Gemini Omni Flash API for Conversational Video Editing
Gemini Omni API đưa mô hình tạo và chỉnh sửa video đa phương thức của Google DeepMind, được giới thiệu tại Google I/O 2026, vào stack của bạn. Gemini Omni kết hợp công cụ suy luận của Gemini với media tạo sinh, chấp nhận mọi tổ hợp văn bản, hình ảnh, video và âm thanh để tạo ra kết quả nhất quán, dựa trên nền tảng tri thức. Tinh chỉnh kết quả qua hội thoại tự nhiên — hoán đổi vật thể, viết lại cảnh quay và thay đổi phong cách, trong khi vật lý, nhân vật và tính liên tục vẫn được giữ nguyên. Atlas Cloud cung cấp trọn bộ dòng Gemini Omni Flash — chuyển văn bản thành video, chuyển hình ảnh thành video với tối đa 7 hình ảnh tham chiếu, và chuyển tham chiếu thành video — thông qua một API hợp nhất với mức giá minh bạch tính theo giây từ $0.112 và không cần đăng ký thuê bao. Bắt đầu xây dựng ngay hôm nay.
Khám phá Mô hình Hàng đầu
Atlas Cloud cung cấp cho bạn các mô hình sáng tạo tiên tiến nhất trong ngành.







Bốn cách tạo với Gemini Omni Flash API
Chọn điểm cuối API Gemini Omni Flash phù hợp với công việc của bạn, từ chuyển đổi văn bản thành video và hình ảnh thành video cho đến tạo nội dung dựa trên tham chiếu và chỉnh sửa qua hội thoại.
| Phương thức | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | Bạn chỉ có một lời nhắc văn bản? Gemini Omni Flash Text-to-Video API sẽ chuyển đổi nó thành một đoạn video 720p với âm thanh đồng bộ chỉ trong một lần xử lý, tuân theo sự điều hướng dựa trên suy luận về cảnh, chuyển động và camera cho các đoạn video dài tối đa 10 giây. |
| Gemini Omni Flash Image-to-Video API (I2V) | Gemini Omni Flash Image-to-Video API tạo hoạt ảnh biến một hình ảnh tĩnh thành chuyển động, cố định ảnh gốc làm khung hình mở đầu. Với chuyển động tự nhiên và âm thanh đồng bộ, API này mang các bức ảnh chụp sản phẩm, ảnh chân dung và các ý tưởng vào cuộc sống ở độ phân giải 720p. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Hướng dẫn quá trình tạo bằng tối đa bảy hình ảnh tham chiếu và ba đoạn video ngắn bằng Gemini Omni Flash Reference-to-Video API. Nó giữ cho nhân vật, phong cách và bối cảnh nhất quán trên toàn bộ đoạn phim, lý tưởng cho nội dung có thương hiệu và nội dung dài kỳ. |
| Gemini Omni Flash Video Edit API | Khi một video clip cần thay đổi, Gemini Omni Flash Video Edit API sẽ áp dụng các lệnh bằng ngôn ngữ tự nhiên thông qua một Interactions API có trạng thái (stateful). Nó hoán đổi các thành phần, điều chỉnh ánh sáng và thay đổi phong cách của các cảnh, trong khi vẫn giữ nguyên phần còn lại của cảnh quay qua các lượt tương tác. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
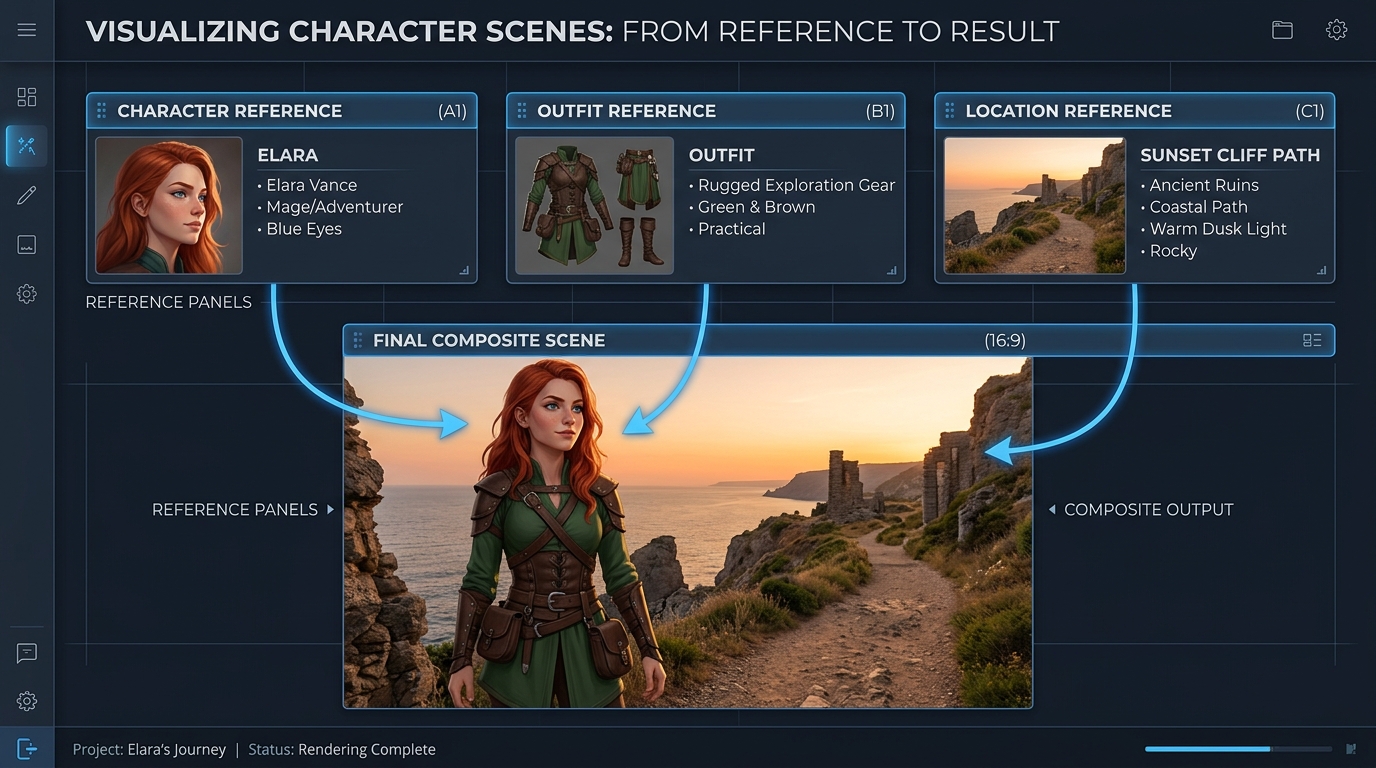
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
So sánh Gemini Omni Flash API
Xem các mô hình từ các nhà cung cấp khác nhau so sánh như thế nào — so sánh hiệu suất, giá cả và điểm mạnh độc đáo để đưa ra quyết định sáng suốt.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Chỉnh sửa video đã hoàn thiện thông qua hội thoại | Yes | Có, có trạng thái | Văn bản, hình ảnh, video, âm thanh |
| Veo 3.1 | Các đoạn video chuẩn điện ảnh với tính năng mở rộng cảnh | Yes | No | Văn bản, hình ảnh, tham chiếu |
| Seedance 2.0 | Video điều khiển bằng tham chiếu chất lượng đỉnh cao | Yes | No | Văn bản, hình ảnh, video, âm thanh |
| Kling 3.0 | Kể chuyện đa cảnh quay do AI đạo diễn | Yes | No | Văn bản, hình ảnh, tham chiếu |
Cách Sử Dụng Gemini Omni Flash trên Atlas Cloud
Bắt đầu trong vài phút — làm theo các bước đơn giản sau để tích hợp và triển khai mô hình qua nền tảng Atlas Cloud.
Tạo Tài Khoản Atlas Cloud
Đăng ký tại atlascloud.ai và hoàn tất xác minh. Người dùng mới nhận được tín dụng miễn phí để khám phá nền tảng và thử nghiệm mô hình.
Tại sao Sử dụng Gemini Omni Flash trên Atlas Cloud
Sự kết hợp của các mô hình tiên tiến của Gemini Omni Flash với nền tảng được tăng tốc GPU của Atlas Cloud mang lại hiệu suất, khả năng mở rộng và trải nghiệm nhà phát triển độc đáo.
Hiệu suất và Tính linh hoạt
Độ Trễ Thấp:
Suy luận được tối ưu hóa GPU cho suy luận thời gian thực.
API Thống nhất:
Chạy Gemini Omni Flash, GPT, Gemini và DeepSeek với một tích hợp duy nhất.
Giá cả Minh bạch:
Thanh toán dựa trên token có thể dự đoán với tùy chọn serverless.
Doanh nghiệp và Mở rộng
Trải nghiệm Nhà phát triển:
SDK, phân tích, công cụ tinh chỉnh và mẫu.
Độ tin cậy:
99,99% khả dụng, RBAC và ghi nhật ký sẵn sàng cho tuân thủ.
Bảo mật và Tuân thủ:
SOC 2 Type II, tuân thủ HIPAA, chủ quyền dữ liệu tại Hoa Kỳ.
Câu hỏi thường gặp về Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Khám phá Thêm Dòng
Seedance 2.0
Seedance 2.0 API cung cấp cho bạn quyền truy cập cấp sản xuất vào mô hình video đa phương thức của ByteDance — đầu vào bốn phương thức (văn bản, hình ảnh, video, âm thanh) và hệ thống "Universal Reference" hàng đầu trong ngành giúp khóa bố cục, chuyển động của camera và hành động của nhân vật trên các cảnh quay. Tích hợp quyền kiểm soát cấp độ đạo diễn bằng một lệnh gọi API, mức giá cố định $0,09/giây, cấp khóa tức thì và không có danh sách chờ — được hỗ trợ bởi thời gian hoạt động và sự tuân thủ cấp doanh nghiệp. Seedance 2.0 Native 4K hiện đã ra mắt!
Grok Imagine
Grok Imagine API cung cấp cho các nhà phát triển khả năng tạo hình ảnh, video và âm thanh của xAI trong một bộ công cụ duy nhất. API này tạo ra hình ảnh độ phân giải lên đến 2K với khả năng hiển thị văn bản đa ngôn ngữ, cộng với video lên đến 15 giây với âm thanh gốc, được đồng bộ hóa và chỉnh sửa dựa trên tham chiếu. Trên Atlas Cloud, một khóa duy nhất có thể chạy mọi chế độ Grok Imagine, do đó bạn có thể chuyển đổi giữa hình ảnh, video và âm thanh mà không cần thiết lập riêng biệt, với mức giá từ 0,02 USD cho mỗi hình ảnh và 0,05 USD mỗi giây.
Gemini Omni Flash
Gemini Omni API đưa mô hình tạo và chỉnh sửa video đa phương thức của Google DeepMind, được giới thiệu tại Google I/O 2026, vào stack của bạn. Gemini Omni kết hợp công cụ suy luận của Gemini với media tạo sinh, chấp nhận mọi tổ hợp văn bản, hình ảnh, video và âm thanh để tạo ra kết quả nhất quán, dựa trên nền tảng tri thức. Tinh chỉnh kết quả qua hội thoại tự nhiên — hoán đổi vật thể, viết lại cảnh quay và thay đổi phong cách, trong khi vật lý, nhân vật và tính liên tục vẫn được giữ nguyên. Atlas Cloud cung cấp trọn bộ dòng Gemini Omni Flash — chuyển văn bản thành video, chuyển hình ảnh thành video với tối đa 7 hình ảnh tham chiếu, và chuyển tham chiếu thành video — thông qua một API hợp nhất với mức giá minh bạch tính theo giây từ $0.112 và không cần đăng ký thuê bao. Bắt đầu xây dựng ngay hôm nay.
GPT Image 2
GPT Image 2 API cung cấp cho các nhà phát triển quyền truy cập vào mô hình hình ảnh mới nhất của OpenAI, phiên bản kế nhiệm của GPT Image 1.5. Mô hình này tạo và chỉnh sửa hình ảnh với khả năng hiển thị văn bản chính xác trên các chữ viết Latinh và CJK, cùng với bố cục mạnh mẽ cho áp phích, mockup và đồ họa thông tin. Trên Atlas Cloud, bạn có thể truy cập nó thông qua một API thống nhất cùng với hơn 300 mô hình khác, với tín dụng miễn phí, 99,99% thời gian hoạt động và không yêu cầu xác minh tổ chức OpenAI.
Các mô hình sáng tạo mạnh mẽ nhất của Google hiện đều có sẵn trên Atlas Cloud. Veo 3.1 cung cấp khả năng tạo video đậm chất điện ảnh, Nano Banana 2 hỗ trợ tạo hình ảnh có độ chân thực cao, và Gemini mang trí tuệ đa phương thức vào mọi quy trình làm việc. Truy cập toàn bộ bộ mô hình Google thông qua một API key duy nhất với tính khả dụng Day-0 và mức giá dùng bao nhiêu trả bấy nhiêu (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini mang khả năng tạo video đa phương thức của ByteDance vào các quy trình làm việc nơi tốc độ và chi phí là quan trọng nhất. Nó cung cấp các khả năng cốt lõi của Seedance 2.0 với mức tiêu thụ tài nguyên nhẹ hơn — tạo nhanh hơn, chi phí mỗi video thấp hơn và tích hợp API giống như bạn đã sử dụng. Đối với các nhóm chạy các quy trình (pipeline) khối lượng lớn hoặc tạo nguyên mẫu ở quy mô lớn, Mini là lựa chọn mặc định thiết thực.
ByteDance
Từ tạo video điện ảnh đến kiến tạo hình ảnh có độ trung thực cao, các mô hình mạnh mẽ nhất của ByteDance hiện đã có mặt trên Atlas Cloud. Chạy Seedance và Seedream ở quy mô lớn với mức giá suy luận thấp nhất và không có chi phí quản lý cơ sở hạ tầng.
Alibaba
Atlas Cloud tập hợp toàn bộ dòng mô hình của Alibaba dưới một API duy nhất: Qwen cho các tác vụ ngôn ngữ và hình ảnh, Wan để tạo video với độ phân giải lên đến 1080p. Truy cập mọi mô hình theo hình thức dùng đến đâu trả tiền đến đó (pay-as-you-go) mà không cần đăng ký gói. Alibaba API có sẵn thông qua một URL cơ sở (base URL) duy nhất bằng cách sử dụng ứng dụng khách tương thích với OpenAI hiện có của bạn.
OpenAI
Atlas Cloud cấp cho bạn quyền truy cập vào toàn bộ danh mục OpenAI API, từ GPT Image 2 để tạo hình ảnh đến Sora 2 cho video. Mọi mô hình đều có sẵn theo hình thức dùng đến đâu trả tiền đến đó (pay-as-you-go) mà không cần cam kết hàng tháng. Tích hợp dễ dàng chỉ bằng cách thay đổi một base URL thông qua API tương thích với OpenAI.
xAI
Xây dựng các pipeline hình ảnh và video hoàn chỉnh bằng xAI API trên Atlas Cloud. Tạo ở độ phân giải 2K, chỉnh sửa bằng hình ảnh tham chiếu và tạo hoạt ảnh từ hình ảnh thành các clip đồng bộ với âm thanh.
Kwaivgi
Kwaivgi API với mức giá thấp hơn 15% so với giá tiêu chuẩn. Atlas Cloud cung cấp quyền truy cập Day-0 cho các bản phát hành Kling mới với mức giá dùng trả theo mức sử dụng (pay-as-you-go) và không giới hạn số lượng người dùng. Một tài khoản, một khóa, mọi mô hình Kling từ cấp tiêu chuẩn đến cấp master.
Seedream 5.0 Pro
Seedream 5.0 Pro API cung cấp cho các nhà phát triển mô hình chỉnh sửa hình ảnh có thể kiểm soát của ByteDance trên Atlas Cloud. Nó đặt các chỉnh sửa một cách chính xác bằng các điểm neo và tọa độ, tách hình ảnh thành các lớp có thể chỉnh sửa, kết hợp nhiều tham chiếu và khớp màu sắc cũng như vật liệu chính xác, với văn bản đa ngôn ngữ ở độ phân giải 2K và 3K. Trên Atlas Cloud, bạn có thể truy cập nó chỉ bằng một khóa!


