GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
استكشف النماذج الرائدة
يوفر لك Atlas Cloud أحدث النماذج الإبداعية الرائدة في الصناعة.
ما الذي يميز GLM LLM Models
توفر لك Atlas Cloud أحدث النماذج الإبداعية الرائدة في الصناعة.

Advanced Reasoning
Tuned for strong logical reasoning, structured analysis, and multi-step problem solving.

Cost-Efficiency
Optimized architectures keep latency and costs under control.

Safety & Governance
Built-in content filters, auditing tools, and policy controls help teams deploy.

Enterprise Reliability
Production-ready SLAs, monitoring, and governance features help teams confidently ship applications.

Chinese–English Excellence
Native-strength Chinese and fluent English support enable high-quality bilingual chat, search, and generation.

Developer-Friendly Ecosystem
Clean APIs, SDKs, and tooling make it easy to integrate, fine-tune, and operate Z.ai across products and platforms.
السرعة القصوى
أقل تكلفة
| Model | Description |
|---|---|
| GLM-5 | GLM-5 is Z.ai's flagship LLM featuring a massive 202.75K context window optimized for complex systems and long-horizon agentic tasks. Outperforming elite closed-source models in benchmarks like Humanity’s Last Exam and BrowseComp, it provides robust programming and stable multi-step reasoning at highly competitive baseline pricing. |
| GLM-4.7 | GLM-4.7 is a high-performance LLM with a 202.75K context window specifically engineered for real-world intelligent agents, advanced reasoning, and professional coding. Fast, smart, and reliable, it serves as the ideal engine for building complex websites and automating sophisticated professional workflows with precision. |
| GLM-4.6 | GLM-4.6 is a powerful MoE LLM with a 202.75K context window designed for rapid data analysis and instant, high-fidelity answers. This dependable model excels at high-efficiency tasks like creating professional slides and web content, offering a smart balance of speed and enterprise-grade performance. |
ميزات جديدة لـ GLM LLM Models + عرض
يوفر الجمع بين النماذج المتقدمة ومنصة Atlas Cloud المسرّعة بوحدات GPU سرعة وقابلية توسع وتحكمًا إبداعيًا لا مثيل لهما في إنشاء الصور والفيديو.
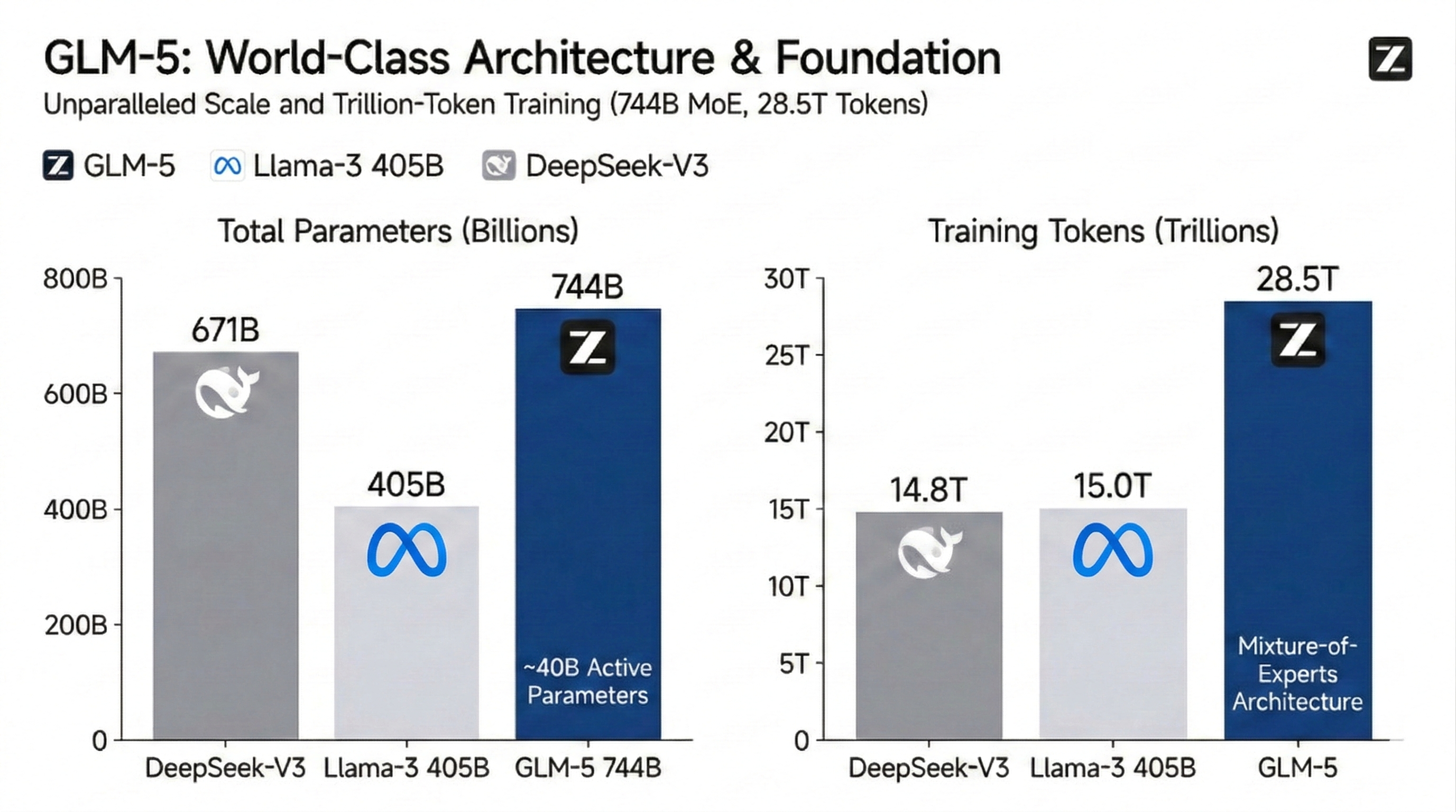
بنية MoE ضخمة بحجم 744B وقاعدة معرفة شاملة
يستفيد نموذج GLM-5 من بنية "مزيج الخبراء" (MoE) التي تضم 744 مليار معلمة، وتم تدريبها على 28.5 تريليون رمز مميز مذهل لإعادة تعريف حدود الأداء في المصادر المفتوحة. من خلال تحسين 40 مليار معلمة نشطة، فإنه يسهل قفزة هائلة في كثافة المعرفة العالمية ودقة الاسترجاع. إنه الأساس الأول للمهام الإدراكية واسعة النطاق وتوليف البيانات المعقدة.
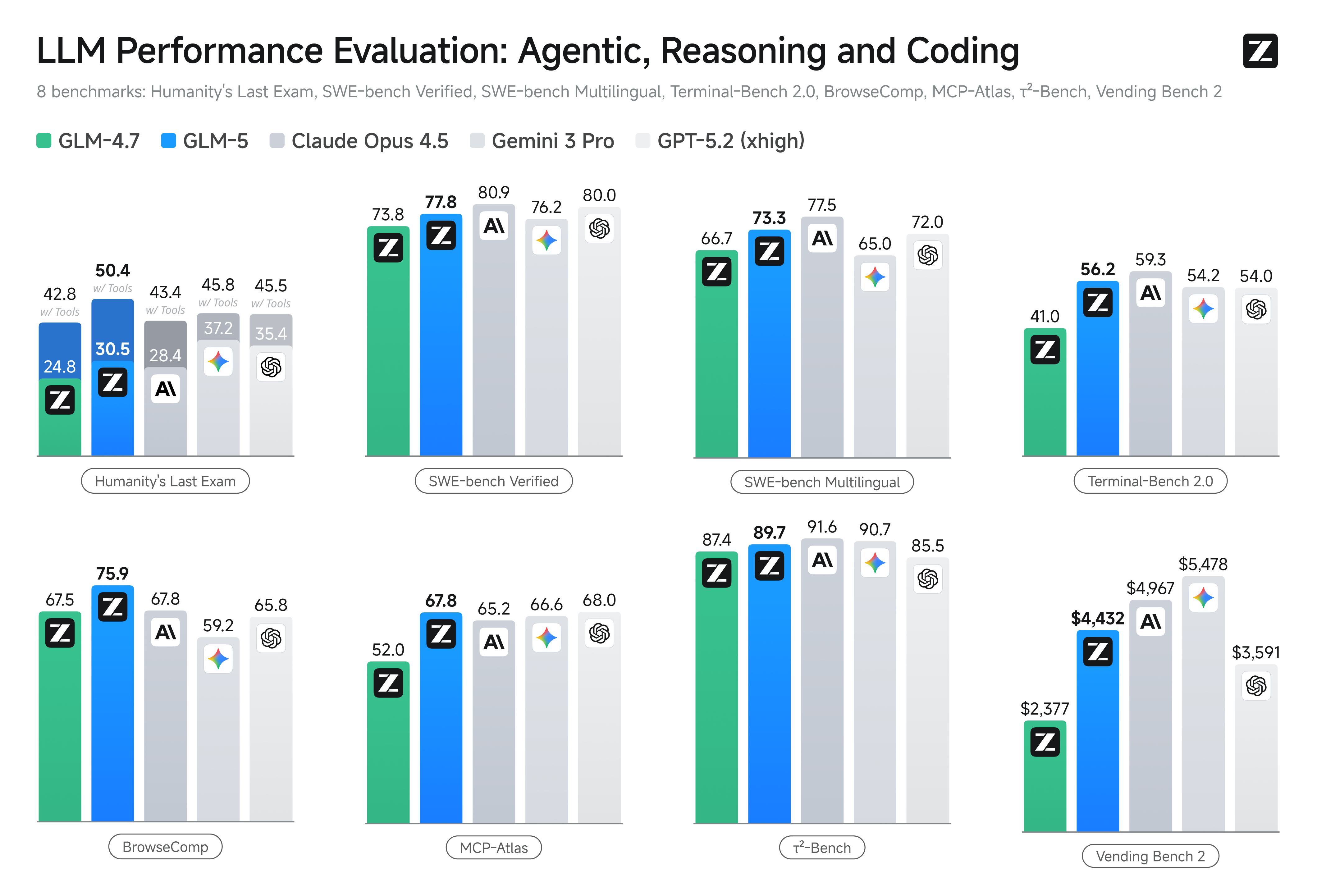
هندسة النظم الوكيلة الثورية باستخدام GLM-5
يقدم GLM-5 قدرات وكلاء متقدمة مصممة لتنفيذ المهام النظامية طويلة الأمد عبر بيئات الاستدلال متعددة الخطوات. من خلال دمج منطق التخطيط المتطور في بنيته الأساسية، يحافظ النموذج على استقرار استثنائي أثناء تطوير البرمجيات الآلي والصياغة القانونية المهنية. إنه بمثابة المحرك النهائي لسير العمل المستقل الذي يتطلب دقة متناهية واتساقًا طويل الأمد.
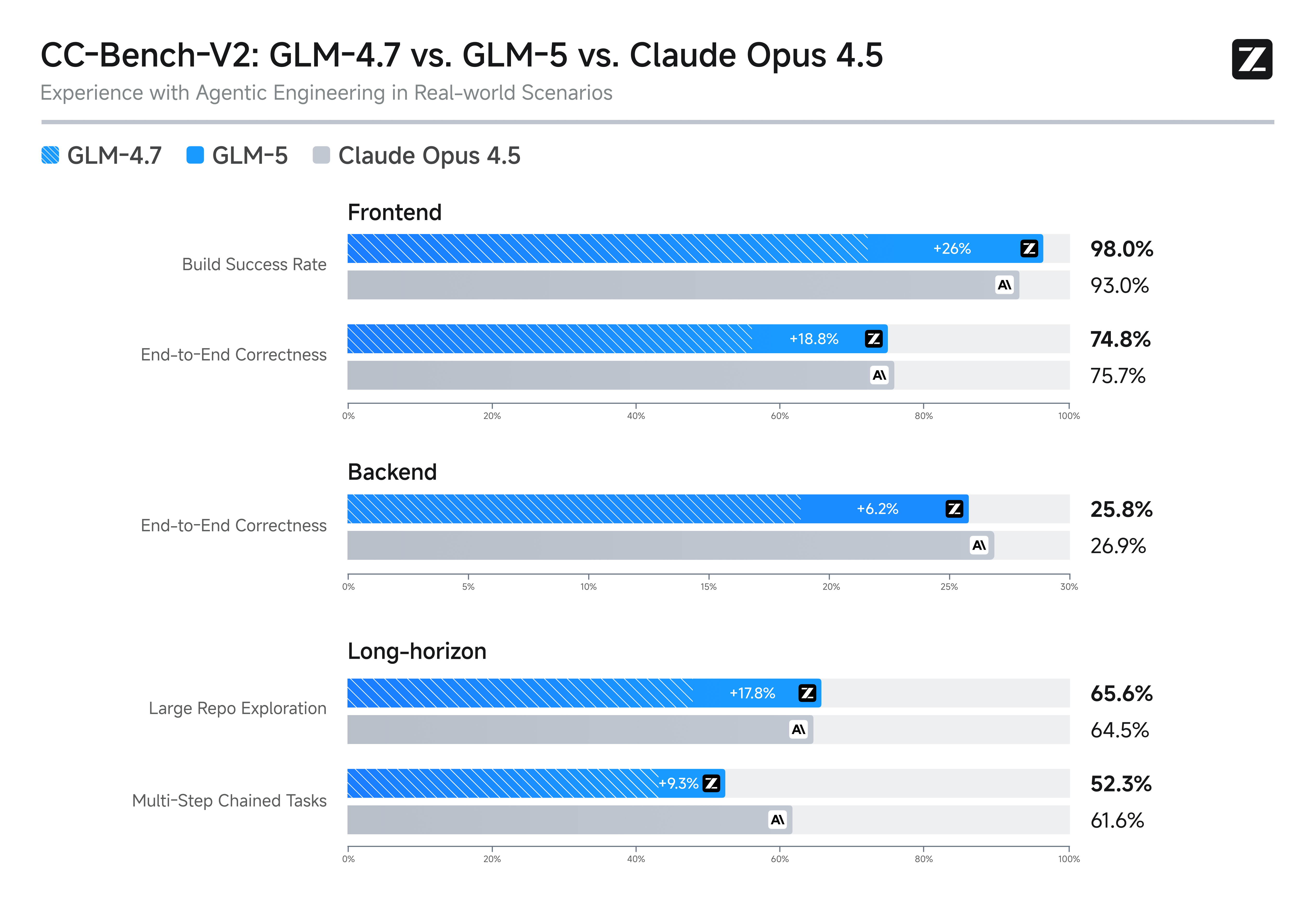
Slime التعلم المعزز غير المتزامن والتطور المنطقي
يستخدم GLM-5 البنية التحتية المبتكرة للتعلم التعزيزي غير المتزامن "Slime" لإحداث ثورة في كفاءة ما بعد التدريب والصرامة المنطقية. يعزز هذا الإنجاز بشكل كبير جودة إنشاء التعليمات البرمجية والاستدلال الخوارزمي، متجاوزًا المعايير السابقة ومؤمنًا مرتبته كنموذج مفتوح المصدر من الدرجة الأولى. إنه الحل الأمثل للتطوير الشامل (full-stack) وحل المشكلات الهيكلية عالية المستوى.
ما يمكنك فعله مع GLM LLM Models
اكتشف حالات الاستخدام العملية وسير العمل التي يمكنك بناؤها مع عائلة النماذج هذه — من إنشاء المحتوى والأتمتة إلى التطبيقات على مستوى الإنتاج.
ذكاء المستودعات الشامل مع GLM-5
تُمكّن واجهة برمجة تطبيقات GLM-5 المطورين من استيعاب قواعد التعليمات البرمجية بالكامل لإجراء تحليل منطقي عميق وإعادة هيكلة بنيوية. من خلال رسم خرائط التبعية وتتبع تدفقات البيانات غير المتزامنة المعقدة، تحدد الواجهة شروط السباق (race conditions) في الحالات النادرة والديون التقنية الخفية. إنها مثالية لتسريع تأهيل الفرق، ومراجعات PR الآلية، والحفاظ على معماريات الخدمات المصغرة القابلة للتوسع وعالية الأداء.
نماذج أولية Full-Stack فورية باستخدام GLM-5
من أجل التطوير القائم على الإلهام (vibe-driven)، يقوم GLM-5 بتحويل النماذج المرئية المجردة والملاحظات المتفرقة إلى مكونات React أو Next.js قابلة للنشر. يتولى النموذج المهام الشاقة المتمثلة في إنشاء التعليمات البرمجية النمطية (boilerplate)، وتنسيق Tailwind CSS، وإدارة الحالة، مع ضمان الاتساق عبر الصفحات. مثالي للمؤسسين الفرديين، ومجربي تجربة المستخدم (UX)، وإطلاق نماذج أولية قابلة للتطبيق (MVPs) وظيفية بسرعة البرق.
تنسيق سير العمل المستقل باستخدام GLM-5
يتميز GLM-5 في إدارة مهام البحث طويلة المدى التي تتطلب تفكيرًا متعدد الخطوات وتكاملًا للأدوات في الوقت الفعلي. يمكنه تجميع بيانات السوق من مصادر متعددة بشكل مستقل، وصياغة ملخصات قانونية ممتثلة للمعايير، وأتمتة الجدولة المعقدة عبر الأنظمة الأساسية دون فقدان السياق. تناسب حالة الاستخدام هذه مديري المشاريع والمهنيين القانونيين وأي شخص يحتاج إلى وكيل رقمي عالي الموثوقية للعمليات النظامية.
مقارنة النماذج
شاهد كيف تتقارن نماذج مختلف المزودين — قارن الأداء والأسعار ونقاط القوة الفريدة لاتخاذ قرار مدروس.
| Model | Context | Max Output | Input | Positioning |
|---|---|---|---|---|
| GLM-5 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.7 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.6 | 202.75K | 202.75K | Text | Efficient MoE Model |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flagship General |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA Agentic Coding |
How to Use GLM LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
لماذا تستخدم GLM LLM Models على Atlas Cloud
دمج نماذج GLM LLM Models المتقدمة مع منصة Atlas Cloud المسرّعة بـ GPU يوفر أداءً لا مثيل له وقابلية للتوسع وتجربة مطور استثنائية.
الأداء والمرونة
زمن انتقال منخفض:
استدلال محسّن لـ GPU للاستجابة في الوقت الفعلي.
API موحد:
قم بتشغيل GLM LLM Models و GPT و Gemini و DeepSeek من خلال تكامل واحد.
تسعير شفاف:
فواتير يمكن التنبؤ بها لكل رمز مع خيارات بدون خادم.
المؤسسات والتوسع
تجربة المطور:
SDKs والتحليلات وأدوات الضبط الدقيق والقوالب.
الموثوقية:
وقت تشغيل 99.99%، RBAC، وتسجيل جاهز للامتثال.
الأمان والامتثال:
SOC 2 Type II، توافق HIPAA، سيادة البيانات في الولايات المتحدة.
الأسئلة الشائعة حول GLM LLM Models
بفضل 28.5 تريليون رمز (tokens) من بيانات التدريب ونتائج اختبارات الأداء المتميزة، يُعتبر GLM-5 على نطاق واسع "سقف المصادر المفتوحة". فهو ينافس أو يتجاوز النماذج التجارية العالمية من الدرجة الأولى من حيث القدرة والمنطق، مما يوفر أساسًا قويًا وعالي الأداء للنظام البيئي العالمي للمطورين.
HLE هو معيار عالي الصعوبة صُمم لاختبار ما إذا كان الذكاء الاصطناعي يمتلك معرفة بشرية واستدلالاً بمستوى الخبراء. إن تحقيق GLM-5 لأعلى درجة يدل على أن إتقانه للعلوم الرائدة والمنطق المعقد قد وصل إلى مستوى النماذج الرائدة مغلقة المصدر أو تجاوزه.
يُعد BrowseComp قائمة الصدارة المعتمدة لقدرات "الوكلاء" (Agentic)، مع التركيز على تخطيط المهام المعقدة وتنفيذها في بيئات الويب الواقعية. تمثل أعلى درجة قدرة GLM-5 على التنقل بشكل مستقل في المتصفحات ودمج المعلومات عبر الصفحات، مما يجعله محرك Web Agent الرائد.
توفر هذه البنية "قاعدة معرفية" هائلة تبلغ 744 مليار معلمة (parameter) بينما تقوم بتنشيط ~40 مليار فقط أثناء الاستدلال (inference). بالنسبة للمطورين، يترجم هذا إلى كثافة معرفية وعمق استنتاجي من الطراز العالمي - يتفوق على النماذج الكثيفة مثل Llama-3 405B - مع زمن انتقال وتكلفة أقل.
تمثل المعلمات الإجمالية "السعة المعرفية" للنموذج، حيث تتيح 744B تخزينًا هائلاً للحقائق العالمية والمنطق الخبير. تمثل المعلمات النشطة "القوة الحسابية" المستخدمة لكل استنتاج. بفضل بنية MoE، يقدم GLM-5 ذكاءً بمستوى 744B باستخدام 40B فقط من الحساب، مما يوازن بين قاعدة معرفية ضخمة وأداء عالي السرعة وفعال من حيث التكلفة.
يحدد حجم بيانات التدريب المسبق "اتساع رؤية" النموذج. تُعد 28.5 تريليون رمز (token) واحدة من أكبر مجموعات البيانات عالميًا (ضعف حجم Llama-3 تقريبًا)، وتشمل لغات نادرة وأوراقًا أكاديمية متخصصة وكميات هائلة من الأكواد البرمجية عالية الجودة. وهذا يضمن امتلاك GLM-5 دقة وقدرة تعميم فائقة عند التعامل مع استفسارات الذيل الطويل (long-tail queries) المعقدة، والفروق الدقيقة بين الثقافات، وبرمجة الأنظمة منخفضة المستوى.
استكشف المزيد من العائلات
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


