràng buộc và giọng điệu ổn định trên các đầu ra mà không bị lệch. Độ tin cậy đó phù hợp với tác tử tự động, trích xuất có cấu trúc và các pipeline production nơi đầu ra phải tuân thủ quy tắc.
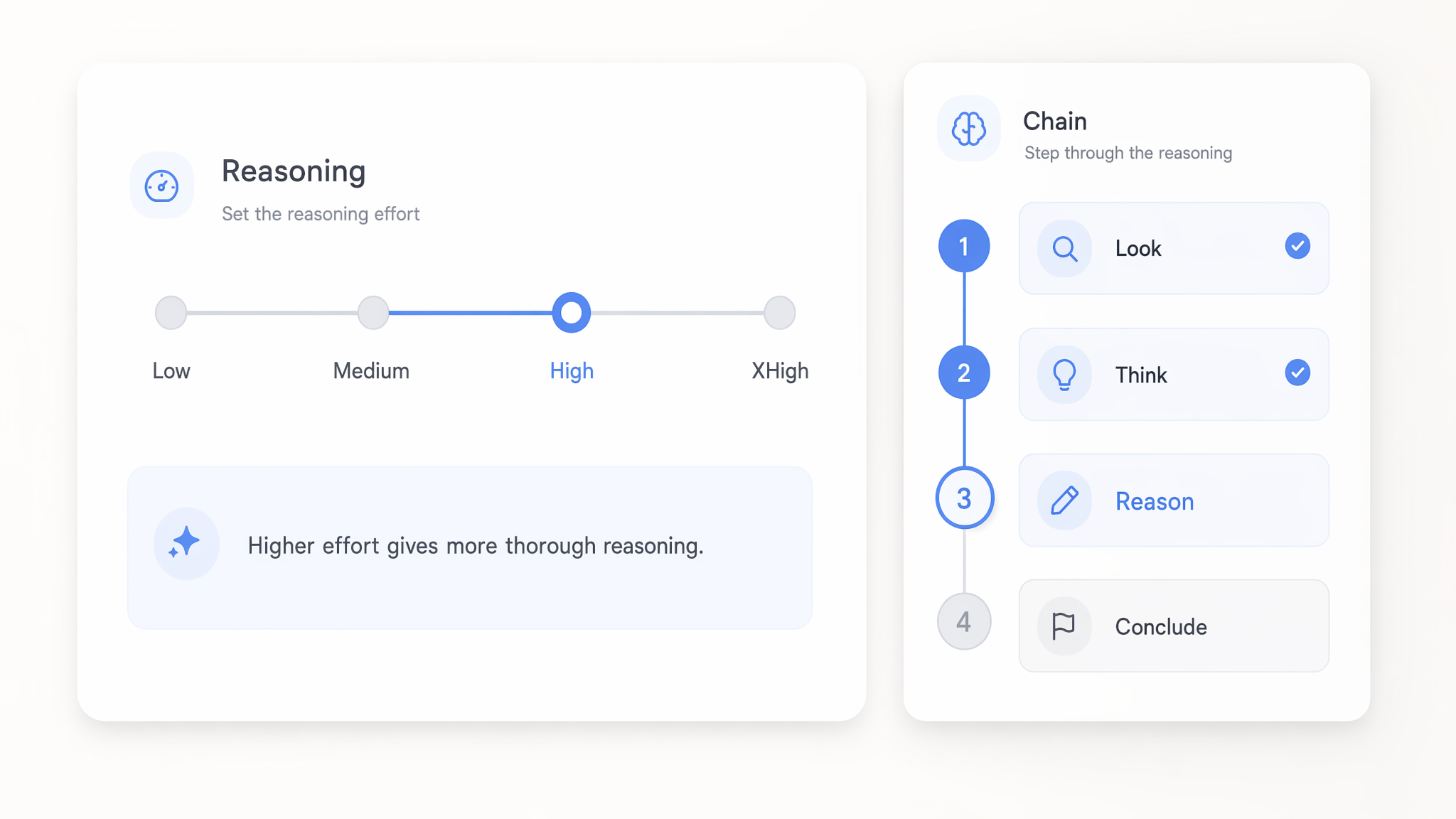
Điều chỉnh mức nỗ lực suy luận từ Low đến xHigh
Đặt mức nỗ lực suy luận trên các model GPT 5.x ở bất kỳ mức nào từ low đến xhigh để kiểm soát mức độ suy nghĩ sâu trước khi trả lời. Thiết lập low trả lời các lệnh gọi đơn giản nhanh và tiết kiệm, trong khi xhigh dùng nhiều compute hơn cho logic nhiều bước khó.
Trọng số Apache 2.0 mà bạn toàn quyền sở hữu
Được phân phối theo giấy phép Apache 2.0, GPT OSS 120B cho phép sử dụng thương mại và fine-tuning riêng trên một GPU 80GB duy nhất. Host on-premises để giữ dữ liệu độc quyền trong nội bộ và tránh hoàn toàn phí theo token.

Năm bậc GPT, một ChatGPT API
Một ChatGPT API phục vụ toàn bộ dòng GPT 5.x, với giá từ Luna ở mức $1 đến Sol ở mức $5 cho mỗi triệu input token. Ghép từng lệnh gọi với bậc phù hợp theo chi phí và nhu cầu trí tuệ, không cần thay đổi endpoint.
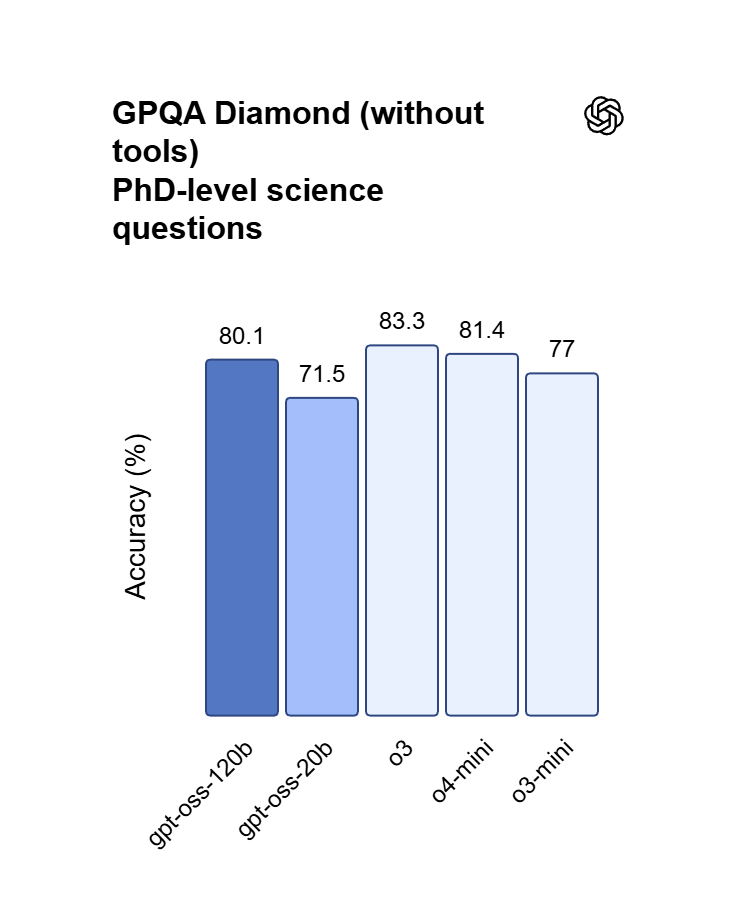
Suy luận được tinh chỉnh cho Vibecoding
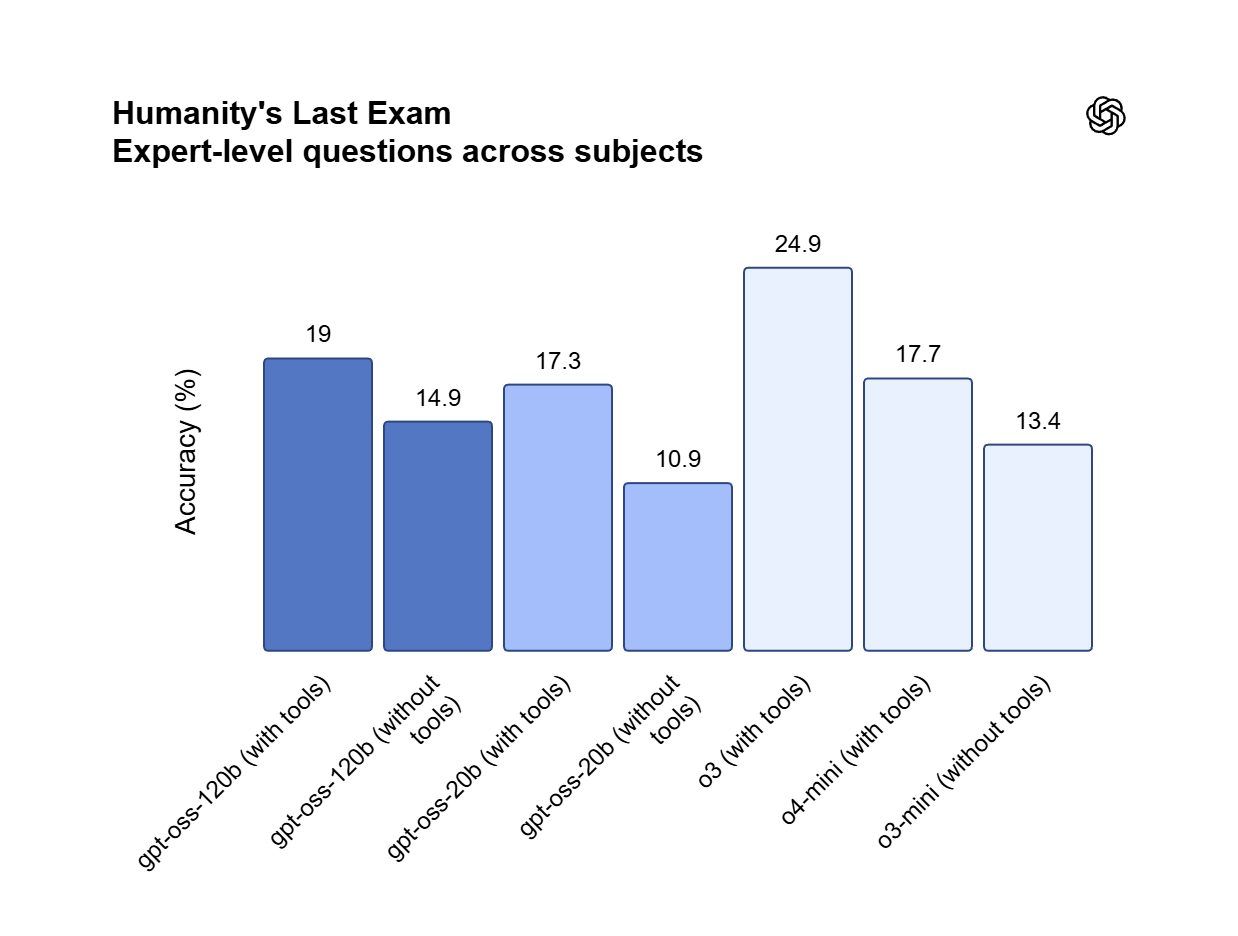
Mức gần tương đương OpenAI o4-mini giúp GPT OSS 120B xử lý tổng hợp mã nhiều bước và chứng minh toán học. Biến ý tưởng bằng ngôn ngữ tự nhiên thành ứng dụng web chạy được, debug logic lồng nhau và điều phối các luồng lập lịch tác vụ phức tạp.

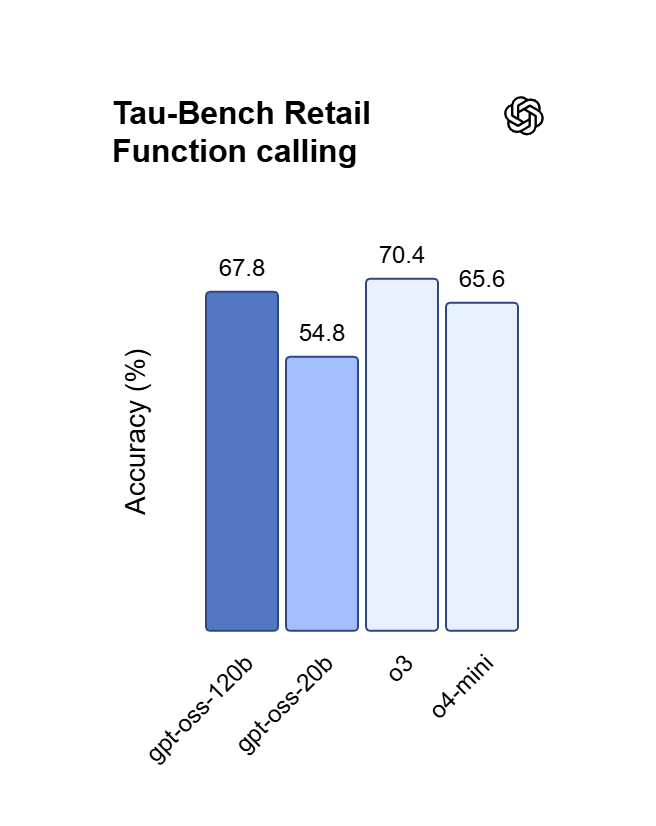
Gọi hàm với tìm kiếm web trực tiếp
Các model GPT 5.x hỗ trợ gọi hàm với lựa chọn công cụ tự động cùng tính năng tìm kiếm web tích hợp để lấy kết quả hiện tại. Stream phản hồi dưới dạng server-sent events, trong khi prompt caching giảm input được cache của GPT 5.6 Sol xuống còn $0.5 cho mỗi triệu token.
Một prompt, ba đối thủ: So găng ChatGPT API
Chúng tôi đưa cùng một chỉ dẫn xây dựng vào các model thông qua ChatGPT API và hai flagship đối thủ, rồi render nguyên vẹn mọi phản hồi HTML thô để bạn có thể so sánh trực tiếp độ sâu lập luận, chất lượng mã và gu thiết kế.
Xây dựng một file HTML độc lập duy nhất (chỉ dùng CSS và JavaScript inline — tuyệt đối không dùng thư viện ngoài, CDN, framework, font hay URL hình ảnh) có thể mở trực tiếp trong mọi trình duyệt hiện đại và chạy một trình mô phỏng hệ sinh thái nhà kính bằng kính đang sống, tự phát triển, được render hoàn toàn dưới dạng minh họa vector phẳng bằng Canvas/SVG. Cảnh toàn màn hình là một nhà kính Victoria có mái vòm: một cupola kính cong vắt qua phần trên làm khung chính, các ô kính được vẽ như những đa giác xanh ngọc trong mờ với điểm sáng phản chiếu mềm và đường khung muntin mảnh, còn một dải đất trồng sẫm màu chạy dọc phía dưới. Định hướng nghệ thuật là minh họa vector sạch — lá và thân được vẽ bằng nét gân sắc gọn cùng các lớp tô bán trong suốt chồng lên nhau, bảng màu dựa trên xanh sage phủ sương và nâu rêu, điểm thêm nắng hổ phách và sắc kính xanh ngọc; không photorealism, không dùng gradient như texture, giữ cảm giác đồ họa và vẽ tay. Tương tác cốt lõi: nhấp vào bất kỳ đâu trên phần đất để gieo một hạt tại vị trí đó, và cây sẽ phát triển theo thời gian thực bằng một L-system thực sự — triển khai ngữ pháp viết lại đệ quy (axiom cộng các production rules với ngoặc nhánh và độ nhiễu ngẫu nhiên cho góc/chiều dài theo từng instance để không có hai cây nào giống nhau) và animate quá trình suy diễn để cành vươn dài, phân nhánh và lá bung mở dần trong vài giây thay vì xuất hiện ngay ở trạng thái hoàn chỉnh. Dương xỉ nhiệt đới và dây leo phải uốn cong và cuộn về phía một mặt trời có thể kéo thả theo phototropism: render một đĩa mặt trời hổ phách phát sáng mà người dùng có thể nắm và kéo đến bất kỳ đâu trên bầu trời, và mọi ngọn đang phát triển phải liên tục điều chỉnh lại hướng sinh trưởng về vị trí hiện tại của mặt trời để khi kéo mặt trời, người dùng thấy rõ cả khu vườn nghiêng và leo theo hướng đó. Cây con bung lá bằng animation easing, và các giọt ngưng tụ hình thành trên kính rồi từ từ trượt xuống theo vòng lặp. Điều khiển mọi thứ bằng chu kỳ ngày-đêm gắn với vị trí mặt trời: ánh sáng môi trường và lớp phủ bầu trời chuyển mượt theo gradient từ vàng ấm sang xanh lạnh, vị trí mặt trời xác định hướng và độ dài của bóng cây mềm đổ trên sàn cũng như các đốm sáng trôi trên kính, và lúc hoàng hôn đom đóm hiện dần thành những điểm sáng nhỏ nhấp nháy trôi giữa tán lá. Bố cục tỏa sự phát triển của cây từ phần gốc lên phía trung tâm, được bao trong vòng cung của mái vòm. Dùng requestAnimationFrame cho một vòng lặp animation liên tục, nhẹ nhàng như đang thở; giữ hiệu năng mượt khi có nhiều cây trên màn hình cùng lúc. Bao gồm các điều khiển tinh tế, không gây chú ý (ví dụ: slider hoặc toggle tự chạy cho thời điểm trong ngày, và nút reset/clear) được tạo kiểu đồng bộ với thẩm mỹ minh họa, cùng một dòng gợi ý cho người dùng nhấp vào đất để trồng cây và kéo mặt trời để dẫn hướng sinh trưởng. Làm cho giao diện responsive với mọi kích thước cửa sổ, và giữ sắc thái cảm xúc bình yên, tĩnh lặng mà đầy sức sống — ánh sáng đầu buổi sáng xiên vào khi những chồi non cùng mở ra. Đây là một mô phỏng sinh thành, không phải game hay dashboard: ưu tiên thuật toán tăng trưởng đệ quy thật sự, vòng lặp animation, cùng vật lý ánh sáng/bóng đổ/phototropism.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Xây dựng một trang HTML single-file hoàn chỉnh chứa dashboard tương tác về gọi vốn startup toàn cầu, dùng dữ liệu hư cấu nhưng nhất quán nội bộ cho 8 ngành trong 5 năm. Toàn bộ CSS và JavaScript phải inline, không có dependency bên ngoài, không dùng thư viện biểu đồ, không CDN, không hình ảnh. Render ba visualization viết tay bằng canvas hoặc SVG: biểu đồ cột có animation và tự sắp xếp lại bằng easing khi người dùng chọn năm từ slider, biểu đồ đường có tooltip khi hover hiển thị giá trị chính xác và một đường dẫn hướng dọc, và biểu đồ donut có các segment mở rộng khi hover bằng animation kiểu spring. Bao gồm UI hiện đại nền tối với bảng màu nhấn từ tím sang xanh teal, bộ đếm số có animation trong bốn thẻ KPI, hàng filter ngành dạng toggle chip cập nhật ngay lập tức tất cả biểu đồ, và công tắc theme sáng/tối với chuyển màu mượt. Bố cục phải responsive, thu gọn thành một cột dưới 768px, và mọi tương tác phải phản hồi theo thời gian thực mà không reload trang.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
Mọi khối lượng công việc mà ChatGPT API có thể vận hành
Từ lập trình tác nhân và trích xuất có cấu trúc đến chat hỗ trợ có căn cứ và nội dung số lượng lớn, ChatGPT API trên Atlas Cloud định tuyến từng tác vụ đến đúng tầng GPT 5.6 thông qua một khóa tương thích OpenAI duy nhất.

Ra mắt công cụ lập trình tác nhân với ChatGPT API
Định tuyến các tác vụ tái cấu trúc phức tạp và tổng hợp mã trên nhiều tệp đến GPT 5.6 Sol, tầng suy luận sâu của dòng mô hình, được xây dựng cho các khối lượng công việc kỹ thuật tiên phong. Các nhóm xây dựng trợ lý lập trình, bot đánh giá tự động và trình tạo kiểm thử sẽ có được năng lực logic đạt chuẩn sản xuất.

Tạo nội dung đúng thương hiệu ở quy mô lớn
GPT 5.6 Luna, tầng sáng tạo của dòng mô hình, soạn thảo bài blog, mô tả sản phẩm và nội dung bản địa hóa với giọng văn tự nhiên cùng đầu ra được cá nhân hóa. Các nhóm nội dung và nền tảng thương mại điện tử có thể sản xuất nội dung số lượng lớn mà không phải đánh đổi giọng điệu thương hiệu.

Vận hành trợ lý hỗ trợ bằng ChatGPT API
Cần một chatbot luôn bám sát kịch bản? GPT 5.6 Terra cung cấp phản hồi đáng tin cậy, có căn cứ, được xây dựng cho hội thoại trong môi trường sản xuất, giúp các nhóm hỗ trợ và sản phẩm SaaS tự động hóa ticket và xử lý ổn định các truy vấn lặp lại.

Hệ thống tri thức tăng cường bằng truy xuất
Đưa toàn bộ sổ tay chính sách hoặc kho lưu trữ nghiên cứu vào một mô hình ngữ cảnh dài và nhận câu trả lời có căn cứ, giữ đúng nguồn. Các nhóm pháp lý, y tế và tìm kiếm nội bộ có được một công cụ đáng tin cậy cho hỏi đáp tăng cường bằng truy xuất.

Trích xuất dữ liệu có cấu trúc qua ChatGPT API
Hóa đơn, email và PDF lộn xộn được chuyển thành JSON sạch mà các hệ thống downstream có thể tin cậy. Khả năng tuân thủ chỉ dẫn ổn định giúp giữ nguyên schema, phục vụ các pipeline dữ liệu, tự động hóa CRM và quy trình phân tích không thể chấp nhận sai lệch.

Ghép từng tác vụ với đúng tầng mô hình
Khi ngân sách và độ trễ là yếu tố quan trọng, hãy chuyển đổi giữa Sol, Terra và Luna thông qua một khóa tương thích OpenAI duy nhất. Startup và nhà phát triển độc lập có thể tạo prototype nhanh với giá trả theo mức sử dụng, rồi mở rộng cùng một tích hợp đó lên môi trường sản xuất.
| Model | Ngữ cảnh | Đầu ra tối đa | Đầu vào | Định vị |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Văn bản | LLM suy luận hiệu suất cao |
| GLM-5 | 202.75K | 202.75K | Văn bản | Mô hình nền tảng chủ lực |
| DeepSeek V3.2 | 163.84K | 163.84K | Văn bản | Mô hình tổng quát chủ lực |
| MiniMax-M2.5 | 204.8K | 196.6K | Văn bản | Lập trình tác tử SOTA |
Cách Sử Dụng ChatGPT trên Atlas Cloud
Bắt đầu trong vài phút — làm theo các bước đơn giản sau để tích hợp và triển khai mô hình qua nền tảng Atlas Cloud.
Tạo Tài Khoản Atlas Cloud
Đăng ký tại atlascloud.ai và hoàn tất xác minh. Người dùng mới nhận được tín dụng miễn phí để khám phá nền tảng và thử nghiệm mô hình.
Tại sao Sử dụng ChatGPT trên Atlas Cloud
Sự kết hợp của các mô hình tiên tiến của ChatGPT với nền tảng được tăng tốc GPU của Atlas Cloud mang lại hiệu suất, khả năng mở rộng và trải nghiệm nhà phát triển độc đáo.
Hiệu suất và Tính linh hoạt
Độ Trễ Thấp:
Suy luận được tối ưu hóa GPU cho suy luận thời gian thực.
API Thống nhất:
Chạy ChatGPT, GPT, Gemini và DeepSeek với một tích hợp duy nhất.
Giá cả Minh bạch:
Thanh toán dựa trên token có thể dự đoán với tùy chọn serverless.
Doanh nghiệp và Mở rộng
Trải nghiệm Nhà phát triển:
SDK, phân tích, công cụ tinh chỉnh và mẫu.
Độ tin cậy:
99,99% khả dụng, RBAC và ghi nhật ký sẵn sàng cho tuân thủ.
Bảo mật và Tuân thủ:
SOC 2 Type II, tuân thủ HIPAA, chủ quyền dữ liệu tại Hoa Kỳ.
ChatGPT API: Giải đáp câu hỏi cho nhà phát triển
ChatGPT API cho phép nhà phát triển gửi prompt đến các mô hình GPT của OpenAI và nhận kết quả hoàn thiện theo cách lập trình, thay vì thông qua giao diện chat. Trên Atlas Cloud, bạn có thể truy cập toàn bộ dòng GPT 5.6, cùng với GPT 5.4 và GPT 5.5, thông qua một endpoint tương thích với OpenAI. Mỗi lệnh gọi được tính phí theo token với mô hình trả theo mức sử dụng minh bạch, nên bạn chỉ trả tiền cho những gì mình tạo ra.
Năm mô hình bao phủ nhiều nhu cầu, từ suy luận chuyên sâu đến chat hằng ngày. GPT 5.6 Sol hướng đến giải quyết vấn đề tham vọng và các workload tuyến đầu, GPT 5.6 Terra xử lý các quy trình sản xuất ổn định, còn GPT 5.6 Luna được tinh chỉnh cho hội thoại tự nhiên và tạo nội dung. GPT 5.4 và GPT 5.5 bổ sung khả năng suy luận đa phương thức và lập trình cho các nhóm cần hiệu năng đa dụng đã được kiểm chứng.
Tạo một API key, trỏ base URL của bạn đến https://api.atlascloud.ai/v1, rồi đặt model ID, chẳng hạn openai/gpt-5.6-terra. Vì ChatGPT API tại đây tương thích hoàn toàn với OpenAI, mã dùng OpenAI SDK hiện có sẽ chạy sau khi chỉ cần đổi base URL và key. Không có danh sách chờ hay gói đăng ký, và các bản phát hành mới có quyền truy cập Day-0, nên bạn có thể gửi yêu cầu đầu tiên ngay trong ngày.
Giá thay đổi theo mô hình bạn chọn. GPT 5.6 Luna tiết kiệm nhất ở mức $1 cho mỗi triệu input tokens và $6 cho mỗi triệu output tokens, GPT 5.6 Terra có giá $2.5 và $15, còn GPT 5.6 Sol ở mức $5 và $30. Prompt caching giúp giảm chi phí cho input lặp lại, và thanh toán vẫn theo mô hình trả theo mức sử dụng, nên bạn chỉ bị tính phí cho số token mình dùng.
Có. Endpoint tuân theo định dạng OpenAI Chat Completions, nên các OpenAI SDK chính thức, LangChain và hầu hết thư viện tương thích với OpenAI đều hoạt động sau khi bạn thay base URL và key. Điều này nghĩa là một tích hợp ChatGPT API hiện có có thể chuyển sang mà không cần viết lại logic yêu cầu.
Streaming và function calling đều hoạt động không đổi so với cách triển khai của OpenAI, nên bạn đặt stream thành true để nhận output theo từng token và truyền một mảng tools để kích hoạt function calls. Phản hồi JSON có cấu trúc tuân theo cùng định dạng yêu cầu tương thích với OpenAI, giúp việc điều phối agent và các pipeline trích xuất dữ liệu luôn dễ dự đoán.
Các mô hình này chấp nhận prompt lớn cho workflow xử lý tài liệu dài và toàn bộ repository. Giá được phân tầng tại mốc 272,000-token, với mức giá tiêu chuẩn cho prompt bên dưới mốc này và mức giá thứ hai cho prompt vượt quá 272,000 tokens. Vì vậy, bạn có thể đưa ngữ cảnh rất rộng vào một yêu cầu duy nhất và biết chính xác mức giá thay đổi ra sao khi prompt tăng lên.
Hãy ghép mô hình với công việc. Chọn GPT 5.6 Sol khi bạn cần suy luận tuyến đầu và giải quyết vấn đề tham vọng, chọn GPT 5.6 Terra cho phân tích có căn cứ, đạt chuẩn production, và dùng GPT 5.6 Luna cho công việc hội thoại hoặc sáng tạo khi chi phí là yếu tố quan trọng nhất. GPT 5.4 và GPT 5.5 vẫn là các lựa chọn đa phương thức mạnh cho lập trình và suy luận tổng quát.
Atlas Cloud vận hành ChatGPT API trên hạ tầng được quản lý, có khả năng mở rộng theo lưu lượng của bạn, nên bạn tránh được việc cấp phát GPU và điều phối node khi tự host. Các phiên bản mô hình mới có quyền truy cập Day-0, giúp bạn luôn cập nhật mà không cần công việc migration. Khi nhu cầu tăng lên, cùng một key tương thích với OpenAI bao phủ mọi mô hình trong họ này, nên mở rộng quy mô không bao giờ đồng nghĩa với một tích hợp mới.
Khám phá Thêm Dòng
Seedance 2.0
Seedance 2.0 API cung cấp cho bạn quyền truy cập cấp sản xuất vào mô hình video đa phương thức của ByteDance — đầu vào bốn phương thức (văn bản, hình ảnh, video, âm thanh) và hệ thống "Universal Reference" hàng đầu trong ngành giúp khóa bố cục, chuyển động của camera và hành động của nhân vật trên các cảnh quay. Tích hợp quyền kiểm soát cấp độ đạo diễn bằng một lệnh gọi API, mức giá cố định $0,09/giây, cấp khóa tức thì và không có danh sách chờ — được hỗ trợ bởi thời gian hoạt động và sự tuân thủ cấp doanh nghiệp. Seedance 2.0 Native 4K hiện đã ra mắt!
Grok Imagine
Grok Imagine API cung cấp cho các nhà phát triển khả năng tạo hình ảnh, video và âm thanh của xAI trong một bộ công cụ duy nhất. API này tạo ra hình ảnh độ phân giải lên đến 2K với khả năng hiển thị văn bản đa ngôn ngữ, cộng với video lên đến 15 giây với âm thanh gốc, được đồng bộ hóa và chỉnh sửa dựa trên tham chiếu. Trên Atlas Cloud, một khóa duy nhất có thể chạy mọi chế độ Grok Imagine, do đó bạn có thể chuyển đổi giữa hình ảnh, video và âm thanh mà không cần thiết lập riêng biệt, với mức giá từ 0,02 USD cho mỗi hình ảnh và 0,05 USD mỗi giây.
Gemini Omni Flash
Gemini Omni API đưa mô hình tạo và chỉnh sửa video đa phương thức của Google DeepMind, được giới thiệu tại Google I/O 2026, vào stack của bạn. Gemini Omni kết hợp công cụ suy luận của Gemini với media tạo sinh, chấp nhận mọi tổ hợp văn bản, hình ảnh, video và âm thanh để tạo ra kết quả nhất quán, dựa trên nền tảng tri thức. Tinh chỉnh kết quả qua hội thoại tự nhiên — hoán đổi vật thể, viết lại cảnh quay và thay đổi phong cách, trong khi vật lý, nhân vật và tính liên tục vẫn được giữ nguyên. Atlas Cloud cung cấp trọn bộ dòng Gemini Omni Flash — chuyển văn bản thành video, chuyển hình ảnh thành video với tối đa 7 hình ảnh tham chiếu, và chuyển tham chiếu thành video — thông qua một API hợp nhất với mức giá minh bạch tính theo giây từ $0.112 và không cần đăng ký thuê bao. Bắt đầu xây dựng ngay hôm nay.
GPT Image 2
GPT Image 2 API cung cấp cho các nhà phát triển quyền truy cập vào mô hình hình ảnh mới nhất của OpenAI, phiên bản kế nhiệm của GPT Image 1.5. Mô hình này tạo và chỉnh sửa hình ảnh với khả năng hiển thị văn bản chính xác trên các chữ viết Latinh và CJK, cùng với bố cục mạnh mẽ cho áp phích, mockup và đồ họa thông tin. Trên Atlas Cloud, bạn có thể truy cập nó thông qua một API thống nhất cùng với hơn 300 mô hình khác, với tín dụng miễn phí, 99,99% thời gian hoạt động và không yêu cầu xác minh tổ chức OpenAI.
Các mô hình sáng tạo mạnh mẽ nhất của Google hiện đều có sẵn trên Atlas Cloud. Veo 3.1 cung cấp khả năng tạo video đậm chất điện ảnh, Nano Banana 2 hỗ trợ tạo hình ảnh có độ chân thực cao, và Gemini mang trí tuệ đa phương thức vào mọi quy trình làm việc. Truy cập toàn bộ bộ mô hình Google thông qua một API key duy nhất với tính khả dụng Day-0 và mức giá dùng bao nhiêu trả bấy nhiêu (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini mang khả năng tạo video đa phương thức của ByteDance vào các quy trình làm việc nơi tốc độ và chi phí là quan trọng nhất. Nó cung cấp các khả năng cốt lõi của Seedance 2.0 với mức tiêu thụ tài nguyên nhẹ hơn — tạo nhanh hơn, chi phí mỗi video thấp hơn và tích hợp API giống như bạn đã sử dụng. Đối với các nhóm chạy các quy trình (pipeline) khối lượng lớn hoặc tạo nguyên mẫu ở quy mô lớn, Mini là lựa chọn mặc định thiết thực.
ByteDance
Từ tạo video điện ảnh đến kiến tạo hình ảnh có độ trung thực cao, các mô hình mạnh mẽ nhất của ByteDance hiện đã có mặt trên Atlas Cloud. Chạy Seedance và Seedream ở quy mô lớn với mức giá suy luận thấp nhất và không có chi phí quản lý cơ sở hạ tầng.
Alibaba
Atlas Cloud tập hợp toàn bộ dòng mô hình của Alibaba dưới một API duy nhất: Qwen cho các tác vụ ngôn ngữ và hình ảnh, Wan để tạo video với độ phân giải lên đến 1080p. Truy cập mọi mô hình theo hình thức dùng đến đâu trả tiền đến đó (pay-as-you-go) mà không cần đăng ký gói. Alibaba API có sẵn thông qua một URL cơ sở (base URL) duy nhất bằng cách sử dụng ứng dụng khách tương thích với OpenAI hiện có của bạn.
OpenAI
Atlas Cloud cấp cho bạn quyền truy cập vào toàn bộ danh mục OpenAI API, từ GPT Image 2 để tạo hình ảnh đến Sora 2 cho video. Mọi mô hình đều có sẵn theo hình thức dùng đến đâu trả tiền đến đó (pay-as-you-go) mà không cần cam kết hàng tháng. Tích hợp dễ dàng chỉ bằng cách thay đổi một base URL thông qua API tương thích với OpenAI.
xAI
Xây dựng các pipeline hình ảnh và video hoàn chỉnh bằng xAI API trên Atlas Cloud. Tạo ở độ phân giải 2K, chỉnh sửa bằng hình ảnh tham chiếu và tạo hoạt ảnh từ hình ảnh thành các clip đồng bộ với âm thanh.
Kwaivgi
Kwaivgi API với mức giá thấp hơn 15% so với giá tiêu chuẩn. Atlas Cloud cung cấp quyền truy cập Day-0 cho các bản phát hành Kling mới với mức giá dùng trả theo mức sử dụng (pay-as-you-go) và không giới hạn số lượng người dùng. Một tài khoản, một khóa, mọi mô hình Kling từ cấp tiêu chuẩn đến cấp master.
Seedream 5.0 Pro
Seedream 5.0 Pro API cung cấp cho các nhà phát triển mô hình chỉnh sửa hình ảnh có thể kiểm soát của ByteDance trên Atlas Cloud. Nó đặt các chỉnh sửa một cách chính xác bằng các điểm neo và tọa độ, tách hình ảnh thành các lớp có thể chỉnh sửa, kết hợp nhiều tham chiếu và khớp màu sắc cũng như vật liệu chính xác, với văn bản đa ngôn ngữ ở độ phân giải 2K và 3K. Trên Atlas Cloud, bạn có thể truy cập nó chỉ bằng một khóa!


