
أنت تعرف هذا الشعور.
لقد تأخر الوقت. لقد قمت بإجراء أربعة تعديلات على حملة تجارية. لقد ولّد الذكاء الاصطناعي إضاءة مثالية في لقطة البطل، لكن وجه العارض تغير بشكل طفيف للمرة الثالثة الليلة. نفس الزي. شخص مختلف. لا يمكنك نشره. لا يمكنك إصلاحه. تبدأ من جديد.
بحلول منتصف الليل، لم تعد تحرر فيديو. أنت تلعب الروليت.
بالنسبة لأي شخص يحاول بناء استمرارية سردية - عرض توضيحي لمنتج مع نفس العارض عبر اللقطات، أو درس تعليمي مع نفس المعلم عبر المشاهد، أو فيديو موسيقي مع نفس المغني عبر التقطيعات - كان "انحراف الشخصية" (character drift) هو القاتل الصامت لكل أدوات الفيديو المعتمدة على الذكاء الاصطناعي. وهذا هو السبب في أن فيديو الذكاء الاصطناعي ظل حبيس "العروض التوضيحية الرائعة" بدلاً من التحول إلى المجال التجاري.

في 19 مايو في مؤتمر I/O 2026، قدم Gemini Omni من Google دليلاً على أن هذا العصر أوشك على الانتهاء.
تتلخص الوعود بأكملها في سطر واحد على صفحة منتجات Google DeepMind: "كل تعديل تجريه يبني على ما قبله — مما يحافظ على مشهد متسق ومترابط."
العرض التوضيحي لعازف الكمان المكون من ثلاث خطوات الذي صنع التاريخ بهدوء
لم تكن اللحظة الأكثر أهمية في إعلان I/O هي الكرة المتدحرجة، ولم تكن منحوتة الفقاعات. لقد كان عازف كمان.
إليك التسلسل الدقيق الذي عرضته Google على المسرح ونشرته في مدونتها:
- الخطوة الأولى: فيديو أساسي لعازف كمان يعزف أغنية على المسرح.
- الخطوة الثانية: أمر توجيهي — "انقل عازف الكمان إلى بيئة الصورة." النتيجة: تم نقل العازف إلى خلفية جديدة، ولكن الوجه والوضعية وقبضة القوس وحتى زاوية المعصم ظلت متطابقة.
- الخطوة الثالثة: أمر توجيهي آخر — "غيّر زاوية الكاميرا لتكون فوق كتف عازف الكمان." النتيجة: تأطير جديد. نفس عازف الكمان. نفس الهوية. نفس الأداء.
ثلاثة تحولات. موضوع واحد. صفر انحراف.
إذا كنت قد قضيت وقتاً كافياً مع أدوات فيديو الذكاء الاصطناعي الحالية، فسيظهر هذا كأنه غش. لكنه ليس كذلك. إنه أول دليل عام على أن التنقيح متعدد الخطوات — سير العمل الذي كان ينتظره صانعو الأفلام والمعلنون والمعلمون — أصبح حقيقياً وقابلاً للشحن تقنياً.
لماذا كان الاتساق متعدد الخطوات بمثابة جرح مفتوح لفيديو الذكاء الاصطناعي
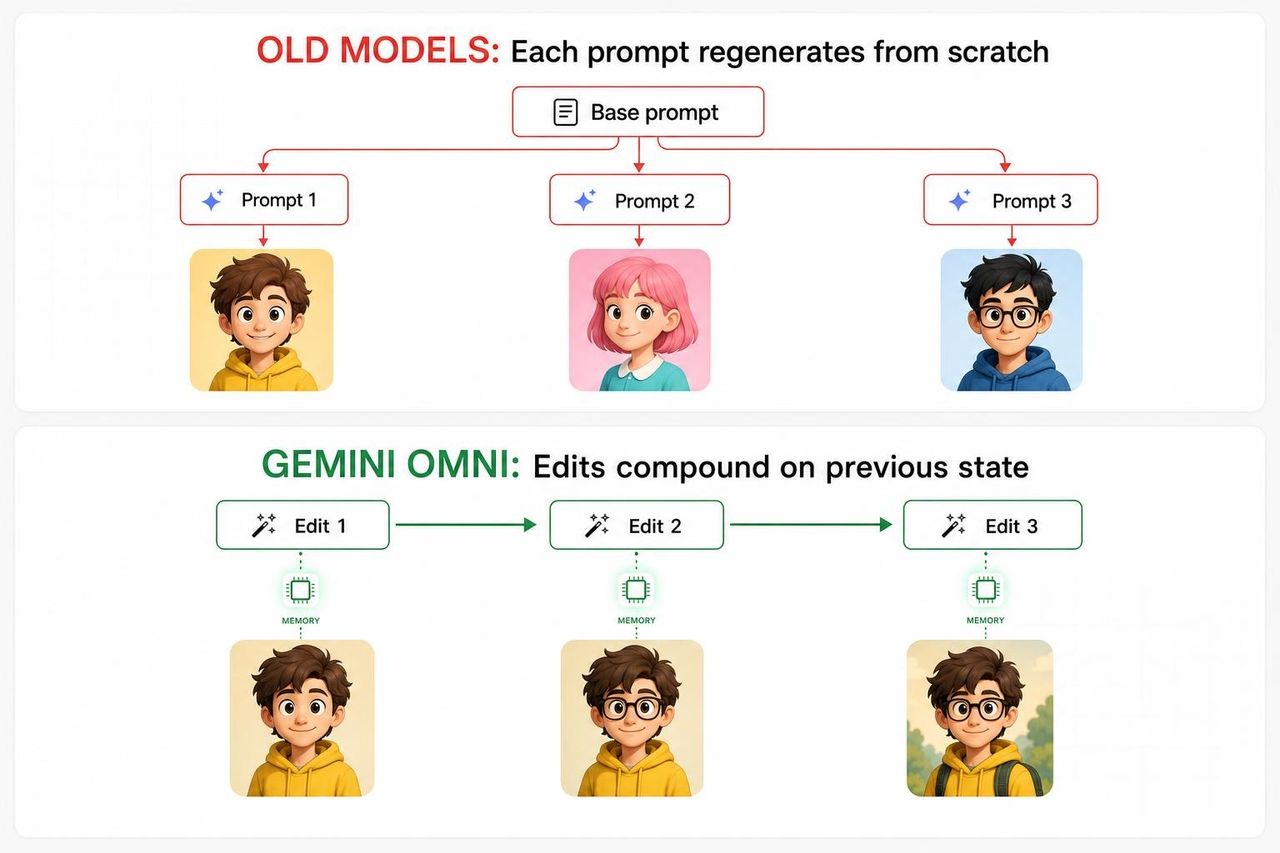
لفهم سبب أهمية عرض عازف الكمان، عليك أن تفهم أين تفشل كل نماذج فيديو الذكاء الاصطناعي الأخرى.
في خطوط إنتاج الفيديو التوليدي التقليدية، يقوم كل أمر جديد أساساً بإعادة إنشاء المشهد من الصفر — باستخدام الأمر الأصلي بالإضافة إلى الأمر الجديد كمدخلات مجمعة. لا يمتلك النموذج أي استمرارية داخلية حقيقية بين الخطوات. تنحرف الوجوه. تختفي الدعائم في الخلفية. تتغير الإضاءة. بحلول الخطوة الثالثة، تكون النتيجة قد ابتعدت كثيراً عن الرؤية الأصلية لدرجة أن المبدعين يستسلمون ويبدأون من جديد.
السبب الجذري هو معماري. تم تدريب معظم نماذج الفيديو كمولدات من خطوة واحدة (one-shot)، وليس كوكلاء متعددي الخطوات. تم تحسينها لإنتاج أفضل مخرجات واحدة من أمر توجيهي — وليس لتذكر ما أنتجته في المرة السابقة والتنقيح من هناك. كان الطلب منها "التحرير" يعادل فعلياً الطلب منها البدء من جديد مع سياق إضافي، وأدت رياضيات تلك العملية إلى انحراف مضاعف، وليس تنقيحاً تراكمياً.
نهج Omni مختلف. لقد تم بناؤه كـ محرر ذي حالة (stateful editor) — مما يعني أن كل خطوة تحدّث تمثيلاً مستمراً للمشهد بدلاً من إعادة إنشائه من الصفر.
ماذا يعني في الواقع "المشهد يتذكر"
بدأت الصحافة التقنية باللغة الإنجليزية تتوصل إلى نفس الإدراك بكلماتها الخاصة.
وصفت Decrypt هذا الاختراق بأوضح العبارات: "تقول Google إن Omni يمكنه الحفاظ على نفس الشخصيات والخلفيات والحركات متسقة حتى بعد إجراء المستخدمين تغييرات على الفيديو — وهو أمر تكافح معه العديد من نماذج فيديو الذكاء الاصطناعي."
استخلصت Android Central التفاصيل التقنية الرئيسية: "تقول الشركة أيضاً إن النموذج يسترجع الأوامر السابقة أثناء المراجعات متعددة الخطوات، مما قد يجعل التحرير التكراري يبدو أقل فوضوية بكثير."
صاغت TechRadar الأمر بأسلوب سينمائي: "تظل الشخصيات قابلة للتعرف عليها. تحافظ المشاهد على استمراريتها. تظل الحركة متماسكة بدلاً من إعادة تعيينها في كل مرة يتغير فيها الأمر التوجيهي."
وقامت Phandroid بضغط القدرة بأكملها في خمس كلمات: "المشهد يتذكر ما جاء قبله."
تلك هي الخلاصة. المشهد يتذكر. تلك الخاصية الوحيدة هي الفرق بين فيديو الذكاء الاصطناعي كـ "لعبة" وفيديو الذكاء الاصطناعي كـ "أداة".
كيف يقارن Omni أمام Sora وVeo وSeedance من حيث الاتساق
إليك كيفية مقارنة نماذج فيديو الذكاء الاصطناعي الرائدة تحديداً فيما يتعلق بالاتساق متعدد الخطوات اعتباراً من مايو 2026:
| النموذج | التحرير متعدد الخطوات | التنقيح التفاعلي | اتساق الشخصية (مراجعة Medium) | الحالة الحالية |
|---|---|---|---|---|
| Gemini Omni Flash | حالة مستمرة، متعدد الخطوات | دردشة أصلية | (3/5) | متاح منذ 19 مايو 2026 |
| Sora 2 (OpenAI) | إعادة توليد من خطوة واحدة | محدود | متوقف | تم إغلاق تطبيق Sora؛ API ينتهي في سبتمبر 2026 |
| Veo 3.1 (Google) | جزئي | نص + صورة فقط | أقل من Omni | متاح، يتم استبداله بـ Omni |
| Seedance 2.0 (ByteDance) | يعتمد على المرجع، غير تكراري | محدود | (4/5) | متاح؛ في المرتبة الأولى في Artificial Analysis Video Arena |
القراءة الصادقة: Omni هو النموذج الوحيد الذي يتمتع بتحرير فعلي ذو حالة (stateful) ومتعدد الخطوات. يسجل Seedance درجات أعلى في اتساق الشخصية الخام (وفقاً للمراجع في Medium) من خلال الاستفادة من ما يصل إلى 9 صور مرجعية لكل توليد — لكنه لا يستطيع نقل هذا الاتساق عبر جلسة التحرير. Sora يخرج من سوق المستهلكين. وVeo يتم دمجه.
من "إعادة التوليد" إلى "التنقيح" — ماذا يفتح هذا التحول في سير العمل

القيمة الحقيقية هنا ليست في العرض التوضيحي، بل في تحول سير العمل.
أوضحت Blockchain.news الآثار التجارية بأفضل شكل: "تتيح ميزة التحرير المجمّع إجراء تعديلات متزامنة عبر مقاطع فيديو متعددة لتسريع الإنتاج مع الحفاظ على معايير الجودة في المحتوى الذي يولده الذكاء الاصطناعي. يكتسب صانعو محتوى الأفلام والإعلانات والمحتوى التعليمي مزايا كبيرة من خلال خفض التكاليف وتحسين الموثوقية السردية."
تلك العبارة الأخيرة — الموثوقية السردية — هي الجزء الذي يجب أن يهم أي شخص يعمل في مجال المحتوى.
حتى الآن، كان بإمكان فيديو الذكاء الاصطناعي تقديم مقطع واحد جيد. لم يكن بإمكانه تقديم حملة — سلسلة من المقاطع بنفس البطل، ونفس أصول العلامة التجارية، ونفس اللغة البصرية عبر مخرجات متعددة. كان كل تعديل أشبه برمي العملة. الآن، تتراكم التعديلات.
لخصت TechTimes مجموعة القدرات الموضحة علناً بـ: "تحرير الإجراءات والأشياء في لقطات المستخدم، نقل الأسلوب بين المظهر الواقعي والرسوم المتحركة، التنقيح متعدد الخطوات، والتوليد بأسلوب الشرح."
وأكدت مراجعة DataCamp العملية أن السلوك متعدد الخطوات صمد في الممارسة: "يدعم Omni التحرير متعدد الخطوات، لذا يمكنك تنقيح التفاصيل والبيئات وزوايا الكاميرا خطوة بخطوة مع الحفاظ على اتساق المشهد."
يبدو التحول في سير العمل صغيراً على الورق. لكنه في الممارسة ضخم: توليد ← إعادة توليد ← إعادة توليد ← استسلام يتحول إلى توليد ← تنقيح ← تنقيح ← نشر.
بدأ المطورون يلاحظون ذلك. ففي منتدى المطورين الصيني V2EX، كتب أحد المهندسين الذين اختبروا Omni في يوم الإطلاق: "سرعة التوليد والاتساق تجاوزت توقعاتي."
عندما يصل مهندسو الذكاء الاصطناعي والمبدعون في الخطوط الأمامية إلى نفس الملاحظة في غضون ساعات من الإطلاق، فأنت تشهد تحولاً حقيقياً في القدرات — وليس مجرد تسويق.
التشكيك الصادق — Omni ليس مثالياً بعد
قبل أن يعلن أي شخص عن حل مشكلة الاتساق، إليكم الواقع ببرود.
قام مراجع في AI Analytics Diaries على Medium بتشغيل Omni مقابل Seedance 2.0 من ByteDance وأعطى اتساق الشخصية في Omni درجة 3 من 5.
العبارة التي تستحق التثبيت على شاشة كل مدير منتج فيديو ذكاء اصطناعي: "كلا النموذجين يكافحان مع اتساق الشخصية عبر تقطيعات متعددة — يظل هذا هو الجرح المفتوح لفيديو الذكاء الاصطناعي."
الترجمة: Omni أفضل مادياً من كل النماذج العامة الأخرى في التنقيح متعدد الخطوات داخل جلسة تحرير واحدة. لكنها ليست مشكلة محلولة عبر الفئة الأوسع بعد.
أين الفجوة المتبقية؟
- اتساق المشهد الواحد متعدد الخطوات يعمل بشكل جيد للغاية (عرض عازف الكمان).
- اتساق عبر التقطيعات (نفس الشخصية، مشاهد مختلفة، إعدادات إضاءة مختلفة، تأطير مختلف) لا يزال غير مثالي.
- الميزات الدقيقة — تفاصيل الوجه الدقيقة، حركة اليدين، أنسجة الملابس المحددة — لا تزال قادرة على الانحراف عبر العديد من التعديلات.
- يعني حد الـ 10 ثوانٍ للمقطع الحالي في Omni Flash أن الاتساق متعدد الخطوات لم يتم اختباره بضغط في العمل السردي طويل الشكل بعد.
بالنسبة لـ 80% من حالات الاستخدام — تنقيح المشهد الواحد، محتوى طوله مناسب لوسائل التواصل الاجتماعي، أصول التسويق — Omni جيد بما يكفي للنشر. بالنسبة للـ 20% المتبقية — العمل بجودة سينمائية حيث يجب أن تبقى استمرارية الشخصية حية عبر تسلسل من 30 لقطة — لا يزال هناك حاجة لمرور تنظيف تحريري.
ماذا يغير هذا في الواقع — قطاعاً تلو الآخر
إذا كان الاتساق متعدد الخطوات قد تم حله (أو قارب على الحل داخل جلسة واحدة)، فإليك ما سيتم فتحه:
لمعلني العلامات التجارية: استمرارية الحملة. يمكن لعلامة تجارية للأزياء أخيراً توليد عشرة تنويعات لنفس عارض البطل عبر عشرة إعدادات — دون إعادة تصوير، دون البحث عن مواهب جديدة، دون دفع تكاليف لعشر لمسات يدوية. تتغير رياضيات إنتاج المحتوى الموجه للتواصل الاجتماعي بشكل كبير.
للمعلمين وصناع المحتوى التعليمي: استمرارية السلسلة. يمكن لمقدم واحد تم توليده بالذكاء الاصطناعي استضافة دورة كاملة — من الحلقة الأولى إلى الحلقة الثانية عشرة — دون أن يلاحظ الجمهور أنه اصطناعي. مشكلة "الوجه المتسق عبر المحتوى" قتلت تعليم الذكاء الاصطناعي لمدة عامين. لقد تم حلها للتو.
لصناع الأفلام: التصور المسبق على نطاق واسع. نفس الممثل عبر مقترحات مشاهد متعددة، إعدادات إضاءة متعددة، زوايا كاميرا متعددة — كلها تم توليدها في جلسة واحدة، وكلها قابلة للتنقيح بشكل تكراري. تتقلص الفجوة بين "لدي فكرة" و"يمكنني عرضها على المخرج" من أيام إلى دقائق.
لفرق التجارة الإلكترونية: لقطات البطل للمنتج التي تتطابق عبر تنويعات القوائم. نفس العارض، ستة أزياء، لقطات نمط حياة، لقطات استوديو، لقطات في البيئة — كلها متسقة، كلها قابلة للشحن، وكلها تم توليدها من نفس الجلسة متعددة الخطوات.
لمطوري الألعاب: شخصيات غير لاعبة (NPCs) تبدو كأنها نفس الشخصية عبر المشاهد السينمائية. كانت نقطة ضعف مشهديات الذكاء الاصطناعي داخل اللعبة هي أن البطل يتغير بشكل طفيف بين المشاهد. التحرير ذو الحالة (Stateful) في Omni يجعل قفل الشخصية مجدياً تجارياً.
توتر المصدر — التزييف المتسق يصبح اكتشافه أصعب
هناك أثر أكثر قتامة لهذا الاختراق يستحق التسمية المباشرة.
اتساق أفضل متعدد الخطوات يعني تزييفاً أصعب في الاكتشاف. "العلامات" الكلاسيكية التي تدل على أن شيئاً ما تم توليده بالذكاء الاصطناعي — وجه يتغير عبر التقطيعات، أيدي يتغير شكلها، شعر ينحرف في اللون — هي بالضبط ما يعالجه الاتساق. مع تحسن Omni وخلفائه في الاستمرارية الداخلية، تغلق الفجوة بين "اصطناعي بوضوح" و"لا يمكن تمييزه عن الحقيقي" بسرعة.
وهذا هو السبب بالضبط في أن كل مقطع يتم توليده بواسطة Omni يتم شحنه بعلامة SynthID المائية غير المرئية من Google وبيانات اعتماد المحتوى C2PA المدمجة في وقت التوليد. قابلة للتحقق داخل تطبيق Gemini وChrome وSearch. ليست اختيارية. وليست ميزة يمكنك إيقاف تشغيلها.
وهذا هو السبب أيضاً في أن Google حظرت عمداً تحرير الكلام والصوت في الفيديوهات الحالية: "لا نزال نعمل على اختبار هذا وفهم كيفية تقديم هذه القدرة للمستخدمين بمسؤولية." الترجمة: خطر التزييف العميق لوجه متسق + صوت معدل مرتفع جداً بحيث لا يمكن شحنه دون وجود ضمانات.
بالنسبة للعلامات التجارية والمبدعين، يتغير الحساب. مع تحول اكتشاف المحتوى "المزيف" بالعين البشرية إلى أمر غير موثوق، يصبح المصدر المشفر هو المعيار الجديد لأصالة المحتوى. كل مكسب في الاتساق يأتي مقترناً بالتزام بالمصدر.
الاختناق الجديد ليس الجودة. بل "تشتت النماذج".
إليك ما يعنيه هذا استراتيجياً لأي شخص يبني منتجات فوق فيديو الذكاء الاصطناعي.
الفجوة في القدرات بين النماذج الرائدة تضيق بسرعة — وتتفتت بسرعة في نفس الوقت. اعتباراً من منتصف عام 2026:
- Gemini Omni يقود في الاتساق متعدد الخطوات والتحرير التفاعلي
- Seedance 2.0 يقود في الحركة السينمائية والرسوم المتحركة المصممة، مع اتساق أقوى للشخصية القائم على المرجع
- متخصصون آخرون يقودون في التوليد طويل الشكل، التحكم الدقيق في الشخصية، مزامنة الصوت، أو المعالجة المجمعة منخفضة التكلفة
النموذج الأفضل في الاتساق هذا الربع ربما ليس هو النموذج الأفضل في الحركة السينمائية هذا الربع. النموذج الذي يمتلك أقوى فيزياء اليوم ليس هو الذي يمتلك أفضل مزامنة صوتية بعد ستة أشهر من الآن. وكل واحد منهم يتم شحنه بـ SDK الخاص به، ومسار المصادقة، وطبقة التسعير، ومراوغات تحديد المعدل، وشروط العقد. يمكن لفريقك بسهولة حرق دورة هندسية (sprint) لكل تكامل — ودورة أخرى لكل إيقاف.
هذه هي بالضبط مشكلة التجزئة التي تم بناء Atlas Cloud لحلها. نحن نمنح المطورين نقطة نهاية موحدة للوصول إلى أكثر من 300 نموذج — كل نموذج أساسي رئيسي، وإصدارات المصدر المفتوح الرائدة، والمتخصصين سريعي الحركة عبر الصورة والفيديو والصوت والاستدلال. الوصول إلى Gemini Omni قادم إلى Atlas Cloud في الأسابيع القليلة القادمة، لذا ففي اللحظة التي تكون فيها مستعداً لاستبدال مجموعتك التقنية لاختباره، يكون التكامل قد تم بالفعل من أجلك.
ما يعنيه ذلك عملياً لفريقك:
- تبديل النماذج بسطر واحد من التعليمات البرمجية — لا حاجة لإعادة كتابة تكاملات SDK في كل مرة يظهر فيها مستوى تقني جديد (SOTA).
- إجراء تقييمات جنباً إلى جنب على أوامر متطابقة — اكتشف أي نموذج يفوز فعلياً لحالة استخدامك المحددة قبل الالتزام بالميزانية.
- شحن أقوى نموذج لكل قدرة — رائد الاتساق متعدد الخطوات اليوم، رائد الحركة السينمائية غداً، رائد كفاءة التكلفة الربع القادم.
- لوحة تحكم واحدة للفوترة، والمراقبة، وحدود المعدل — بدلاً من اثني عشر حساباً منفصلاً للإدارة.
بالنسبة للمطورين الذين يشحنون منتجات فيديو الذكاء الاصطناعي في عام 2026، فإن القرار المعماري الذكي ليس "راهن على Omni." بل هو "ابنِ على طبقة تجريد تسمح لك بالتبديل إلى أي شيء يفوز بعد ذلك." عندما يهبط Gemini Omni على Atlas Cloud، ستتمكن من اختباره مقابل Seedance، ومقابل النموذج الاختراقي التالي، ومقابل أي شيء يأتي بعد ذلك — دون تغيير سطر واحد من تعليمات التكامل البرمجية.
في سوق حيث يقود كل من الاتساق، والفيزياء، والحركة السينمائية، ودقة الصوت نموذج مختلف، فإن الارتباط بأي منها هو أسوأ دين تقني ممكن. Atlas Cloud هي طبقة التجريد التي تحول هذا التجزئة من ضريبة إلى ميزة.
واجهة برمجة تطبيقات واحدة موحدة لتوليد فيديو الإنتاج
بينما تطلق Google Gemini Omni Flash داخل تطبيق Gemini وGoogle Flow للمستخدمين النهائيين، يحتاج المطورون وفرق الإنتاج الذين يرغبون في تضمين نفس محرك الفيديو متعدد الوسائط في سير عملهم الخاص إلى طبقة API مستقرة ويمكن التنبؤ بها.
يقدم Atlas Cloud خدمة Gemini Omni Flash عبر API موحد ومتوافق مع OpenAI، إلى جانب أكثر من 300 نموذج آخر للصورة والفيديو والنماذج اللغوية الكبيرة — بحيث يمكنك دمج نموذج Google متعدد الوسائط الأصلي دون التلاعب بحسابات البائعين المنفصلة، أو بوابات الفوترة، أو SDKs.
كلا نوعي Gemini Omni Flash متاحان على Atlas Cloud:
| النوع | الأفضل لـ | المدخلات | الدقة | المدة | السعر المبدئي |
|---|---|---|---|---|---|
| Gemini Omni Flash لتحويل النص إلى فيديو (مطور) | التوليد السينمائي القائم على الأوامر | نص (حتى 20,000 حرف) | 720p / 1080p / 4K | 4, 6, 8, 10 ثوانٍ | $0.2 + $0.1/ثانية |
| Gemini Omni Flash لتحويل الصورة إلى فيديو (مطور) | فيديو متسق مع المراجع الحقيقية | نص + حتى 7 صور مرجعية | 720p / 1080p / 4K | 4, 6, 8, 10 ثوانٍ | $0.2 + $0.1/ثانية |
بداية سريعة — توليد فيديو Gemini Omni Flash في 5 أسطر:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
تعيد واجهة برمجة التطبيقات معرف تنبؤ (prediction ID) على الفور — قم بعمل استعلام على /api/v1/model/prediction/{id} للحصول على عنوان URL الخاص بملف MP4 المولد. المخطط الكامل، ونماذج الكود بـ 7 لغات، وPlayground بدون كود متاحة على صفحات النماذج المرتبطة أعلاه.
رؤى جوهرية
سبب أهمية الاتساق متعدد الخطوات ليس العرض التوضيحي. بل هو الإنجاز الذي يفتحه.
لمدة خمس سنوات، اصطدمت كل محادثة حول "متى سيتحول فيديو الذكاء الاصطناعي إلى المجال التجاري؟" بنفس الجدار: اللحظة التي تستطيع فيها النماذج الحفاظ على اتساق الشخصية عبر التعديلات. ذلك الجدار قد تحرك للتو.
عرض عازف الكمان ليس حيلة. إنه المرة الأولى التي يضع فيها مختبر كبير سير عمل تحرير حقيقي ومتعدد الخطوات على المسرح. في المرة القادمة التي يطلب فيها فريق تسويق من أداة فيديو الذكاء الاصطناعي إنتاج ستة مقاطع لنفس بطل المنتج عبر ستة سيناريوهات، يجب أن يتوقعوا ستة مخرجات قابلة للاستخدام — وليس ستة وجوه غير مترابطة.






