Google lanzó Gemini Omni en I/O 2026: un modelo multimodal que edita video mediante conversaciones en lenguaje natural, sin necesidad de líneas de tiempo ni fotogramas clave. Las demos virales (la escultura de burbujas, el espejo líquido, el violinista) demuestran el verdadero cambio: no se trata solo de texto a video, sino de texto para editar el video que ya tienes. Es el momento "cámara del iPhone" para la creación de video. La voz, la edición de audio y una versión Pro están notablemente ausentes, y eso es deliberado.
Es la 1 a. m. Llevas cuatro horas editando un clip de 30 segundos. Tu archivo de proyecto tiene 47 capas. Has arrastrado fotogramas clave hasta que te duele la muñeca. El cliente acaba de enviar un mensaje: "¿podemos probar con una iluminación más cálida?". Y tú, como profesional, estás a punto de empezar de cero.
Ese era el trabajo. Ese era el trabajo.
El 19 de mayo de 2026, Google lo retiró silenciosamente.
En I/O 2026, la compañía anunció Gemini Omni, un modelo multimodal que convierte la edición de video en algo que la mayoría pensábamos que estaba a una década de distancia: una conversación normal.
La promesa central: deja de manipular el video. Empieza a hablar con él.
Aquí tienes todo el concepto en una frase: ya no manipulas el video, le dices lo que quieres.
El anuncio de Google lo dice sin rodeos: "Cada instrucción se basa en la anterior. Tus personajes mantienen la coherencia, la física se mantiene y la escena recuerda lo que ocurrió antes".
Esto no es una actualización de Veo. La página de producto de Google DeepMind lo define mejor: "Piensa en Gemini Omni como Nano Banana, pero para video". El año pasado, Nano Banana hizo que la edición de fotos fuera tan fácil como escribir lo que deseabas. Ahora, Omni lo hace para imágenes en movimiento.
El primer modelo de la familia, Gemini Omni Flash, ya está disponible en la aplicación Gemini, Google Flow y YouTube Shorts.
Y aquí está la frase que debería cambiar tu forma de pensar sobre esta categoría: en la entrevista de TechCrunch con el equipo de DeepMind, el ingeniero de investigación Gabe Barth-Maron describió lo que la gente está creando con Omni como "memes personalizados".
Esa es la tesis. La creación de video acaba de pasar de ser un oficio a ser una forma de expresión; la misma migración que hizo la fotografía cuando los iPhones acabaron con el dominio de las cámaras DSLR.
Las demos que están rompiendo Twitter
Puedes leer material de marketing todo el día. Lo que vendió este lanzamiento fueron las demos. Tres están en todas partes ahora mismo:
- La escultura de burbujas. Le das a Omni un clip de una escultura de piedra, escribes "haz que la escultura sea de burbujas" y el siguiente render mantiene la misma composición, la misma iluminación y las mismas sombras, pero la escultura ahora es de jabón translúcido que atrapa la luz ambiental.
- El espejo líquido. Una mano toca un espejo; el prompt le pide a Omni que "haga que el espejo ondee maravillosamente como si fuera líquido y que el brazo de la persona se convierta en material de espejo reflectante". Como documentó Windows Report, las ondas se propagan físicamente hacia afuera y el cromo del brazo refleja la habitación real.
- Las ediciones encadenadas. La demo del violinista de Google muestra a un mismo sujeto en tres rondas: escenario → entorno transportado → ángulo de cámara sobre el hombro. Tres ediciones. Una persona. Rostro, postura, agarre del instrumento: todo es consistente.

Esto no es texto a video. Es texto para editar el video que ya tienes. La distinción parece pequeña. Cambia todo.
Por qué los creadores están perdiendo la cabeza
La razón por la que esto impacta más que otros lanzamientos de modelos es simple: Omni elimina el peor bucle del video generativo.
Viejo bucle: generar → odiarlo → reescribir todo el prompt → esperar 90 segundos → sigue siendo malo → repetir.
Nuevo bucle: generar → "cambia la iluminación a hora dorada" → listo → "ahora ralentiza el movimiento de cámara" → listo.
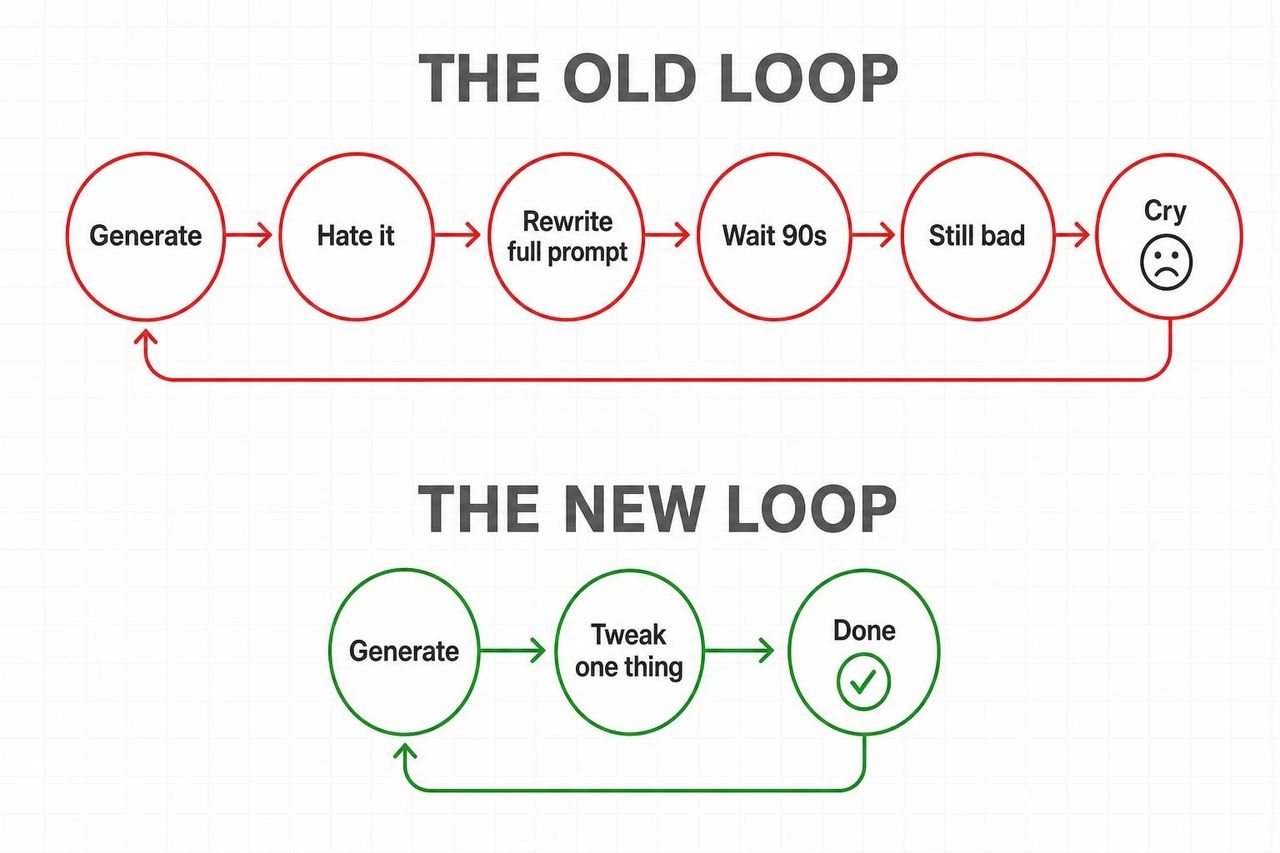
Android Central no suavizó el veredicto: "Gemini Omni podría hacer que las aplicaciones de edición de video tradicionales parezcan antiguas". TechRadar señaló lo mismo con más matices, destacando que el movimiento ahora permanece coherente entre ediciones en lugar de reiniciarse con cada prompt.
Los desarrolladores ya se están moviendo. En el foro de desarrolladores V2EX, un desarrollador chino lo probó el día del lanzamiento y publicó: "modificación basada en chat de objetos dentro de un video; este tipo de interacción es claramente la dirección del futuro. La velocidad y la consistencia superaron mis expectativas". En X, el inmunólogo y comentarista de IA Dr. Derya Unutmaz tuiteó a los pocos minutos de la presentación: "¡Guau! Google DeepMind acaba de lanzar una nueva e increíble IA multimodal llamada Gemini Omni. ¡Los videos se ven súper bien! ¡Debo probarlo lo antes posible!".
Cuando la inteligencia de la IA en Twitter y los foros de desarrolladores chinos coinciden en cuestión de horas, estamos ante un punto de inflexión real.
Donde Google se está conteniendo discretamente
Sería irresponsable escribir una carta de amor sin los asteriscos.

Engadget señaló el elefante en la habitación: "el principal problema con Veo 3.1 y otras aplicaciones de generación de video es que el video tiene un aspecto de 'valle inquietante' y a menudo es odiado por los usuarios finales. Será interesante ver si la calidad de salida coincide con las afirmaciones entusiastas de Google".
Y las pruebas prácticas de DataCamp ya mostraron un error de física real: una catapulta que lanzaba su carga hacia atrás. El revisor señaló que al modelo aún le faltan puntuaciones de referencia publicadas, por lo que la verificación independiente tardará semanas.
También hay una omisión deliberada: la edición de voz y audio dentro de videos existentes. Como la propia Google reconoció, la compañía está "trabajando todavía para probar esto y entender mejor cómo podemos ofrecer esta capacidad a los usuarios de manera responsable". Traducción: el riesgo de deepfake es real y están manteniendo la capacidad más peligrosa tras bambalinas.
Cada clip de Omni incluye la marca de agua invisible SynthID de Google, además de las credenciales de contenido C2PA: una procedencia verificable dentro de la aplicación Gemini, Chrome y la Búsqueda. Eso no es opcional. Eso es lo mínimo necesario ahora.
Lo que esto significa realmente para tu flujo de trabajo
Quita el bombo publicitario y te queda algo genuinamente nuevo:
- La herramienta es la conversación. Sin línea de tiempo, sin capas, sin fotogramas clave. Solo palabras.
- El bucle de retroalimentación se colapsa. Lo que antes eran regeneraciones de 90 segundos se convierte en ajustes de 10 segundos.
- La ventaja competitiva profesional se reduce. Cuando cualquiera con buen gusto puede iterar en un video tan rápido como en un mensaje de Slack, el cuello de botella pasa de la ejecución a las ideas.
Para equipos de marketing, creadores independientes, educadores, cualquiera que alguna vez haya necesitado "solo un clip rápido de 10 segundos", este es el punto de inflexión. No porque el modelo sea perfecto, sino porque el patrón de interacción finalmente es el correcto.
La edición de video del futuro no necesitará software. Necesitará vocabulario.
Una API unificada para la producción de video generativo
Mientras Google despliega Gemini Omni Flash en la aplicación Gemini y Google Flow para usuarios finales, los desarrolladores y equipos de producto que quieran integrar el mismo motor de video multimodal en sus propios flujos de trabajo necesitan una capa de API estable y predecible.
Atlas Cloud ofrece Gemini Omni Flash a través de una API unificada y compatible con OpenAI, junto con más de 300 modelos de imagen, video y LLM; de modo que puedes integrar el modelo multimodal nativo de Google sin tener que gestionar cuentas de proveedores, portales de facturación o SDKs por separado.
Ambas variantes de Gemini Omni Flash están disponibles en Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Ideal para | Entradas | Resolución | Duración | Precio inicial |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | Generación cinemática pura por prompt | Texto (hasta 20 000 caracteres) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
| Gemini Omni Flash Image-to-Video (Developer) | Video consistente con referencias reales | Texto + hasta 7 imágenes de referencia | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
Inicio rápido: genera un video con Gemini Omni Flash en 5 líneas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
La API devuelve un ID de predicción de inmediato; consulta /api/v1/model/prediction/{id} para obtener la URL del MP4 generado. El esquema completo, ejemplos de código en 7 idiomas y un Playground sin código están disponibles en las páginas de modelos vinculadas anteriormente.
Una última cosa: para cualquiera que realmente esté construyendo con esto
Esta es la realidad incómoda detrás de cada lanzamiento de modelo como este: para el próximo trimestre, llegarán otros tres anuncios del "mejor modelo de video del mundo". Cada uno tendrá un SDK diferente, un flujo de autenticación diferente, una gestión de límites de velocidad diferente y un modelo de precios diferente. Tu equipo perderá una semana integrando cada uno. Y luego otra semana eliminando el anterior.
Ese es exactamente el problema que resuelve Atlas Cloud.
Brindamos a los desarrolladores un punto de acceso a más de 300 modelos: todos los modelos fundamentales principales, los lanzamientos de código abierto líderes y los especialistas en imagen, video y razonamiento de rápido avance. Cambia de modelo con una sola línea de código. Realiza comparativas lado a lado sin necesidad de volver a integrar SDKs. Implementa el modelo que sea tendencia hoy y cambia al que lo sea el próximo mes, sin tener que reescribir nada.
Porque lo único seguro sobre la IA en este momento es que la clasificación cambia todos los martes. Prepárate para ello.






