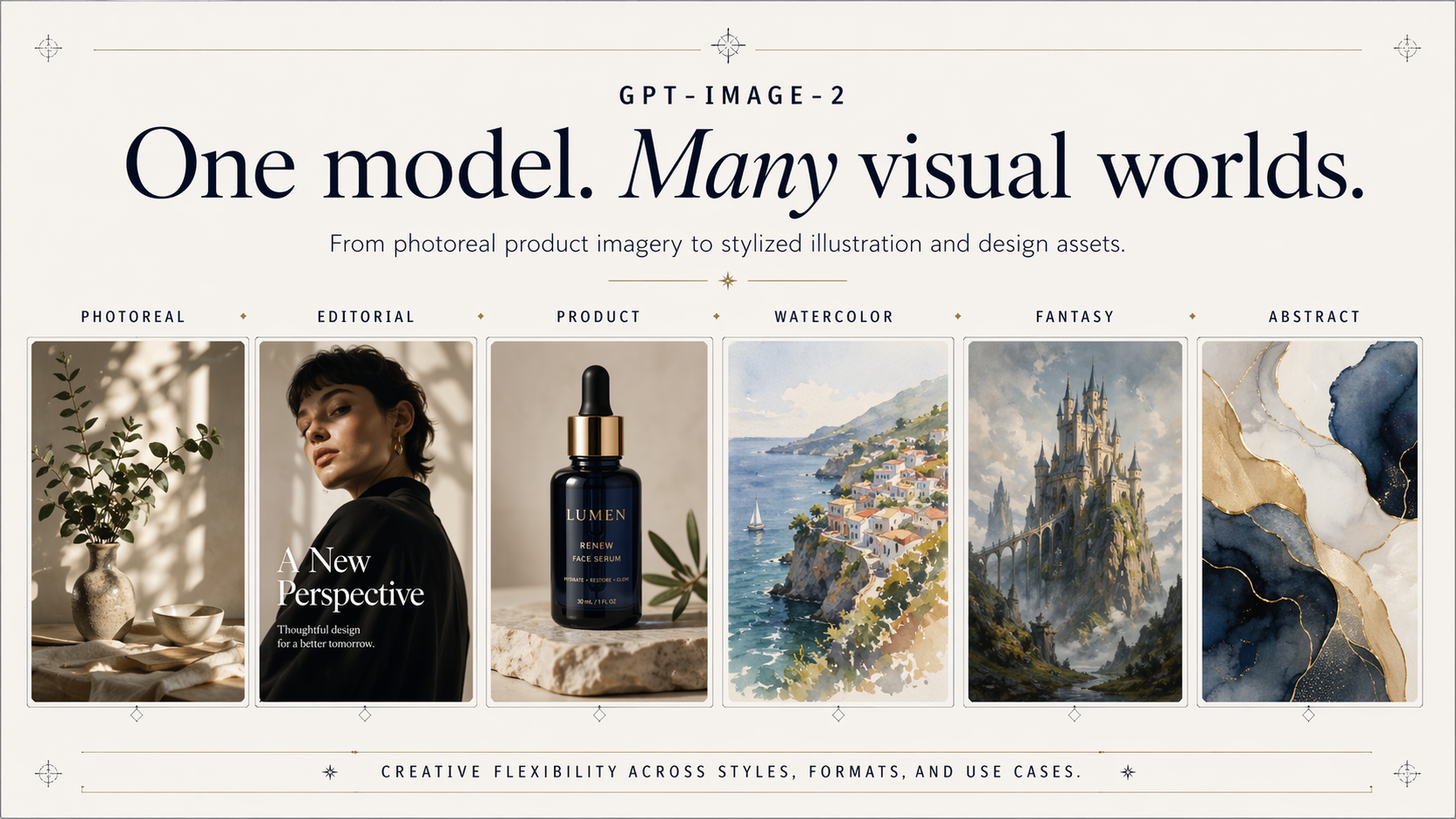

GPT Image 2 API for Accurate In-Image Text
La API de GPT Image 2 ofrece a los desarrolladores acceso al último modelo de imágenes de OpenAI, el sucesor de GPT Image 1.5. Genera y edita imágenes con una representación de texto precisa en caracteres latinos y CJK, además de una sólida composición para carteles, maquetas e infografías. En Atlas Cloud, puede acceder a ella a través de una API unificada junto con más de 300 modelos, con créditos gratuitos, un tiempo de actividad del 99,99% y sin necesidad de verificación de organización de OpenAI.
Explorar Modelos Líderes
Atlas Cloud le proporciona los últimos modelos creativos líderes en la industria.




Velocidad máxima de GPT Image 2 API
Compare los endpoints de la API de GPT Image 2 en toda la familia, con opciones de texto a imagen y edición para GPT Image 2, 1.5, 1 y Mini, para que pueda ajustar el costo y la calidad a cada trabajo mediante una única integración.
| Modalidad | Descripción |
|---|---|
| GPT Image-1 T2I API(Text to Image) | La API Text to Image de GPT Image-1 permite a los desarrolladores transformar indicaciones de texto en imágenes asombrosas y fotorrealistas con un nivel de detalle excepcional. Al combinar el razonamiento de GPT-4 Turbo con una síntesis visual de clase DALL·E, ofrece una fidelidad a las indicaciones líder en la industria y capacidades de composición compleja para la producción de imágenes de nivel profesional. |
| GPT Image-1 Edit API(Image to Image) | La GPT Image-1 Edit API permite a los desarrolladores transformar imágenes existentes en obras maestras refinadas o reimaginadas con una consistencia perfecta. Al utilizar la comprensión multimodal, genera transferencias estilísticas precisas, composiciones contextuales y modificaciones específicas para la iteración de activos de calidad profesional. |
| GPT Image-1.5 T2I API(Text to Image) | La API Text to Image de GPT Image-1.5 permite a los desarrolladores transformar indicaciones de texto en recursos visuales de alta calidad a un costo optimizado. Al aprovechar la arquitectura impulsada por GPT, ofrece una sólida comprensión de las indicaciones y fidelidad visual para flujos de trabajo de producción equilibrados. |
| GPT Image-1.5 Edit API(Image to Image) | La GPT Image-1.5 Edit API permite a los desarrolladores perfeccionar los activos existentes con modificaciones precisas. Al admitir el control de input_fidelity, facilita ajustes precisos mientras preserva elementos esenciales como rostros y logotipos. |
| GPT Image-1 Mini T2I API(Text to Image) | La GPT Image-1 Mini Text to Image API proporciona a los desarrolladores la generación de imágenes más rentable de la familia. Al aprovechar la arquitectura GPT-5, ofrece resultados de calidad profesional al menor costo por imagen para la producción de contenido de gran volumen. |
| GPT Image-1 Mini Edit API(Image to Image) | La GPT Image-1 Mini Edit API permite a los desarrolladores transformar imágenes existentes con capacidades de edición optimizadas. Al proporcionar funciones de edición esenciales a un costo mínimo, facilita la iteración rápida y los flujos de trabajo de producción de contenido. |
Características principales de GPT Image 2
Explore lo que puede hacer la GPT Image 2 API, desde texto en imagen preciso en alfabetos latinos y CJK, hasta renderizado fotorrealista, edición basada en máscaras y composición con múltiples referencias.

Renderizado fotorrealista
GPT Image 2 ofrece resultados fotorrealistas en gráficos de marketing, contenido visual de productos, contenido para redes sociales y maquetas, donde la precisión es tan importante como la calidad visual. Muestra una verdadera comprensión de la física, la iluminación y las propiedades de los materiales, con colores neutros y precisos en todo tipo de escenas.

Texto en imagen casi perfecto
GPT Image 2 renderiza texto escrito correctamente y ubicado de forma natural dentro de las imágenes, desde letreros y etiquetas de UI hasta carteles. Produce de manera confiable gráficos de marketing, creatividades publicitarias y encabezados de correo electrónico con texto preciso a gran escala.

Control avanzado de composición
GPT Image 2 maneja escenas complejas con múltiples objetos sin los errores de oclusión y posicionamiento de los modelos anteriores. Sigue prompts largos y de varias partes mientras conserva la composición, la iluminación y los detalles finos.

Consistencia del Personaje
GPT Image 2 mantiene la identidad del personaje, los accesorios y la iluminación de manera consistente en múltiples generaciones. Esta consistencia del sujeto se mantiene en composiciones de múltiples elementos, lo que lo hace confiable para conjuntos de variantes y trabajos en serie.

Soporte de texto multilingüe
GPT Image 2 renderiza caracteres CJK con glifos precisos y trazos claros, una clara mejora respecto a la debilidad de los modelos anteriores con escrituras no latinas. Admite un potente renderizado de texto tanto en idiomas latinos como CJK.

Edición de imágenes con soporte para máscaras
La Edit API admite inpainting y outpainting precisos a través de imágenes de máscara, lo que le permite modificar regiones específicas mientras cada píxel no relacionado permanece intacto. Esto hace que la GPT Image 2 API sea confiable para retoques, eliminación de objetos y limpieza de composición controlada.

Composición multireferencia
La GPT Image 2 API puede combinar varias imágenes de entrada en un resultado coherente, guiado por un prompt de lenguaje natural. Esto admite la colocación de productos, la transferencia de estilo y la consistencia de los personajes en un conjunto de elementos visuales generados.

Mockups de UI e Interfaz
GPT Image 2 genera maquetas de UI e interfaces de aplicaciones con texto de botones escrito correctamente y una estructura de diseño limpia. Es ideal para pantallas conceptuales rápidas y vistas previas de diseño donde la legibilidad del texto en pantalla es importante.

Fuerte Adherencia al Prompt
La API de GPT Image 2 sigue prompts largos y de múltiples partes con un cumplimiento confiable de las instrucciones, preservando la composición, las opciones de iluminación y los detalles finos. El resultado es un menor número de reintentos y resultados fiables para los flujos de trabajo de producción.
Comparación entre GPT Image 2 y otros SOTA
Create a Japanese-language infographic titled "うちの部署のメンバー スペック分析" (Our Department Member Spec Analysis) with subtitle "個性豊かなプロ集団(たぶん)". Layout as a 2x3 grid of six member cards on a clean white background with pastel accents and star decorations. Each card features a cute chibi-style cartoon avatar and includes: member name and role in Japanese, a radar chart or bar chart showing their stats, bullet-point strengths and weaknesses in Japanese. Add a summary section at the bottom with overall team evaluation, a team compatibility graph placeholder, and a final takeaway note. Cheerful office illustration style, soft rounded UI elements, kawaii aesthetic, highly legible Japanese typography, no watermark.

GPT Image 2

Grok Imagine
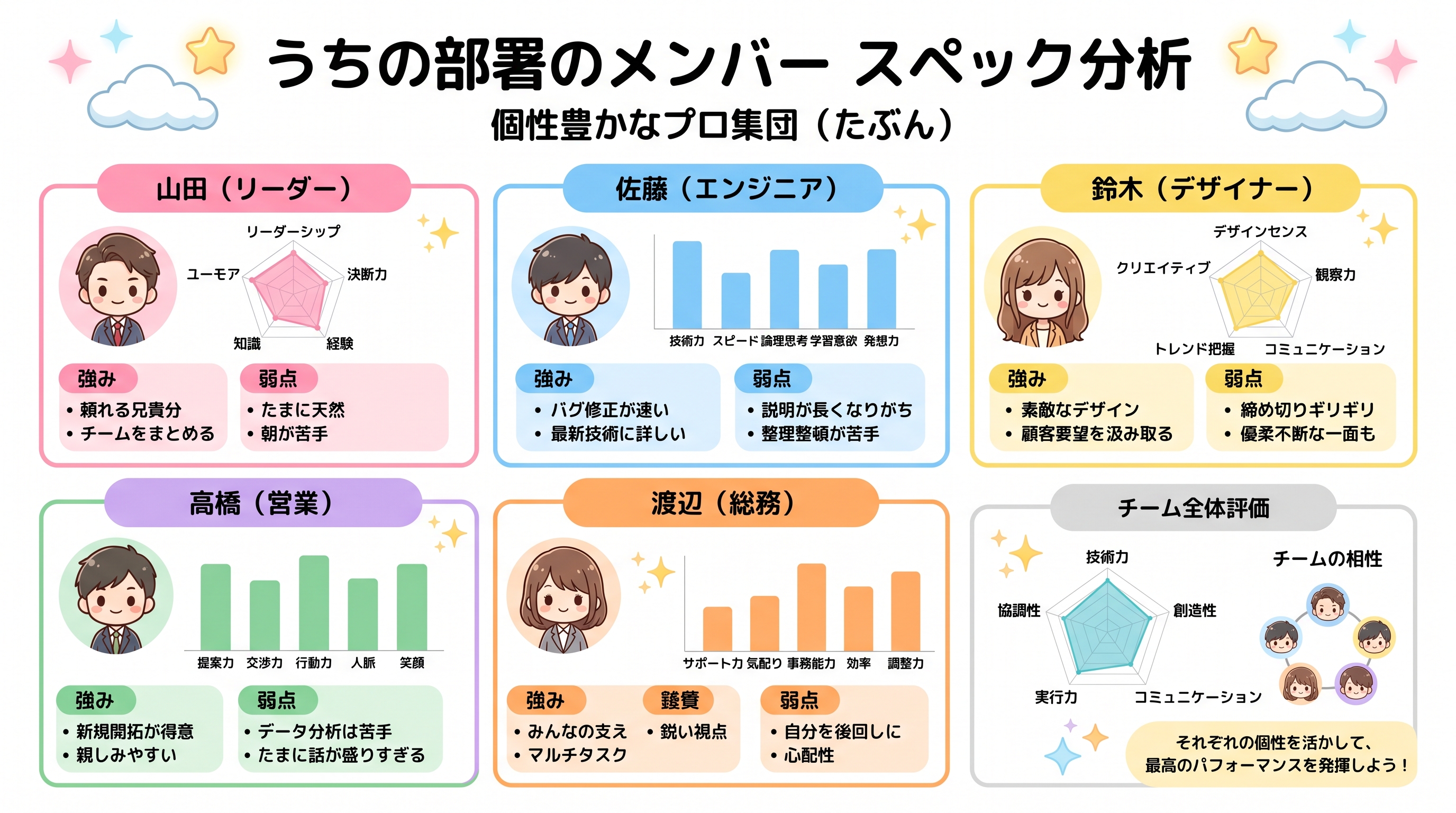
Nano Banana 2
Lo que puede hacer con GPT Image 2 API
Desde creatividades publicitarias y recursos visuales de productos hasta mockups de UI, contenido localizado e infografías editoriales, descubra lo que la GPT Image 2 API puede construir.
Publicidad y Marketing Profesional
Se espera que GPT Image 2 sea particularmente fuerte para la automatización de marketing: generando gráficos para redes sociales, creatividades publicitarias y encabezados de correo electrónico con texto preciso y a gran escala. En combinación con MindStudio, gracias a su cumplimiento casi perfecto de los prompts y su fotorrealismo mejorado, su objetivo es crear activos de campañas listos para producción sin necesidad de sesiones fotográficas.
Comercio electrónico y visualización de productos
GPT Image 2 está siendo muy discutido en el contexto de los elementos visuales de productos y el contenido social, donde la precisión importa tanto como la calidad visual. Dreamina Las mejoras en la consistencia de los personajes y la preservación de la imagen lo hacen muy adecuado para escalar catálogos de productos, generar imágenes de estilo de vida y producir conjuntos de variantes consistentes.
Mockups de UI y Diseño de Producto
Los mockups de UI y las interfaces de aplicaciones — con texto de botones escrito correctamente y una estructura de diseño limpia — se encuentran entre los casos de uso que los primeros evaluadores destacaron específicamente. Los equipos de productos y diseñadores de Dzine pueden utilizar GPT Image 2 para mockups de conceptos rápidos, elementos visuales para páginas de aterrizaje y recursos para presentaciones.
Visualización arquitectónica y de interiores
Los renders arquitectónicos y de interiores con profundidad mejorada y realismo de materiales se encuentran entre los puntos fuertes esperados de GPT Image 2. Las mejoras de fotorrealismo y composición de Dzine lo convierten en una herramienta práctica para presentaciones de diseño y marketing inmobiliario.
Contenido multilingüe y localizado
La API de GPT Image 2 renderiza texto preciso en chino, japonés, coreano y otras escrituras, de modo que puede producir cartelería, publicaciones para redes sociales y materiales de marca que antes requerían la superposición manual de texto. Esto hace que sea práctico localizar campañas y crear gráficos específicos para cada región a gran escala.
Publicación, Edición e Infografías
La GPT Image 2 API genera portadas de libros, artículos ilustrados, infografías y material visual educativo donde el texto legible en la imagen es un requisito indispensable. Con una tipografía precisa y una generación estructurada para gráficos, diagramas y explicaciones, transforma información compleja en gráficos claros y fáciles de compartir.
Comparación de Modelos
Vea cómo se comparan los modelos de diferentes proveedores — compare rendimiento, precios y fortalezas únicas para tomar una decisión informada.
| Modelo | Límite de imágenes de referencia | Número de salidas | Resolución | Relación de aspecto |
|---|---|---|---|---|
| GPT Image-2 | 16 | 1-10 | Up to 2048×2048 (2K) native;4K via scaling | 1:1, 2:3, 3:2 |
| GPT Image-1.5 | 10 | 1 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| GPT Image-1 | 4 | 1~10 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| GPT Image-1 Mini | 4 | 1~10 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| Nano Banana 2 | 14 | 1 | 512×512, 1024×1024, 2048×2048, 4096×4096 (0.5K/1K/2K/4K) | 1:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9, 1:4, 4:1, 1:8, 8:1 |
| Grok Imagine | 1 | 1-10 | 1024×1024 (1K), 2048×2048 (2K) | 1:1, 3:2, 2:3, 16:9, 9:16 |
Cómo usar GPT Image 2 en Atlas Cloud
Empieza en minutos — sigue estos sencillos pasos para integrar y desplegar modelos a través de la plataforma de Atlas Cloud.
Crea una cuenta en Atlas Cloud
Regístrate en atlascloud.ai y completa la verificación. Los nuevos usuarios reciben créditos gratuitos para explorar la plataforma y probar modelos.
Por Qué Usar GPT Image 2 en Atlas Cloud
Combina modelos avanzados de GPT Image 2 con la plataforma acelerada por GPU de Atlas Cloud, proporcionando rendimiento, escalabilidad y experiencia de desarrollo incomparables.
Rendimiento y Flexibilidad
Baja Latencia:
Inferencia optimizada por GPU para respuestas en tiempo real.
API Unificada:
Una sola integración para acceder a GPT Image 2, GPT, Gemini y DeepSeek.
Precios Transparentes:
Facturación por Token, soporta modo Serverless.
Empresa y Escala
Experiencia del Desarrollador:
SDK, análisis de datos, herramientas de ajuste fino y plantillas todo en uno.
Confiabilidad:
99.99% de disponibilidad, control de permisos RBAC, registros de cumplimiento.
Seguridad y Cumplimiento:
Certificación SOC 2 Type II, cumplimiento HIPAA, soberanía de datos en EE.UU.
Preguntas frecuentes de los usuarios sobre GPT Image 2 API
La API de GPT Image 2 ofrece a los desarrolladores acceso programático a GPT Image 2 de OpenAI, el modelo de imágenes lanzado en abril de 2026 como sucesor de GPT Image 1.5 y reemplazo de DALL-E 3. Genera y edita imágenes a partir de entradas de texto e imagen, con texto en imagen preciso, soporte multilingüe y un fuerte fotorrealismo. En Atlas Cloud, puede invocarlo a través de una API unificada junto con más de 300 modelos adicionales.
Sí. La API de GPT Image 2 admite tanto la generación de texto a imagen como la edición de imágenes en un solo modelo. La edición incluye inpainting y outpainting precisos con imágenes de máscara, además de composición de múltiples referencias que combina varias entradas en un resultado coherente.
No. GPT Image 2 es el sucesor de GPT Image 1.5, no de DALL-E. OpenAI ha abandonado por completo la marca DALL-E: tanto DALL-E 2 como DALL-E 3 se cerrarán el 12 de mayo de 2026. La familia GPT Image utiliza una arquitectura autorregresiva integrada de forma nativa dentro del modelo de lenguaje, lo cual es fundamentalmente diferente del enfoque basado en difusión que utilizaba DALL-E.
Sí. La GPT Image 2 API admite tanto la generación de texto a imagen como la edición de imágenes en un solo modelo. La edición incluye inpainting y outpainting precisos con imágenes de máscara, además de composición multirreferencia que combina varias entradas en un resultado coherente.
Sí. La API de GPT Image 2 renderiza texto en sistemas de escritura latinos y CJK (chino, japonés, coreano), incluyendo chino, japonés y coreano, con glifos precisos y trazos claros. Esto le permite producir señalización localizada, publicaciones en redes sociales y materiales de marca que antes requerían la superposición manual de texto.
La API de GPT Image 2 admite tamaños de imagen y relaciones de aspecto flexibles, con una resolución de salida nativa de hasta 2K y 4K disponible mediante escalado. Puede solicitar tamaños preestablecidos o dimensiones personalizadas para adaptarse a publicaciones en redes sociales, banners y recursos listos para imprimir.
No. OpenAI restringe la familia GPT Image detrás de una verificación de organización en su propia consola de desarrollador, lo que puede bloquear a los desarrolladores individuales. Con la API de GPT Image 2 en Atlas Cloud, solo necesita una cuenta de Atlas Cloud, por lo que puede obtener una clave y comenzar a generar sin la verificación de OpenAI.
OpenAI factura GPT Image 2 por token, por lo que el costo por imagen varía según la resolución, la calidad y las imágenes de referencia, y es difícil de predecir. En Atlas Cloud, la API de GPT Image 2 utiliza un precio fijo por imagen: la generación de texto a imagen comienza en $0.009 por imagen y la edición en $0.01 por imagen, reduciéndose a $0.004 y $0.005 en el nivel de desarrollador. Los nuevos usuarios también obtienen créditos gratuitos para probar antes de gastar.
Explorar Más Series
Seedance 2.0
La API de Seedance 2.0 le ofrece acceso de producción al modelo de video multimodal de ByteDance: entradas cuatrimodales (texto, imagen, video, audio) y un sistema "Universal Reference" líder en la industria que bloquea la composición, el movimiento de la cámara y las acciones de los personajes en diferentes tomas. Integre un control de nivel de director con una sola llamada a la API, una tarifa fija de $0.09/s, clave instantánea y sin lista de espera, todo respaldado por un tiempo de actividad y cumplimiento de nivel empresarial. ¡Seedance 2.0 Native 4K ya está disponible!
Grok Imagine
La Grok Imagine API ofrece a los desarrolladores la generación de imágenes, video y audio de xAI en una sola suite. Produce imágenes de hasta 2K con renderizado de texto multilingüe, además de videos de hasta 15 segundos con audio nativo y sincronizado, y edición basada en referencias. En Atlas Cloud, una sola clave ejecuta cada modo de Grok Imagine, por lo que puede alternar entre imagen, video y audio sin configuraciones separadas, desde $0.02 por imagen y $0.05 por segundo.
Gemini Omni Flash
La Gemini Omni API lleva a tu stack el modelo multimodal de generación y edición de vídeo de Google DeepMind, presentado en Google I/O 2026. Gemini Omni fusiona el motor de razonamiento de Gemini con los medios generativos y acepta cualquier combinación de texto, imágenes, vídeo y audio para producir resultados coherentes y fundamentados en conocimiento. Refina los resultados mediante conversación natural: sustituye objetos, reescribe escenas y cambia de estilo mientras la física, los personajes y la continuidad permanecen intactos. Atlas Cloud ofrece toda la gama Gemini Omni Flash —texto a vídeo, imagen a vídeo con hasta 7 imágenes de referencia y referencia a vídeo— a través de una única API unificada, con precios transparentes por segundo desde $0.112 y sin suscripción. Empieza a construir hoy mismo.
GPT Image 2
La API de GPT Image 2 ofrece a los desarrolladores acceso al último modelo de imágenes de OpenAI, el sucesor de GPT Image 1.5. Genera y edita imágenes con una representación de texto precisa en caracteres latinos y CJK, además de una sólida composición para carteles, maquetas e infografías. En Atlas Cloud, puede acceder a ella a través de una API unificada junto con más de 300 modelos, con créditos gratuitos, un tiempo de actividad del 99,99% y sin necesidad de verificación de organización de OpenAI.
Los modelos creativos más potentes de Google están todos disponibles en Atlas Cloud. Veo 3.1 ofrece generación de video cinematográfico, Nano Banana 2 impulsa la creación de imágenes de alta fidelidad y Gemini aporta inteligencia multimodal a cada flujo de trabajo. Acceda a la suite completa de modelos de Google a través de una sola API key con disponibilidad Day-0 y precios de pago por uso (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini lleva la generación de video multimodal de ByteDance a los flujos de trabajo donde la velocidad y el costo son más importantes. Ofrece las capacidades principales de Seedance 2.0 con un menor consumo de recursos: generación más rápida, menor costo por video y la misma integración de API que ya utiliza. Para los equipos que ejecutan pipelines de alto volumen o crean prototipos a escala, Mini es la opción predeterminada práctica.
ByteDance
Desde la generación de video cinematográfico hasta la creación de imágenes de alta fidelidad, los modelos más potentes de ByteDance están disponibles en Atlas Cloud. Ejecute Seedance y Seedream a gran escala con los precios de inferencia más bajos y cero gastos generales de infraestructura.
Alibaba
Atlas Cloud reúne toda la línea de modelos de Alibaba bajo una sola API: Qwen para tareas de lenguaje e imagen, y Wan para la generación de video hasta 1080p. Acceda a cada modelo con pago por uso sin suscripciones. La API de Alibaba está disponible a través de una única URL base utilizando su cliente compatible con OpenAI existente.
OpenAI
Atlas Cloud le ofrece acceso a la línea completa de la API de OpenAI, desde GPT Image 2 para la generación de imágenes hasta Sora 2 para video. Cada modelo está disponible bajo la modalidad de pago por uso sin compromiso mensual. Intégrelo cambiando simplemente la URL base mediante la API compatible con OpenAI.
xAI
Construya pipelines completos de imágenes y video utilizando la xAI API en Atlas Cloud. Genere en 2K, edite con imágenes de referencia y anime imágenes en clips sincronizados con audio.
Kwaivgi
La API de Kwaivgi a un 15% por debajo del precio estándar. Atlas Cloud ofrece acceso Day-0 a los nuevos lanzamientos de Kling con precios de pago por uso y sin límites de puestos. Una cuenta, una clave, todos los modelos de Kling desde el nivel estándar hasta el nivel maestro.
Seedream 5.0 Pro
La API de Seedream 5.0 Pro ofrece a los desarrolladores el modelo de edición de imágenes controlable de ByteDance en Atlas Cloud. Sitúa las ediciones con precisión mediante anclajes y coordenadas, separa las imágenes en capas editables, fusiona múltiples referencias y empareja colores y materiales exactos, con texto multilingüe a 2K y 3K. ¡En Atlas Cloud puede acceder a él mediante una sola clave!


