
Ya conoces esa sensación.
Es tarde. Llevas cuatro revisiones de una campaña de marca. La IA acaba de generar una iluminación perfecta en la toma principal, pero la cara de tu modelo ha cambiado sutilmente por tercera vez esta noche. Misma ropa. Persona diferente. No puedes publicarlo. No puedes arreglarlo. Empiezas de cero.
Para la medianoche, ya no estás editando un vídeo. Estás jugando a la ruleta.
Para cualquiera que intente construir una narrativa con continuidad —una demostración de producto con el mismo modelo en varias tomas, un tutorial con el mismo instructor en distintas escenas, un videoclip con el mismo cantante a través de varios cortes—, la deriva de los personajes ha sido el asesino silencioso de todas las herramientas de vídeo por IA. Es la razón por la que el vídeo con IA ha vivido en el purgatorio de las "demos vistosas" en lugar de volverse comercial.

El 19 de mayo, en el I/O 2026, Gemini Omni de Google demostró que esta era está llegando a su fin.
Toda la promesa se resume en una frase de la página de producto de Google DeepMind: "Cada edición que realizas construye sobre la anterior, manteniendo una escena coherente y consistente".
La demo del violinista de tres pasos que silenciosamente hizo historia
El momento más trascendental del anuncio del I/O no fue la canica rodante. Tampoco fue la escultura de burbujas. Fue un violinista.
Esta es la secuencia exacta que Google mostró en el escenario y publicó en su blog:
- Primer paso: Un vídeo base de un violinista tocando una canción en el escenario.
- Segundo paso: Prompt — "Transporta al violinista al entorno de la imagen". Resultado: el músico se traslada a un nuevo fondo, pero el rostro, la postura, el agarre del arco e incluso el ángulo de la muñeca permanecen idénticos.
- Tercer paso: Otro prompt — "Cambia el ángulo de cámara para que sea sobre el hombro del violinista". Resultado: nuevo encuadre. El mismo violinista. Misma identidad. Misma actuación.
Tres turnos. Un sujeto. Cero deriva.
Si has pasado tiempo con herramientas actuales de vídeo por IA, esto parece un truco. No lo es. Es la primera prueba pública de que el refinamiento multietapa —el flujo de trabajo que cineastas, publicistas y educadores han estado esperando— es técnicamente real y está listo para producción.
Por qué la consistencia multietapa ha sido la herida abierta del vídeo por IA
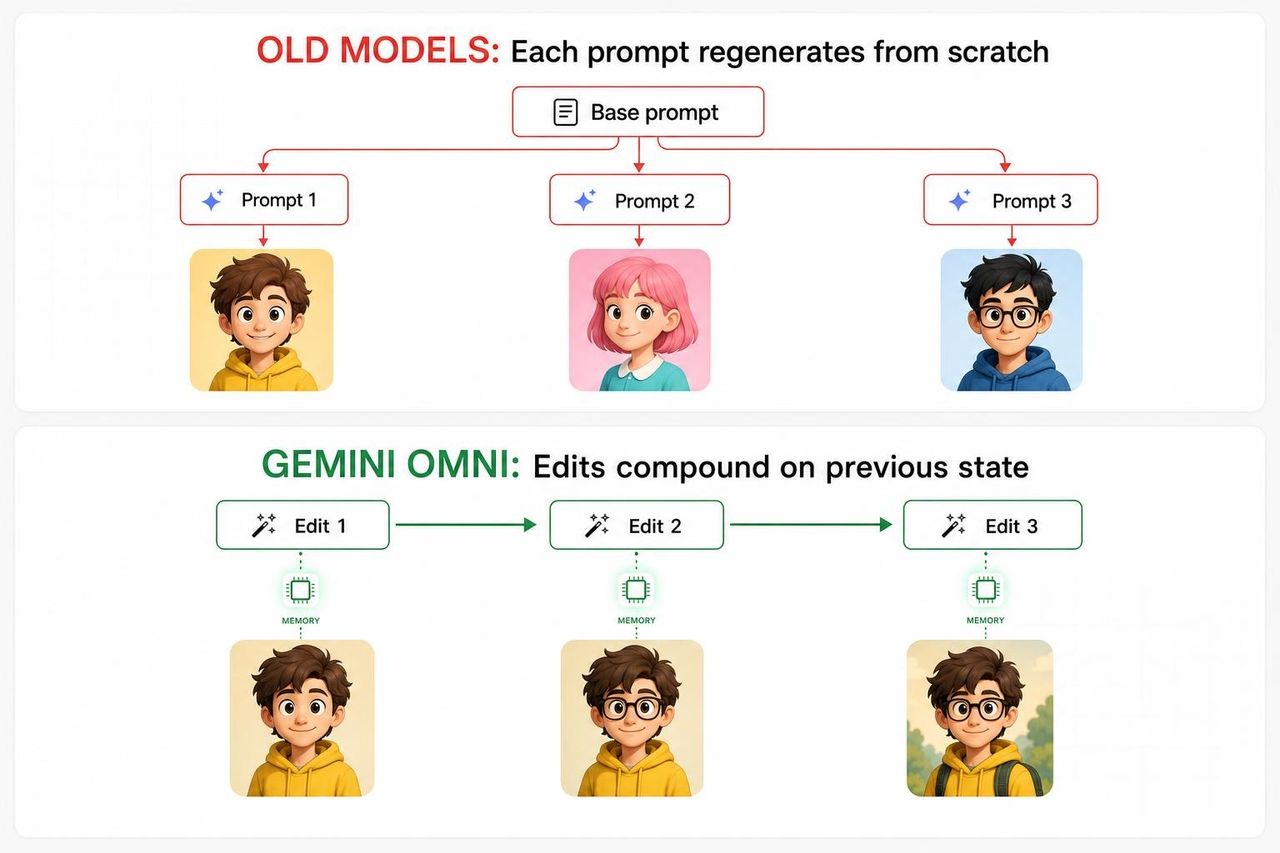
Para entender por qué importa la demo del violinista, debes entender en qué han fallado los demás modelos de vídeo por IA.
En los pipelines generativos tradicionales, cada nuevo prompt esencialmente regenera la escena desde cero, utilizando el prompt original más el nuevo como entradas combinadas. El modelo no tiene una verdadera continuidad interna entre turnos. Los rostros cambian. Los objetos del fondo desaparecen. La iluminación varía. Para el tercer turno, el resultado se ha alejado tanto de la visión original que los creadores se rinden y reinician.
La causa raíz es arquitectónica. La mayoría de los modelos de vídeo fueron entrenados como generadores de un solo paso, no como agentes multietapa. Fueron optimizados para producir un único resultado óptimo a partir de un prompt, no para recordar lo que produjeron anteriormente y refinar a partir de ahí. Pedirles que "editen" era, en la práctica, pedirles que empezaran de nuevo con contexto adicional, y las matemáticas de esa operación producían una deriva acumulada, no un refinamiento acumulado.
El enfoque de Omni es diferente. Ha sido construido como un editor con estado (stateful), lo que significa que cada turno actualiza una representación persistente de la escena en lugar de regenerarla desde cero.
Qué significa realmente que "la escena recuerda"
La prensa tecnológica ha convergido en la misma conclusión.
Decrypt describió el avance con mayor claridad: "Google afirma que Omni puede mantener la consistencia de los mismos personajes, fondos y movimientos incluso después de que los usuarios realicen cambios en un vídeo, algo con lo que muchos modelos de vídeo por IA tienen dificultades".
Android Central destacó el detalle técnico clave: "La compañía también dice que el modelo recuerda comandos previos durante las revisiones de múltiples pasos, lo que podría hacer que la edición iterativa se sienta mucho menos caótica".
TechRadar lo planteó desde una perspectiva cinematográfica: "Los personajes se mantienen reconocibles. Las escenas mantienen la continuidad. El movimiento permanece coherente en lugar de reiniciarse cada vez que cambia un prompt".
Y Phandroid resumió toda la capacidad en cinco palabras: "La escena recuerda lo que ocurrió antes".
Ese es el punto clave. La escena recuerda. Esa propiedad es la diferencia entre el vídeo por IA como juguete y el vídeo por IA como herramienta.
Cómo se compara Omni frente a Sora, Veo y Seedance en cuanto a consistencia
Así es como se comparan los principales modelos de vídeo por IA en cuanto a consistencia multietapa a fecha de mayo de 2026:
| Modelo | Edición multietapa | Refinamiento conversacional | Consistencia de personajes (Reseña) | Estado actual |
| Gemini Omni Flash | Con estado, multietapa | Chat nativo | (3/5) | Disponible (19 mayo 2026) |
| Sora 2 (OpenAI) | Regeneración de un solo paso | Limitado | Descontinuado | App Sora cerrada; API finaliza sept 2026 |
| Veo 3.1 (Google) | Parcial | Solo texto + imagen | Inferior a Omni | Disponible, siendo reemplazado por Omni |
| Seedance 2.0 (ByteDance) | Basado en referencia, no iterativo | Limitado | (4/5) | Disponible; n.º 1 en Artificial Analysis Video Arena |
La lectura honesta: Omni es el único modelo con edición multietapa verdaderamente con estado. Seedance obtiene mejor puntuación en consistencia bruta de personajes aprovechando hasta 9 imágenes de referencia por generación, pero no puede trasladar esa consistencia a lo largo de una sesión de edición. Sora está saliendo del mercado de consumo. Veo está siendo absorbido.
De "regenerar" a "refinar": lo que desbloquea este cambio en el flujo de trabajo

El valor real aquí no es la demo. Es la transformación del flujo de trabajo.
Blockchain.news resumió mejor la implicación comercial: "La edición por lotes permite modificaciones simultáneas en múltiples segmentos de vídeo para acelerar la producción manteniendo estándares de calidad en contenidos generados por IA. Los creadores de cine, publicidad y contenido educativo obtienen ventajas significativas mediante la reducción de costes y una mayor fiabilidad narrativa".
Esa última frase —fiabilidad narrativa— es la parte que debería importar a cualquiera que trabaje en creación de contenido.
Hasta ahora, el vídeo por IA podía entregar un buen clip. No podía entregar una campaña: una serie de clips con el mismo protagonista, los mismos activos de marca y el mismo lenguaje visual. Cada edición era una moneda al aire. Ahora, las ediciones se acumulan.
TechTimes resumió el conjunto de capacidades demostradas como "edición de acciones y objetos en metraje grabado por el usuario, transferencia de estilo entre looks realistas y animados, refinamiento multietapa y generación de contenido explicativo".
Y la reseña práctica de DataCamp confirmó que el comportamiento multietapa se mantuvo en la práctica: "Omni admite edición multietapa, por lo que puedes refinar detalles, entornos y ángulos de cámara paso a paso mientras mantienes la escena consistente".
El cambio en el flujo de trabajo parece pequeño sobre el papel. En la práctica, es enorme: generar → regenerar → regenerar → rendirse se convierte en generar → refinar → refinar → publicar.
Los desarrolladores se están dando cuenta. En el foro chino V2EX, un ingeniero que probó Omni el día del lanzamiento escribió: "La velocidad de generación y la consistencia superaron mis expectativas".
Cuando ingenieros de IA y creadores de primera línea llegan a la misma conclusión a las pocas horas del lanzamiento, estás ante un cambio real de capacidad, no solo marketing.
El escepticismo honesto: Omni aún no es perfecto
Antes de que alguien declare que el problema de la consistencia está resuelto, aquí está la perspectiva realista.
Un reseñador en AI Analytics Diaries en Medium enfrentó a Omni contra Seedance 2.0 de ByteDance y otorgó a la consistencia de personajes de Omni un 3 sobre 5.
La frase que merece estar en el monitor de todo gestor de producto de vídeo por IA: "Ambos modelos tienen dificultades con la consistencia de personajes en múltiples cortes; esta sigue siendo la herida abierta del vídeo por IA".
Traducción: Omni es materialmente mejor que cualquier otro modelo público en el refinamiento multietapa dentro de una única sesión de edición. Todavía no es un problema resuelto en toda la categoría.
¿Dónde está la brecha restante?
- La consistencia multietapa en una sola escena funciona extremadamente bien (la demo del violinista).
- La consistencia entre cortes (mismo personaje, diferentes escenas, diferentes iluminaciones, diferentes encuadres) sigue siendo imperfecta.
- Los detalles sutiles —rasgos faciales, articulación de las manos, texturas específicas de ropa— aún pueden variar a través de muchas ediciones.
- El límite actual de 10 segundos de Omni Flash significa que la consistencia multietapa aún no se ha probado a fondo en trabajos narrativos de larga duración.
Para el 80% de los casos de uso —refinamiento de una sola escena, contenido para redes sociales, recursos de marketing—, Omni ya es lo suficientemente bueno como para publicar. Para el 20% restante —trabajos de nivel cinematográfico donde la continuidad de los personajes debe sobrevivir a una secuencia de 30 tomas—, todavía se requiere un proceso de limpieza editorial.
Lo que cambia realmente, industria por industria
Si la consistencia multietapa está ahora resuelta (o casi resuelta en una sola sesión), esto es lo que se desbloquea:
Para publicistas de marca: Continuidad de campaña. Una marca de moda puede finalmente generar diez variaciones del mismo modelo principal en diez entornos, sin volver a rodar, sin buscar nuevos talentos y sin pagar por diez retoques manuales. Las matemáticas de la producción creativa cambian en un orden de magnitud.
Para educadores y creadores de tutoriales: Consistencia en series. Un único presentador generado por IA puede conducir un curso completo —del episodio uno al doce— sin que la audiencia note que es sintético. El problema de la "cara consistente a través del contenido" mató a los educadores por IA durante dos años. Se acaba de solucionar.
Para cineastas: Previsualización a escala. Mismo actor a través de múltiples propuestas de escena, múltiples esquemas de iluminación y múltiples ángulos de cámara, todo generado en una sola sesión y refinable de forma iterativa. La brecha entre "tengo una idea" y "puedo enseñársela al director" se reduce de días a minutos.
Para equipos de comercio electrónico: Fotos principales de productos que coinciden entre variaciones de listado. Mismo modelo, seis atuendos, fotos de estilo de vida, fotos de estudio, fotos en entorno; todo consistente, todo publicable, todo generado desde la misma sesión multietapa.
Para desarrolladores de juegos: NPC que parecen el mismo personaje en diferentes escenas cinemáticas. El talón de Aquiles de la IA en juegos ha sido que el protagonista cambiaba sutilmente entre escenas. La edición con estado de Omni hace que el bloqueo de personajes sea comercialmente viable.
La tensión de la procedencia: las falsificaciones consistentes son más difíciles de detectar
Existe una implicación más oscura en este avance que vale la pena mencionar directamente.
Una mejor consistencia multietapa significa falsificaciones más difíciles de detectar. Los "indicadores" clásicos de que algo ha sido generado por IA —un rostro que cambia entre cortes, manos que varían de forma, colores de cabello que derivan— son precisamente lo que soluciona la consistencia. A medida que Omni y sus sucesores mejoran en la continuidad interna, la brecha entre "obviamente sintético" e "indistinguible de la realidad" se cierra rápidamente.
Esta es precisamente la razón por la que cada clip generado por Omni se publica con la marca de agua invisible SynthID de Google y las Credenciales de Contenido C2PA integradas en el momento de la generación. Verificables dentro de la aplicación Gemini, Chrome y el buscador. No es opcional. No es una función que puedas desactivar.
Es también por lo que Google decidió no incluir la edición de voz y audio en vídeos existentes: "Seguimos trabajando para probar esto y entender mejor cómo podemos llevar esta capacidad a los usuarios de manera responsable". Traducción: el riesgo de deepfake de un rostro consistente + una voz modificada es demasiado alto para lanzarlo sin salvaguardas implementadas.
Para marcas y creadores, el cálculo está cambiando. A medida que la detección humana de contenido "falso" se vuelve poco fiable, la procedencia criptográfica se convierte en el nuevo estándar para la autenticidad del contenido. Cada victoria en consistencia viene acompañada de una obligación de procedencia.
El nuevo cuello de botella no es la calidad. Es la dispersión de modelos.
Esto es lo que significa estratégicamente para cualquiera que construya productos sobre vídeo por IA.
La brecha de capacidades entre los modelos líderes se está cerrando rápido, y fragmentando al mismo tiempo. A mediados de 2026:
- Gemini Omni lidera en consistencia multietapa y edición conversacional.
- Seedance 2.0 lidera en movimiento cinematográfico y animación estilizada, con una consistencia de personajes basada en referencias más sólida.
- Otros especialistas lideran en generación de larga duración, control detallado de personajes, sincronización de audio o procesamiento por lotes de bajo coste.
El mejor modelo en consistencia este trimestre probablemente no sea el mejor en movimiento cinematográfico. El modelo con las mejores físicas hoy no será el de mejor sincronización de audio dentro de seis meses. Y todos ellos se lanzan con su propio SDK, flujo de autenticación, plan de precios, peculiaridades de límites de tasa y términos contractuales. Tu equipo puede desperdiciar fácilmente un sprint de ingeniería por integración, y otro por cada descontinuación.
Este es exactamente el problema de fragmentación que Atlas Cloud fue diseñado para resolver. Ofrecemos a los desarrolladores un único punto de acceso unificado para más de 300 modelos: cada modelo fundacional importante, los lanzamientos de código abierto líderes y los especialistas de rápido movimiento en imagen, vídeo, audio y razonamiento. El acceso a Gemini Omni llegará a Atlas Cloud en las próximas semanas, por lo que en el momento en que estés listo para cambiar tu stack y probarlo, la integración ya estará hecha para ti.
Lo que eso significa en la práctica para tu equipo:
- Cambia de modelo con una sola línea de código — sin reescribir integraciones de SDK cada vez que sale un nuevo estándar de la industria (SOTA).
- Ejecuta evaluaciones comparativas con prompts idénticos — descubre qué modelo gana realmente para tu caso de uso específico antes de asignar presupuesto.
- Publica con el modelo más potente para cada capacidad — el líder en consistencia multietapa hoy, el líder en movimiento cinematográfico mañana, el líder en eficiencia de costes el próximo trimestre.
- Un único panel para facturación, observabilidad y límites de tasa — en lugar de doce cuentas separadas para gestionar.
Para los desarrolladores que lanzan productos de vídeo por IA en 2026, la decisión arquitectónica inteligente no es "apostar por Omni". Es "construir sobre una capa de abstracción que te permita cambiar a lo que gane después". Cuando Gemini Omni llegue a Atlas Cloud, podrás probarlo contra Seedance, contra el próximo modelo revolucionario y contra lo que venga después, sin cambiar una sola línea de código de integración.
En un mercado donde la consistencia, la física, el movimiento cinematográfico y la fidelidad de audio están liderados por modelos diferentes, encerrarse en uno solo es la peor deuda técnica que se puede adquirir. Atlas Cloud es la capa de abstracción que convierte esa fragmentación de un lastre en una ventaja.
Una API unificada para la generación de vídeo de producción
Mientras Google despliega Gemini Omni Flash dentro de la aplicación Gemini y Google Flow para usuarios finales, los equipos de producto que desean integrar el mismo motor de vídeo multimodal en sus propios flujos de trabajo necesitan una capa de API estable y predecible.
Atlas Cloud ofrece Gemini Omni Flash a través de una API unificada y compatible con OpenAI, junto con más de 300 modelos de imagen, vídeo y LLM, para que puedas integrar el modelo multimodal nativo de Google sin tener que gestionar cuentas de proveedores, portales de facturación o SDKs por separado.
Ambas variantes de Gemini Omni Flash están disponibles en Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Mejor para | Entradas | Resolución | Duración | Precio inicial |
| Gemini Omni Flash Text-to-Video (Developer) | Generación cinematográfica guiada por prompt | Texto (hasta 20.000 carácteres) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
| Gemini Omni Flash Image-to-Video (Developer) | Vídeo con sujeto consistente desde referencias reales | Texto + hasta 7 imágenes de ref. | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
Inicio rápido: genera un vídeo con Gemini Omni Flash en 5 líneas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
La API devuelve un ID de predicción inmediatamente; consulta /api/v1/model/prediction/{id} para obtener la URL del MP4 renderizado. El esquema completo, muestras de código en 7 lenguajes y un Playground sin código están disponibles en las páginas de los modelos vinculadas anteriormente.
Perspectivas clave
La razón por la que la consistencia multietapa importa no es la demo. Es lo que desbloquea.
Durante cinco años, cada conversación sobre "cuándo se volverá comercial el vídeo por IA" chocaba con el mismo muro: el momento en que los modelos puedan mantener a un personaje consistente a través de ediciones. Ese muro acaba de moverse.
La demo del violinista no es un truco. Es la primera vez que un laboratorio importante ha puesto un flujo de trabajo de edición multietapa real y funcional sobre el escenario. La próxima vez que un equipo de marketing pida a una herramienta de vídeo por IA que produzca seis clips del mismo producto en seis escenarios diferentes, deberían esperar seis resultados utilizables, no seis rostros sin relación alguna.






