
In Teil 1 haben wir sechs Ansätze zur Generierung langer Videos untersucht – TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk und Helios – und sind bei SVI als dem einzigen Weg gelandet, der heute ohne das Retraining eines 14B-Modells funktioniert. Dieser Beitrag beschreibt, wie die Implementierung in der Praxis aussah: wie die Clip-Stitching-Schleife funktioniert, warum Error-Recycling wichtig ist und die Produktionskennzahlen aus unserem ersten Deployment auf TurboWan.
Die Wahl: SVI (Stable Video Infinity)
Die Kernphilosophie von SVI besteht darin, eine Generierung mit unendlicher Länge in das Zusammenfügen einer endlichen Anzahl kurzer Clips mit sorgfältig konzipiertem Memory-Transfer zu verwandeln. Das klingt bescheiden, bis man erkennt, dass es die meisten technischen Schwierigkeiten auf einen Schlag löst: kein Retraining des Basismodells (ein kleines LoRA auf TurboWan), konstanter VRAM-Bedarf, kombinierbar mit bestehender Speed-Distillation und offizielle LoRA-Weights sind öffentlich verfügbar.
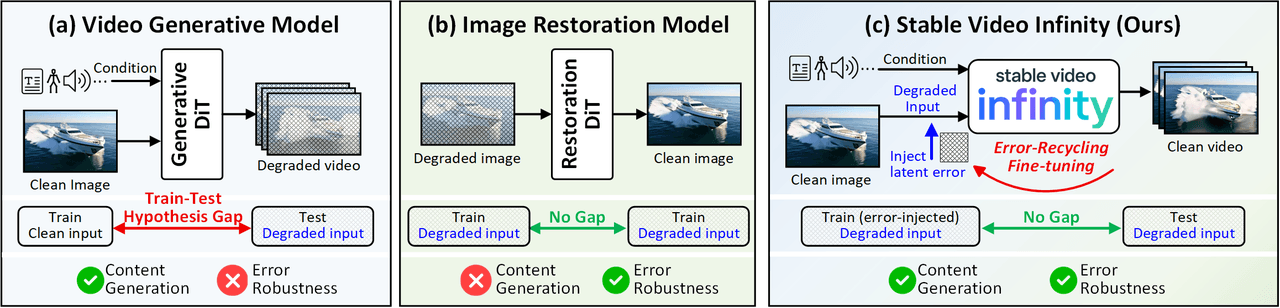
Das mentale Modell von SVI. (a) Standard-Videogenerierungsmodelle haben eine Lücke zwischen Trainings- und Testhypothese – sie trainieren auf sauberen Eingaben, sehen sich aber bei der Inferenz mit verrauschten, fehlerbehafteten Eingaben konfrontiert. (b) Bildwiederherstellungsmodelle sind robust gegenüber Fehlern, können aber keine neuen Inhalte generieren. (c) Das Error-Recycling Fine-Tuning von SVI schlägt die Brücke – es nutzt selbst erzeugte Fehler als supervisory signals, sodass das Modell aktiv lernt, seine eigenen Generierungsfehler zu identifizieren und zu korrigieren.
Wie das Clip-Stitching funktioniert
Jeder Clip umfasst 81 Frames (5s bei 16fps). Die Generierung ist lediglich eine Schleife: Der nächste Clip wird durch einen globalen Identitäts-Anker und eine kurzfristige Bewegungsbrücke (Motion Bridge) des vorherigen Clips konditioniert und dann verkettet.
Clip 1: Eingaben: Referenzbild + leeres Motion-Memory. Ausgabe: ein 5s Clip. Extrahiere Motion-Memory: das Latent der letzten 4 Frames. Clip 2: Eingaben: Referenzbild + Motion-Memory aus Clip 1. Ausgabe: ein 5s Clip. Extrahiere Motion-Memory aus dem Ende des Clips. ... Wiederhole dies für N Clips und verknüpfe dann Clip 1 + Clip 2 + … + Clip N zum langen Video.
Das Elegante daran ist, dass keine Modifikation der DiT-Attention erforderlich ist. Der historische Kontext wird auf Input-Ebene als Latents verkettet, und ein kleines LoRA bringt dem Modell bei, dieses Präfix tatsächlich zu nutzen.
Anker-Latent: Vom Benutzer bereitgestelltes Referenzbild, encodiert durch den VAE → sorgt für globale Konsistenz von Subjekt/Charakter. Motion-Latent: Latent der letzten 4 / 8 / 12 Frames des vorherigen Clips → zeigt dem Modell, wie das letzte Segment endete. Padding: Richtet die Input-Form so aus, dass das DiT eine saubere, verkettete Sequenz sieht: Anker + Motion + Padding.
Error-Recycling Fine-Tuning
Das Detail, das dafür sorgt, dass SVI über viele Clips hinweg stabil bleibt, ist die Art und Weise, wie das LoRA trainiert wird. Bei der Standard-Inferenz beginnt das Denoising immer bei reinem Gaußschen Rauschen – aber beim Stitching langer Videos verunreinigen Fehler aus früheren Clips die Konditionierung für spätere Clips. Wenn man nur auf sauberen Referenzeingaben trainiert, baut man die Trainings-Inferenz-Lücke fest ein.
Standard-Training: Die Referenzeingaben jedes Clips sind saubere Ground Truths → das Modell sieht nie die Art von verrauschtem historischem Kontext, dem es bei der Inferenz tatsächlich begegnet, und Diskontinuitäten summieren sich.
Error-Recycling: Während des Trainings werden absichtlich die eigenen Fehler des Modells in die Referenzeingaben injiziert, sodass das LoRA explizit lernt, mit verrauschtem historischem Kontext zu arbeiten. Visuelle Diskontinuitäten an Clip-Grenzen nehmen drastisch ab.
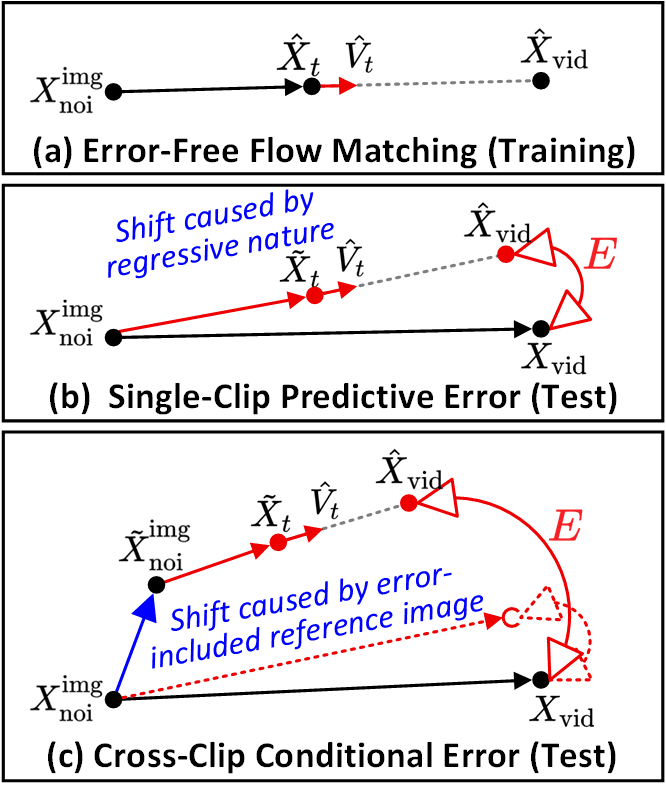
SVI identifiziert zwei Kern-Fehlertypen. (a) Error-Free Flow Matching ist die Trainings-Trajektorie. (b) Single-Clip Predictive Error – der Drift pro Clip zwischen dem Denoising-Pfad und der idealen Trajektorie. (c) Cross-Clip Conditional Error – fehlerbehaftete Referenzbilder verursachen einen kaskadierenden Drift über Clips hinweg. Error-Recycling injiziert explizit beides.
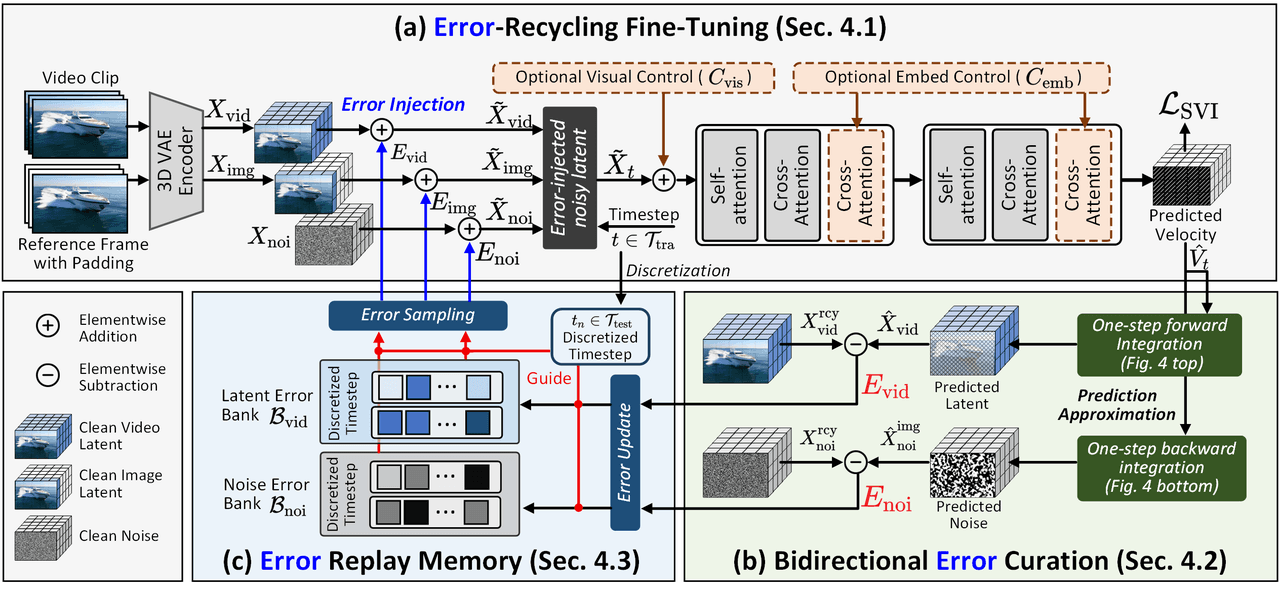
SVI Trainings-Framework. (a) Injektion der selbst erzeugten Fehler des DiT in den Latent-Raum, um die Annahme fehlerfreier Daten zu brechen. (b) Effiziente Berechnung bidirektionaler Fehler mittels einstufiger Vorwärts-/Rückwärtsintegration. (c) Speicherung der Fehler in einem Replay-Memory und dynamisches Resampling zur Wiederverwendung, wodurch ein geschlossener Fehlerüberwachungszyklus entsteht.
SVI unterscheidet zwei Fehlertypen. Der Single-clip Predictive Error ist der Drift pro Clip zwischen dem Denoising-Pfad und der idealen Trajektorie. Der Cross-clip Conditional Error ist der kaskadierende Drift, der entsteht, wenn fehlerbehaftete Referenzbilder in den nächsten Clip einfließen. Error-Recycling injiziert beides, damit das LoRA eine explizite Fehlertoleranz erlernt.
LoRA-Varianten
SVI liefert drei Varianten aus – SVI-Shot für statisches Bild → kurzer Clip, SVI-Dance für menschliche Bewegung (kann auch eine Pose-Sequenz als Input nehmen) und SVI-Film für Videos mit mehreren Shots / Szenenübergängen. Hyperparameter: 81 Frames pro Clip, num_motion_frames ∈ {4, 8, 12}, LoRA-Rang typischerweise 16–64.
Stacking auf TurboWan
Wir montieren das SVI-LoRA auf TurboWan (eine von Atlas optimierte Turbo-Version von Wan) und behalten unser spezialisiertes LoRA für die Style-Kontrolle im Stack. Bei der Inferenz werden mehrere LoRA-Gewichtungen gleichzeitig überlagert.
Basis: TurboWan LoRA 1: spezialisiertes LoRA – Content- / Style-Kontrolle. LoRA 2: SVI-LoRA – Konsistenz langer Videos. Kombiniert: TurboWan-Geschwindigkeit + SVI-Kontinuität für lange Videos + Spicy-Style, alles in einem Inferenz-Durchgang.
Der vollständige Inferenz-Flow ist geradlinig: Encodierung der Referenz in ein Anker-Latent, Verkettung mit dem Motion-Latent und Padding des vorherigen Clips, Ausführen des TurboWan-Denoising, Decodierung, Anhängen und Aktualisierung des Motion-Latents aus dem Ende des frisch generierten Clips. Nach N Iterationen wird alles zu einem Video zusammengefügt.
1. Encodierung des Referenzbildes → Anker-Latent. 2. y = concat(Anker-Latent, Motion-Latent, Padding). 3. Ausführen des 5-Schritte-Denoising von TurboWan, konditioniert auf y und das Text-Embedding. 4. VAE-Dekodierung des Clips und Anhängen an die Ausgabeliste. 5. Setzen des Motion-Latents = Ende (letzte num_motion_frames) des gerade generierten Clips. 6. Wiederholen für N Clips, dann alle miteinander verketten.
Einige Produktionskennzahlen
Standard-Test: ein einzelnes Referenzbild und 3 Prompts, Generierung von ~15s Output (3 Clips × 5s):
| Metrik | Wert |
|---|---|
| Generierte Dauer | 15s (3 Clips) |
| Inferenzzeit pro Clip | ~14s (TurboWan fp8, einzelne GPU) |
| Inferenzzeit gesamt | ~42s |
| Subjekt-Konsistenz | Gut |
Ein Praxisbeispiel: Cat Adventure
Um das Cross-Clip-Verhalten zu veranschaulichen, haben wir einen 15-sekündigen Fall mit einer Referenz und drei Einstellungen durchgeführt. Der Style-Prompt legte einen Pixar-Look mit warmer Beleuchtung fest; der Charakter war ein orangefarbenes getigertes Kätzchen mit großen neugierigen Augen; die drei Einstellungen führten es von einem Fenstersims auf den Gehweg bis hin zum Treffen mit einem Golden Retriever, jeweils mit eigener Kameraführung.

Clip 1 (0–5s): das orangefarbene Pixar-Kätzchen auf einem Fenstersims, während die Kamera langsam aus einer Nahaufnahme zurückfährt. Style und Charakter bleiben über die Frames hinweg stabil.

Clip 2 (5–10s) an der Übergangsgrenze: Das Aussehen des Kätzchens entspricht Clip 1, dann dreht es sich und ändert seine Haltung, während es herunterspringt. Das Motion-Latent hat den Bewegungszustand über die Grenze hinweg übertragen.

Clip 3 (10–15s): ein Golden Retriever wird eingeführt und die Szene wechselt in Richtung eines Innen-/Außenbereichs. Der Pixar-Style des Kätzchens bleibt über alle drei Clips hinweg stabil.
Aggregierte Metriken für den Durchlauf:
| Metrik | Wert |
|---|---|
| Gesamtdauer | 15s (3 Clips × 5s) |
| Gesamtzahl Frames | 240 Frames (16fps) |
| Inferenzzeit gesamt | 33s (TurboWan, einzelne GPU) |
| Time-to-video-Verhältnis | 2,2 s/s |
| Subjekt-Konsistenz | Pixar-orangefarbenes Kätzchen durchgehend stabil |
| Clip-Grenzdiskontinuität | Keine offensichtlichen Jump-Cuts |
Das ist ein 15 Sekunden langes Video in 33 Sekunden auf einer einzelnen GPU, mit konsistentem Subjekt über die Clips hinweg – weit innerhalb der von uns gesetzten Wartezeit von ≤ 60s. In einem internen Test-Set mit 14 Fällen ergaben 9 Fälle keine offensichtlichen Probleme (64% Erfolgsquote).
Die ehrliche abschließende Beobachtung ist, dass bei der Videogenerierung Geschwindigkeit, Länge und Qualität die drei Ecken eines eisernen Dreiecks bilden. Kein einziger Ansatz führt heute in allen drei Bereichen gleichzeitig. Die interessante Arbeit besteht darin, zu entscheiden, welche Ecke man am wenigsten opfern kann, angesichts der heutigen Hardware und des Trainingsbudgets. SVI opfert ein wenig Länge und ein wenig Grenzqualität – und im Gegenzug liefern wir heute lange Videos mit einer Wiedergabetreue der Wan2.2-Klasse auf einer einzigen GPU.






