
منذ بضعة أشهر، وضعنا لأنفسنا هدفًا يبدو بسيطًا بشكل خادع: إنتاج فيديو متماسك وعالي الجودة أطول من 15 ثانية، على وحدة معالجة رسومات (GPU) واحدة، في أقل من دقيقة واحدة من وقت التنفيذ الفعلي. نماذج انتشار الفيديو الحالية مثل Wan2.2 جيدة في مقاطع مدتها 3–5 ثوانٍ. أما تمديد ذلك إلى 10 ثوانٍ أو 30 ثانية أو دقيقة فهو المكان الذي تصبح فيه الأمور مثيرة للاهتمام.
يوثق هذا المنشور المسار الذي سلكناه بالفعل. قمنا بمسح ستة مناهج ظهرت في الأوراق البحثية والتقارير التقنية الأخيرة — TTT، وLoL، وSelf Forcing، وSelf Forcing++، وInfinite Talk، وHelios — وقياس المقايضات، واستقر بنا المطاف في النهاية على SVI (Stable Video Infinity)، وربطناه بـ TurboWan في محرك DiffSynth Engine الخاص بنا. سنستعرض كل مسار من تلك المسارات، ثم كيفية عمل SVI، ثم أرقام الإنتاج.
لماذا يصعب إنتاج فيديو طويل؟
تتعطل ثلاثة أشياء عندما تتجاوز الخمس ثوانٍ تقريبًا.
جدار ذاكرة الفيديو (VRAM wall)
يستخدم Wan2.2 خاصية الانتباه الكامل (Full Attention) بتكلفة O(n²) في عدد رموز (tokens) الكامنة. الرياضيات هنا لا ترحم:
5 ثوانٍ (81 إطارًا): ~32.7 ألف رمز، مصفوفة انتباه ~10 جيجابايت.
10 ثوانٍ (165 إطارًا): ~65.5 ألف رمز، مصفوفة انتباه ~40 جيجابايت — تبدأ بالفعل في تجاوز سعة وحدة معالجة رسومات واحدة.
30 ثانية (~500 إطار): ~200 ألف رمز، أمر غير مجدٍ.
من الناحية العملية، تملأ تقنية Self Forcing وحدها معظم سعة ذاكرة H200 البالغة 129 جيجابايت عند 165 إطارًا فقط لذاكرة التخزين المؤقت KV.
الانحراف الزمني (Temporal drift)
حتى عندما تكون الذاكرة كافية، تظهر ثلاثة أنماط للانحراف. أطلقت عليها ورقة Helios البحثية أسماء: تحول الموقع (تجوّل العناصر عبر الإطار)، تحول اللون (انحراف تدريجي في تدرج اللون والسطوع)، و_تحول الاستعادة_ (الإفراط في التصحيح من النموذج وإنتاج انقطاعات مرئية).
الاتساق السببي (Causal consistency)
يستخدم انتشار الفيديو القياسي خاصية الانتباه الكامل ثنائي الاتجاه — كل إطار ينتبه لكل إطار آخر. هذا يعني عدم وجود إخراج متدفق (streaming): لا يمكنك عرض الإطار 1 حتى ينتهي الإطار N.
كان هدفنا المحدد متواضعًا: فيديو ≥15 ثانية، استمرارية بصرية سلسة، عناصر مستقرة عبر المقطع بأكمله، وقت انتظار إجمالي أقل من 60 ثانية، حد أدنى من التدريب، وتفضيل قوي لإعادة استخدام الأوزان التي نمتلكها بالفعل.
المسح التقني
لقد نظرنا في ست عائلات. الأسماء في الغالب هي عناوين أوراق بحثية؛ وستكون الفئات مهمة لاحقًا.
المسار 1 · TTT (التدريب أثناء الاختبار - Test-Time Training)
الورقة البحثية: One-Minute Video Generation with Test-Time Training (arXiv 2504.05298، أبريل 2025).
الفكرة هي ضبط النموذج بدقة أثناء الاستدلال بحيث يتذكر ما ولّده بالفعل. يتم إدراج طبقة TTT صغيرة (طبقة MLP من مستويين، بالإضافة إلى بوابة وانتباه محلي) بعد الانتباه في كل كتلة Transformer، ويتم تدريب النموذج على منهج دراسي ينتقل من المقاطع القصيرة إلى دقيقة كاملة.
الإدراج لكل كتلة: بعد الانتباه القياسي، يتم لصق بوابة (Gate)، وطبقة TTT، وانتباه محلي (Local Attention)، ثم طبقة LayerNorm.
المنهج الدراسي: التدريب على نوافذ متزايدة الطول — 3 ثوانٍ ← 9 ثوانٍ ← 18 ثانية ← 30 ثانية ← 60 ثانية.
التكلفة: 256 وحدة H100 لمدة ~50 ساعة.
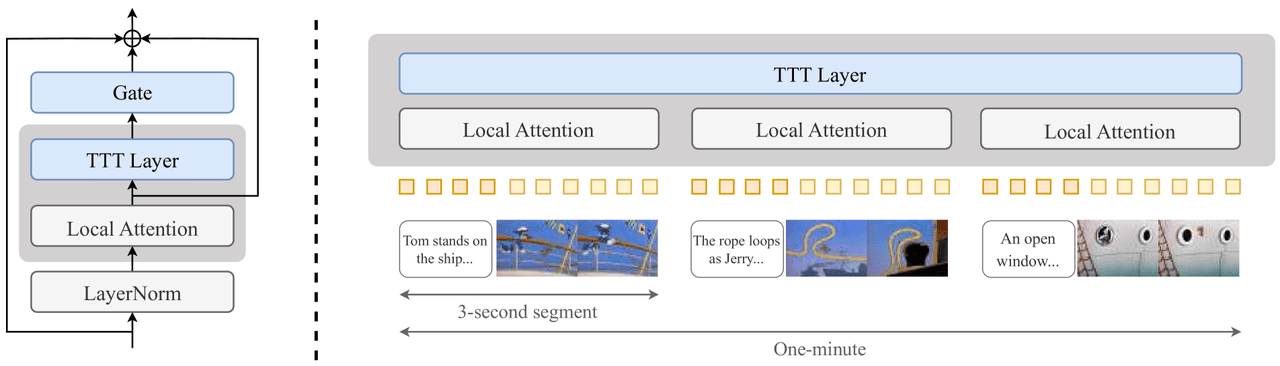
TTT — اليسار: نقطة الإدراج (بوابة + طبقة TTT + انتباه محلي + LayerNorm، مرتبطة بعد الانتباه القياسي عبر residual). اليمين: فيديو مقسم إلى مقاطع مدتها 3 ثوانٍ، كل منها يتم التعامل معه بواسطة الانتباه المحلي داخليًا، مع حمل طبقة TTT للذاكرة العالمية عبر المقاطع.
إنه يعمل — حيث تصل الورقة البحثية إلى توليد فيديو مدته دقيقة واحدة. لكن تكلفة التدريب هائلة، والتجارب تغطي فقط CogVideoX 5B (انتقال الوزن إلى Wan2.2 14B غير مثبت)، وتتعارض طبقات TTT المدرجة مع تحسينات النواة (kernel optimizations) التي نعتمد عليها بالفعل. الحكم: لم يتم الاختيار.
المسار 2 · LoL (أطول من الطويل - Longer than Longer)
الورقة البحثية: LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914، يناير 2026).
يستهدف LoL نمط فشل محدد في الفيديو الطويل ذاتي الانحدار (autoregressive) — انهيار الحوض (sink-collapse)، حيث تتقارب خاصية الانتباه متعدد الرؤوس (multi-head attention) كلها نحو الإطار المرجعي ويعود الفيديو بشكل دوري إلى حالته الأولية. الحل هو اهتزاز RoPE متعدد الرؤوس (Multi-Head RoPE Jitter): اضطرابات طور عشوائية لكل رأس تكسر تجانس الرؤوس. بدون تدريب، يعمل كإضافة.
نمط الفشل: انهيار الحوض — تحت تأثير RoPE ذاتي الانحدار، تعيد أطوار المواضع للإطارات البعيدة محاذاة نفسها دوريًا مع الإطار المرجعي، ويتركز الانتباه، ويعود المحتوى إلى الإطار المرجعي.
الحل: إعطاء كل رأس انتباه إزاحة طور عشوائية صغيرة خاصة به. لم تعد الرؤوس قادرة على الانهيار إلى نفس العمود. لا يتطلب إعادة تدريب، ويعمل مع النماذج الحالية.
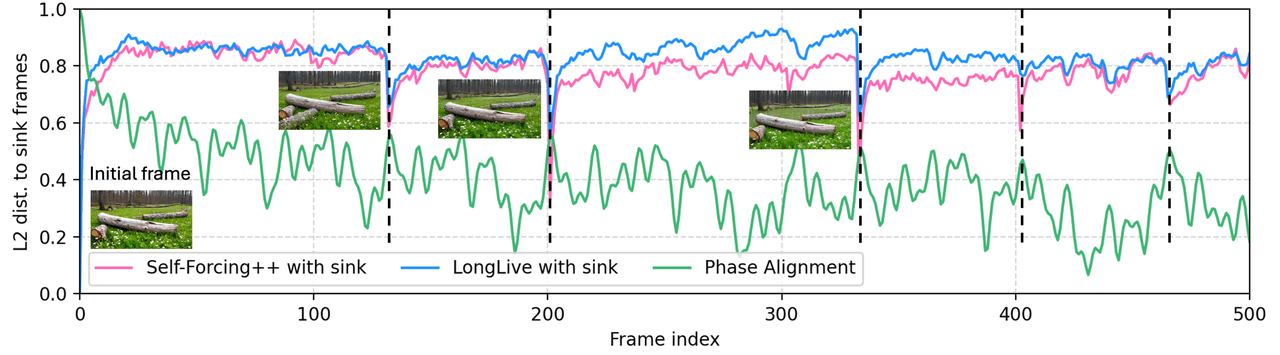
مسافة L2 إلى المرجع مقابل مؤشر الإطار. Self-Forcing++ (أحمر) وLongLive (أزرق)، كلاهما مع وجود حوض، يعودان بشكل متكرر عند مواضع إطار محددة — تلك هي أحداث انهيار الحوض حيث يعود الفيديو إلى المرجع. محاذاة الطور في LoL (أخضر) تقضي على الارتداد.
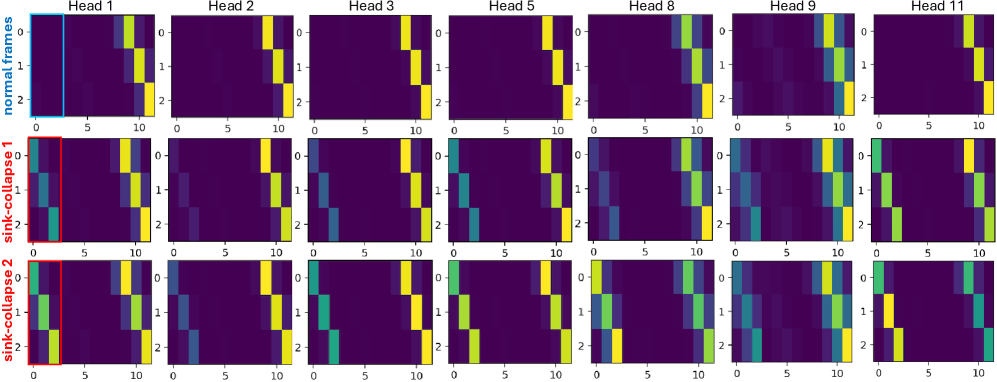
خرائط الانتباه لكل رأس. الصف العلوي: إطارات عادية — الرؤوس لديها أنماط مختلفة بشكل واضح. الصفوف السفلية: أثناء انهيار الحوض — يبدو كل رأس كما هو، كلها انهارت على عمود الإطار المرجعي. يعمل اهتزاز RoPE على استعادة تنوع الرؤوس.
يصل LoL إلى 12 ساعة من الفيديو على CogVideoX/HunyuanVideo مع فقدان ضئيل في الجودة. المشكلة هي أن جميع العروض التوضيحية عبارة عن مشاهد ساكنة نوعًا ما؛ لا نعرف كيف يصمد في الرقص أو الرياضة أو أي شيء به حركة قوية. بالإضافة إلى ذلك، سنحتاج إلى تعديل انتباه Wan2.2. الحكم: تكلفة التكيف عالية جدًا مقابل مكاسب غير مثبتة في محتوى الحركة. لم يتم الاختيار.
المسار 3 · Self Forcing (Wan2.2 السببي)
الورقة البحثية: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009، NeurIPS 2025 Spotlight).
يستبدل Self Forcing خاصية الانتباه الكامل ثنائي الاتجاه في Wan2.2 بـ الانتباه السببي (causal attention): ينتبه الإطار فقط للإطارات التي تسبقه. هذا التغيير الواحد يفتح الباب لتوليد الفيديو المتدفق — بمجرد الانتهاء من الجزء 1، قم بفك التشفير وإرساله.
ثنائي الاتجاه: كل إطار ينتبه لكل إطار آخر ← يجب إنهاء جميع خطوات تقليل الضوضاء الأربعين قبل عرض أي إطار. سببي: الإطار يرى ماضيه فقط ← يمكن للجزء الأول البث بمجرد انتهائه.
خدعة التدريب هي ما أعطت الورقة اسمها. بدلاً من التدريب على سياق الحقيقة الأرضية النظيف (Teacher Forcing) أو باستخدام أقنعة انتباه مخصصة (Diffusion Forcing)، يقوم Self Forcing بتنفيذ مسار الاستدلال الفعلي باستخدام ذاكرة تخزين مؤقت KV متدحرجة، بحيث تتطابق توزيعات التدريب والاستدلال.
حلقة التوليد: تقليل ضوضاء الجزء الصغير التالي من الإطارات باستخدام جدول خطوات DMD المضغوط، مشروطًا بذاكرة KV متدحرجة مبنية من الإطارات التي تم إنشاؤها بالفعل.
البث: بمجرد انتهاء الجزء، يتم فك تشفيره بواسطة VAE وإصداره.
الترحيل: دفع إطارات الجزء الجديد إلى ذاكرة KV ليتم الانتباه إليها في الجزء التالي.
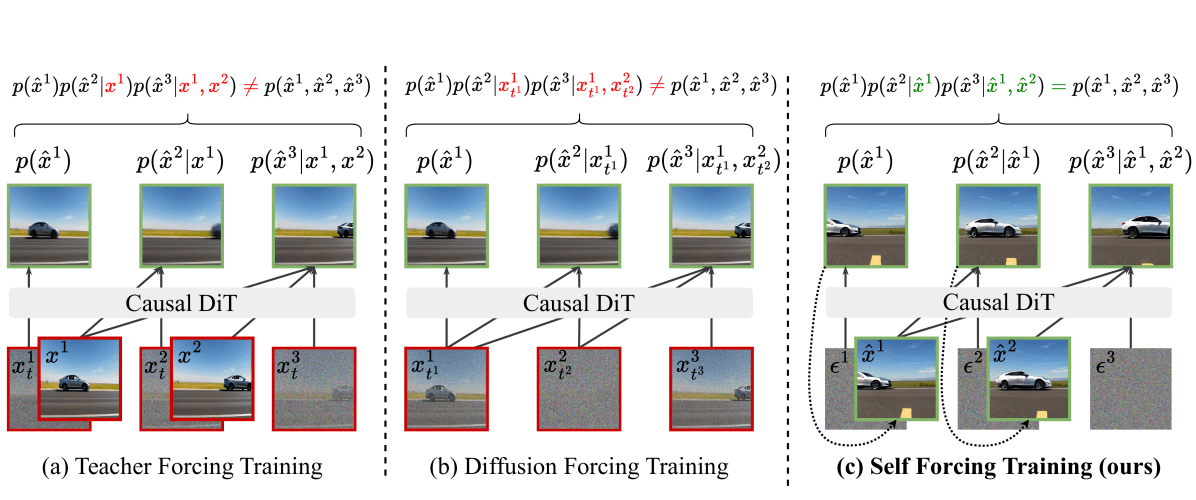
تمت مقارنة ثلاثة نماذج تدريب: (أ) Teacher Forcing يتدرب على إطارات نظيفة — في الاستدلال، تسبب الإطارات المشوشة انحرافًا عن التوزيع؛ (ب) Diffusion Forcing يستخدم أقنعة انتباه مخصصة ولكن لا يزال هناك عدم تطابق في التدريب والاستدلال؛ (ج) Self Forcing يعيد تشغيل عملية الاستدلال الحقيقية باستخدام ذاكرة KV متدحرجة، مما يطابق التدريب والاستدلال تمامًا.
قمنا بقياسه على إطار عمل FastVideo، باستخدام وحدة H200 واحدة:
| الطول | الإطارات | الوقت | ذاكرة الفيديو (VRAM) |
|---|---|---|---|
| 5 ثوانٍ | 81 إطارًا | 70 ثانية | — |
| 10 ثوانٍ | 165 إطارًا | 168 ثانية | 129 جيجابايت (قرب السعة الكاملة) |
| 20 ثانية | 321 إطارًا | 287 ثانية | 129 جيجابايت (تم تقييد ذاكرة KV بـ 42 إطارًا) |
هذه هي الإجابة الأنظف من الناحية المعمارية، ونحن نحبها حقًا. لكن 10 ثوانٍ تشبع بالفعل ذاكرة VRAM الخاصة بـ H200، وتنخفض الجودة عند 165 إطارًا، ويحتاج النموذج الأصلي إلى ضبط دقيق للانتباه السببي، كما يتطلب البث الحقيقي أيضًا Causal Conv3D في VAE.
الحكم: ننتظر أن يقوم المجتمع بتقليل استهلاك VRAM وتحسين الجودة. لم يتم اعتماده حاليًا.
المسار 4 · Self Forcing++
الورقة البحثية: Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283، أكتوبر 2025).
يبني على Self Forcing مع ثلاث إضافات: تهيئة الضوضاء العكسية (Backward Noise Initialization) (كل جزء جديد يبدأ من ضوضاء مدمجة عكسيًا من إطارات تم إنشاؤها بالفعل، مما يزيل انقطاعات حدود الجزء)؛ محاذاة DMD الموسعة (Extended DMD alignment) (تقطيع نوافذ مدتها 5 ثوانٍ من طرح طويل ومحاذاتها مقابل مخرج نافذة قصيرة لمعلم)؛ ومرحلة GRPO بمكافأة التدفق البصري (optical-flow) للدفع نحو حركة أكثر ديناميكية.
الخطوة 1. تنفيذ ذاتي للنموذج لفترة أطول بكثير من 5 ثوانٍ، وتجميع مسودة طويلة باستخدام ذاكرة KV متدحرجة. الخطوة 2. تقطيع نوافذ عشوائية مدتها 5 ثوانٍ من تلك المسودة، وتشغيلها من خلال DMD الموسعة مقابل توزيع النافذة القصيرة للمعلم للمحاذاة. الخطوة 3. التحسين باستخدام GRPO باستخدام مقدار التدفق البصري كمكافأة، مما يدفع النموذج نحو حركة أكثر ديناميكية. الخدعة. كل جزء جديد يبدأ من ضوضاء مدمجة عكسيًا من الجزء السابق، وليس من Gaussian جديد — لذا لم تعد حدود الأجزاء تظهر بشكل مفاجئ.
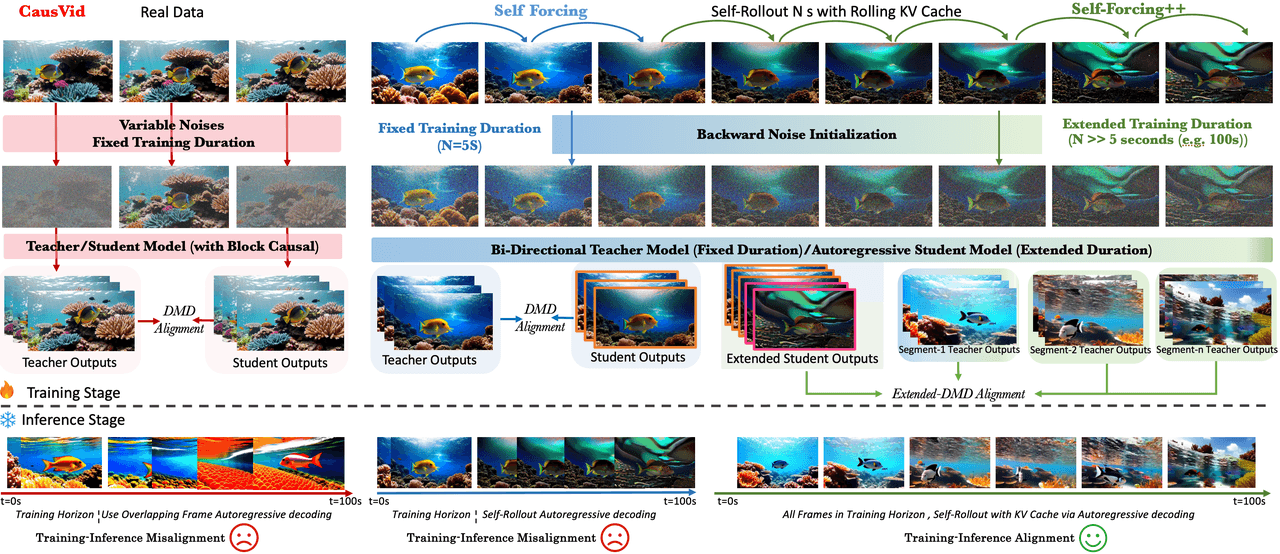
من اليسار إلى اليمين: CausVid (مدة تدريب ثابتة، عدم تطابق تدريب-استدلال) ← Self Forcing (مدة ثابتة + محاذاة DMD) ← Self-Forcing++ (مدة ممتدة + تهيئة الضوضاء العكسية + محاذاة DMD موسعة). تظهر الصفوف السفلية التوافق بين مرحلة التدريب ومرحلة الاستدلال.
النتيجة: فيديو بحجم دقيقة (يصل إلى حوالي 4 دقائق و15 ثانية) على Wan2.1 1.3B. ورقة رائعة. للإنتاج، اصطدمنا بجدارين: المحتوى ثابت في الغالب (حركة منخفضة)، النموذج الأساسي هو 1.3B (أقل بكثير من Wan2.2 14B)، ولا يوجد كود أو أوزان مُصدرة للبدء منها. الحكم: لم يتم الاختيار حاليًا.
المسار 5 · Infinite Talk (A2V)
شكل مختلف تمامًا للمشكلة — من الصوت إلى الفيديو (Audio-to-Video)، حيث يقود الصوت توليد رأس يتحدث بشكل مستمر.
حزمة إدخال كل جزء: الرموز الكامنة المشوشة للجزء الجديد، ميزات الصوت لتلك النافذة الزمنية، الصورة المرجعية المقدمة من المستخدم، الإطار الأخير للجزء السابق، ووزن تكييف ناعم. الهوية المرجعية: تحافظ الصورة المرجعية على ثبات المظهر على المدى الطويل. القيد التكيفي: يقوم الوزن الناعم بتشديد أو إرخاء المرجع بناءً على انحراف التشابه. جسر الحركة: يحمل الإطار الأخير للجزء السابق الحركة عبر الحدود.
إنه جيد لما صُمم من أجله — رؤوس متحدثة، إلى أجل غير مسمى. لكن الهندسة المعمارية تختلف بما يكفي عن Wan2.2 بحيث تتطلب تدريبًا مخصصًا، ولا تعمم على المشاهد العامة. الحكم: قيّم في مجال ضيق، وليس حلاً عامًا للفيديو الطويل.
المسار 6 · Helios
الورقة البحثية: Helios: Real Real-Time Long Video Generation Model (PKU-YuanGroup, arXiv 2603.04379، مارس 2026).
حتى كتابة هذا التقرير، تعد Helios هي الأفضل (SOTA) للفيديو الطويل — 14B بارامتر، 19.5 إطارًا في الثانية في الوقت الفعلي على H100 واحدة. الحيلة هي ضغط الإطارات التاريخية في هرم من ثلاثة مستويات وحقنها في تقليل ضوضاء الإطار الحالي، بحيث تظل ميزانية الرموز ثابتة بغض النظر عن طول الفيديو.
الذاكرة متعددة المصطلحات (Multi-Term Memory). التاريخ قصير المدى (آخر 3 إطارات) يحافظ على الدقة الكاملة؛ متوسط المدى (آخر 20 إطارًا) يحصل على ضغط معتدل؛ طويل المدى (كل ما سبق) يحصل على ضغط شديد. ميزانية الرموز الإجمالية ثابتة بغض النظر عن طول الفيديو. انتباه التوجيه (Guidance Attention). داخل كل كتلة DiT، تتم معالجة رموز KV التاريخية النظيفة ورموز QKV الحالية المشوشة بشكل منفصل بحيث لا يمكن للضوضاء التاريخية تلويث تقليل الضوضاء الحالي. أخذ العينات الهرمي (Pyramid Sampling). أخذ عينات بدقة منخفضة أولاً لتحديد الهيكل، ثم التحسين إلى دقة عالية لإضافة التفاصيل — حوالي 2.3 ضعف عدد رموز أقل بشكل عام.
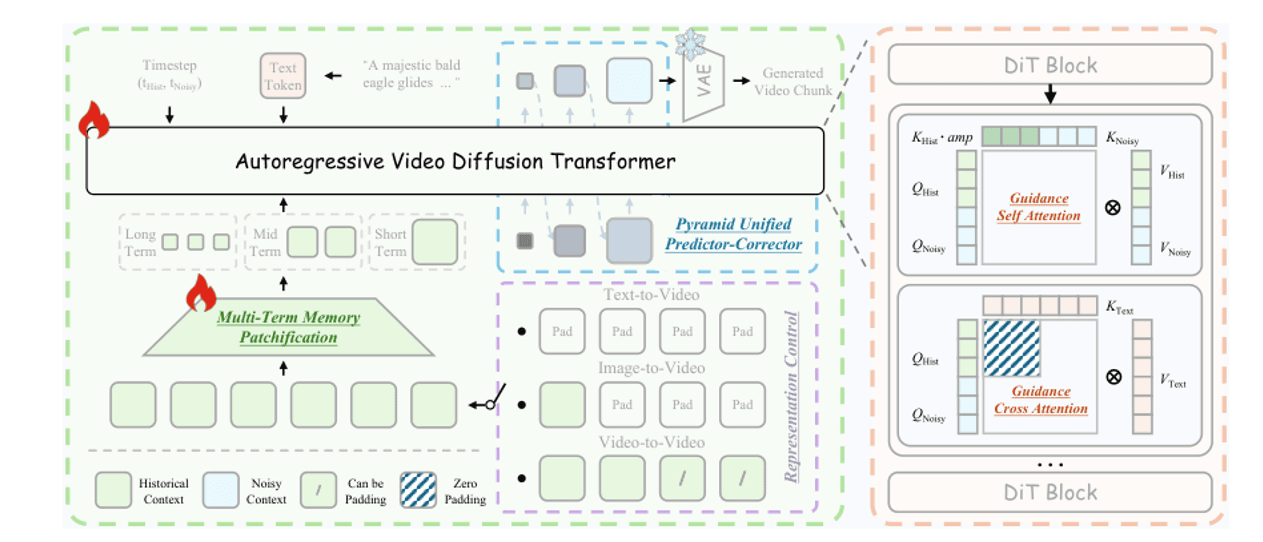
هندسة Helios. اليسار: حقن التاريخ الموحد — تاريخ قصير/متوسط/طويل المدى مضغوط بنسب مختلفة، مدمج مع الإطار الحالي قبل دخول DiT. اليمين: المصحح التنبئي الهرمي الموحد — عدد رموز منخفض أولاً لتحديد الهيكل، ثم عدد رموز مرتفع لتحسين التفاصيل، مما يقلل الحساب بنسبة ~2.3×.

تحدد ورقة Helios بشكل منهجي وتصور ثلاث فئات من الانحراف في توليد الفيديو الطويل: (أ) تحول الموقع، (ب) تحول اللون، (ج) تحول الاستعادة (ضوضاء)، (د) تحول الاستعادة (ضبابية). تم تصميم انتباه التوجيه خصيصًا لمعالجة الثلاثة جميعًا.
إنتاجية Helios المقاسة على H200 ملفتة للنظر — مسطحة بشكل أساسي مع الطول:
| الطول | الوقت | الإنتاجية |
|---|---|---|
| 240 إطارًا (10 ثوانٍ) | 24 ثانية | ~10 إطارات/ثانية |
| 480 إطارًا (20 ثانية) | 42 ثانية | ~11.4 إطار/ثانية |
| 960 إطارًا (40 ثانية) | 82 ثانية | ~11.7 إطار/ثانية |
| H100 وحدة واحدة (Helios-Distilled) | — | 19.5 إطار/ثانية |
المشكلة هي أن تقنية Multi-Term Memory Patchification تحتاج إلى إعادة تدريب كامل لنموذج 14B. لا توجد أوزان مُصدرة — فقط تقرير تقني — لذلك لا يمكننا ببساطة إضافة LoRA. الحكم: اتجاه متوسط إلى طويل المدى؛ غير قابل للنشر اليوم.
ملخص مقارنة المسارات
المسارات الستة جنبًا إلى جنب، مع إضافة SVI كصف التزمنا به في النهاية:
| النهج | أقصى مدة | الجودة | التدريب المطلوب | صعوبة الهندسة | العمومية | التوصية |
|---|---|---|---|---|---|---|
| TTT | 1 دقيقة | عالية | تدريب ثقيل مطلوب | عالية | متوسطة | ★★☆ |
| LoL | على مستوى الساعة | متوسطة (ثابتة فقط) | تدريب مطلوب | متوسطة | متوسطة | ★★☆ |
| Self Forcing | غير محدود نظريًا | متوسطة (تنخفض > 10 ثوانٍ) | نموذج موجود | عالية (مشاكل VRAM) | عالية | ★★★ |
| Self Forcing++ | على مستوى الدقيقة | منخفضة (ثابتة في الغالب) | تدريب مطلوب | عالية جدًا (لا يوجد كود) | عالية | ★☆☆ |
| Infinite Talk | غير محدود | عالية (رأس متحدث) | تدريب مطلوب | عالية | منخفضة (A2V فقط) | ★★☆ |
| Helios | غير محدود نظريًا | عالية (الأفضل صناعيًا) | إعادة تدريب كاملة | عالية جدًا (لا توجد أوزان) | عالية | ★★★☆ |
| SVI | غير محدود | متوسطة-عالية | LoRA مفتوح المصدر | متوسطة | عالية | ★★★★ |
تصنيف ظهر من خلال المسح
إذا دققت النظر، يندرج كل نهج قمنا بمسحه في واحدة من ثلاث فئات.
النوع أ — توسيع نطاق الانتباه نفسه (Self Forcing, LoL, TTT). اجعل النموذج يعالج تسلسلات أطول مباشرة. أعلى جودة نظرية. تنمو ذاكرة VRAM بشكل تربيعي، لذا تصل الهندسة إلى جدار عند 10 ثوانٍ اليوم.
النوع ب — ضغط التاريخ الهرمي (Helios). ضغط الإطارات السابقة وحقنها كشرط. يتجاوز عائق VRAM. يكلف إعادة تدريب كاملة لنموذج 14B.
النوع ج — التوليد المتدحرج ذو الحالة (SVI, Infinite Talk). تحليل الفيديو الطويل إلى مقاطع قصيرة بحالة متداخلة. ذاكرة VRAM ثابتة، طول غير محدود، تدريب LoRA فقط. المقايضة هي انقطاعات محتملة عند حدود المقاطع وانحراف غير محدود على المدى الطويل يمكنك إدارته ولكن لا يمكنك القضاء عليه.
بالنسبة لهذا الربع، النوع ج هو ما نقوم بشحنه. بالنسبة للعام المقبل، النوع ب هو المكان الذي نراقب فيه الأدبيات.
في المنشور القادم، سنستعرض كيف كان الشحن في الواقع — ستة مناهج لتوليد فيديو ≥15 ثانية، ولماذا اخترنا SVI، وكيف تبدو أرقام الإنتاج. اقرأ الجزء 2 →






