Ihr Prompt ist auf eine Weigerung gestoßen. Nicht, weil er schädlich war, sondern weil ein Schlüsselwort einen Filter ausgelöst hat.
Entwickler in der Ollama-Community bezeichnen dies als „Refusal Vectors“ (Verweigerungs-Vektoren): durch Schlüsselwörter ausgelöste Sperren, die nichts mit tatsächlichem Schaden zu tun haben. Reverse Engineering von Malware für die Sicherheitsforschung, Dokumentation medizinischer Fallstudien, Erstellung von Inhalten für Erwachsene, Schreiben von Dark Fiction. Mainstream-KI blockiert all dies. Diese Liste führt die besten unzensierten KI-Modelle 2026 auf Basis echter Community-Daten auf, nicht auf Basis von Marketingtexten. Sie deckt drei Kategorien ab: unzensierte LLM-Modelle für Text und Code, die besten unzensierten lokalen KI-Modelle 2026 für den Einsatz auf privater Hardware sowie unzensierte KI-Modelle 2026 für die Bild- und Videogenerierung per API. Jede Zahl ist belegt und auf den Stand Mai 2026 datiert.
Für eine Einführung in die breitere Tool-Landschaft finden Leser, die neu in diesem Bereich sind, den Leitfaden für unzensierte KI-Bildgeneratoren als nützlichen Ausgangspunkt, bevor sie ein spezifisches Modell auswählen.
So haben wir die besten unzensierten KI-Modelle 2026 bewertet
Im Jahr 2026 bieten die Download-Zahlen der Community von Ollama ein zuverlässigeres Ranking-Signal als Benchmark-Ergebnisse, die eher für Pressemitteilungen als für die reale Leistung ausgewählt werden (Ollama, Suche nach unzensierten Modellen, 2026). Millionen von Pulls repräsentieren Tausende von Hardware-Setups und Prompt-Typen. Das ist schwerer zu manipulieren als ein kuratiertes Eval-Set.
In diesem Artikel werden drei Ranking-Signale verwendet. Für unzensierte Ollama-Modelle ist das primäre Signal die Pull-Anzahl von ollama.com, abgerufen im Mai 2026. Für OpenRouter-Modelle erfolgt das Ranking nach Parameteranzahl und Kontextfenster, da Pull-Zahlen auf dieser Plattform nicht öffentlich verfügbar sind. Bei Bild- und Videomodellen erfolgt das Ranking nach dem Preis pro Output, wobei niedrigere Kosten innerhalb jeder Gruppe zuerst aufgeführt werden.
Die meisten unzensierten KI-Modelle 2026 fallen in zwei technische Kategorien: feinabgestimmt (fine-tuned) und ablatiert (abliterated). Feinabgestimmte Modelle wie die Dolphin-Serie werden mit Datensätzen trainiert, die kein Verweigerungsverhalten verstärken. Bei ablatierten Modellen wurden die Verweigerungsgewichte chirurgisch entfernt. Die Community stellt konsistent fest, dass feinabgestimmte Modelle bei diversen Prompt-Typen stabiler sind.
In der Praxis korrelieren Download-Zahlen auch mit der Modellstabilität. Ein Modell, das über 1 Million Pulls erreicht, wurde über eine breite Palette von Hardware-Konfigurationen getestet, wodurch Fehler und Instabilitäten aufgedeckt wurden, die kleineren Testgruppen völlig entgangen wären.
Was sind die 5 am häufigsten heruntergeladenen unzensierten Ollama-Modelle?
Im Jahr 2026 kommen die fünf am häufigsten heruntergeladenen unzensierten Ollama-Modelle zusammen auf über 9,2 Mio. Pulls, wobei llama2-uncensored mit 2,6 Mio. anführt (Ollama, Suche nach unzensierten Modellen, 2026). Dies sind die besten unzensierten Ollama-Modelle 2026 nach Community-Validierung, nicht nach irgendeinem Benchmark. Hardware ist der primäre Filter, den die meisten Nutzer zuerst anwenden: Die VRAM-Anforderungen reichen in dieser Gruppe von unter 4 GB bis 40 GB.
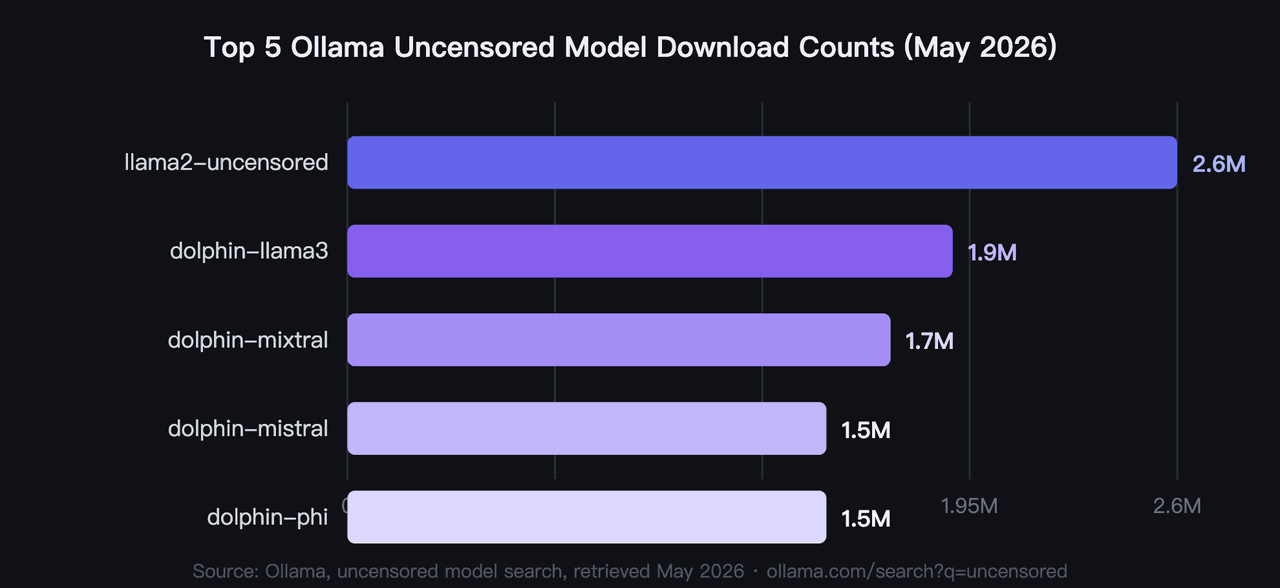
1. llama2-uncensored: Das meist heruntergeladene unzensierte KI-Modell auf Ollama
Der ursprüngliche Community-Maßstab für unzensierte lokale KI. George Sung und Jarrad Hope veröffentlichten dieses Fine-Tune, um das Verweigerungsverhalten von Llama 2 zu entfernen, ohne die allgemeine Leistungsfähigkeit zu beeinträchtigen. Es ist das Modell, mit dem die meisten Entwickler beginnen, und seine 2,6 Mio. Pulls spiegeln über zwei Jahre realen Einsatz wider. Kein anderes unzensiertes LLM hat dieses Download-Volumen erreicht.
- Parameter: 7B oder 70B
- VRAM: ~6 GB (7B); ~40 GB (70B)
- Am besten geeignet für: Allzweck-Chat ohne Einschränkungen und Inhaltserstellung
- Plattform: Ollama
2. dolphin-llama3: Bestes unzensiertes Llama 3 LLM-Modell für Agenten-Workflows
Eric Hartfords Dolphin auf einer Llama 3-Basis ist das am häufigsten heruntergeladene unzensierte Modell, das auf einer modernen Architektur basiert, mit 1,9 Mio. Pulls (Ollama, dolphin-llama3 Modellseite, 2026). Es unterstützt Funktionsaufrufe (Function Calling) und ein Kontextfenster, das je nach Konfiguration von 8K auf 256K Token erweitert werden kann. Die 8B-Version ist 4,7 GB groß und passt auf die meisten Consumer-GPUs der Mittelklasse.
- Parameter: 8B oder 70B
- VRAM: ~5 GB (8B); ~40 GB (70B)
- Am besten geeignet für: Programmierung, Agenten-Workflows und Funktionsaufrufe
- Plattform: Ollama
3. dolphin-mixtral 8x7B: Unzensiertes MoE-KI-Modell für komplexes Schlussfolgern
Eine Mixture-of-Experts-Architektur leitet jedes Token durch eine Teilmenge ihrer 8 Experten-Layer. Dies erzeugt eine Qualität beim Schlussfolgern, die fast der von 70B-Modellen entspricht, bei geringeren Inferenzkosten als ein dichtes Modell mit äquivalenter Gesamtparameterzahl. Eric Hartfords unzensiertes Fine-Tune behält einen starken Schwerpunkt auf Programmierung bei.
- Parameter: 8x7B (aktive Parameter pro Inferenzdurchgang sind weit geringer als die Gesamtzahl)
- VRAM: ~12-16 GB mit Quantisierung
- Am besten geeignet für: Komplexe Programmieraufgaben, technisches Schlussfolgern und längere Anweisungsketten
- Plattform: Ollama
4. dolphin-mistral: Unzensiertes 7B lokales KI-Modell für schnelle Antworten
Leichter und schneller als dolphin-mixtral auf CPU-beschränkter Hardware. Es verzeichnet 1,5 Mio. Pulls von Entwicklern, die ein reaktionsschnelles lokales Modell für die Code-Vervollständigung ohne High-End-GPU suchen. Die Mistral-Basisarchitektur verleiht ihm ein starkes Verhältnis von Leistung zu Größe für ein 7B-Modell.
- Parameter: 7B
- VRAM: ~5-6 GB
- Am besten geeignet für: Leichte Programmierhilfe und schnelle Chat-Antworten
- Plattform: Ollama
5. dolphin-phi 2.7B: Leichtestes unzensiertes lokales KI-Modell
Die Phi-Basisarchitektur von Microsoft packt fähiges Schlussfolgern in eine Parameterzahl von 2,7B. Eric Hartfords unzensiertes Fine-Tune bewahrt diese Effizienz. Mit weniger als 4 GB VRAM läuft es auf den meisten Consumer-Laptops mit diskreter GPU und ist damit der zugängliche Einstiegspunkt für die besten unzensierten lokalen KI-Modelle 2026.
- Parameter: 2,7B
- VRAM: Unter 4 GB
- Am besten geeignet für: Laptop-Einsatz, schnelles Testen und hardwarebeschränkte Umgebungen
- Plattform: Ollama
Beste unzensierte LLM-Modelle 6-10: Programmierung, Rollenspiel und langer Kontext
Im Jahr 2026 belegt die Dolphin-Serie 5 der Top-10-Plätze im unzensierten Katalog von Ollama nach Download-Anzahl – eine Konzentration, die Eric Hartfords konsistente Fine-Tuning-Methodik widerspiegelt, die auf verschiedene Basisarchitekturen angewendet wird (Ollama, hermes3 Modellseite, 2026). Die Modelle 6 bis 10 decken Rollenspiele, allgemeine Konversation, Entwicklertools, Anweisungsbefolgung und erweiterten Kontext ab: die Anwendungsfälle, bei denen die Weigerungen von Mainstream-KI am störendsten sind.
6. hermes3: Unzensiertes KI-Modell für Rollenspiele und Agenten-Aufgaben
Nous Research hat hermes3 für Rollenspiel-Tiefe und strukturierte Tool-Nutzung entwickelt. Es ist in vier Größen von 3B bis 405B erhältlich, der breiteste Größenbereich aller Modelle in dieser Liste. Mit 1,3 Mio. Pulls liegt die 8B-Variante an einem praktischen Punkt für kreatives Schreiben und Workflows zur Planung von Agenten-Aufgaben (Ollama, hermes3 Modellseite, 2026).
- Parameter: 3B, 8B, 70B oder 405B
- VRAM: ~2 GB (3B); ~5 GB (8B); ~40 GB (70B)
- Am besten geeignet für: Rollenspiel, kreative Fiktion und Planung von Agenten-Aufgaben
- Plattform: Ollama
7. wizard-vicuna-uncensored: Unzensiertes Multi-Größen-KI-Modell für den allgemeinen Gebrauch
Ein älteres, aber bewährtes Modell auf Basis von Llama 2, erhältlich in drei Größen bis zu 30B. Seine 1,2 Mio. Pulls stammen von Benutzern, die eine zuverlässige unzensierte Option mit einem breiteren Parameterbereich wünschen. Es erreicht zwar nicht die Möglichkeiten des Kontextfensters von dolphin-llama3, bewältigt aber allgemeine Konversation und kreative Inhalte konsistent.
- Parameter: 7B, 13B oder 30B
- VRAM: ~5 GB (7B); ~9 GB (13B); ~20 GB (30B)
- Am besten geeignet für: Allgemeine Konversation und kreative Inhalte mit mehreren Größenoptionen
- Plattform: Ollama
8. dolphincoder: Unzensiertes KI-Programmiermodell auf StarCoder2-Basis
StarCoder2 als Basis macht dolphincoder zu einem echten Spezialisten. Während andere Dolphin-Modelle Generalisten mit unzensiertem Fine-Tuning sind, zielt dieses speziell auf die Softwareentwicklung ab. Seine 943K Pulls stammen fast ausschließlich von Entwicklern, nicht von kreativen Nutzern. Die 15B-Variante verarbeitet größere Codebasen als die 7B-Version.
- Parameter: 7B oder 15B
- VRAM: ~5 GB (7B); ~10 GB (15B)
- Am besten geeignet für: Code-Generierung, Debugging und technische Dokumentation
- Plattform: Ollama
9. wizardlm-uncensored: Unzensiertes LLM für Anweisungsbefolgung in Forschungs-Workflows
Ein 13B-Modell zur Anweisungsbefolgung mit 610K Pulls. Seine Stärke ist das Befolgen komplexer, mehrstufiger Anweisungen ohne Ausflüchte oder die Verweigerung von Teilaufgaben. In Forschungs-Workflows, in denen eine einzige Verweigerung eine lange Kette unterbricht, hat diese Zuverlässigkeit einen direkten Produktivitätswert. Es verfügt nicht über die moderne Basisarchitektur von dolphin-llama3, erledigt die Anweisungsaufgabe jedoch konsistent.
- Parameter: 13B
- VRAM: ~9 GB
- Am besten geeignet für: Komplexe mehrstufige Anweisungsketten und Forschungs-Workflows
- Plattform: Ollama
10. everythinglm: Unzensiertes LLM mit 16K Kontextfenster
Das herausragende Merkmal hier ist das 16K-Kontextfenster auf einer Llama 2-Basis. Die meisten 7B-Modelle erreichen maximal 4K oder 8K Token. Dieser zusätzliche Kontext ermöglicht es everythinglm, vollständige Codebasen, lange Dokumente oder erweiterte Konversationsverläufe ohne Kürzung zu verarbeiten. Seine 536K Pulls sind nach den Maßstäben dieser Liste bescheiden, aber es füllt eine Lücke, die kein anderes Modell hier in dieser Größe abdeckt.
- Parameter: 13B
- VRAM: ~9 GB
- Am besten geeignet für: Analyse langer Dokumente, Chat mit erweitertem Kontext und Überprüfung vollständiger Codebasen
- Plattform: Ollama
Die Dominanz der Dolphin-Serie bei den Ollama-Downloads spiegelt ein Muster wider, das die Community dokumentiert hat: Feinabgestimmte unzensierte Modelle von einem einzigen Autor mit einer konsistenten Methodik übertreffen einmalige Ablierungsversuche. Ablierung entfernt Verweigerungsgewichte aus einem einzelnen Modell. Fine-Tuning baut stabiles unzensiertes Verhalten über diverse Prompt-Typen hinweg auf. Diese Konsistenz ist der Grund, warum 5 der Top-10-Plätze der Arbeit von Eric Hartford gehören, nicht irgendeiner einzelnen Basisarchitektur.
Wie richtet man unzensierte Ollama-Modelle lokal ein?
Im Jahr 2026 installieren drei Befehle jedes Ollama-Modell auf Mac, Linux oder Windows: Ollama von ollama.com installieren, ollama pull [Modellname] ausführen, dann ollama run [Modellname] (Ollama-Dokumentation, 2026). Kein API-Schlüssel erforderlich. Es findet keine externe Inhaltsmoderation statt. Ihr Prompt verlässt niemals Ihre Hardware.
Als konkretes Beispiel für dolphin-llama3: ollama pull dolphin-llama3 lädt die 4,7 GB große 8B-Datei herunter. ollama run dolphin-llama3 öffnet einen interaktiven Prompt. Der gesamte Inferenzprozess läuft auf Ihrer lokalen GPU oder CPU.
LM Studio bietet eine Desktop-GUI für Benutzer, die nicht im Terminal arbeiten möchten. Es verwendet dieselben GGUF-Modelldateien wie Ollama, mit einer visuellen Oberfläche für die Modellauswahl und Parameteranpassung. llama.cpp ist die zugrunde liegende Inferenz-Engine beider Tools und unterstützt die direkte Verwendung über die Befehlszeile, wenn Sie mehr Kontrolle über Quantisierungsstufen und Kontextlängeneinstellungen benötigen.
Entwickler, die spezifische Hardwareanforderungen und Quantisierungseinstellungen für den Betrieb der besten unzensierten lokalen KI-Modelle 2026 auf Consumer-GPUs suchen, finden im vollständigen Leitfaden zur lokalen Einrichtung detaillierte Informationen zu Mindestkonfigurationen des VRAM und häufigen Einrichtungsfehlern.
Welche unzensierten OpenRouter-Modelle sind ohne lokale GPU verfügbar?
Im Jahr 2026 hostet OpenRouter unzensierte LLMs per API, wodurch die GPU-Anforderung komplett entfällt. Das Modell venice/uncensored ist als Modell der kostenlosen Stufe für 0 USD pro Million Input- und Output-Token verfügbar (OpenRouter, venice/uncensored Modellseite, 2026). Dies macht unzensierte OpenRouter-Modelle zum praktischen Einstiegspunkt für Benutzer ohne dedizierte Hardware.
Der Kompromiss ist einfach: OpenRouter leitet Ihren Prompt durch seine Infrastruktur, daher ist die Konversation nicht in der Weise privat, wie es bei einem lokalen Modell der Fall ist. Lokale Ollama-Modelle behalten alles auf Ihrem Gerät. Kein Ansatz ist universell besser. Die richtige Wahl hängt von Ihrem Bedrohungsmodell und der verfügbaren Hardware ab.
11. venice/uncensored: Kostenloses unzensiertes OpenRouter-Modell
Das Venice Uncensored-Modell im kostenlosen Tarif von OpenRouter. Eine 24B Mistral-Small-Basis, feinabgestimmt für unzensierten Output von Cognitive Computations in Zusammenarbeit mit Venice.ai. 32K Kontextfenster, 0 USD pro Million Token. Der kostenlose Tarif von OpenRouter wendet ein plattformweites Limit von 200 Anfragen pro Tag für kostenlose Modelle an.
- Parameter: 24B
- VRAM: Keine erforderlich (Cloud-gehostet)
- Am besten geeignet für: Testen unzensierter LLMs ohne lokale Hardware; kostenlos innerhalb der Plattform-Ratenlimits
- Plattform: OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B: Großes unzensiertes Modell via OpenRouter
70B-Modell für kreative Rollenspiele und Anweisungsbefolgung von Sao10k, feinabgestimmt für unzensierten Output. Basiert auf Llama 3.3 70B mit 131K Kontext. Aktiv gepflegt mit realer Nutzung auf OpenRouter und per Namen in der globalen Suche der Plattform auffindbar.
- Parameter: 70B
- VRAM: Keine erforderlich (Cloud-gehostet)
- Am besten geeignet für: Komplexes kreatives Schreiben, Rollenspiel und lange Anweisungsketten ohne lokale Hardware
- Plattform: OpenRouter
13. Sao10K: Llama 3 8B Lunaris: Leichtes unzensiertes Modell via OpenRouter
Lunaris 8B ist ein vielseitiges Allzweck- und Rollenspielmodell von Sao10k, basierend auf Llama 3 8B. Es ist eine strategische Zusammenführung mehrerer Modelle, die darauf ausgelegt ist, Kreativität mit verbesserter Logik und Allgemeinwissen in Einklang zu bringen, und bietet eine verbesserte Erfahrung gegenüber Stheno v3.2 mit gesteigerter Kreativität und Schlussfolgerung. Die kostengünstigste unzensierte Option auf OpenRouter für 0,04 USD / 0,05 USD pro Million Token, mit über 6 Milliarden Token an realer Nutzung auf der Plattform.
- Parameter: 8B
- VRAM: Keine erforderlich (Cloud-gehostet)
- Am besten geeignet für: Leichte unzensierte Konversation und kreatives Schreiben bei minimalen Kosten
- Plattform: OpenRouter
14. TheDrummer: Cydonia 24B V4.1: Unzensiertes Modell für kreatives Schreiben via OpenRouter
Cydonia 24B V4.1 ist ein unzensiertes Modell für kreatives Schreiben von TheDrummer, basierend auf Mistral Small 3.2 24B, mit gutem Erinnerungsvermögen, Prompt-Einhaltung und Intelligenz. 131K Kontextfenster. Aktiv gepflegt und direkt per Namen in der globalen Suche von OpenRouter auffindbar.
- Parameter: 24B
- VRAM: Keine erforderlich (Cloud-gehostet)
- Am besten geeignet für: Unzensiertes kreatives Schreiben und Rollenspiel ohne lokale Hardware
- Plattform: OpenRouter
Zugriff auf unzensierte Bild- und Videomodelle via Atlas Cloud
Im Jahr 2026 erfordern die meisten unzensierten Bild- und Videomodelle entweder lokale GPU-Hardware oder eine dedizierte API-Plattform, da Mainstream-Cloud-Anbieter Inhaltsfilter anwenden, die NSFW-Output auf Inferenzebene blockieren. Atlas Cloud ist eine Modell-API-Plattform, die speziell dafür entwickelt wurde, diese Einschränkung aufzuheben, und deckt über 300 kuratierte Modelle aus den Bereichen Text, Bild, Video und Audio ab.
Der Einstieg umfasst drei Schritte:
- Erstellen Sie ein Konto bei atlascloud.ai
- Generieren Sie einen API-Schlüssel über das Dashboard
- Rufen Sie den Modell-Endpunkt mit dem Schlüssel auf — Bild- und Videomodelle verwenden ihr eigenes REST-Format; LLM-Endpunkte folgen dem OpenAI Chat Completions-Format
Was Atlas Cloud speziell für unzensierte Anwendungsfälle relevant macht:
- Die Datenschutzrichtlinie der Plattform besagt: „Ihre generierten Inhalte werden niemals zum Training verwendet und von niemandem überprüft.“ Dies ist eine veröffentlichte, explizite Verpflichtung, keine Standardannahme.
- Für kein Modell im Katalog gilt ein tägliches Generierungslimit.
- Der Katalog für unzensierte Bilder umfasst 33 Text-zu-Bild-Modelle ab 0,003 USD pro Bild.
- Der Katalog für unzensierte Videos umfasst über 10 NSFW-Videomodelle ab 0,01 USD/Sek.
Der vollständige Katalog für unzensierte Modelle ist unter Uncensored AI durchsuchbar. Die Modelle 15 bis 20 in dieser Liste sind alle über einen einzigen Atlas Cloud API-Schlüssel zugänglich.
Was sind die besten unzensierten KI-Bildmodelle für NSFW- und Erwachseneninhalte?
Im Jahr 2026 basiert die Mehrheit der hochwertigen unzensierten Bildgenerierung auf der FLUX-Architektur, verfügbar über die Atlas Cloud API in verschiedenen Preis- und Qualitätsstufen (Atlas Cloud, Liste der Text-zu-Bild-Modelle, 2026). Der Katalog von Atlas Cloud umfasst insgesamt 33 Text-zu-Bild-Modelle. Zu den Anwendungsfällen gehören bildende Kunst, Charakterdesign, unzensierte Dessous-Modelle und die Generierung von Porträts für Erwachsene, die Erstellung von Spiel-Assets sowie die Stapelillustration in großem Umfang.
Die Homepage von Atlas Cloud gibt „über 300 kuratierte Modelle aus Text, Bild, Video und Audio“ an, und die Datenschutzrichtlinie der Plattform für ihren unzensierten Katalog lautet: „Ihre generierten Inhalte werden niemals zum Training verwendet und von niemandem überprüft.“
Für eine vollständige Aufschlüsselung browserbasierter und API-basierter unzensierter Bild-Tools deckt der Leitfaden für die besten unzensierten NSFW-KI-Bildgeneratoren beide Kategorien mit Fähigkeitsvergleichen ab. Entwickler, die sich speziell auf die FLUX-Architektur konzentrieren, können den Leitfaden für unzensierte FLUX-Bildgeneratoren für Details zu Fine-Tuning und Workflows lesen.
Für Workflows, die von einem vorhandenen Bild statt von einem Text-Prompt ausgehen, decken der Leitfaden für unzensierte KI-Bild-zu-Bild-Generatoren und der Leitfaden für die besten unzensierten KI-Bildeditoren Transformations- bzw. Bearbeitungspipelines ab. Teams, die sich auf Anime-Stil oder illustriertes Charakterdesign konzentrieren, finden spezialisierte Optionen im Leitfaden für unzensierte Anime-KI-Bildgeneratoren.
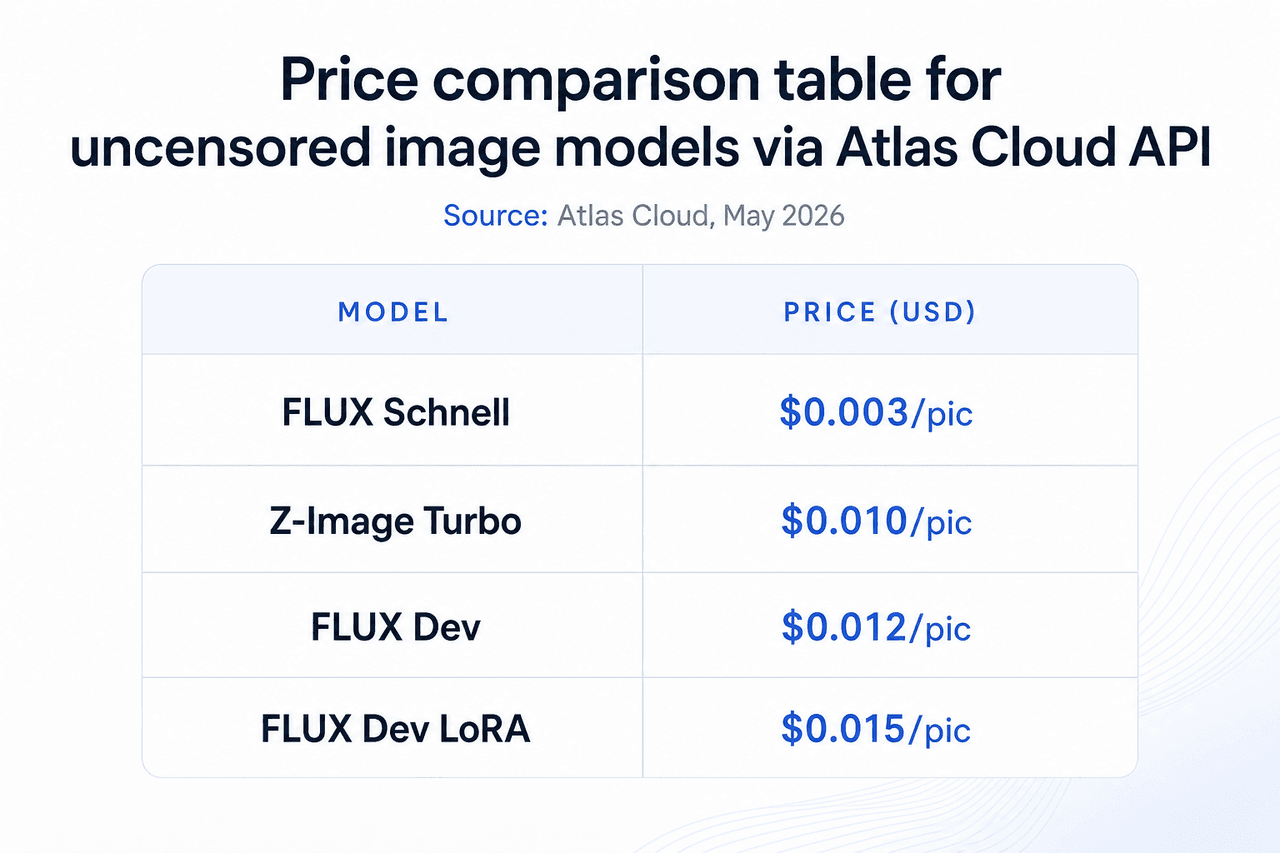
15. FLUX Schnell: Schnellstes unzensiertes KI-Bildmodell für Stapelgenerierung
Die kostengünstigste Option im Bild-Katalog von Atlas Cloud. Mit 0,003 USD pro Bild ist es das richtige Tool für Stapelgenerierungs-Workflows, bei denen Geschwindigkeit und Volumen wichtiger sind als feine Details. Es gilt kein tägliches Limit, und es werden keine Inhalte für das Training gespeichert.
- Preis: 0,003 USD/Bild
- VRAM: Keine erforderlich (API-Zugriff)
- Am besten geeignet für: Stapel-Bildgenerierung, Rapid Prototyping und unzensierten Output mit hohem Volumen
- Plattform: Atlas Cloud API
Bei 0,003 USD pro Bild produziert ein Budget von 3,00 USD 1.000 Bilder. Diese Kosten pro Output sind bei den meisten Anbietern niedriger als die Cloud-Speichergebühren für die resultierenden Dateien. Dies ändert die Wirtschaftlichkeit für Studios, die zuvor über Nacht teure lokale GPU-Rigs für die Stapelgenerierung betrieben haben: Der API-Ansatz ist jetzt sowohl billiger als auch schneller für Volumenarbeiten.
16. FLUX Dev: Höchstwertiges unzensiertes KI-Bildmodell für die Endproduktion
Vier Mal so teuer wie FLUX Schnell, mit merklich besserer Anatomie, Beleuchtung und Texturdetails. Für hochwertigen Output, bei dem einzelne Bilder zählen, ist der Preispunkt von 0,012 USD ein praktischer Schritt nach oben. Es eignet sich für Portfolio-Stücke, kommerzielle Inhalte für Erwachsene und Produktions-Assets, bei denen Qualität die primäre Einschränkung darstellt.
- Preis: 0,012 USD/Bild
- VRAM: Keine erforderlich (API-Zugriff)
- Am besten geeignet für: Hochwertige Einzelbilder, Portfolio-Stücke und finale Produktions-Assets
- Plattform: Atlas Cloud API
17. FLUX Dev LoRA: Unzensiertes Bildmodell mit Training für benutzerdefinierte Stile
LoRA-Fine-Tuning injiziert einen benutzerdefinierten Stil, ein Charakter-Aussehen oder ein Subjekt in die FLUX Dev-Basis. Dies ist das Modell, das Sie verwenden sollten, wenn Sie ein konsistentes Charakter-Aussehen über einen Stapel hinweg benötigen oder einen House-Stil auf jedes Bild in einem Set anwenden möchten. Atlas Cloud übernimmt das Laden des LoRA serverseitig.
- Preis: 0,015 USD/Bild
- VRAM: Keine erforderlich (API-Zugriff)
- Am besten geeignet für: Charakterkonsistenz, Training benutzerdefinierter Stile und Marken-Bildserien
- Plattform: Atlas Cloud API
18. Z-Image Turbo: Günstiges unzensiertes KI-Bildmodell bei mittlerer Qualität
Positioniert zwischen FLUX Schnell und FLUX Dev auf der Preis-Qualitäts-Kurve. Mit 0,01 USD pro Bild bietet Z-Image Turbo eine andere Architektur, die auf Geschwindigkeit optimiert ist, ohne die Bildvereinfachung, die Schnell zu seinem niedrigeren Preispunkt vornimmt. Die praktische Wahl, wenn die Qualität von Schnell nicht ausreicht und die Kosten für FLUX Dev zu hoch für das benötigte Volumen sind.
- Preis: 0,01 USD/Bild
- VRAM: Keine erforderlich (API-Zugriff)
- Am besten geeignet für: Generierung mittleren Volumens, bei der Qualität und Kosten ausgeglichen werden müssen
- Plattform: Atlas Cloud API
Was sind die besten unzensierten KI-Videomodelle für NSFW-Animationen im Jahr 2026?
Im Jahr 2026 erfordert die unzensierte Videogenerierung eine separate Pipeline von der Bildgenerierung, da Mainstream-Videoplattformen identische Inhaltsfilter anwenden und sich weigern, NSFW-Inhalte zu animieren, selbst wenn das Quellbild anderswo generiert wurde (Atlas Cloud, unzensierter Modellkatalog, 2026). Die Seite für unzensierte Videos von Atlas Cloud trägt die Überschrift „Unrestricted Creative Freedom. No Filters. No Limits.“ und deckt über 10 NSFW-Videomodelle ab, wobei der vollständige Katalog auch Varianten der Serien Wan 2.6, Wan 2.5 und Van umfasst.
19. Wan 2.2 Turbo Spicy Infinite I2V: Kostengünstigstes unzensiertes Videomodell
Die Einstiegsoption für NSFW-Animationen aus einem Standbild. Mit 0,01 USD/Sek. ist es der kosteneffizienteste Weg, ein statisches Bild in ein NSFW-Video zu animieren. Die Auflösung erreicht 1080p bei variabler Clip-Dauer, was es zum richtigen Ausgangspunkt für budgetbewusste Produktionspipelines macht.
- Preis: 0,01 USD/Sek.
- Auflösung: 1080p
- Dauer: Variabel
- Am besten geeignet für: Kosteneffiziente NSFW-Animation und Vorschau von Bewegungskonzepten
- Plattform: Atlas Cloud API
20. Seedance v1.5 Spicy: Höchstwertiges unzensiertes Videomodell für den finalen Output
Die Option in Kinoqualität im Katalog. Mit 0,049 USD/Sek. kostet es etwa 2,5 Mal mehr als Wan 2.2 Turbo Spicy Infinite, erzeugt aber flüssigere Bewegungen, eine bessere Kohärenz des Subjekts über die Frames hinweg und natürlichere Übergänge. Für NSFW-Video-Output in Endqualität, bei dem visuelle Wiedergabetreue das primäre Anliegen ist, ist dies die Top-Option im unzensierten Video-Lineup von Atlas Cloud.
- Preis: 0,049 USD/Sek.
- Auflösung: 720p
- Dauer: 5s
- Am besten geeignet für: NSFW-Video in Endqualität, professionelle Inhalte für Erwachsene und lieferbereiten Output
- Plattform: Atlas Cloud API
Der Leitfaden für die besten unzensierten KI-Bild-zu-Video-Generatoren deckt den vollständigen Katalog der Varianten der Wan 2.7- und Wan 2.2 Spicy-Serie mit allen Dauer- und Auflösungsoptionen ab.
Kurzanleitung zur Auswahl unzensierter KI-Modelle
| Bedarf | Empfehlung |
|---|---|
| Bestes unzensiertes LLM insgesamt | llama2-uncensored oder dolphin-llama3 |
| Programmieraufgaben | dolphin-mixtral 8x7B oder dolphincoder |
| Rollenspiel und kreatives Schreiben | hermes3 |
| Unter 4 GB VRAM | dolphin-phi 2.7B |
| Unzensierte Bildgenerierung | FLUX Schnell via Atlas Cloud (0,003 USD/Bild) |
| NSFW-Video aus Bild | Wan 2.2 Turbo Spicy Infinite via Atlas Cloud (0,01 USD/Sek.) |
FAQ zu unzensierten KI-Modellen
Was ist das unzensierteste KI-Modell im Jahr 2026?
Nach Ollama-Download-Zahlen führt llama2-uncensored mit 2,6 Mio. Pulls und ist damit die am stärksten durch die Community validierte Option unter den unzensierten KI-Modellen 2026 (Ollama, Suche nach unzensierten Modellen, 2026). Nach reiner Leistungsfähigkeit bietet dolphin-llama3 mehr: Funktionsaufrufe, bis zu 256K Kontext und eine Llama 3-Basisarchitektur. Die Antwort hängt davon ab, ob für Ihren Anwendungsfall bewährte Stabilität oder moderne Leistungsfähigkeit wichtiger ist.
Welche unzensierten Modelle laufen auf Ollama?
Zehn Modelle aus dieser Liste laufen als unzensierte Ollama-Modelle: llama2-uncensored, dolphin-llama3, dolphin-mixtral, dolphin-mistral, dolphin-phi, hermes3, wizard-vicuna-uncensored, dolphincoder, wizardlm-uncensored und everythinglm. Das Community-Modell jaahas/qwen3.5-uncensored läuft ebenfalls auf Ollama für die mehrsprachige Nutzung. Alle werden mit ollama pull [Modellname] installiert.
Welche unzensierten Modelle sind auf OpenRouter verfügbar?
Im Jahr 2026 hostet OpenRouter unzensierte LLMs per API, wodurch die GPU-Anforderung komplett entfällt. Zu den Optionen gehören das Modell venice/uncensored der kostenlosen Stufe für 0 USD pro Million Token (200 Anfragen pro Tag) sowie kostenpflichtige Modelle, darunter Sao10K Euryale 70B, Lunaris 8B und TheDrummer Cydonia 24B (OpenRouter, venice/uncensored Modellseite, 2026). Diese unzensierten OpenRouter-Modelle erfordern keine lokale GPU und keine Hardware-Investition für den Start.
Was ist der Unterschied zwischen einem ablatierten und einem feinabgestimmten unzensierten Modell?
Die Ablierung entfernt Weigerungsgewichte chirurgisch auf der Gewichtsebene aus einem Modell. Feinabgestimmte unzensierte Modelle wie die Dolphin-Serie werden von Anfang an mit Datensätzen trainiert, die kein Verweigerungsverhalten verstärken. Die Community stellt konsistent fest, dass feinabgestimmte Modelle stabiler sind: Ablierung kann bei diversen Prompt-Typen zu inkonsistenten Ausgaben führen, während Fine-Tuning zuverlässige Ergebnisse liefert, was erklärt, warum Dolphin-Modelle die Download-Zahlen der unzensierten Ollama-Modelle dominieren.
Kann ich unzensierte KI-Modelle lokal auf einem Laptop ausführen?
Ja. dolphin-phi 2.7B läuft mit unter 4 GB VRAM und ist damit der Einstiegspunkt für den Laptop-Einsatz mit einer diskreten GPU. Mit 6-8 GB VRAM können Sie jedes 7B-Modell aus dieser Liste ausführen. Integrierte Grafiken funktionieren nicht. Der Leitfaden zur lokalen Einrichtung für unzensierte KI-Modelle behandelt Mindesthardwarekonfigurationen und Quantisierungseinstellungen im Detail.
Fazit
Das beste unzensierte KI-Modell 2026 hängt vollständig von Ihrem Anwendungsfall ab. Für allgemeine LLM-Arbeit ist dolphin-llama3 die fähigste Ollama-Option. Für Laptops deckt dolphin-phi die VRAM-Anforderung von unter 4 GB ab. Für Cloud-LLM-Zugriff ohne Hardware ist venice/uncensored im kostenlosen Tarif von OpenRouter bei 0 USD pro Million Token der praktische Ausgangspunkt. Für unzensierte Bildgenerierung in großem Maßstab produziert FLUX Schnell über die Atlas Cloud API Output für 0,003 USD pro Bild ohne tägliches Limit. Für NSFW-Videos beginnt der Atlas Cloud-Katalog bei 0,01 USD/Sek. mit einer verifizierten „Kein Training, keine Überprüfung“-Richtlinie.
Leser, die einen vollständigen Überblick über unzensierte KI-Tools für Bilder, Videos und Editoren suchen, finden im Leitfaden für unzensierte KI-Bildgeneratoren die vollständige Landschaft abgedeckt.






