
每位開發人員都懂那種痛苦:你發現了一個卓越的 API,但遷移過程卻看起來遙不可及。你必須更新無數的整合項目並重寫驗證邏輯,任何一個錯誤步驟都可能導致整個生產環境崩潰。這就是「遷移稅」——它讓大多數團隊在開始之前就選擇了放棄。這份 影片管道遷移指南 (video pipeline migration guide) 以 Atlas Cloud 作為參考實作,詳細拆解了如何安全地進行切換。
舊系統的更新是一場災難。持續的崩潰、層出不窮的 Bug 和高昂的培訓成本不斷堆積。這種壓力迫使許多團隊只能繼續使用早該淘汰的舊工具。
AI 影片生成 API 整合與 Atlas Cloud:隨插即用,無需重構
Atlas Cloud 的 AI 影片工作流 API 設計核心只有一個原則:融入你現有的架構。無論你是從既有的圖像與影片生成 API 拉取資料,還是連接到地端管道,Atlas Cloud 的 AI 影片生成 API 整合 都能在不要求全面重寫的情況下,無縫疊加在你的當前技術棧之上。
它的獨特之處
| 考量點 | 傳統遷移 | Atlas Cloud 方案 |
| 程式碼變更 | 大規模重構 | 極簡轉接層 (Adapter Layer) |
| 停機風險 | 高 | 低—支援平行部署 |
| 舊系統相容性 | 經常中斷 | 保留現有端點 |
從小規模開始,驗證後再擴展——無需在基礎架構維護上浪費一個衝刺週期 (Sprint)。
為什麼現在是遷移影片管道的時機?
如果你的影片管道是三年前建構的,那麼它是為轉碼與縮圖生成的時代所設計的,而非生成式 AI 時代。如今,這種技術落差表現為實際的營運痛苦;對於擴展生成式功能的團隊而言,降低 AI 推論成本已成為最緊迫的工程優先事項。
- 高昂的推論成本: 按需運行龐大的影片模型會讓雲端帳單飆升。若缺乏智慧批次處理或成本上限機制,每月支出將變得難以預測。
- GPU 短缺: 晶片供應不足與漫長的等待時間導致嚴重延遲。這些延遲通常發生在最糟糕的時間點,例如大型產品發佈期間。
- 嚴苛的速率限制 (Rate Limits): 大多數生成 API 都有無法隨需求擴展的固定限制。這迫使團隊必須支付額外容量費用,或被迫減緩應用程式速度。
AI 推論成本是擴展生成式功能的產品團隊中成長最快的開支項目之一。要實現有意義的 AI 推論成本降低,不僅需要架構調整,還需要選擇正確的 API 層——而不僅僅是談判更優惠的價格。
AI 推論成本:舊有管道 vs. Atlas Cloud 整合:
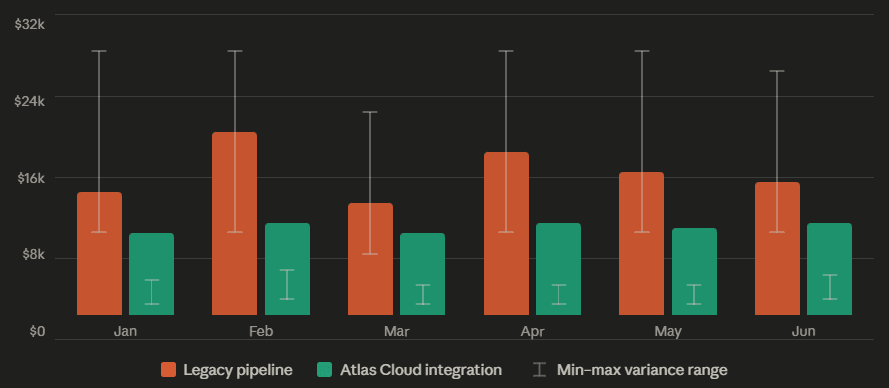
基於典型中型市場影片團隊的規模
平均節省:約 39% · 變異數降低:約 85%
轉向多模態——為何靜態工作流無法跟上?
傳統的影片管道是線性的:攝取 → 轉碼 → 交付。生成式 AI 影片工作流 的需求有本質上的不同。正如你在任何實用的影片管道遷移指南中所見,核心挑戰不僅在於工具,更在於重新思考架構。模型現在可以單次請求處理文字轉影片提示詞、影像條件設定以及多步驟生成鏈。
舊系統整合並非為此而建。將生成式模型強行植入靜態管道通常意味著:
| 舊管道假設 | 生成式現實 |
| 固定輸入/輸出格式 | 動態、模型依賴的輸出 |
| 可預測的運算時間 | 可變的推論持續時間 |
| 每個任務使用一個模型 | 多模型鏈式運作 |
Atlas Cloud 的 AI 影片生成 API 整合透過將多模態、多步驟工作流視為一等公民設計模式而非事後彌補,解決了上述問題。
映射架構:AI 影片生成 API 整合如何融入你的技術棧
將 Atlas Cloud 視為一座智慧橋樑,而非取代你基礎設施的產品。它位於你的主應用程式與繁重的 AI 處理任務之間。當前端發出請求時,Atlas Cloud 負責路由與模型執行。它會返回乾淨的回應,而你的內部服務完全無需感知背後發生的複雜運作。
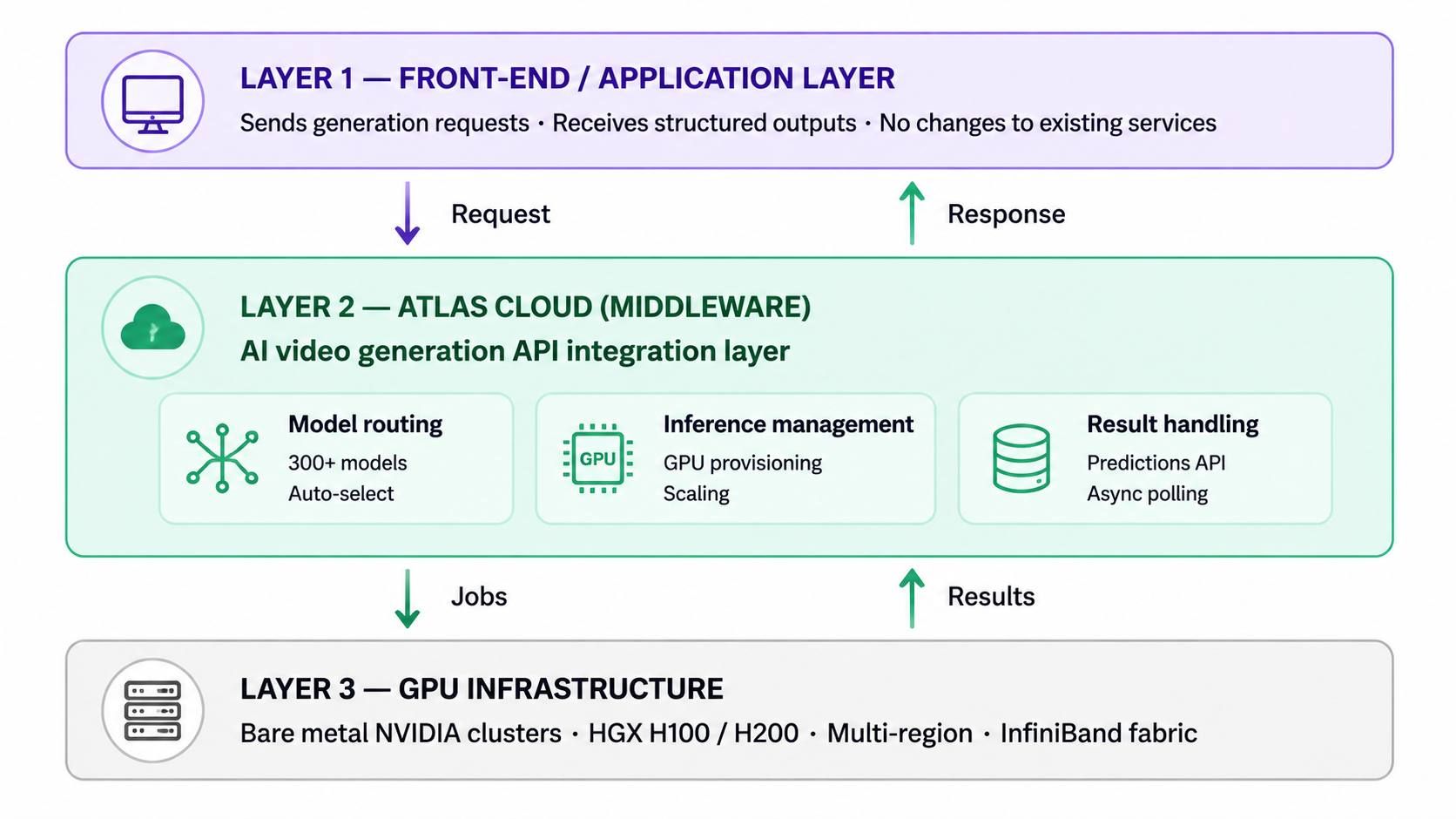
這種中間件模式使 AI 影片生成 API 整合對於擁有成熟管道的團隊來說切實可行。你無需拆除既有的運作架構,只需在處理層插入 Atlas Cloud。它負責:
- 模型路由 — 在 300 多個 AI 模型間導向請求,包括驅動你 AI 影片工作流的模型。
- 推論管理 — 將 GPU 配置與擴展抽象化,統一於單一端點。
- 結果處理 — 透過其 Predictions API 以一致且可預測的格式返回生成輸出。
相容層:接軌你現有的架構
舊系統整合常因新工具要求新工具鏈而停滯。Atlas Cloud 透過提供以下功能避開了此問題:
| 整合介面 | 細節 |
| API 風格 | RESTful,與 OpenAI 相容的端點 |
| SDK 支援 | Python、Node.js 及任何 HTTP 客戶端 |
| 驗證 | 標準 API 金鑰驗證 |
| 模型範疇 | 單一金鑰涵蓋 LLM、圖像與影片生成 API |
與 OpenAI 相容的設計特別實用——已經使用 OpenAI SDK 的團隊只需切換基礎 URL,即可存取 Atlas Cloud 的完整模型目錄,包括 影片生成 和 圖像生成 模型,且幾乎無需更改程式碼。
舊有管道 vs. 多模態 AI 影片工作流:
| 維度 | 舊有管道 | 多模態 AI 工作流 (Atlas Cloud) |
| 處理模式 | 線性:攝取 → 轉碼 → 交付。每個階段需等待前一階段完成。 | 平行多步驟:文字提示、圖像條件設定與生成鏈在單一生命週期中處理。 |
| 延遲配置 | 可預測但緩慢。轉碼受限;不原生支援生成任務。 | 依模型而異,但透過非同步輪詢管理。使用專用端點可縮小 P50/P95 變異。 |
| 結構彈性 | 專有的內部架構。整合新模型需徹底重寫轉接器。 | 與 OpenAI 相容的 REST。切換基礎 URL;現有的 SDK 呼叫與驗證中間件可直接沿用。 |
| GPU 依賴 | 自行管理 Spot 實例。短缺時會在高峰期導致隊列尖峰。 | 抽象化於單一端點。自動擴展 0 → 800 個 GPU;無需手動配置。 |
| 成本模型 | 全天候配置。團隊為了避免節流而過度配置,為閒置容量付費。 | Serverless 層級按請求計費。高流量工作負載可使用具可預測定價的專用端點。 |
| 遷移成本 | — | 3 步驟:驗證同步 → 負載映射 → 非同步輪詢。無需停機;可與現有架構並行運行。 |
3 步驟影片管道遷移指南:實現零停機連接
切換 API 不代表必須凍結服務。這份影片管道遷移指南將逐步說明如何將 Atlas Cloud 接入現行堆疊,而無需關閉正在運行的服務。
第 1 步:驗證與環境同步
Atlas Cloud 透過 Authorization 標頭中的 Bearer token 驗證每個請求,這與大多數現代 REST API 使用的模式相同,代表你的現有驗證中間件幾乎無需更動。
安全設定清單:
| 任務 | 建議 |
| 儲存 API 金鑰 | 使用環境變數 (ATLAS_API_KEY),切勿硬編碼 |
| 標頭格式 | Authorization: Bearer <your_api_key> |
| 基礎 URL | https://api.atlascloud.ai/v1 |
| 金鑰輪替 | 直接從 Atlas Cloud 儀表板 生成新金鑰,無需更動程式碼 |
將你的金鑰排除在版本控制之外。至少應將 .env 檔案加入 .gitignore;在生產環境中則建議使用祕密管理服務 (Secrets Manager)。
第 2 步:映射資料負載
Atlas Cloud 目錄中的每個模型(無論是圖像與影片生成 API 還是 LLM)都透過一個 model 欄位來識別目標(例如:kling-video/v1.6/standard/image-to-video)。這正是舊系統整合團隊花費最多時間的地方:將內部的專有 JSON 結構轉換為模型所需的格式。
實用的映射方法:
- 審查現有負載 — 識別 input_url、解析度、時長與提示詞等需要重命名或重組的欄位。
- 參考模型參數規格 — 在撰寫任何轉換邏輯前,參考 Model APIs 文件。
- 撰寫精簡的轉接函式 — 建立一個接收內部結構並輸出 Atlas Cloud 相容主體的函式,將轉換邏輯隔離,以便在模型版本更新時輕鬆調整。
第 3 步:非同步結果輪詢
影片生成並非即時完成。提交請求後會返回一個 request_id;接著你的應用程式需輪詢 GET /api/v1/model/result/{request_id},直到 status 欄位變為完成狀態,且 outputs 陣列完成填充。
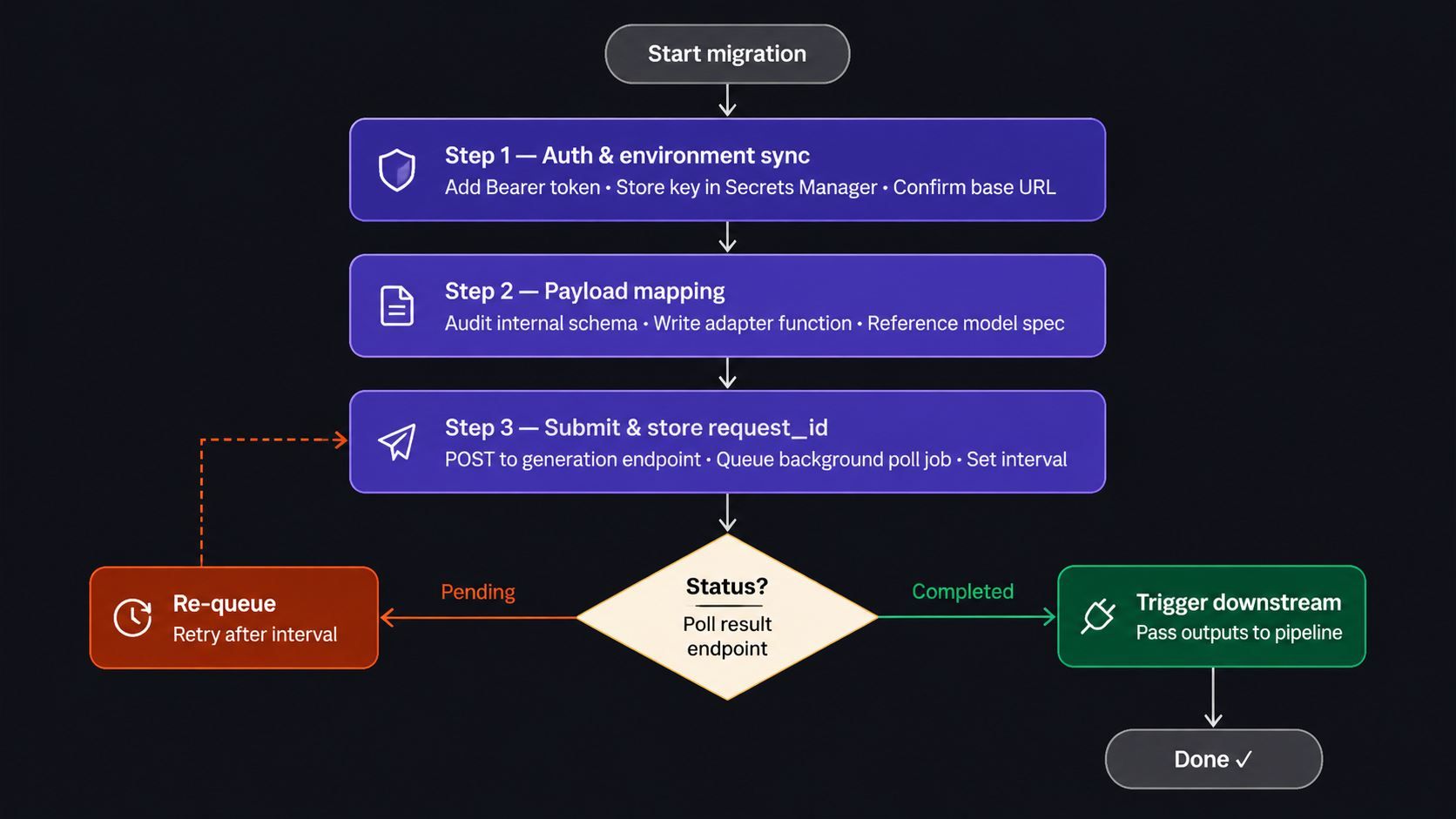
為確保在 AI 影片工作流渲染期間應用程式不被阻塞:
- 提交生成請求並儲存返回的 request_id。
- 排入背景作業(例如透過 Celery 或 BullMQ 等任務佇列),以合理的間隔輪詢結果端點。
- 觸發下游邏輯 — 僅在狀態確認完成後,將輸出結果傳遞至你的交付管道。
這將渲染時間與 API 回應延遲解耦,確保使用者端的介面始終保持響應。
解決冷啟動與延遲——降低 AI 推論成本的隱形推手
沒什麼比緩慢的首回應時間和不可預測的渲染效能更讓利害關係人對新 AI 影片工作流失去信心了。解決這些問題也是任何嚴肅的 AI 推論成本降低策略的核心——因為延遲變異會迫使過度配置資源,從而推高成本。
邊緣處理 vs. 雲端集中化
AI 推論的延遲往往既是地理問題也是硬體問題。請求傳輸到 GPU 的距離越遠,你的管道感覺就越慢——無論模型本身多強大。
Atlas Cloud 在多個區域運行裸機 (Bare Metal) GPU 叢集,讓團隊能夠選擇將工作負載路由到更靠近使用者或資料來源的地方:
| GPU 模型 | 位置 | 數量 | 定價 ($/GPU/小時) | 網路 |
| H100 | EU | 200 | $1.95 | IB |
| 新加坡 | 32 | $2.10 | IB | |
| 美國 | 16 | $2.10 | IB | |
| H200 | 美國 | 128 | $2.35 | RoCe |
| 日本 | 8 | $2.40 | IB | |
| EU | 16 | $2.40 | IB | |
| 新加坡 | 8 | $2.40 | IB | |
| 美國 | 8 | $2.40 | IB | |
| GB200 | 馬來西亞 | 8 | $4.50 | IB |
| A100 | 美國 | 64 | $1.35 | / |
與虛擬化雲端環境不同,裸機實例讓你的 AI 影片工作流能直接存取 NVIDIA 硬體——沒有會侵蝕推論吞吐量的 Hypervisor 開銷。Atlas 的 HGX H100 和 H200 叢集使用針對平行生成任務優化的 InfiniBand 設計,可最小化節點間延遲。
對於使用 Serverless 層級的團隊,Atlas Cloud 的專用端點 (Dedicated Endpoint) 可在幾秒鐘內將容量從 0 擴展至 800 個 GPU,並聲稱相比標準 Serverless 部署,冷啟動時間減少了 90%——解決了流量尖峰期間最常見的延遲投訴。
效能基準測試:提交前應衡量的指標
任何廠商的基準測試都無法取代你自己的工作負載測試。在針對現有圖像與影片生成 API 進行 Atlas Cloud 整合壓力測試時,請專注於以下三個指標:
| 指標 | 重要性 | 目標閾值 | 需監控的訊號 |
| P50 渲染時間 | 大多數請求的中位數體驗,代表使用者預期基準。 | 15秒影片 ≤ 8秒 | 若 P50 已高於目標,架構在擴展後將難以改進。 |
| P95 渲染時間 | 變異是真正的成本驅動因素。不可預測的尾端延遲迫使過度配置。 | ≤ 2x P50 | P50 為 8 秒但 P95 為 45 秒的管道,比 P50 為 12 秒但 P95 為 14 秒的管道糟糕得多。 |
| 冷啟動延遲 | 閒置期間的首個請求延遲,流量尖峰期間的主要 UX 投訴點。 | 至首個 Token ≤ 3秒 | 比較專用端點與 Serverless 層級。Atlas Cloud 宣稱較標準 Serverless 減少 90%。 |
| 負載下的錯誤率 | 速率限制與 GPU 短缺在生產規模下會轉化為錯誤而非單純變慢。 | 峰值 RPS 時 < 0.5% | 以預期峰值的 2 倍進行壓力測試。任何 > 1% 的錯誤率皆代表爆發空間不足。 |
| 輸出一致性 | 生成模型在相同提示詞下可能在解析度、格式或偽影率上出現飄移。 | 100% 規格相符格式 | 記錄 50 次以上相同運行下的解析度、編解碼器與檔案大小變異。標記 > ±10% 的異常值。 |
| 單位渲染成本 | 決定整合在大規模下是否能實現獲利的單位經濟效益。 | 追蹤對比現有供應商 | 比較包括閒置 GPU 時間在內的總成本,而不僅僅是按請求定價。Atlas Cloud:Serverless 層級按請求計費。 |
執行平行測試: 試著進行一些對照測試。同時向現有架構和 Atlas Cloud 發送完全相同的提示詞。檢查渲染速度、最終品質以及故障頻率。大多數團隊意識到,最大的勝利不僅在於速度,而在於可靠性。擁有穩定的 8 秒等待時間,遠勝於無法預測任務需要 3 秒還是 25 秒。
現實世界整合情境
上述架構討論在映射到大多數團隊現行系統時會變得具體。以下兩個情境代表了基於 Atlas Cloud 驗證能力所建構的常見整合模式。
情境 A — 創意套件:CMS 觸發的社群影片預覽
設定: 一家數位媒體集團使用 Contentful 或 Sanity 等 Headless CMS 發布報導。每篇新文章都需要一段 15 秒的社群影片。手動製作這些影片太慢,造成撰稿人員與社群團隊間的巨大瓶頸。
Atlas Cloud API 整合如何融入:

| 管道階段 | 工具 / 系統 | Atlas Cloud 角色 |
| 發佈觸發 | CMS Webhook | 接收包含文章元資料的 POST 事件 |
| 提示詞建構 | 內部中間件 | 從標題 + 縮圖 URL 組裝文字提示詞 |
| 影片生成 | Atlas Cloud Video API | 透過統一端點呼叫 Kling 或 Hailuo 等模型 |
| 結果交付 | CMS 資產欄位 | 輪詢 GET /api/v1/model/result/{request_id} 並將輸出 URL 回寫 |
由於 Atlas Cloud 的圖像與影片生成 API 接受具備 Bearer 驗證的標準 REST 呼叫,CMS 整合僅需輕量級 Serverless 函式即可完成——無需新基礎設施,無需專用 GPU 採購。按請求計費模式也意味著團隊僅在內容發佈時才付費,無需為閒置容量買單。
此案例的主要優勢: 自動化從發佈事件到渲染資產的 AI 影片工作流,編輯與創意團隊間無需手動交接。
情境 B — 企業沙盒:DAM 大規模影片增強
設定: 某大品牌的數位資產管理 (DAM) 系統中存有數千個現有產品影片——許多解析度已過時或缺少品牌專屬的動態疊層。任務是在不重建 DAM 整合層的情況下,大規模增強並重新渲染這些影片。
Atlas Cloud 如何介入:

- 保留舊系統整合:DAM 匯出任務清單(包含資產 URL 與目標規格的 JSON 列表),該清單可直接映射到 Atlas Cloud 的模型輸入結構。
- 透過 LoRA/QLoRA 微調模型:可針對品牌特定的視覺風格進行訓練,並部署為專用推論端點——確保成千上萬個資產的輸出一致性 (Atlas Cloud 微調)。
- Serverless 擴展處理突發工作負載:500 個資產的批次作業可自動擴展至所需的 GPU 容量,無需手動配置叢集。
- 統一儲存:微調模型權重、輸入資產與渲染輸出皆可在單一位置存取。
此案例的主要優勢: 大規模實現品牌一致的影片增強,無需重構 DAM 系統或管理專用 GPU 基礎設施。
未來考量:隱私與擴展性
隱私至上
對於在 AI 影片工作流中處理敏感資產的團隊,Atlas Cloud 的合規性是在基礎設施層級建構的——而非事後添加。平台在所有層級皆持有 SOC I & II 認證與 HIPAA 合規性,並提供「安全、全託管」的微調管道。
對於受監管產業的舊系統整合,這移除了常見的障礙:向安全團隊證明新 API 供應商符合現有資料治理標準,且無需進行自定義審核。
無需手動干預的擴展
規模成長是許多 圖像與影片生成 API 悄然崩潰的地方。Atlas Cloud 的專用端點直接解決了這個問題:
| 擴展觸發 | Atlas Cloud 回應 |
| 流量尖峰 | 幾秒鐘內擴展 0 → 800 個 GPU |
| 冷啟動 | 較標準 Serverless 減少 90% |
| 計費模式 | 僅按請求計費 — 無閒置 GPU 成本 |
從 10 個請求到 10,000 個請求,無需進行任何手動基礎設施調整。相同的 Atlas Cloud API 整合即可處理兩者,將容量規劃轉變為計費溝通,而非工程負擔。






