
Vor ein paar Monaten haben wir uns ein täuschend einfaches Ziel gesetzt: Kohärentes, hochwertiges Video mit einer Länge von über 15 Sekunden produzieren, auf einer einzigen GPU und in deutlich unter einer Minute Gesamtlaufzeit. Heutige Video-Diffusionsmodelle wie Wan2.2 beherrschen 3–5-sekündige Clips gut. Interessant wird es erst bei einer Dehnung auf 10s, 30s oder eine Minute.
Dieser Beitrag dokumentiert den Weg, den wir tatsächlich eingeschlagen haben. Wir haben sechs Ansätze untersucht, die in aktuellen Papern und Technikberichten auftauchen – TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk und Helios – die Kompromisse abgewogen und sind letztlich bei SVI (Stable Video Infinity) gelandet, eingebunden in unsere DiffSynth Engine neben TurboWan. Wir gehen jeden dieser Wege durch, erklären die Funktionsweise von SVI und präsentieren die Produktionskennzahlen.
Warum langes Video schwierig ist
Drei Dinge brechen zusammen, sobald man die fünf Sekunden überschreitet.
Die VRAM-Mauer
Wan2.2 nutzt Full Attention mit O(n²)-Kosten bezüglich der Anzahl der latenten Token. Die Mathematik ist unerbittlich:
5s (81 Frames): ~32,7k Token, Attention-Matrix ~10 GB.
10s (165 Frames): ~65,5k Token, Attention-Matrix ~40 GB — das überschreitet bereits die Kapazität einer einzelnen GPU.
30s (~500 Frames): ~200k Token, nicht machbar.
In der Praxis belegt Self Forcing allein bei 165 Frames den Großteil der 129 GB einer H200 nur für den KV-Cache.
Zeitliche Drift
Selbst wenn der Speicher ausreicht, treten drei Drift-Modi auf. Das Helios-Paper hat sie benannt: Position Shift (Objekte wandern über das Bild), Color Shift (allmähliche Farb- und Helligkeitsdrift) und Restoration Shift (das Modell überkorrigiert und erzeugt sichtbare Unstetigkeiten).
Kausale Konsistenz
Standard-Videodiffusion nutzt bidirektionale Full Attention – jedes Frame achtet auf jedes andere. Das bedeutet: kein Streaming-Output – man kann Frame 1 nicht anzeigen, bis Frame N fertig ist.
Unser konkretes Ziel war bescheiden: ≥15 Sekunden Video, flüssige visuelle Kontinuität, stabile Subjekte über den gesamten Clip hinweg, Gesamtlaufzeit unter 60 Sekunden, minimales Training und eine starke Präferenz für die Wiederverwendung bereits vorhandener Gewichte.
Die Untersuchung
Wir haben sechs Familien unter die Lupe genommen. Die Namen sind meist Titel von Papern; die Kategorien werden später wichtig.
Route 1 · TTT (Test-Time Training)
Paper: One-Minute Video Generation with Test-Time Training (arXiv 2504.05298, Apr 2025).
Die Idee ist, das Modell während der Inferenz feinabzustimmen, damit es sich daran erinnert, was es bereits generiert hat. Eine kleine TTT-Schicht (ein 2-Layer-MLP, plus ein Gate und eine lokale Attention) wird in jedem Transformer-Block nach der Attention eingefügt, und das Modell wird mit einem Curriculum trainiert, das von kurzen Clips bis zu einer vollen Minute reicht.
Einfügen pro Block: Nach der Standard-Attention werden ein Gate, eine TTT-Schicht und eine lokale Attention sowie ein LayerNorm eingefügt.
Curriculum: Training in schrittweise längeren Fenstern — 3s → 9s → 18s → 30s → 60s.
Kosten: 256 H100s für ~50 Stunden.
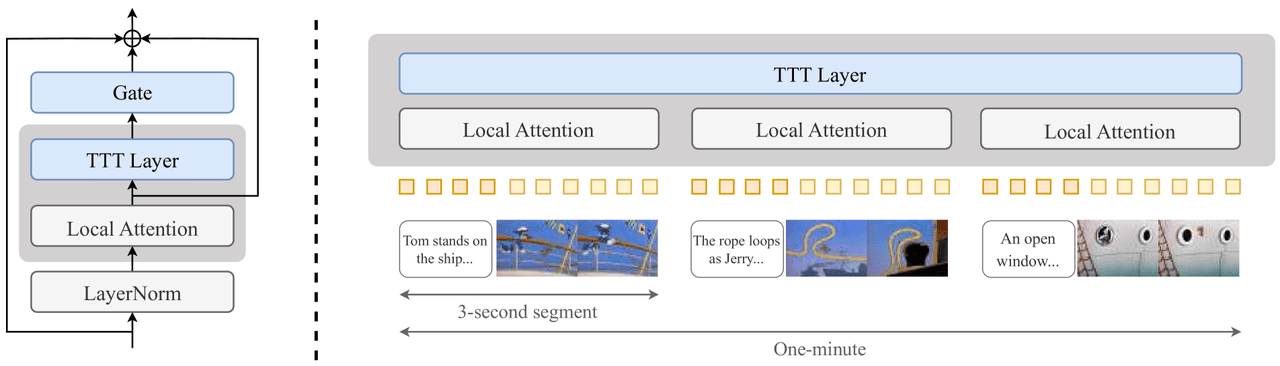
TTT — links: Einfügepunkt (Gate + TTT-Schicht + lokale Attention + LayerNorm, nach der Standard-Attention via Residual angehängt). Rechts: Video in 3-Sekunden-Clips segmentiert, die jeweils intern durch lokale Attention verarbeitet werden, wobei die TTT-Schicht den globalen Speicher über die Segmente hinweg trägt.
Es funktioniert – das Paper erreicht eine 1-Minuten-Generierung. Aber die Trainingskosten sind enorm, die Experimente decken nur CogVideoX 5B ab (der Transfer auf Wan2.2 14B ist nicht bewiesen) und die eingefügten TTT-Schichten kollidieren mit den Kernel-Optimierungen, auf die wir bereits setzen. Fazit: nicht ausgewählt.
Route 2 · LoL (Longer than Longer)
Paper: LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914, Jan 2026).
LoL zielt auf einen spezifischen Fehler bei autoregressivem Langvideo ab – den Sink-Collapse, bei dem Multi-Head Attention vollständig auf das Anker-Frame konvergiert und das Video periodisch in seinen Anfangszustand zurückfällt. Die Lösung ist Multi-Head RoPE Jitter: zufällige Phasenstörungen pro Head, die die Inter-Head-Homogenität aufbrechen. Training-frei, Plug-in.
Fehlermodus: Sink-Collapse — unter autoregressivem RoPE richten sich die Positionsphasen entfernter Frames periodisch am Anker aus, die Attention konzentriert sich, der Inhalt schnappt zum Anker-Frame zurück.
Korrektur: Jeder Attention-Head erhält seine eigene kleine zufällige Phasenverschiebung. Die Heads können nicht mehr in die gleiche Spalte kollabieren. Kein Nachtraining erforderlich, lässt sich in bestehende Modelle einfügen.
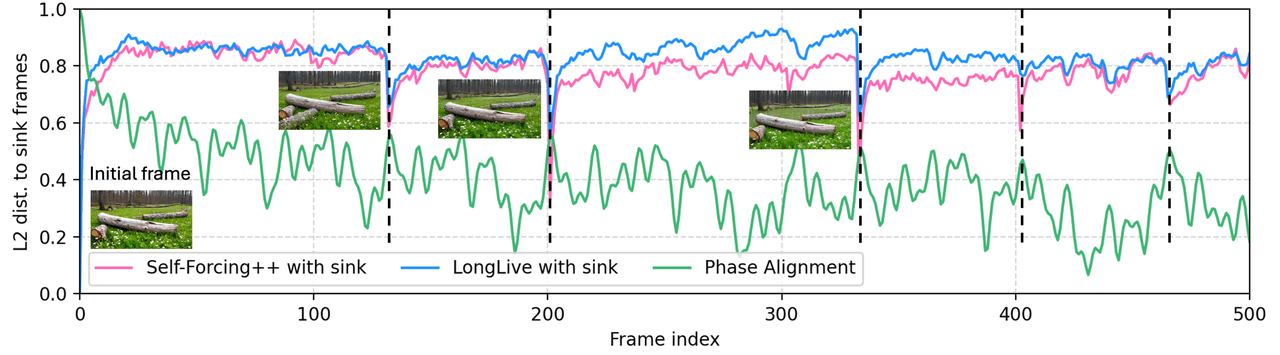
L2-Distanz zum Anker vs. Frame-Index. Self-Forcing++ (rot) und LongLive (blau), beide mit Sink, schnappen an bestimmten Frame-Positionen periodisch zurück – das sind Sink-Collapse-Ereignisse, bei denen das Video zum Anker zurückkehrt. LoLs Phasenabgleich (grün) eliminiert dieses Zurückschnappen.
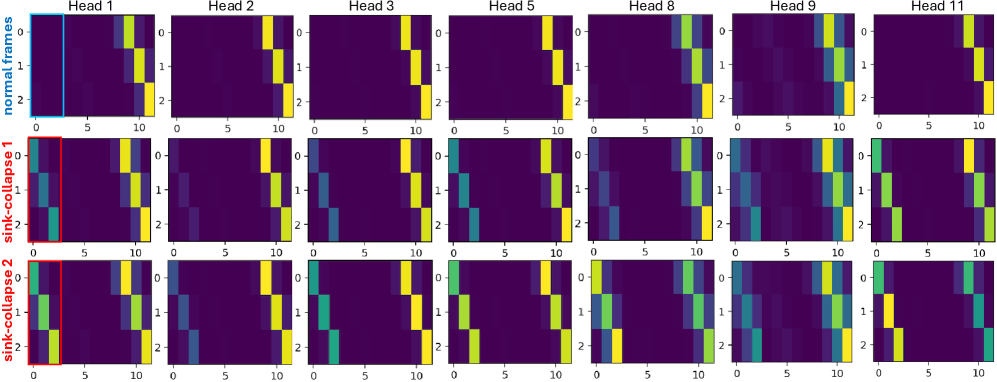
Attention-Maps pro Head. Obere Reihe: normale Frames – die Heads haben sichtbar unterschiedliche Muster. Untere Reihen: während des Sink-Collapse – jeder Head sieht gleich aus, alle auf die Spalte des Anker-Frames kollabiert. RoPE Jitter stellt die Diversität pro Head wieder her.
LoL erreicht 12-Stunden-Videos auf CogVideoX/HunyuanVideo mit geringem Qualitätsverlust. Der Haken ist, dass alle Demos eher statische Szenen zeigen; wir wissen nicht, wie es bei Tanz, Sport oder allem mit starker Bewegung abschneidet. Zudem müssten wir die Attention von Wan2.2 modifizieren. Fazit: Die Anpassungskosten sind zu hoch für unbewiesene Gewinne bei Bewegungs-Content. Nicht ausgewählt.
Route 3 · Self Forcing (Causal Wan2.2)
Paper: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009, NeurIPS 2025 Spotlight).
Self Forcing ersetzt die bidirektionale Full Attention von Wan2.2 durch kausale Attention: Ein Frame achtet nur auf Frames, die vor ihm liegen. Diese einzige Änderung ermöglicht Streaming-Generierung – sobald Chunk 1 fertig ist, kann er dekodiert und ausgegeben werden.
Bidirektional: Jedes Frame achtet auf alle anderen → alle 40 Denoise-Schritte müssen abgeschlossen sein, bevor irgendein Frame gezeigt werden kann. Kausal: Ein Frame sieht nur seine Vergangenheit → der erste Chunk kann streamen, sobald er fertig ist.
Der Trainings-Trick ist das, was dem Paper seinen Namen gibt. Anstatt auf sauberer Ground-Truth-Kontext-Basis (Teacher Forcing) oder mit benutzerdefinierten Attention-Masken (Diffusion Forcing) zu trainieren, durchläuft Self Forcing den tatsächlichen Inferenz-Pfad mit einem rollenden KV-Cache, sodass Trainings- und Inferenz-Verteilungen übereinstimmen.
Generierungs-Loop: Entrauschen des nächsten kleinen Frame-Chunks unter Nutzung von DMDs komprimiertem Step-Schedule, konditioniert auf einem rollenden KV-Cache, der aus bereits generierten Frames aufgebaut ist.
Stream: Sobald ein Chunk fertig ist, wird er VAE-dekodiert und ausgegeben.
Carry-over: Die Latents des neuen Chunks werden in den KV-Cache geschoben, auf den der nächste Chunk achten kann.
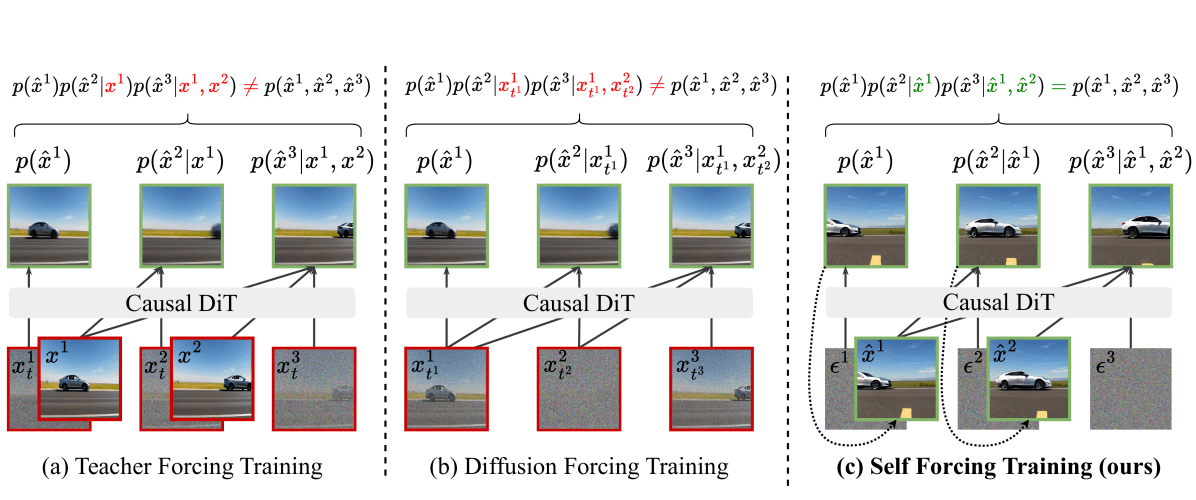
Drei Trainingsparadigmen im Vergleich: (a) Teacher Forcing trainiert auf sauberen Frames — bei Inferenz führen verrauschte Frames zu Out-of-Distribution-Drift; (b) Diffusion Forcing nutzt benutzerdefinierte Attention-Masken, hat aber immer noch Diskrepanzen; (c) Self Forcing wiederholt den wahren Inferenz-Prozess unter Nutzung eines rollenden KV-Cache, was Training und Inferenz vollständig abgleicht.
Wir haben es im FastVideo-Framework auf einer einzelnen H200 gemessen:
| Länge | Frames | Zeit | VRAM |
|---|---|---|---|
| 5s | 81 Frames | 70s | — |
| 10s | 165 Frames | 168s | 129 GB (nahe Kapazitätsgrenze) |
| 20s | 321 Frames | 287s | 129 GB (KV-Cache auf 42 Frames begrenzt) |
Dies ist architektonisch die sauberste Antwort, und sie gefällt uns wirklich gut. Aber 10s sättigen bereits das VRAM einer H200, die Qualität sinkt bei 165 Frames, das Originalmodell benötigt ein Kausal-Attention-Feintuning, und echtes Streaming erfordert zudem ein kausales Conv3D im VAE.
Fazit: Wir warten darauf, dass die Community VRAM- und Qualitätsprobleme weiter löst. Vorerst nicht übernommen.
Route 4 · Self Forcing++
Paper: Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283, Okt 2025).
Baut auf Self Forcing mit drei Ergänzungen auf: Backward Noise Initialization (jeder neue Chunk startet mit Noise, das von bereits generierten Frames rückwärts integriert wurde, was Unstetigkeiten an Chunk-Grenzen eliminiert); Extended DMD Alignment (Schneiden von 5s-Fenstern aus einem langen Rollout und Abgleich gegen die Kurzfenster-Ausgabe eines Lehrers) sowie eine GRPO-Phase mit Optical-Flow-Belohnung, um dynamischere Bewegungen zu erzwingen.
Schritt 1: Self-Rollout des Schülers für weit mehr als 5 Sekunden, wobei ein langer Entwurf mittels rollendem KV-Cache gesammelt wird. Schritt 2: Zufälliges Schneiden von 5s-Fenstern aus diesem Entwurf, Ausführung durch Extended DMD gegen die Kurzfenster-Verteilung des Lehrers zum Abgleich. Schritt 3: Verfeinerung mit GRPO unter Verwendung der Optical-Flow-Größe als Belohnung, was das Modell zu dynamischeren Bewegungen anstupsen soll. Trick: Jeder neue Chunk startet mit Noise, das vom vorherigen Chunk rückintegriert wurde, nicht von frischem Gauß-Rauschen – dadurch "springen" Chunk-Grenzen nicht mehr.
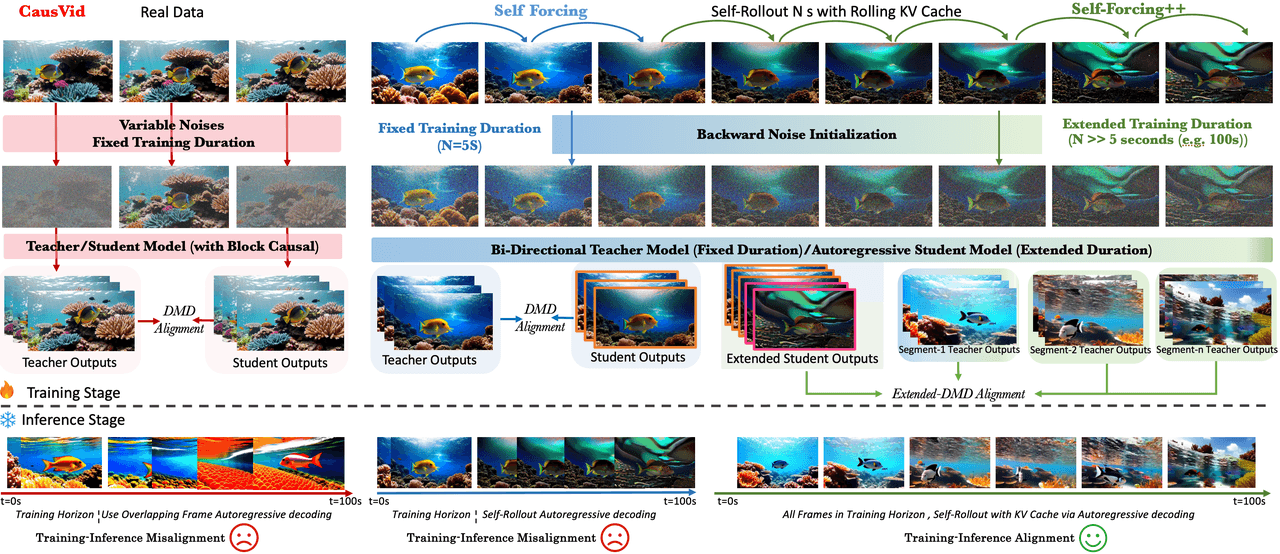
Von links nach rechts: CausVid (feste Trainingsdauer, Diskrepanz zwischen Training und Inferenz) → Self Forcing (feste Dauer + DMD-Abgleich) → Self-Forcing++ (erweiterte Dauer + Backward Noise Initialization + Extended DMD-Abgleich). Die unteren Reihen zeigen die Korrespondenz von Trainings- und Inferenzphase.
Ergebnis: Minutengenaue Videos (bis zu ca. 4m 15s) auf einem 1.3B Wan2.1. Großartiges Paper. Für die Produktion stießen wir auf zwei Mauern: der Content ist meist statisch (geringe Bewegung), das Basismodell ist 1.3B (weit unter dem Wan2.2 14B) und es gibt keinen veröffentlichten Code oder Gewichte zum Bootstrappen. Fazit: Vorerst nicht ausgewählt.
Route 5 · Infinite Talk (A2V)
Eine völlig andere Art von Problem – Audio-to-Video, bei dem Audio die kontinuierliche Talking-Head-Generierung steuert.
Input-Bündel pro Chunk: Die verrauschten Latents des neuen Chunks, die Audio-Features für dieses Zeitfenster, das vom Benutzer bereitgestellte Referenzbild, das letzte Frame des vorherigen Chunks und ein Soft-Conditioning-Gewicht. Referenz-Identität: Das Referenzbild hält das langfristige Aussehen stabil. Adaptive Einschränkung: Das Soft-Gewicht strafft oder lockert die Referenz basierend auf der Ähnlichkeitsdrift. Motion-Bridge: Das letzte Frame des vorherigen Chunks überträgt die Bewegung über die Grenzen hinweg.
Es ist gut für das, was es ist – Talking Heads, unbegrenzt. Aber die Architektur unterscheidet sich so stark von Wan2.2, dass dediziertes Training erforderlich ist, und es lässt sich nicht auf allgemeine Szenen verallgemeinern. Fazit: wertvoll in einer Nische, keine allgemeine Lösung für lange Videos.
Route 6 · Helios
Paper: Helios: Real Real-Time Long Video Generation Model (PKU-YuanGroup, arXiv 2603.04379, Mär 2026).
Zum Zeitpunkt der Erstellung dieses Artikels ist Helios der SOTA für lange Videos – 14B Parameter, 19,5 FPS in Echtzeit auf einer einzelnen H100. Der Trick besteht darin, historische Frames in eine dreistufige Pyramide zu komprimieren und sie in das Denoising des aktuellen Frames einzuspeisen, sodass das Token-Budget unabhängig von der Videolänge konstant bleibt.
Multi-Term Memory: Kurzzeitgedächtnis (letzte 3 Frames) behält volle Auflösung; mittelfristig (letzte 20 Frames) erhält moderate Komprimierung; langfristig (alles Frühere) erhält starke Komprimierung. Das gesamte Token-Budget ist unabhängig von der Videolänge konstant. Guidance Attention: Innerhalb jedes DiT-Blocks werden saubere historische KVs und verrauschte aktuelle QKVs separat verarbeitet, damit historisches Rauschen das aktuelle Entrauschen nicht kontaminieren kann. Pyramid Sampling: Erst in niedriger Auflösung sampeln, um die Struktur zu definieren, dann auf hohe Auflösung verfeinern, um Details hinzuzufügen – insgesamt etwa 2,3× weniger Token.
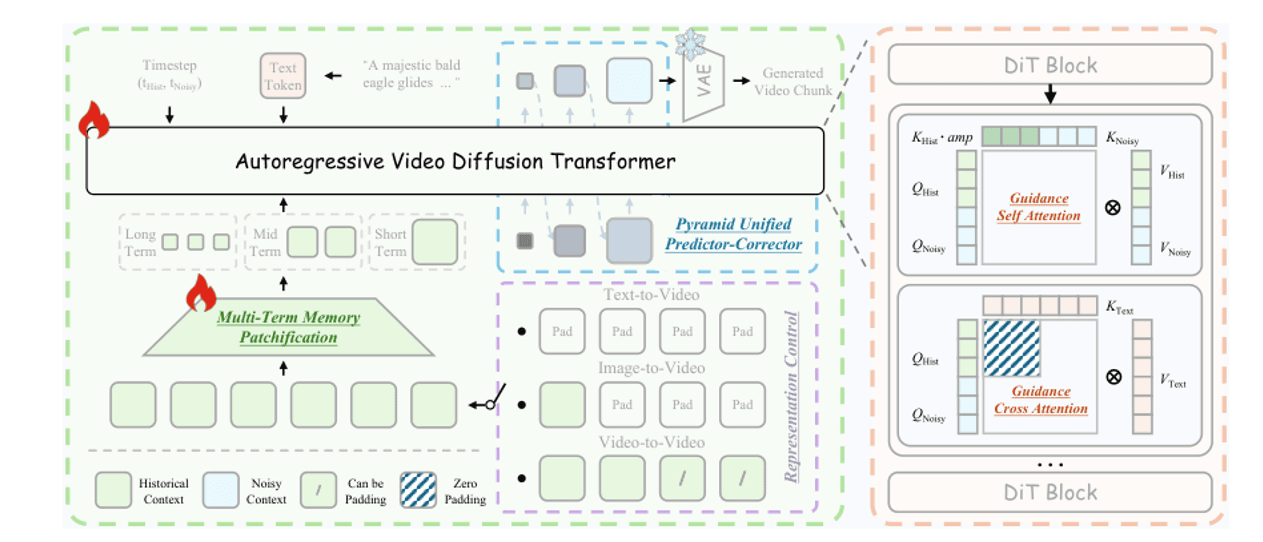
Helios-Architektur. Links: Unified History Injection – kurz-/mittel-/langfristige Historie mit unterschiedlichen Verhältnissen komprimiert, vor dem Eintritt in das DiT mit dem aktuellen Frame konkateniert. Rechts: Pyramid Unified Predictor-Corrector – erst niedrige Token-Anzahl zur Strukturdefinition, dann hohe Token-Anzahl zur Verfeinerung der Details, Reduzierung der Berechnung um ~2,3×.

Das Helios-Paper definiert und visualisiert systematisch drei Drift-Kategorien bei der Langvideo-Generierung: (a) Position Shift, (b) Color Shift, (c) Restoration Shift (Rauschen), (d) Restoration Shift (Unschärfe). Guidance Attention wurde speziell entwickelt, um alle drei anzugehen.
Der gemessene Durchsatz von Helios auf einer H200 ist beeindruckend – im Grunde flach bei steigender Länge:
| Länge | Zeit | Durchsatz |
|---|---|---|
| 240 Frames (10s) | 24s | ~10 FPS |
| 480 Frames (20s) | 42s | ~11,4 FPS |
| 960 Frames (40s) | 82s | ~11,7 FPS |
| H100 Single GPU (Helios-Distilled) | — | 19,5 FPS |
Der Haken ist, dass die Multi-Term Memory Patchification ein komplettes Retraining eines 14B-Modells erfordert. Es gibt keine veröffentlichten Gewichte – nur einen Technikbericht –, also können wir nicht einfach eine LoRA aufsetzen. Fazit: eine mittel- bis langfristige Richtung; heute noch nicht einsetzbar.
Vergleichszusammenfassung der Routen
Alle sechs Routen nebeneinander, mit SVI als der Zeile, für die wir uns letztendlich entschieden haben:
| Ansatz | Max. Dauer | Qualität | Training erf. | Eng. Schwierigkeit | Allg. | Empf. |
|---|---|---|---|---|---|---|
| TTT | 1 Minute | Hoch | Schweres Training | Hoch | Mittel | ★★☆ |
| LoL | Stunden-Skala | Mittel (nur statisch) | Training erf. | Mittel | Mittel | ★★☆ |
| Self Forcing | Theoretisch unbegr. | Mittel (Abfall > 10s) | Exist. Modell | Hoch (VRAM-Prob.) | Hoch | ★★★ |
| Self Forcing++ | Minuten-Skala | Niedrig (meist stat.) | Training erf. | Sehr hoch (kein Code) | Hoch | ★☆☆ |
| Infinite Talk | Unbegrenzt | Hoch (Talking Head) | Training erf. | Hoch | Niedrig (nur A2V) | ★★☆ |
| Helios | Theoretisch unbegr. | Hoch (Ind.-SOTA) | Vollständiges Retraining | Sehr hoch (keine Gewichte) | Hoch | ★★★☆ |
| SVI | Unbegrenzt | Mittel-Hoch | Open-Source LoRA | Mittel | Hoch | ★★★★ |
Eine Taxonomie, die sich aus der Untersuchung ergab
Wenn man genau hinsieht, fällt jeder Ansatz, den wir untersucht haben, in einen von drei Eimern.
Typ A — Den Attention-Bereich selbst erweitern (Self Forcing, LoL, TTT). Das Modell verarbeitet längere Sequenzen direkt. Höchste theoretische Qualität. Das VRAM wächst quadratisch, weshalb die Technik heute bei etwa 10s an ihre Grenzen stößt.
Typ B — Hierarchische Historienkomprimierung (Helios). Komprimierung vergangener Frames und Einspeisung als Konditionierung. Umgeht VRAM-Probleme. Kostet ein vollständiges Retraining eines 14B-Modells.
Typ C — Zustandshafte, rollende Generierung (SVI, Infinite Talk). Zerlegung eines langen Videos in kurze Clips mit überlappendem Zustand. Konstantes VRAM, unbegrenzte Länge, nur LoRA-Training. Der Kompromiss sind mögliche Unstetigkeiten an Clip-Grenzen und eine unbegrenzte langfristige Drift, die man steuern, aber nicht eliminieren kann.
Für dieses Quartal ist Typ C das, was wir ausliefern. Für das nächste Jahr beobachten wir bei Typ B die Literatur.
Im nächsten Beitrag gehen wir darauf ein, wie die Auslieferung tatsächlich aussah – sechs Ansätze zur Generierung von Videos mit ≥15 Sekunden, warum wir uns für SVI entschieden haben und wie die Produktionszahlen aussehen. Teil 2 lesen →






