OpenAI LLM Models
OpenAI’s premier GPT model family leads the industry, highlighted by the GPT OSS 120B which achieves near-parity with OpenAI o4-mini on core reasoning benchmarks while running efficiently on a single 80GB GPU. Perfectly optimized for vibecoding and complex logic operations, this model balances top-tier intelligence with hardware accessibility for modern developers and AI-driven web development.
نماذج قيد الإطلاق
نضع اللمسات الأخيرة على هذه المجموعة — يمكنك استكشاف المجموعات المماثلة أدناه في غضون ذلك.
استكشف المزيد من العائلات
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
ما الذي يميز OpenAI LLM Models
توفر لك Atlas Cloud أحدث النماذج الإبداعية الرائدة في الصناعة.

Frontier Research
Cutting-edge models that set global benchmarks in reasoning, multimodality, and AI safety.

Cost-Efficient Performance
Optimized families like GPT-4.1 mini and GPT-5 nano balance accuracy, speed, and cost.

Developer Ecosystem
APIs powering millions of daily requests across diverse platforms and industries.

Flexible Model Sizes
Choice of flagship, mini, and nano models for every workload and budget.

Enterprise Reliability
SLAs, monitoring, and compliance-ready logging trusted by Fortune 500 companies.

Open Model Options
Access to open-source models (gpt-oss-20b, gpt-oss-120b) for transparency and customization.
السرعة القصوى
أقل تكلفة
| نموذج | الوصف |
|---|---|
| GPT OSS 120B | يُعد GPT OSS 120B نموذجًا لغويًا كبيرًا (LLM) عالي الأداء يركز على الاستدلال، ويدمج بنية محسنة مع قدرات قوية لمعالجة سياق بحجم 131.07K؛ محققًا تكافؤًا شبه كامل مع OpenAI o4-mini على وحدة معالجة رسومات (GPU) واحدة بسعة 80 جيجابايت، وهو يعمل كمحرك للتطوير التكراري السريع، بما في ذلك vibecoding وتنفيذ سير العمل المعقد القائم على المنطق. |
ميزات جديدة لـ OpenAI LLM Models + عرض
يوفر الجمع بين النماذج المتقدمة ومنصة Atlas Cloud المسرّعة بوحدات GPU سرعة وقابلية توسع وتحكمًا إبداعيًا لا مثيل لهما في إنشاء الصور والفيديو.
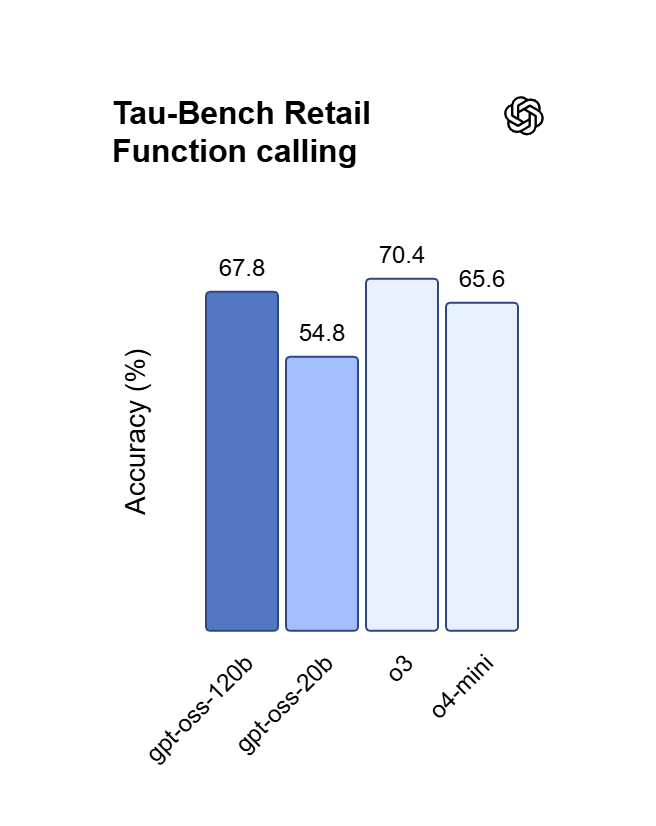
الامتثال الدقيق للتعليمات عبر GPT OSS 120B
يُظهر GPT OSS 120B قابلية توجيه استثنائية، حيث يلتزم بصرامة بمطالبات النظام المعقدة (system prompts) لضمان موثوقية مطلقة للمخرجات. ومن خلال الاستفادة من بنية المحاذاة الدقيقة الخاصة به، يمكن للمستخدمين فرض تنسيقات وقيود وفروق أسلوبية محددة مع انعدام انحراف الأحرف (zero character drift). إنه الخيار الأمثل للوكلاء المستقلين، واستخراج البيانات الهيكلية، وبيئات الإنتاج ذات المهام الحرجة.
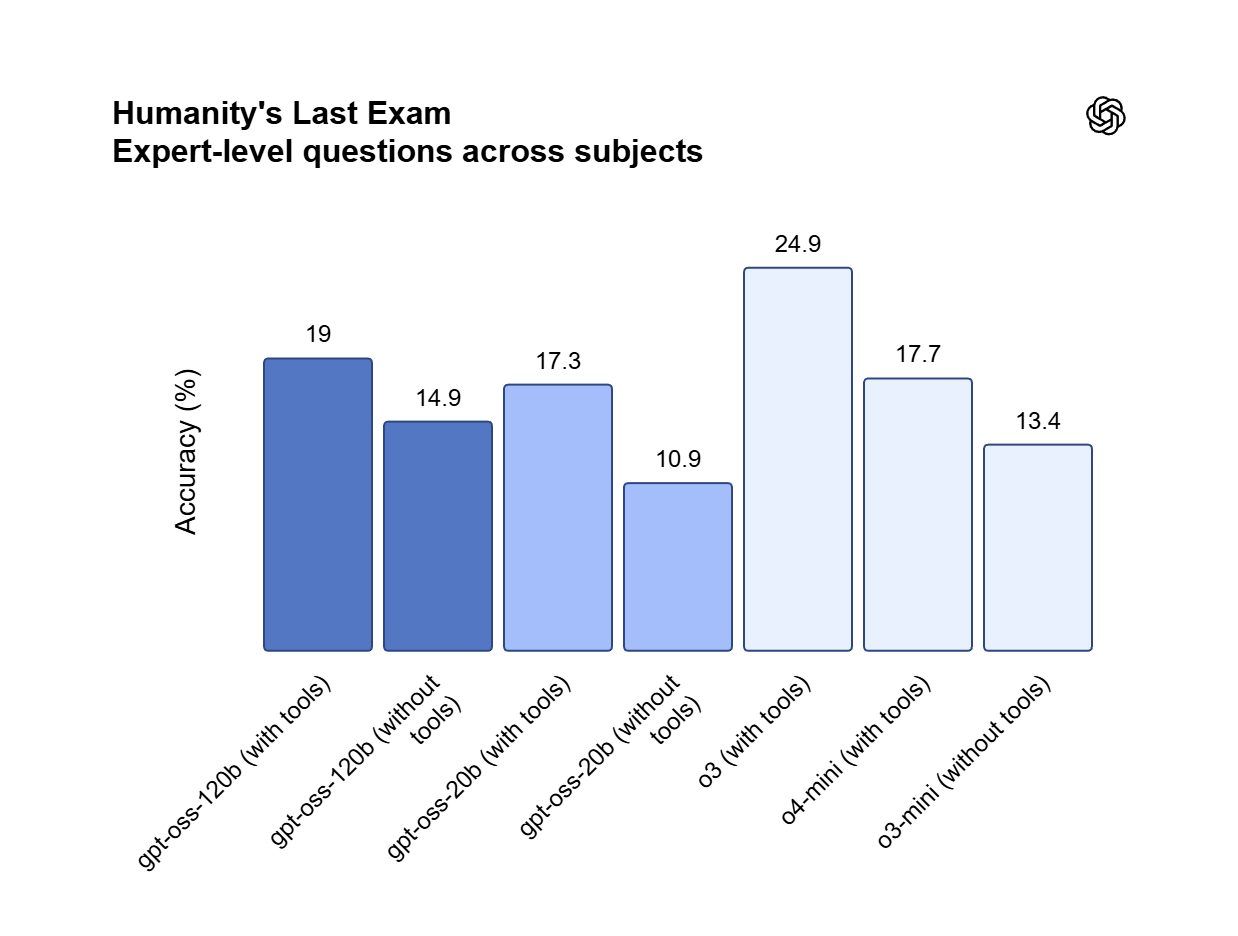
السيادة التجارية بموجب ترخيص Apache 2.0
يتم توزيع GPT OSS 120B بموجب ترخيص Apache 2.0، مما يسمح بالاستخدام التجاري غير المقيد والضبط الدقيق (fine-tuning) الخاص دون رسوم لكل رمز (token). على عكس واجهات برمجة التطبيقات (APIs) مغلقة المصدر، فإنه يسمح بالاستضافة المحلية على وحدة معالجة رسومات (GPU) واحدة بسعة 80 جيجابايت للحفاظ على البيانات الملكية الحساسة بالكامل داخل المؤسسة (on-premises). يوفر هذا الإطار الحرية القانونية والتقنية لبناء وتعديل وتوسيع مكدسات البرمجيات التي تعمل بالذكاء الاصطناعي.
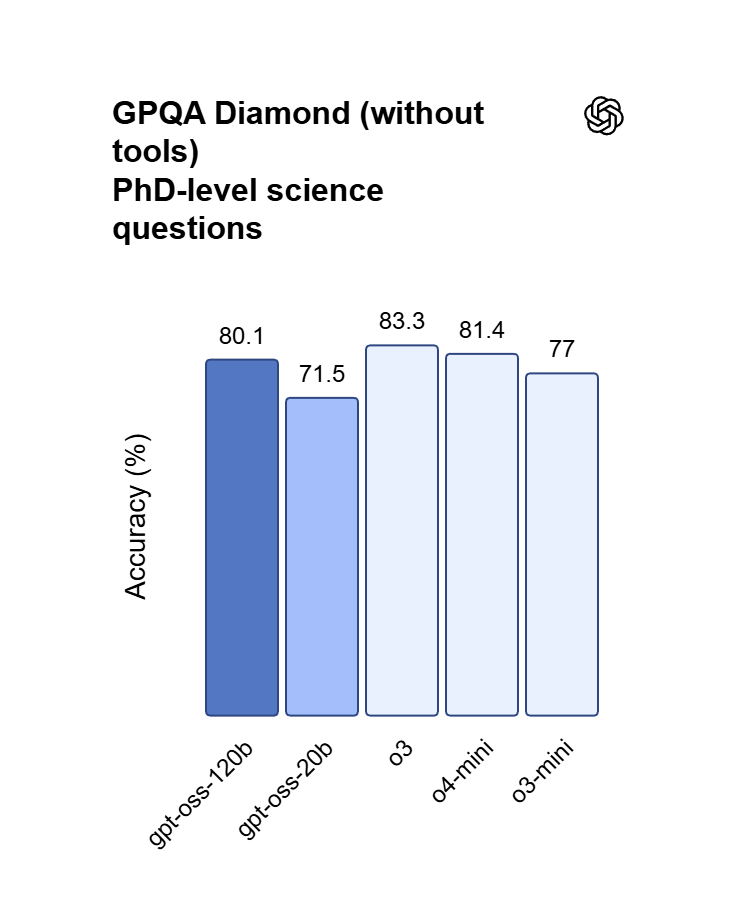
منطق عالي الكفاءة وVibecoding باستخدام GPT OSS 120B
محققاً تكافؤاً شبه كامل مع OpenAI o4-mini، يتفوق هذا النموذج الذي يبلغ حجمه 120 مليار عامل متغير (parameter) في التعامل مع تركيب التعليمات البرمجية المعقدة والإثباتات الرياضية. يمكن للمطورين الاستفادة من محرك الاستدلال الخاص به من أجل "vibe coding"—وهو ترجمة أفكار اللغة الطبيعية مباشرة إلى تطبيقات ويب وظيفية من خلال التلقين المتكرر. إنه حل عالي السرعة لتصحيح أخطاء المنطق المتداخل وتنظيم سير عمل جدولة المهام المتطورة.
ما يمكنك فعله مع OpenAI LLM Models
اكتشف حالات الاستخدام العملية وسير العمل التي يمكنك بناؤها مع عائلة النماذج هذه — من إنشاء المحتوى والأتمتة إلى التطبيقات على مستوى الإنتاج.
تصحيح أخطاء المنطق العميق والنمذجة الأولية باستخدام GPT OSS 120B
يُمكّن GPT OSS 120B المهندسين من حل تحديات "vibecoding" من خلال ترجمة الأفكار المعمارية عالية المستوى إلى مكونات Python أو React جاهزة للإنتاج. يتعامل محرك الاستدلال الخاص به مع التبعيات المتداخلة والحالات الحدية التي غالبًا ما تُعقّد النماذج المصغرة، مما يضمن بقاء تركيب الكود متعدد الخطوات فعالاً. وبفضل دعمه للإثباتات الخوارزمية وجدولة المهام المعقدة، يُعد الأداة المثالية لبناء المنتجات التقنية ذات الحد الأدنى من القيمة (MVPs)، ونصوص ضمان الجودة (QA) المؤتمتة، وتطبيقات الويب كثيفة البيانات.
أدوات مملوكة غير متصلة بالإنترنت باستخدام GPT OSS 120B
بموجب ترخيص Apache 2.0، يمكن للفرق استضافة GPT OSS 120B على وحدة معالجة رسومات (GPU) واحدة بسعة 80 جيجابايت لمعالجة البيانات الداخلية الحساسة دون مخاطر التسرب السحابي. يتيح هذا الإعداد إجراء ضبط دقيق (fine-tuning) محلي دائم على قواعد التعليمات البرمجية الداخلية المتخصصة أو السجلات الطبية دون تكاليف API المتكررة لكل رمز (token). يعتبر هذا النموذج مثالياً للأدوات الداخلية عالية الأمان ومساعدة الذكاء الاصطناعي دون اتصال بالإنترنت، حيث يوفر سيادة كاملة على الأوزان — مما يدعم أنظمة RAG الخاصة وحزم البرامج المملوكة المخصصة.
استخراج بيانات بمخطط مثالي باستخدام GPT OSS 120B
يُمكّن GPT OSS 120B المطورين من تحويل المستندات غير المنظمة والفوضوية إلى تنسيقات JSON أو Markdown منسقة بصرامة دون حدوث "انحراف في التعليمات". من خلال تثبيت نافذة السياق البالغة 131.07K بقواعد نظام صارمة، يضمن النموذج عدم اختلاق الحقول (الهلوسة) أو تخطيها أثناء المعالجة الطويلة. إنه مثالي لأتمتة CRM ووضع علامات المحتوى الآلي، حيث يحافظ على حواجز حماية منطقية عبر مجموعات البيانات الضخمة، مما يدعم عمليات تكامل API الموثوقة وتعبئة قواعد البيانات.
مقارنة النماذج
شاهد كيف تتقارن نماذج مختلف المزودين — قارن الأداء والأسعار ونقاط القوة الفريدة لاتخاذ قرار مدروس.
| نموذج | سياق | الحد الأقصى للمخرجات | إدخال | التموضع |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | نص | LLM عالي الكفاءة في الاستدلال |
| GLM-5 | 202.75K | 202.75K | نص | نموذج تأسيسي رائد |
| DeepSeek V3.2 | 163.84K | 163.84K | نص | عام رائد |
| MiniMax-M2.5 | 204.8K | 196.6K | نص | برمجة قائمة على الوكلاء متطورة (SOTA) |
How to Use OpenAI LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
لماذا تستخدم OpenAI LLM Models على Atlas Cloud
دمج نماذج OpenAI LLM Models المتقدمة مع منصة Atlas Cloud المسرّعة بـ GPU يوفر أداءً لا مثيل له وقابلية للتوسع وتجربة مطور استثنائية.
الأداء والمرونة
زمن انتقال منخفض:
استدلال محسّن لـ GPU للاستجابة في الوقت الفعلي.
API موحد:
قم بتشغيل OpenAI LLM Models و GPT و Gemini و DeepSeek من خلال تكامل واحد.
تسعير شفاف:
فواتير يمكن التنبؤ بها لكل رمز مع خيارات بدون خادم.
المؤسسات والتوسع
تجربة المطور:
SDKs والتحليلات وأدوات الضبط الدقيق والقوالب.
الموثوقية:
وقت تشغيل 99.99%، RBAC، وتسجيل جاهز للامتثال.
الأمان والامتثال:
SOC 2 Type II، توافق HIPAA، سيادة البيانات في الولايات المتحدة.
الأسئلة الشائعة حول OpenAI LLM Models
إنه يحقق تكافؤًا شبه كامل مع OpenAI o4-mini في معايير الاستدلال الأساسي والرياضيات. وبينما يُعد o4-mini واجهة برمجة تطبيقات مغلقة (closed API)، يقدم OSS 120B عمقًا منطقيًا مشابهًا مع ميزة إضافية تتمثل في الوصول الكامل إلى أوزان النموذج.
تم تحسين النموذج ليعمل على وحدة معالجة رسومات (GPU) واحدة بسعة 80 جيجابايت، مما يجنب تعقيدات العقد المتعددة. ومع ذلك، وللحصول على قابلية توسع فورية وصيانة معدومة، نوصي بالوصول إليه عبر API على Atlas Cloud.
نعم. تم إصداره بموجب ترخيص Apache 2.0، الذي يسمح بالاستخدام التجاري والتعديل والتوزيع غير المقيد دون رسوم ترخيص لكل رمز (per-token) أو التقيد بمورد معين (vendor lock-in).
صُممت نافذة السياق بسعة 131.07K لتحقيق دقة استرجاع تضاهي "البحث عن إبرة في كومة قش". يمكنها استيعاب أدلة المشاريع بأكملها أو الكتيبات الفنية التي تزيد عن 100 صفحة مع الحفاظ على الاتساق المنطقي عبر المدخلات بالكامل.
بشكل فائق. تم ضبط محرك الاستدلال الخاص به بدقة من أجل التوليف التكراري للأكواد البرمجية. فهو يتعامل مع مكونات React المتداخلة وخلفيات Python المعقدة بموثوقية أكبر من نماذج فئة 70B القياسية، مما يجعله مثالياً لسير العمل الذي يحول اللغة الطبيعية إلى تطبيقات.


