لا يزال معظم الناس يعتقدون أن الكلمات الأفضل تعني صوراً أفضل. كان هذا صحيحاً قبل عامين. لكن الأمر لم يعد كذلك الآن.
في عام 2026، لا تكمن الفجوة الحقيقية بين النماذج، بل بين المستخدمين الذين يكتفون بـ "الوصف" والمستخدمين الذين يعملون على "البناء". فئة تكتب: "إضاءة سينمائية، دقة 4K، تفاصيل فائقة". أما الفئة الأخرى فتبني المشاهد بناءً دقيقاً؛ يحددون اتجاه الضوء، طبقات العمق، وزوايا الكاميرا.
إذا كانت صورك لا تزال تبدو مسطحة، فالمشكلة غالباً ليست في النموذج، بل فيما لا تخبره به.
لماذا لم تعد مطالباتك (Prompts) كافية (منظور عام 2026)
توقفت المطالبات العامة عن إعطاء نتائج فعالة. فقد شاهدت النماذج عبارات مثل "أفضل جودة" و"تفاصيل عالية" ملايين المرات. هذه الكلمات لم تعد تُحدث فرقاً يُذكر اليوم.
ما المهم حقاً؟ المدخلات المهيكلة. من أين يأتي الضوء؟ ما الموجود في المقدمة مقابل الخلفية؟ أي عدسة تستخدم؟ النماذج الحديثة تستجيب لهذه المتغيرات وتتجاهل الحشو.
إليك نمط شائع: يكتب أحدهم: "بورتريه جميل بإضاءة ناعمة". يقدم النموذج صورة مسطحة. لماذا؟ لعدم وجود اتجاه للضوء، ولا فصل للعمق، ولا زاوية كاميرا محددة. يضطر النموذج للتخمين، والتخمين يؤدي إلى نتائج متوسطة.
التحول الذي تحتاجه بسيط: توقف عن وصف النتيجة، وابدأ في بناء المشهد.
النصائح السبع المتقدمة
-
حدد اتجاه الضوء
كلمة "إضاءة ناعمة" غامضة. الإضاءة الجانبية، الإضاءة الخلفية، أو الإضاءة من الأعلى تمنح النموذج شيئاً ملموساً. الاتجاه يخلق الظلال، والظلال تخلق العمق، والعمق يجعل الصورة تبدو واقعية.
جرب هذا بدلاً من "إضاءة بورتريه ناعمة":
بورتريه لامرأة، إضاءة جانبية من اليسار، ظلال ناعمة على الجانب الأيمن من الوجه، ضوء محيطي خافت من الخلفية

يمكنك رؤية الفرق فوراً؛ يعرف النموذج بالضبط مكان توضع الضوء.
-
استخدم إعدادات التصوير الفوتوغرافي الحقيقية
الإضاءة ثلاثية النقاط، الإضاءة المحيطية (Rim lighting)، إضاءة "رامبرانت". هذه ليست مجرد مصطلحات فاخرة، بل هي أنماط رآها النموذج آلاف المرات أثناء التدريب. استخدمها وستصبح مخرجاتك أكثر استقراراً.
مثال:
لقطة منتج لحذاء رياضي، إعداد إضاءة ثلاثي النقاط، ضوء رئيسي قوي، ضوء ملء (fill light) ناعم، إضاءة محيطية خفيفة لفصل المنتج عن الخلفية الداكنة

هذا يعمل بشكل أفضل من "إضاءة درامية" في كل مرة.
-
ابنِ العمق طبقة تلو الأخرى
الصور المسطحة تعني عادةً أن كل شيء يقع على نفس المستوى. صحح ذلك بتسمية المقدمة، والوسط، والخلفية بشكل صريح.
مثال:
كوب قهوة على طاولة خشبية (المقدمة)، شخص يعمل على كمبيوتر محمول (الوسط)، ديكور مقهى مموه بوضوح خفيف مع أضواء دافئة (الخلفية)

الآن أصبح لدى النموذج علاقات مكانية ليعمل من خلالها.
-
استخدم لغة الكاميرا، لا تسميات الأسلوب
"أسلوب سايبربانك" مصطلح غامض. "عدسة 35 ملم، زاوية منخفضة، لقطة واسعة" مصطلحات دقيقة. إعدادات الكاميرا ترتبط مباشرة بكيفية بناء الصور.
احتفظ بهذه في جعبتك:
- 35 ملم لمظهر طبيعي يومي.
- 85 ملم للبورتريه مع ضغط الخلفية.
- عدسة واسعة للدراما وضخامة المشهد.
- زاوية منخفضة، مستوى العين، أو من الأعلى للمنظور.
مثال:
بورتريه مقرب، عدسة 85 ملم، عمق مجال ضحل، زاوية على مستوى العين، تمويه خلفية ناعم

هذا يمنح النموذج تعليمات أوضح بكثير من "بورتريه جمالي".
-
وجّه الانتباه من خلال التباين
الهدف ليس وجود تفاصيل كثيرة في كل مكان، بل التباين. الضوء مقابل الظل، الألوان الدافئة مقابل الباردة، العنصر الحاد مقابل الخلفية المموهة.
ثلاثة أنواع من التباين تعمل بشكل جيد:
- تباين الضوء: عنصر ساطع مقابل خلفية داكنة.
- تباين الألوان: بقعة ضوء دافئة على خلفية ذات نغمات باردة.
- تباين التفاصيل: عنصر حاد مع بيئة ضبابية.
مثال:
عنصر مضاء بواسطة بقعة ضوء دافئة مقابل خلفية داكنة ذات نغمات باردة، إضاءة عالية التباين، تركيز قوي على العنصر
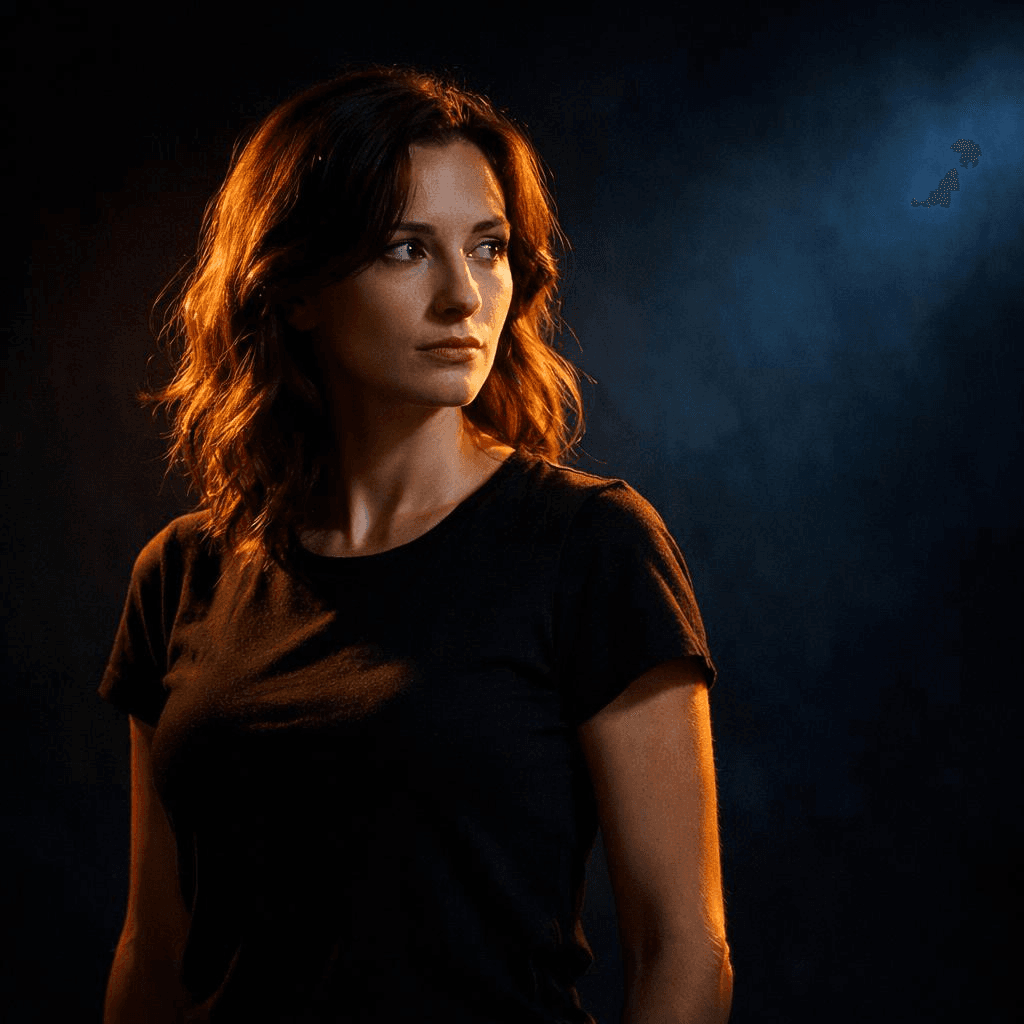
هنا تذهب عين المشاهد بالضبط إلى حيث تريد.
-
أضف قيوداً لتنظيف الفوضى
المطالبات الطويلة تصبح فوضوية. بدلاً من إضافة المزيد من التفاصيل، أضف قيوداً. أخبر النموذج بما لا تريده: لا فوضى، لا تشوه، لا أجسام إضافية.
مثال:
لقطة منتج بسيطة (Minimalist)، تكوين مركزي، خلفية بيضاء نظيفة، بدون فوضى، بدون نص، بدون تشوه

القيود غالباً ما تفعل أكثر مما تفعله الأوصاف الإضافية.
-
كرر التجربة كمخرج، لا كقامر
لا أحد يحصل على الصورة النهائية من المحاولة الأولى. المحترفون يولدون الصور، يعدلون، ثم يولدون مجدداً.
سير عمل بسيط:
- الخطوة الأولى: تكوين أساسي، العنصر والبيئة.
- الخطوة الثانية: إضافة إضاءة اتجاهية وتباين.
- الخطوة الثالثة: صقل التفاصيل وإزالة الفوضى.
كل جولة تحسن النتيجة. هكذا تنتقل من الحظ إلى الاتساق.
الخلاصة — من كتابة المطالبات إلى الإخراج الفني
الحصول على صورة واحدة رائعة أمر جيد، لكن المشاريع الحقيقية تتطلب مئات الصور المتسقة وعالية الجودة. كتابة المطالبات يدوياً لا يمكن توسيع نطاقها.
ستواجه مشكلات عملية مثل التأخير، التكلفة لكل صورة، والحفاظ على نفس الأسلوب البصري. تصميم المطالبات وحده لا يحل هذه المشكلات؛ أنت بحاجة إلى نظام.
هنا يصبح توليد الصور عبر الـ API أمراً جوهرياً. بدلاً من كتابة المطالبات في كل مرة، يمكنك دمج التوليد في سير عملك، حيث يتم إعادة استخدام المطالبات المهيكلة، وأتمتتها، وتحسينها بمرور الوقت.
توفر منصات مثل Atlas Cloud طبقة API موحدة لهذا الغرض.
وإذا كنت: • مطوراً يبحث عن وصول سهل وبأسعار معقولة للذكاء الاصطناعي. • فريقاً يدير مشاريع تحتاج للذكاء الاصطناعي في مجالات متعددة. • شركة تحتاج إلى ذكاء اصطناعي موثوق لأعمال مهمة. • مستخدماً لأدوات مثل ComfyUI و n8n.
جرب AtlasCloud، وستجد نفسك تنتقل من مرحلة التجربة إلى مرحلة الإنتاج الفعلي دون الحاجة لإعادة بناء البنية التحتية من الصفر.
المستقبل لا يتعلق بكتابة مطالبات أفضل بشكل منعزل، بل يتعلق ببناء أنظمة بصرية قابلة للتحكم والتكرار وجاهزة للإنتاج.
الأسئلة الشائعة
لماذا تبدو صوري بالذكاء الاصطناعي مسطحة؟
الصور المسطحة تعني عادةً أنك أغفلت مؤشرات العمق. فكر في كيفية عمل التصوير الفوتوغرافي؛ العمق يأتي من الظلال، وتداخل الأشياء، واختلافات التركيز. يجب أن توضح ذلك في مطالباتك.
خذ مطالبة بسيطة مثل: "شخص يجلس على مكتب". هذا لا يخبر النموذج شيئاً عن العمق. جرب بدلاً من ذلك: "شخص يجلس على مكتب (الوسط)، نافذة مموهة بأضواء المدينة (الخلفية)، كوب قهوة بتركيز حاد (المقدمة)". الآن لدى النموذج طبقات ليعمل بها.
الإضاءة سبب آخر للأخطاء. العديد من المطالبات تذكر فقط الضوء المحيط، وهذا يعطي إضاءة مسطحة ومتساوية. أضف مصدراً اتجاهياً: ضوء جانبي، خلفي، أو محيطي. اختر واحداً، وسيبدأ النموذج في إلقاء الظلال، وفجأة ستكتسب صورتك حجماً.
شيء آخر: لا تحاول ملء كل زاوية بالتفاصيل. المساحات الفارغة والتمويه مفيدة؛ فهي تخبر المشاهد أين ينظر. أحياناً، التفاصيل الأقل تمنحك عمقاً أكبر.
هل يمكن للذكاء الاصطناعي استبدال تصوير المنتجات؟
نعم، في كثير من الحالات. لكن لنكن صادقين بشأن أين ينجح وأين يفشل. إذا كنت بحاجة إلى لقطة احترافية لساعة فاخرة -حيث يهم كل انعكاس على المعدن وتكون ملمس الحزام الجلدي دقيقاً- فإن التصوير التقليدي لا يزال هو الفائز؛ لا يمكنك التفوق على الاستوديو الحقيقي في ذلك.
لكن لكل شيء آخر، الذكاء الاصطناعي أسرع وأرخص. صور الكتالوجات، مشاهد أسلوب الحياة، التغيرات الموسمية، واختبارات الإعلانات (A/B testing). يمكنك توليد لقطة منتج نظيفة على خلفية بيضاء في ثوانٍ، ثم وضع تلك الصورة في مشهد شاطئي، أو مقصورة شتوية، أو مطبخ عصري. لا تأجير استوديو، لا إضاءات مكلفة، ولا إعادة لمس (Retouching). كل صورة تكلف قروشاً قليلة.
بالنسبة للعلامات التجارية الصغيرة والشركات الناشئة، هذا يغير قواعد اللعبة؛ حيث يمكنهم الآن إنتاج مرئيات تنافس الشركات ذات الميزانيات الضخمة، وهو ما لم يكن ممكناً قبل عامين.
كيف يختلف نموذج توليد الصور من OpenAI عن الإصدارات السابقة؟
يحتوي النموذج الجديد، GPT‑image‑1.5، على تغييرات معمارية داخلية. فهو يستخدم "محول الانتشار" (diffusion transformer)، وهو مصطلح فني يعني أنه يتعامل مع العلاقات المكانية بشكل أفضل.
الإصدارات القديمة كانت تقسم المشاهد المعقدة إلى قطع لا تتناسب مع بعضها بشكل جيد؛ فقد تطفو اليد بجانب الكوب بدلاً من إمساكه، أو تشير الظلال في اتجاهات خاطئة. الإصدار الجديد يحافظ على ترابط الأشياء.
عرض النصوص قفزة كبيرة أخرى. النماذج السابقة كانت تنتج حروفاً مشوهة تشبه رموزاً عشوائية. أما GPT‑image‑1.5 فيولد كلمات قابلة للقراءة بلغات متعددة. يمكنك مزج الإنجليزية والصينية في نفس الصورة، وهذا يعمل الآن بفعالية.
يدعم النموذج أيضاً دقات أعلى أصلاً -تصل إلى 2K دون الحاجة لتوسيع النطاق- مع عدد أقل من العيوب (artifacts) وتفاصيل أكثر حدة.
هناك جانب سلبي: النموذج أقل تسامحاً مع المطالبات الغامضة. لا يمكنك فقط قول "بورتريه جميل" وتوقع السحر، عليك أن تكون أكثر دقة. ولكن عندما تمنحه تعليمات مهيكلة (اتجاه الضوء، طبقات العمق، إعدادات الكاميرا)، فإن جودة المخرجات أفضل من أي جيل سابق.






