DeepSeek LLM Models
DeepSeek, developed by the deepseek-ai team, is a cutting-edge series of open-source generative AI models engineered to democratize access to high-performance computing through a cost-effective and efficiency-first strategy. Its flagship reasoning model, DeepSeek-R1, made waves by rivaling top-tier proprietary models in mathematics, programming, and complex logical deduction, while the DeepSeek-V3.2, is designed for seamless daily interaction and autonomous Agent workflows. By significantly lowering the barrier to entry for advanced AI, DeepSeek has become a cornerstone for the "vibe coding" movement and a transformative tool in specialized fields like academic research and high-level technical problem-solving.
استكشف النماذج الرائدة
يوفر لك Atlas Cloud أحدث النماذج الإبداعية الرائدة في الصناعة.
ما الذي يميز DeepSeek LLM Models
توفر لك Atlas Cloud أحدث النماذج الإبداعية الرائدة في الصناعة.

القوة المفتوحة
نماذج من الطراز الأول مفتوحة المصدر بالكامل، تضمن الشفافية والتحكم.

الكفاءة المعمارية
يوظف تقنية "خليط الخبراء" (MoE) المتقدمة لتقديم أداء ريادي بجزء بسيط من التكلفة.

تعدد استخدامات مصمم خصيصاً
من V3.1 متعدد الاستخدامات إلى قدرات الاستدلال المتخصصة في R1، تقدم DeepSeek نماذج لكل مهمة.

حرية تضع المطور أولاً
مرخصة بشكل متساهل للاستخدام التجاري غير المقيد، مما يعزز الابتكار بلا حواجز.

أداء مُثبت
يحقق باستمرار أحدث النتائج في معايير الصناعة للبرمجة والاستدلال.

البديل العملي
يوفر قوة النماذج الاحتكارية الرائدة مع التكلفة الميسورة ومرونة المصادر المفتوحة.
Peak speed
Lowest cost
| النمط | الوصف |
|---|---|
| DeepSeek V3.2 | يُعد DeepSeek V3.2 نموذج LLM رائدًا للأغراض العامة، حيث يدمج آليات الانتباه المتناثر (sparse attention) مع قدرات معالجة سياق قوية تبلغ 163.8K؛ وبفضل أسعاره الأساسية التنافسية للغاية، فإنه يعمل كحجر زاوية لسير العمل اليومي، بما في ذلك الاستدلال العام المعقد وبناء Agents لجدولة المهام متعددة الخطوات. |
| DeepSeek V3.2 Speciale | يتم وضع DeepSeek V3.2 Speciale كنموذج لغوي كبير (LLM) مخصص عالي الأداء، يتميز بنافذة سياق ضخمة تبلغ 163.8K وهيكل تسعير متميز متعدد المستويات (0.4 دولار للإدخال / 1.2 دولار للإخراج)، وهو مصمم خصيصًا لعقد الأعمال الأساسية الحساسة لزمن الانتقال التي تتطلب جودة مخرجات فائقة، مثل خدمة العملاء الذكية للعملاء ذوي الملاءة المالية العالية أو التحليل الكمي على مستوى المللي ثانية. |
| DeepSeek V3.2 Exp | يُعد DeepSeek V3.2 Exp إصداراً تجريبياً متطوراً يعتمد على هندسة V3.2، ويدمج أحدث الميزات الخوارزمية مع الحفاظ على سياق 163.8K وتكاليف مماثلة، مما يجعله مثالياً لفرق البحث والتطوير (R&D) التي تجري أبحاثاً تقنية مسبقة واختبارات كناري (canary testing) للتحقق بشكل استباقي من القوة التنافسية لقدرات الذكاء الاصطناعي من الجيل التالي للمنتجات المستقبلية. |
| DeepSeek-V3.1 | يُعد DeepSeek-V3.1 أحدث جيل من نماذج النظام البيئي مفتوحة المصدر عالية الأداء، حيث يحقق توازنًا جديدًا بين الأداء والتكلفة ضمن سياق 131.1K؛ وباعتباره الخيار الأفضل لمشاريع التنفيذ التجاري، فهو يعمل بمثابة العمود الفقري للسيناريوهات التي تتطلب توليدًا عالي الجودة وتكاليف يمكن التحكم فيها. |
| DeepSeek V3.1 Terminus | يعمل DeepSeek V3.1 Terminus كشكل نهائي مستقر طويل الأمد لسلسلة V3.1، حيث يحافظ DeepSeek V3.1 Terminus على معايير وتسعير مطابقين للإصدار القياسي، بهدف توفير نمط إخراج ومنطق مستقرين بشكل دائم لخدمات نقاط النهاية (endpoint) في بيئة الإنتاج السلسة والموجهة للمستهلك. |
| DeepSeek-V3-0324 | يُعد DeepSeek-V3-0324 إصدار لقطة تاريخية محددة يتميز بسياق 131.1K وأقل تكلفة متاحة لإدخال النص، ويُطبق بشكل أساسي في صيانة الأنظمة القديمة التي تتطلب اتساقًا سلوكيًا مطلقًا، أو مهام المعالجة المجمعة ذات تدفق الإدخال الهائل ولكن متطلبات منطق الإخراج المعتدلة. |
| DeepSeek-R1-0528 | يتم تصنيف DeepSeek-R1-0528 كنموذج استدلال عميق من الطراز الأول، حيث يستخدم سياقًا بحجم 131.1K ويتطلب أعلى تكلفة حوسبة (0.55 دولار/2.15 دولار)، ويمثل قمة القدرات الجدلية المنطقية، ويستخدم حصريًا لمهام "العصف الذهني" الحرجة مثل النمذجة الرياضية المعقدة وتوليد هندسة الأكواد المتقدمة. |
| DeepSeek OCR | يُعد DeepSeek OCR نموذجًا لغويًا كبيرًا (LLM) متعدد الوسائط ومرئيًا ومخصصًا يدعم إدخال المسار المزدوج للصورة والنص بسياق قصير يبلغ 8.2K وتكاليف استخدام منخفضة للغاية، وهو مكيف تمامًا لسيناريوهات خطوط أنابيب إدخال البيانات المؤتمتة مثل رقمنة المستندات الممسوحة ضوئيًا الهائلة والاستخراج الهيكلي للإيصالات المالية. |
ميزات جديدة لـ DeepSeek LLM Models + عرض
يوفر الجمع بين النماذج المتقدمة ومنصة Atlas Cloud المسرّعة بوحدات GPU سرعة وقابلية توسع وتحكمًا إبداعيًا لا مثيل لهما في إنشاء الصور والفيديو.
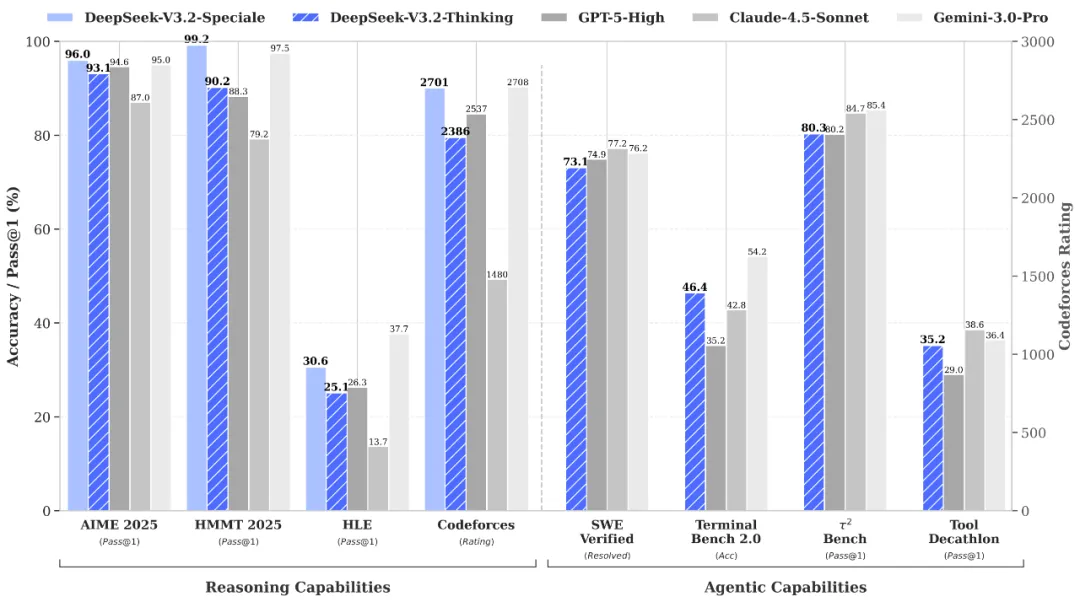
استنتاج وتحقق عالمي المستوى عبر DeepSeek-V3.2-Speciale API
DeepSeek-V3.2-Speciale is the "long-thought" enhanced variant of the V3.2 architecture, integrating advanced theorem-proving capabilities from DeepSeek-Math-V2. Engineered for extreme precision, this model excels in rigorous mathematical proofing, complex logical verification, and superior instruction following, rivaling the performance of Gemini-3.0-Pro in mainstream reasoning benchmarks. It is the premier choice for academic research, automated formal verification, and high-stakes technical problem-solving where logical integrity is non-negotiable.
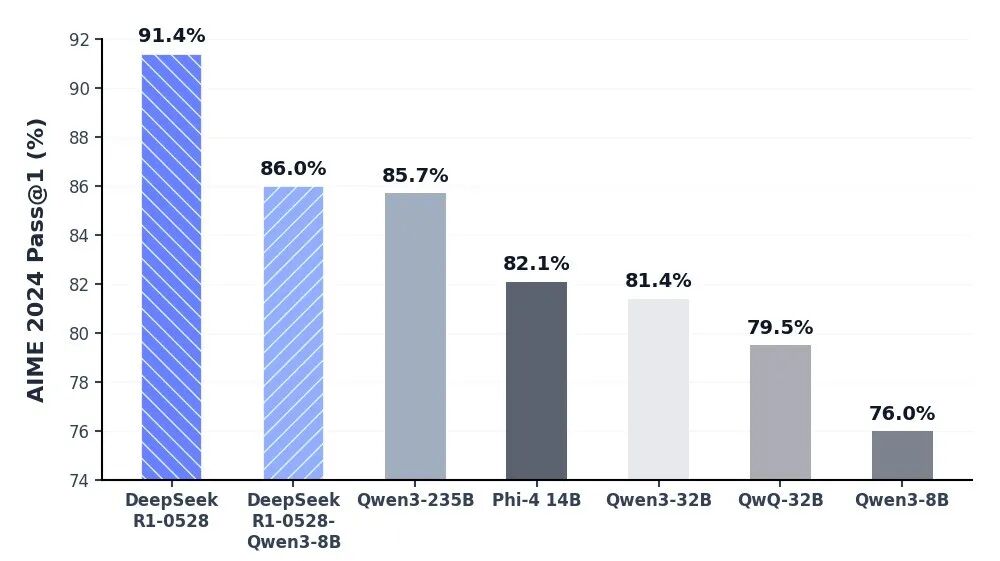
عمق إدراكي لا مثيل له عبر DeepSeek-R1 API
يقف نموذج DeepSeek-R1 في طليعة الذكاء الاصطناعي الاستنتاجي، حيث يقدم أداءً رائدًا في الصناعة في الرياضيات والبرمجة والمنطق العام. من خلال تحقيق التكافؤ مع نماذج النخبة العالمية مثل o3 من OpenAI و Gemini-2.5-Pro، أعاد R1 تعريف قدرات الذكاء مفتوح المصدر. تم تحسينه خصيصًا لمهام التفكير العميق، بما في ذلك تطوير الخوارزميات المعقدة، وتوليف البيانات المتطور، وسير العمل المعرفي المتقدم الذي يتطلب استنتاجًا استنباطيًا متعدد المراحل.
تفاعل يومي سلس مع سير عمل الوكلاء المستقلين باستخدام DeepSeek V3.2 API
يحقق DeepSeek-V3.2 توازناً مثالياً بين عمق الاستدلال وسرعة التنفيذ، وقد صُمم لدعم التفاعلات اليومية السلسة ومنظومات الوكلاء المستقلة (Autonomous Agents). مع انخفاض ملحوظ في زمن الاستجابة وتحكم مُحسّن في المخرجات، يعمل النموذج كمحرك قوي لتنسيق المهام متعددة الخطوات ومساعدي الذكاء الاصطناعي للأغراض العامة. سواء عند نشر الأتمتة على مستوى المؤسسات أو الأدوات التفاعلية عالية التردد، يضمن V3.2 تجربة مستخدم سلسة وفعالة ومنخفضة التكلفة.
اكتشاف علمي دقيق وتحقق رسمي باستخدام DeepSeek-V3.2-Speciale API
The DeepSeek-V3.2-Speciale API is engineered for tasks that demand absolute logical precision and multi-step reasoning. By integrating advanced theorem-proving capabilities, it enables researchers and engineers to execute complex mathematical inductions, verify formal logic, and solve high-tier competitive programming challenges. Perfect for academic R&D, automated code auditing, and cryptographic analysis, this API transforms abstract complexity into verifiable results with the performance of top-tier global models.
Advanced Algorithmic Synthesis & Strategic Reasoning using the DeepSeek-R1 API
DeepSeek-R1 empowers developers to build applications centered on deep cognitive workflows and strategic decision-making. Ranking at the forefront of global reasoning benchmarks, the R1 API excels in synthesizing sophisticated code architectures, processing dense technical documentation, and generating innovative solutions for open-ended logical puzzles. It is the ideal engine for AI-driven software engineering, long-form data synthesis, and any scenario where "thinking fast and slow" requires a powerful, reasoning-first foundation.
تنسيق سلس للوكلاء المستقلين باستخدام DeepSeek-V3.2 API
For high-velocity, sensory-driven AI applications, the DeepSeek-V3.2 API provides the perfect equilibrium between reasoning depth and ultra-low latency. It is optimized for building autonomous Agents that can navigate multi-step workflows, manage real-time user interactions, and execute general-purpose tasks with GPT-5 level intelligence. This use case is tailor-made for enterprise-scale automation, intelligent customer ecosystems, and developers looking to deploy responsive, cost-effective AI assistants at scale.
مقارنة النماذج
شاهد كيف تتقارن نماذج مختلف المزودين — قارن الأداء والأسعار ونقاط القوة الفريدة لاتخاذ قرار مدروس.
| نموذج | سياق | الحد الأقصى للمخرجات | إدخال | التموضع |
|---|---|---|---|---|
| DeepSeek V3.2 | 163.84K | 163.84K | Text | عام رائد |
| DeepSeek V3.2 Speciale | 163.84K | 163.84K | Text | مخصص عالي الأداء |
| DeepSeek V3.2 Exp | 163.84K | 163.84K | Text | بناء تجريبي |
| DeepSeek-V3.1 | 131.07K | 65.54K | Text | عمود فقري مفتوح المصدر |
| DeepSeek V3.1 Terminus | 131.07K | 65.54K | Text | مستقر طويل الأمد (LTS) |
| DeepSeek-V3-0324 | 131.07K | 32.77K | Text | لقطة تاريخية |
| DeepSeek-R1-0528 | 131.07K | 131.07K | Text | استدلال من الطراز الأول |
| DeepSeek OCR | 8.19K | 8.19K | Text | متعدد الوسائط مخصص |
| GLM-5 | 200K | 128K | Text | النموذج الأساسي الرائد |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | برمجة وكيلية SOTA |
How to Use DeepSeek LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
لماذا تستخدم DeepSeek LLM Models على Atlas Cloud
دمج نماذج DeepSeek LLM Models المتقدمة مع منصة Atlas Cloud المسرّعة بـ GPU يوفر أداءً لا مثيل له وقابلية للتوسع وتجربة مطور استثنائية.
الأداء والمرونة
زمن انتقال منخفض:
استدلال محسّن لـ GPU للاستجابة في الوقت الفعلي.
API موحد:
قم بتشغيل DeepSeek LLM Models و GPT و Gemini و DeepSeek من خلال تكامل واحد.
تسعير شفاف:
فواتير يمكن التنبؤ بها لكل رمز مع خيارات بدون خادم.
المؤسسات والتوسع
تجربة المطور:
SDKs والتحليلات وأدوات الضبط الدقيق والقوالب.
الموثوقية:
وقت تشغيل 99.99%، RBAC، وتسجيل جاهز للامتثال.
الأمان والامتثال:
SOC 2 Type II، توافق HIPAA، سيادة البيانات في الولايات المتحدة.
الأسئلة الشائعة حول DeepSeek LLM Models
تقدم DeepSeek شفافية المصدر المفتوح وكفاءة فائقة من حيث التكلفة. بفضل قدرات الاستدلال (R1 و V3.2) التي تنافس GPT-5، فإنها توفر بديلاً عالي الأداء ومنخفض التكلفة مع مرونة النشر الخاص.
يعكس هذا إجمالي "القدرة العقلية" للنموذج. يقرن تصميم MoE من DeepSeek بين العدد الإجمالي الهائل للمعلمات (على سبيل المثال، 671 مليار) من أجل الذكاء العميق والعدد "النشط" المُبسّط لتحقيق أقصى قدر من الكفاءة التشغيلية.
استكشف المزيد من العائلات
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


