
في الجزء الأول، استعرضنا ستة أساليب لتوليد مقاطع الفيديو الطويلة — TTT وLoL وSelf Forcing وSelf Forcing++ وInfinite Talk وHelios — وتوصلنا إلى أن SVI هي المسار الوحيد القابل للتنفيذ حالياً دون الحاجة لإعادة تدريب نموذج بحجم 14B. يتناول هذا المقال تجربتنا العملية في البناء باستخدام هذا الأسلوب: كيف تعمل حلقة ربط المقاطع (clip-stitching loop)، ولماذا تعتبر "إعادة تدوير الأخطاء" (Error-Recycling) أمراً جوهرياً، والأرقام الإنتاجية من أول تجربة لنا على TurboWan.
الخيار: SVI (Stable Video Infinity)
تعتمد الفلسفة الأساسية لـ SVI على تحويل عملية التوليد ذات الطول اللانهائي إلى ربط عدد محدود من المقاطع القصيرة مع نقل ذاكرة مصمم بعناية. قد يبدو هذا بسيطاً، لكنه يحل معظم معوقات الهندسة دفعة واحدة: لا حاجة لإعادة تدريب النموذج الأساسي (يتم تركيب LoRA صغير على TurboWan)، استهلاك ثابت لذاكرة الفيديو (VRAM)، إمكانية التوافق مع تقنيات تقطير السرعة الحالية، وتوفر أوزان LoRA الرسمية للجمهور.
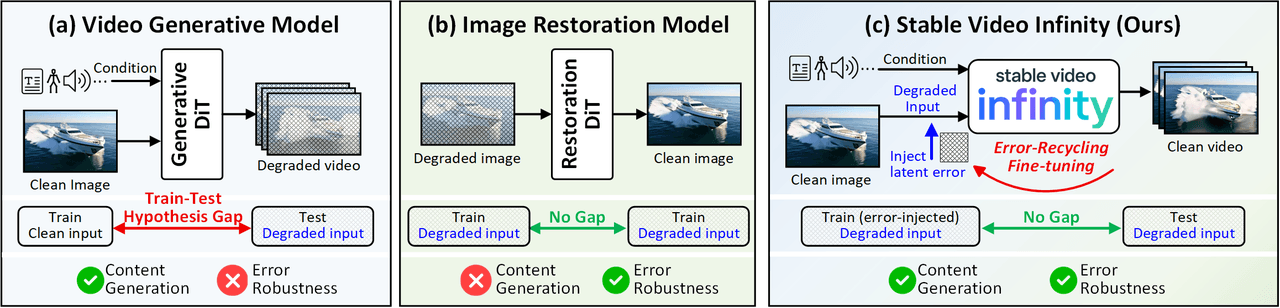
النموذج الذهني لـ SVI: (أ) تعاني نماذج توليد الفيديو القياسية من فجوة فرضية التدريب والاختبار، حيث تتدرب على مدخلات نظيفة لكنها تواجه مدخلات مشوشة تراكمت فيها الأخطاء أثناء الاستنتاج. (ب) نماذج استعادة الصور قوية في التعامل مع الأخطاء لكنها لا تستطيع توليد محتوى جديد. (ج) تعمل ميزة "الضبط الدقيق عبر إعادة تدوير الأخطاء" (Error-Recycling Fine-Tuning) على سد هذه الفجوة؛ حيث تستخدم الأخطاء المولدة ذاتياً كإشارات إشرافية ليتعلم النموذج تحديد وتصحيح أخطاء التوليد الخاصة به بشكل نشط.
كيف يعمل ربط المقاطع
يتكون كل مقطع من 81 إطاراً (5 ثوانٍ بمعدل 16 إطاراً في الثانية). عملية التوليد هي مجرد حلقة تكرارية: تهيئة المقطع التالي بناءً على مرجع هوية عالمي وجسر حركة قصير المدى من المقطع السابق، ثم دمجهم.
المقطع 1: المدخلات: صورة مرجعية + ذاكرة حركة فارغة. المخرجات: مقطع مدته 5 ثوانٍ. استخراج ذاكرة الحركة: الكامنة (latent) لآخر 4 إطارات. المقطع 2: المدخلات: صورة مرجعية + ذاكرة الحركة من المقطع 1. المخرجات: مقطع مدته 5 ثوانٍ. استخراج ذاكرة الحركة من نهايته. ... كرر العملية لـ N مقطعاً، ثم ادمج المقطع 1 + المقطع 2 + ... + المقطع N في الفيديو الطويل.
الجانب الجميل هنا هو عدم الحاجة لتعديل انتباه DiT. يتم دمج السياق التاريخي على مستوى المدخلات كمتجهات كامنة (latents)، ويقوم LoRA صغير بتعليم النموذج كيفية استخدام هذا البادئة فعلياً.
المرجع الكامن (Anchor latent): صورة مرجعية يقدمها المستخدم، يتم تشفيرها بواسطة VAE ← تحافظ على اتساق مظهر الشخصية/الموضوع عالمياً. كامنة الحركة (Motion latent): الكامنة لآخر 4 / 8 / 12 إطاراً من المقطع السابق ← تخبر النموذج كيف انتهى المقطع الأخير. الحشو (Padding): يضبط شكل المدخلات بحيث يرى DiT تسلسلاً واحداً مرتباً: مرجع + حركة + حشو.
الضبط الدقيق عبر إعادة تدوير الأخطاء (Error-Recycling)
التفصيل الذي يجعل SVI متماسكة عبر مقاطع عديدة هو كيفية تدريب LoRA الخاص بها. يبدأ الاستنتاج القياسي دائماً في إزالة الضوضاء من ضوضاء غاوسية صافية، ولكن في ربط الفيديوهات الطويلة، تلوث الأخطاء من المقاطع السابقة سياق التهيئة للمقاطع اللاحقة. إذا قمت بالتدريب فقط على مدخلات مرجعية نظيفة، فأنت ترسخ فجوة التدريب-الاستنتاج.
التدريب القياسي: المدخلات المرجعية لكل مقطع هي "حقيقة أرضية" نظيفة ← لا يرى النموذج أبداً نوع السياق التاريخي المشوش الذي يواجهه فعلياً عند الاستنتاج، مما يؤدي لتراكم الانقطاعات.
إعادة تدوير الأخطاء: أثناء التدريب، يتم حقن أخطاء النموذج السابقة عمداً في المدخلات المرجعية، ليتعلم LoRA صراحةً كيفية العمل على سياق تاريخي مشوش. تنخفض الانقطاعات البصرية عند حدود المقاطع بشكل حاد.
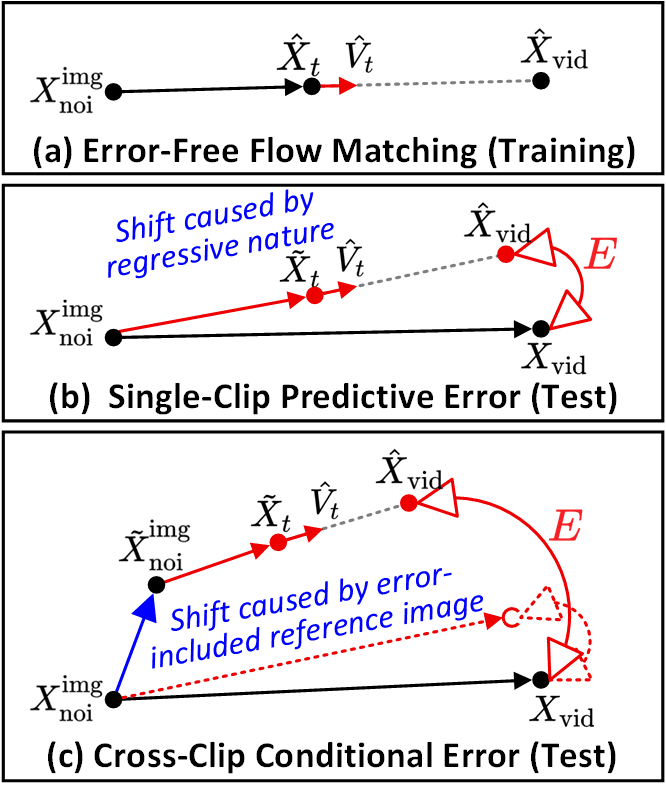
تحدد SVI نوعين أساسيين من الأخطاء: (أ) مطابقة التدفق الخالية من الأخطاء (مسار وقت التدريب). (ب) خطأ التنبؤ لكل مقطع (الانحراف بين مسار إزالة الضوضاء والمسار المثالي). (ج) الخطأ الشرطي عبر المقاطع (الانحراف المتسلسل الناتج عن صور مرجعية ملوثة بالأخطاء). تقوم ميزة إعادة تدوير الأخطاء بحقن كليهما.
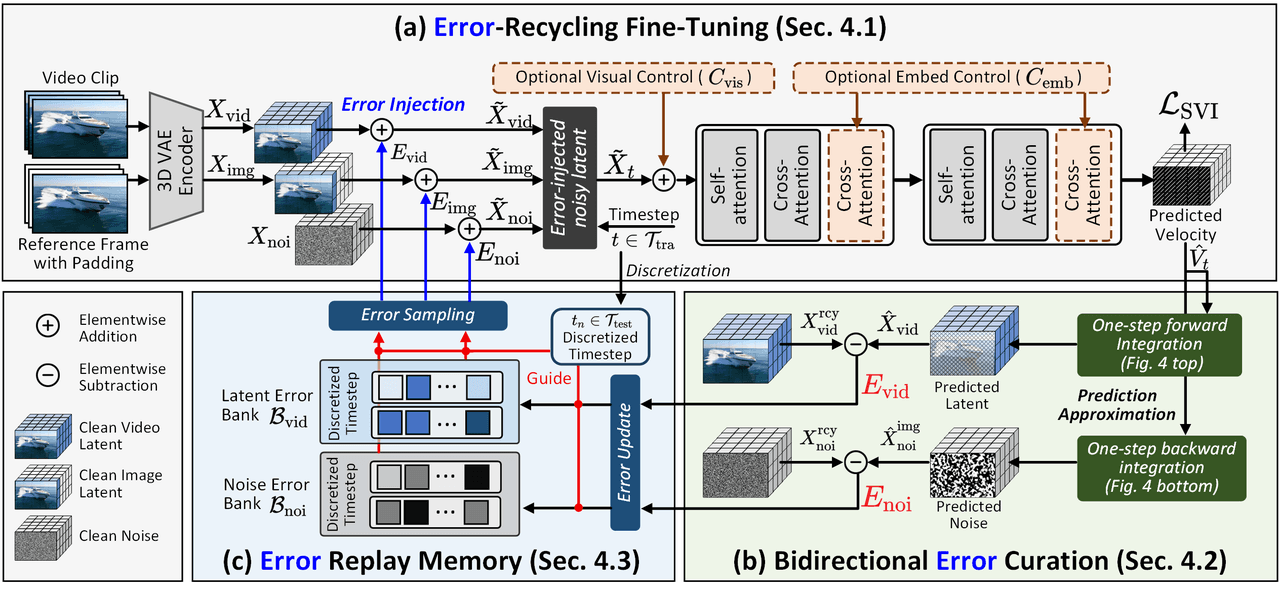
إطار عمل تدريب SVI: (أ) حقن الأخطاء المولدة ذاتياً في مساحة الكامنة. (ب) حساب الأخطاء ثنائية الاتجاه بكفاءة. (ج) تخزين الأخطاء في ذاكرة إعادة تشغيل (Replay Memory) لتعزيز دورة الإشراف المغلقة.
إصدارات LoRA
توفر SVI ثلاثة إصدارات: SVI-Shot للصور الثابتة إلى مقاطع قصيرة، و_SVI-Dance_ لحركة الإنسان (يمكنها أيضاً قبول تسلسل حركي)، و_SVI-Film_ للفيديوهات الطويلة متعددة اللقطات. المعاملات الفائقة: 81 إطاراً لكل مقطع، عدد إطارات الحركة ∈ {4, 8, 12}، ورتبة LoRA عادة ما تكون 16–64.
التكديس على TurboWan
نقوم بتركيب SVI LoRA فوق TurboWan (نسخة أسرع من Wan محسنة بواسطة Atlas)، ونحتفظ بـ LoRA المخصص في المكدس للتحكم في الأسلوب. عند الاستنتاج، يتم دمج أوزان LoRA متعددة في آن واحد.
القاعدة: TurboWan. LoRA 1: مخصص للتحكم في المحتوى/الأسلوب. LoRA 2: SVI لضمان اتساق الفيديو الطويل. النتيجة: سرعة TurboWan + استمرارية SVI + أسلوب Spicy، كل ذلك في تمريرة استنتاج واحدة.
أرقام الإنتاج
اختبار قياسي: صورة مرجعية واحدة و3 مطالبات، لتوليد مخرجات بطول ~15 ثانية (3 مقاطع × 5 ثوانٍ):
| المقياس | القيمة |
|---|---|
| المدة المولدة | 15 ثانية (3 مقاطع) |
| زمن الاستنتاج لكل مقطع | ~14 ثانية (TurboWan fp8، وحدة معالجة رسومية واحدة) |
| إجمالي زمن الاستنتاج | ~42 ثانية |
| اتساق الموضوع | جيد |
مثال عملي: مغامرة القطة
لتوضيح السلوك عبر المقاطع، قمنا بتنفيذ حالة بطول 15 ثانية بمرجع واحد وثلاث لقطات. حدد مطالِب الأسلوب مظهراً مشابهاً لأفلام بيكسار مع إضاءة دافئة؛ الشخصية كانت قطة برتقالية بعيون فضولية؛ انتقلت اللقطات الثلاث من حافة النافذة، إلى الرصيف، إلى لقاء كلب مسترد ذهبي.

المقطع 1 (0–5 ث): القطة البرتقالية على حافة نافذة، مع ابتعاد الكاميرا ببطء. الأسلوب والشخصية ثابتان.

المقطع 2 (5–10 ث) عند حدود الانتقال: مظهر القطة يطابق المقطع 1، ثم تغير وضعيتها عند القفز. نقلت كامنة الحركة حالة الحركة عبر الحدود.

المقطع 3 (10–15 ث): ظهور كلب مسترد ذهبي وانتقال المشهد نحو الداخل/الخارج. أسلوب بيكسار للقطة يظل ثابتاً عبر المقاطع الثلاثة.
المقاييس الإجمالية:
| المقياس | القيمة |
|---|---|
| إجمالي المدة | 15 ثانية (3 مقاطع × 5 ثوانٍ) |
| إجمالي الإطارات | 240 إطاراً (16 إطاراً في الثانية) |
| إجمالي زمن الاستنتاج | 33 ثانية (TurboWan، وحدة معالجة رسومية واحدة) |
| نسبة الوقت للفيديو | 2.2 ثانية/ثانية |
| اتساق الموضوع | القطة البرتقالية مستقرة طوال الوقت |
| انقطاع حدود المقاطع | لا توجد قصات قفز واضحة |
هذا يعني توليد فيديو بطول 15 ثانية في 33 ثانية على وحدة معالجة رسومية واحدة، مع اتساق ممتاز للموضوع — ضمن هدفنا البالغ 60 ثانية.
الملاحظة الصادقة هي أن توليد الفيديو يعتمد على مثلث من السرعة، الطول، والجودة. لا يوجد أسلوب واحد يتفوق في الثلاثة معاً اليوم. يكمن العمل المثير في اختيار التنازل الذي يقلل الضرر، بالنظر إلى الأجهزة الحالية وميزانيتك. تقدم SVI تنازلاً طفيفاً في الطول وجودة الحدود — وفي المقابل، نحصل على فيديو طويل بدقة تقارن بنماذج Wan2.2، على وحدة معالجة رسومية واحدة، اليوم.






