MiniMax M3 ya está aquí, y aquí tienes el resumen: úsalo si necesitas un modelo de pesos abiertos que procese imágenes y video de forma nativa, gestione un millón de tokens de contexto a bajo costo y ejecute bucles largos de codificación y agentes sin reiniciarse. Ese es su caso de uso principal; si tienes agentes que operan de forma autónoma mientras duermes, ¡te recomendamos probarlo! M3 ya está disponible en Atlas Cloud.
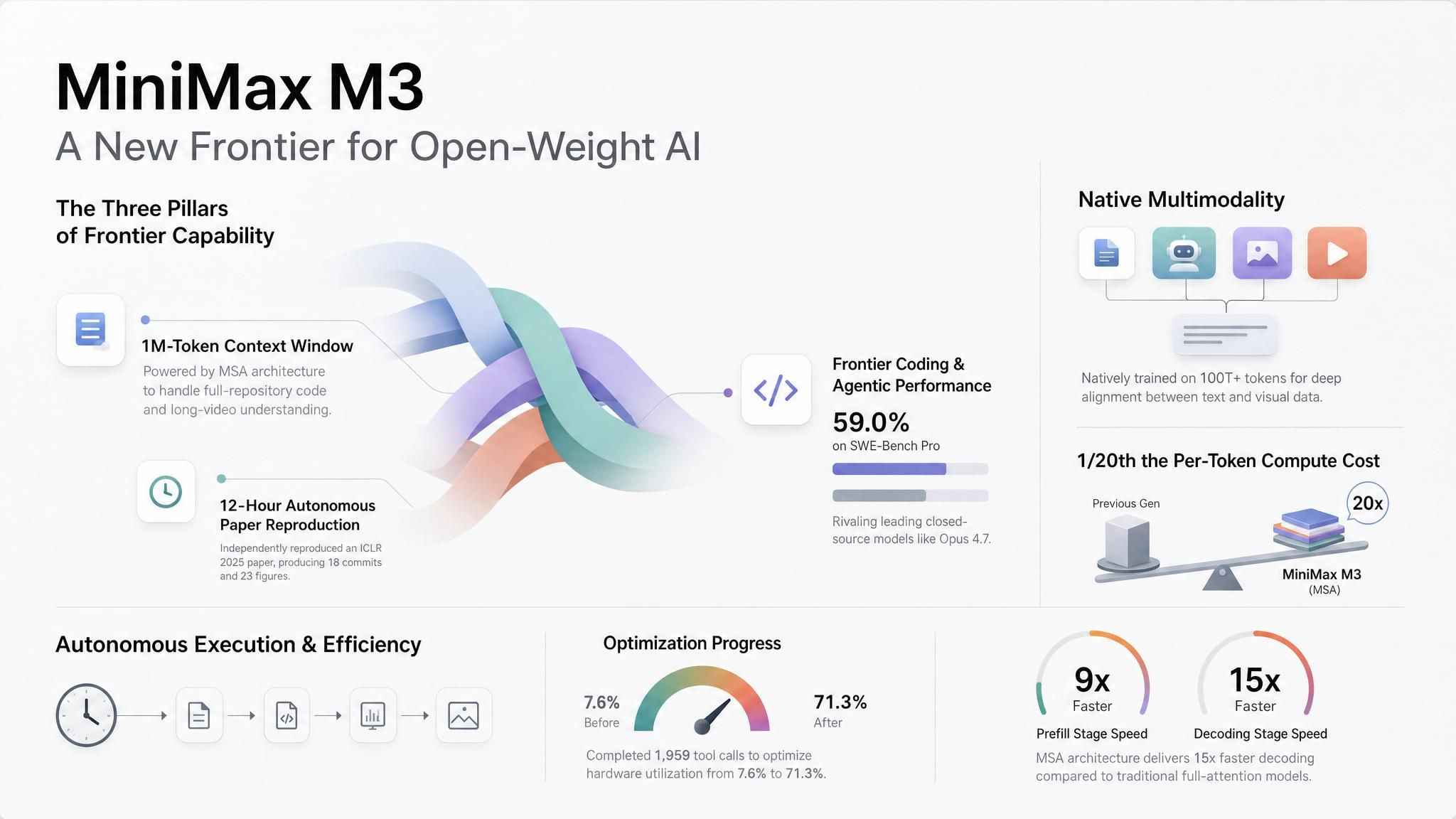
Si no tienes agentes de larga ejecución, M3 sigue siendo relevante por la dirección que tomó MiniMax para llegar ahí. Mantuvieron un contexto de 1M a un precio asequible mediante una arquitectura de atención dispersa (MiniMax Sparse Attention, o MSA) que reduce el cómputo por token a aproximadamente 1/20 de la generación anterior con el contexto completo; y lo lograron eligiendo el camino más económico que funciona con la infraestructura actual, no el más exótico. Esperamos que esta sea la dirección estándar de todos los proveedores principales: contexto largo y barato mediante atención dispersa o comprimida. Esto convierte una ventana de 1M de algo diferenciador a un requisito mínimo, y traslada la competencia real a un nivel superior: qué tan bien logras enrutar entre modelos, no en cuál de ellos decides apostar.
MiniMax anunció M3 el 1 de junio de 2026. La API ya está disponible y la compañía afirma que publicará el informe técnico y los pesos en los próximos 10 días tras el anuncio.
Si ya usas otro modelo de frontera
M3 merece ser probado cuando el trabajo requiere un conjunto de trabajo más grande, contexto visual o un bucle de agente más largo de lo que maneja bien tu opción actual. La columna relevante es la última: lo que M3 añade realmente sobre el modelo específico que ya utilizas.
| Si usas hoy esto | Para este trabajo | Lo que M3 añade realmente |
|---|---|---|
| GPT-5.5 o GPT-5.5 Pro | Codificación por agentes, uso de computadora, investigación, análisis de datos y automatización de trabajo de conocimiento | Entrada de video nativa y una ruta de pesos abiertos anunciada: una segunda ruta de agente con una curva de costos distinta que podrás autohospedar más adelante. (GPT-5.5 ya tiene visión por imagen, así que prueba video y economía, no el soporte de imagen.) |
| Claude Opus 4.8 | Agentes de codificación de larga ejecución, trabajo de conocimiento intensivo en recuperación y uso de herramientas | Una alternativa de pesos abiertos y menor costo para hacer A/B en codificación de repositorios completos y costo por tarea completada. Opus 4.8 ya ofrece ventana de 1M de contexto y visión, así que la prueba real es precio, entrada de video y economía de tareas, no el tamaño de la ventana. |
| Qwen3.7-Plus (multimodal) | Agentes de visión y GUI, conversión de capturas a código, automatización de navegador y escritorio | Multimodalidad comparable con un posicionamiento más fuerte en codificación/agentes y una ruta de pesos abiertos. (Qwen3.7-Plus es propietario, solo API.) |
| Qwen3.7-Max (bandera solo texto) | Razonamiento de texto, agentes de largo horizonte, automatización de oficina | Entrada nativa de imagen y video en el mismo contexto. Qwen3.7-Max es solo texto; para visión, tendrías que cambiar a Plus. |
| DeepSeek-V4-Pro o DeepSeek-V4-Flash | Razonamiento sensible a costos, codificación, llamadas a herramientas y cargas de trabajo de API con contexto largo | Multimodalidad nativa (imagen y video) sobre un contexto largo. DeepSeek-V4 es solo texto, por lo que M3 es la alternativa multimodal cuando la carga de trabajo conlleva una señal visual. |
La prueba práctica es sencilla. Prueba M3 si intentas:
- mantener el repositorio, el historial de tareas, los registros y el plan actual en un solo contexto de trabajo.
- permitir que un agente continúe tras decenas de llamadas a herramientas en lugar de reiniciar la conversación.
- razonar sobre código, texto, capturas de pantalla, gráficos, PDFs y fotogramas de video en una sola pasada.
- reducir los traspasos entre un modelo de texto, uno de visión y una capa de recuperación separada.
- comparar el costo por tarea completada con contexto largo, no solo el precio por millón de tokens.
No cambies solo porque un gráfico de lanzamiento se vea bien. Cambia cuando M3 complete una tarea que tu stack de enrutamiento actual descarta, trunca, sobrepaga o divide entre demasiados modelos.
Dónde ayuda M3
Agentes con espacio para trabajar. Los ejemplos de lanzamiento de MiniMax van más allá del patrón típico de chat. En una prueba, M3 reprodujo los experimentos principales de un artículo destacado de ICLR 2025 tras ejecutar durante casi 12 horas. Produjo 18 commits y 23 figuras experimentales. En otro caso, trabajó durante unas 24 horas en un kernel CUDA FP8 GEMM, realizó 147 envíos a benchmarks y 1,959 llamadas a herramientas, y elevó la utilización del hardware del 7.6% al 71.3%.
No leas esos ejemplos como prueba de que un agente de un día completo funcionará con tu primer prompt. Sí demuestran por qué M3 merece estar en la lista corta para flujos de trabajo donde el modelo necesita planificar, usar herramientas, inspeccionar resultados, revisar y continuar después de que un intento inicial falla.
Contexto a escala de repositorio y documento. M3 soporta hasta 1M de tokens a través de la API, con MiniMax describiendo 512K como el mínimo garantizado. A una longitud de contexto de 1M de tokens, MiniMax reporta un cómputo por token de 1/20 de la generación anterior, con un prefill más de 9x más rápido y una decodificación más de 15x más rápida.
Eso cambia el diseño del producto. Un agente de codificación puede ver más del repositorio. Un asistente de investigación puede llevar un rastro de evidencia más largo. Una herramienta de revisión de contratos puede mantener el material fuente y el análisis en el mismo conjunto de trabajo. La recuperación sigue teniendo su lugar, pero el modelo ya no tiene que empezar desde una pequeña parte del problema.
Contexto visual en la misma solicitud. MiniMax entrenó M3 con datos multimodales desde el principio. El modelo acepta entradas de imagen y video, y MiniMax asegura que puede manejar texto, imágenes y video intercalados en un solo contexto.
Esto reduce los traspasos entre modelos. Un flujo de soporte puede leer el mensaje del usuario e inspeccionar la captura de pantalla. Un flujo de investigación puede razonar sobre gráficos dentro de un documento. Un agente de uso de computadora puede mirar la pantalla y decidir la siguiente acción sin enviar primero el paso visual a otro modelo.
Acceso hospedado ahora, pesos pronto. MiniMax trata a M3 como un lanzamiento de pesos abiertos, pero la primera ruta de acceso es mediante API hospedada. Eso da a los equipos una secuencia útil: probar el modelo hospedado ahora, luego decidir si el lanzamiento posterior de pesos se ajusta a una implementación privada, ajuste fino (fine-tuning) o evaluación interna.
Una frontera de precios clara. MiniMax indica que las llamadas a la API de 512K tokens de entrada o menos usan la tarifa estándar. El precio de contexto largo comienza por encima de 512K, donde los equipos suelen ejecutar cargas de trabajo de repositorios completos, documentos extensos o videos largos. M3 también soporta un interruptor de "pensamiento" al mismo precio, permitiendo usar el modo de razonamiento para tareas de agentes más complejas y un modo más rápido para finalizaciones sensibles a la latencia.
Cómo se ve el costo operativo
MiniMax M3 en Atlas Cloud tiene un precio de USD0.30/M tokens de entrada y USD1.20/M tokens de salida. Claude Opus 4.7 cuesta USD5/M entrada y USD25/M salida, mientras que GPT-5.5 cuesta USD5/M entrada y USD30/M salida.
Esto hace que M3 sea:
- 94% más barato en entrada que Opus 4.7 y GPT-5.5
- 95.2% más barato en salida que Opus 4.7
- 96% más barato en salida que GPT-5.5
El precio del token solo importa después de mapearlo a la forma de la carga de trabajo. Un agente de codificación con un repositorio grande en contexto gasta la mayor parte de su dinero en entrada. Un flujo de investigación o redacción con explicaciones largas gasta más en salida. Un agente GUI multimodal también paga por contexto visual, y la conversión de tokens depende del proveedor.
Usa la tabla a continuación como una traducción de tarifa, no como un benchmark. Asume precios en USD, sin aciertos de caché, sin descuentos por lote, sin primas regionales, sin tarifas por llamadas a herramientas y sin reintentos. Para GPT-5.5, OpenAI indica que los prompts por encima de 272K tokens de entrada se cobran a 2x entrada y 1.5x salida por toda la sesión, por lo que el ejemplo de contexto largo usa esa tarifa efectiva más alta.
| Modelo | Tarifa usada | 100K entrada + 5K salida | 500K entrada + 20K salida | Lectura de costo |
|---|---|---|---|---|
| MiniMax M3 en Atlas Cloud | $0.30 / $1.20 | $0.04 | $0.17 | Ruta multimodal de bajo costo. Más cara que DeepSeek Flash, pero muy por debajo de los precios de frontera cerrados. |
| DeepSeek V4 Flash | $0.14 / $0.28 | $0.02 | $0.08 | La ruta nombrada más barata para trabajo de alto volumen solo de texto. Úsala cuando la entrada visual no es parte de la tarea. |
| DeepSeek V4 Pro | $0.435 / $0.87 | $0.05 | $0.23 | Cerca de M3 en costo puro de token, pero solo texto. Mejor comparación para razonamiento y codificación sin contexto visual. |
| Qwen3.7-Plus | $0.40 / $1.60 hasta 256K; $1.20 / $4.80 > 256K | $0.05 | $0.70 | Competitivo para llamadas multimodales más cortas. El precio de contexto largo cambia la economía por encima de 256K. |
| Qwen3.7-Max | $2.50 / $7.50 | $0.29 | $1.40 | Más barato que GPT y Claude, pero no un estándar de volumen a menos que gane la tarea. |
| Claude Opus 4.8 | $5 / $25 | $0.63 | $3.00 | Ruta premium para codificación de alto riesgo, uso de herramientas y fiabilidad de contexto largo. |
| GPT-5.5 | $5 / $30 estándar; $10 / $45 > 272K entrada | $0.65 | $5.90 | Úsalo cuando el uso de herramientas, el comportamiento de computadora o la eficiencia del modelo justifiquen la prima. |
| GPT-5.5 Pro | $30 / $180 | $3.90 | $18.60 | Resérvalo para el trabajo más difícil. La tarifa lo sitúa en una clase de presupuesto distinta. |
La lectura de costo: M3 no es el modelo de texto más barato de la lista. DeepSeek V4 Flash sigue ganando si la carga de trabajo es solo texto, de alto volumen y tolerante al nivel de capacidad Flash. El argumento de costo de M3 es diferente: sitúa la entrada nativa de imagen y video, el contexto de trabajo largo y la codificación de agentes en una banda de precios cercana a DeepSeek V4 Pro y muy por debajo de GPT-5.5, GPT-5.5 Pro y Claude Opus 4.8.
Para un turno de agente de 500K de entrada y 20K de salida, M3 es aproximadamente 17x más barato que Claude Opus 4.8 y unas 34x más barato que GPT-5.5 una vez que se aplica el multiplicador de contexto largo de OpenAI. Es unas 4x más barato que Qwen3.7-Plus en ese tamaño de solicitud y unas 8x más barato que Qwen3.7-Max. Contra DeepSeek, la respuesta depende de la modalidad: DeepSeek V4 Flash sigue siendo más barato, mientras que V4 Pro cae en el mismo rango general. Si la tarea incluye capturas, gráficos, estado de interfaz o fotogramas de video, M3 puede evitar el paso extra de enrutamiento a un modelo de visión separado.
A escala mensual, la diferencia es más clara. Una carga de trabajo con 10M de tokens de entrada y 1M de salida cuesta unos USD4.20 en M3, USD1.68 en DeepSeek V4 Flash, USD5.22 en DeepSeek V4 Pro, USD75 en Claude Opus 4.8, USD80 en GPT-5.5 a tarifas estándar y USD480 en GPT-5.5 Pro. Qwen3.7-Plus se sitúa entre USD5.60 y USD16.80 dependiendo de si cada solicitud se mantiene por debajo o por encima de su límite de precio de 256K; Qwen3.7-Max ronda los USD32.50.
Nuestra recomendación: Trata a los modelos caros como rutas que necesitan ganarse su lugar. Si GPT-5.5 u Opus 4.8 terminan una tarea difícil en una ejecución mientras M3 necesita tres reintentos y un parche manual, la llamada barata no fue realmente barata. Si la tarea es análisis multimodal de contexto largo, triaje de codificación a escala de repositorio, automatización de tickets de soporte con capturas o trabajo con documentos donde M3 alcanza el nivel de calidad, su economía lo convierte en un candidato de enrutamiento serio, más que en una curiosidad de semana de lanzamiento.
Lee los benchmarks como datos de proveedor
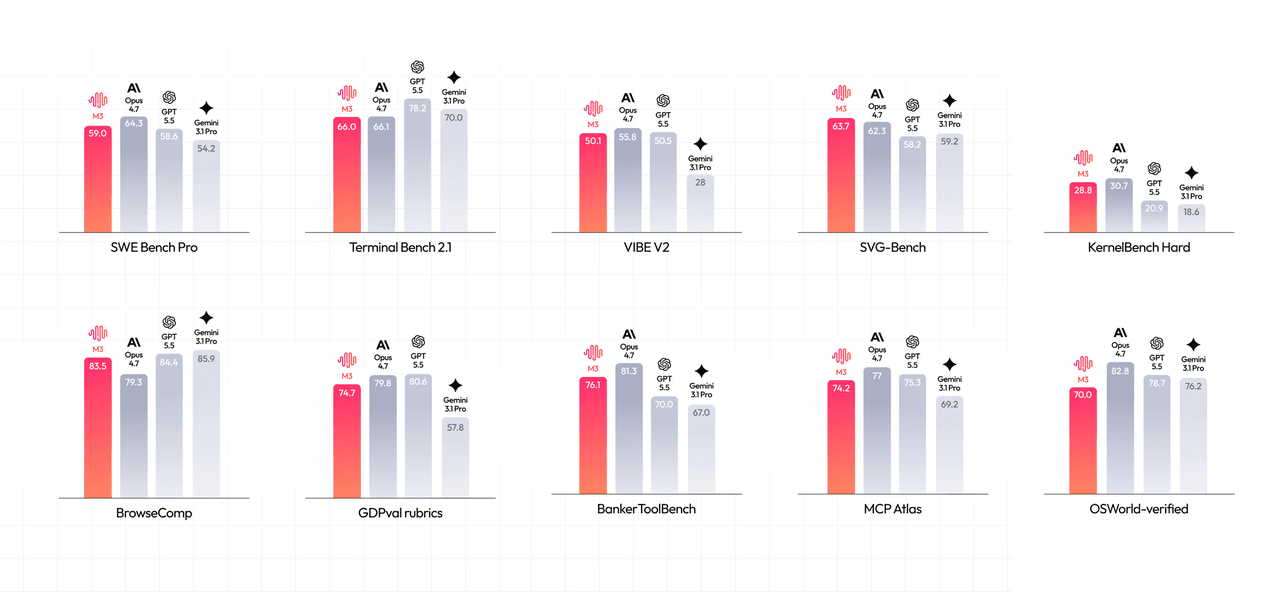
MiniMax reporta puntuaciones sólidas en tareas de codificación y agentes:
- SWE-Bench Pro: 59.0%
- Terminal-Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8%
- MCP-Atlas (un benchmark de uso de herramientas MCP de terceros — no relacionado con Atlas Cloud): 74.2%
- BrowseComp: 83.5, comparado con 79.3 para Claude Opus 4.7 en la comparativa de MiniMax
Una nota sobre la última línea: MiniMax compara M3 contra Opus 4.7, pero Opus 4.8 salió el 28 de mayo, cuatro días antes de que se lanzara M3. La comparación de lanzamiento ya estaba una versión atrás en el día uno: un pequeño detalle, pero un anticipo del punto más importante a continuación.
En PostTrainBench, que pide al modelo sintetizar datos, entrenar, evaluar e iterar sobre cuatro modelos base dentro de una ventana de 12 horas, MiniMax reporta a M3 en 0.37 en el post de lanzamiento, equivalente a la puntuación de 37.1 mostrada en su página de modelo. Eso se clasifica detrás de Opus 4.7 con 0.42 y GPT-5.5 con 0.39, pero por delante del resto del campo reportado.
Esas puntuaciones son útiles para el triaje. No son suficientes para una decisión de producción. MiniMax ejecutó muchas de las pruebas en su propia infraestructura y varias evaluaciones usaron andamiaje específico. Antes de que un equipo use una puntuación en una presentación de ventas o una decisión de arquitectura, debería volver a ejecutar la tarea contra su propio código, documentos, prompts, objetivos de latencia y presupuesto.
Cómo evaluar M3 contra los modelos actuales de frontera
Usa M3 como candidato de evaluación, no como predeterminado. Una ventana de 1M de tokens puede ocultar una mala arquitectura si la llenas de archivos irrelevantes, registros antiguos o cada mensaje que el usuario haya enviado.
Ejecuta el mismo conjunto de pruebas contra GPT-5.5, Claude Opus 4.8, Qwen3.7-Plus o Max, DeepSeek-V4-Pro o Flash, y M3. Luego compara los resultados por tarea, no por reputación de proveedor.
Comienza con seis pruebas:
- Codificación de repo completo: Da a cada modelo el mismo problema, fragmento de repositorio, acceso a herramientas y tiempo de espera. Puntúa la calidad del parche, tasa de éxito de pruebas, tamaño de diff y ediciones innecesarias.
- Recuperación de contexto largo: Pon detalles relevantes al inicio, medio y final del contexto. Añade distractores similares. Comprueba si cada modelo recupera la instancia correcta, no solo cualquier frase que coincida.
- Resistencia de bucle de herramientas: Ejecuta una tarea que necesite 30, 60 y más de 100 llamadas a herramientas. Observa si cada modelo mantiene un plan estable, se repite, pierde restricciones anteriores o se detiene antes de que la tarea termine.
- Trabajo de agente visual: Da a cada modelo multimodal un ticket de soporte con capturas, un documento con gráficos, o una especificación de producto con capturas de interfaz. Para rutas solo texto o con visión débil, mide el costo adicional del traspaso a un modelo de visión separado.
- Latencia bajo contexto real: Compara el tiempo al primer token y el tiempo total de finalización a 128K, 512K y 1M de tokens de entrada. No aceptes una afirmación de ventana de 1M sin datos de latencia.
- Costo por tarea completada: Mide tokens de entrada, salida, reintentos, llamadas a herramientas, aciertos de caché, latencia y corrección humana. Una llamada a un modelo más barato aún puede costar más si requiere tres reintentos.
Aquí es donde la mayoría de los equipos se equivocan con la pregunta del modelo. Preguntan qué modelo tiene el mejor benchmark de lanzamiento. La pregunta de producción es más estrecha: ¿qué modelo completa este flujo de trabajo con la calidad, latencia y costo que tu producto puede tolerar?
Cómo MSA mantiene el contexto largo utilizable
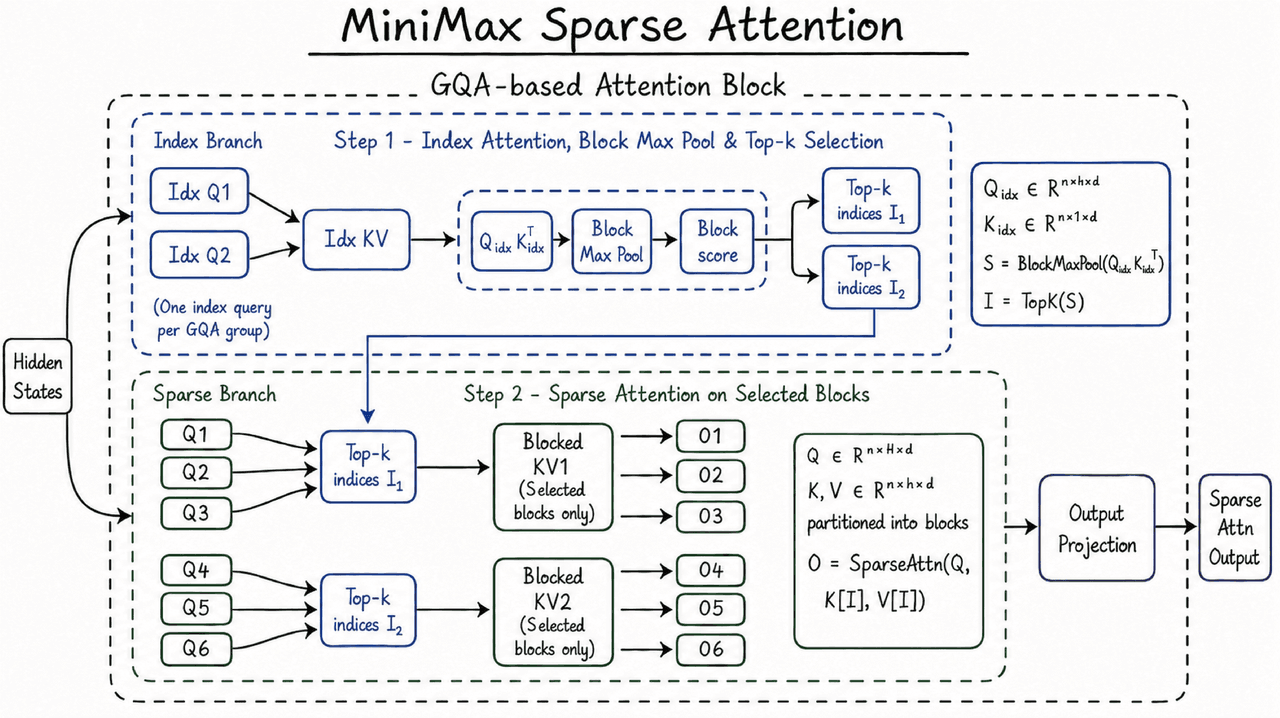
La ventana de contexto de M3 depende de MiniMax Sparse Attention, o MSA.
La atención completa permite que cada token atienda a cada otro token. A medida que la secuencia se hace más larga, el trabajo crece con el cuadrado de la longitud de la secuencia. La atención dispersa añade un paso de selección, luego ejecuta la atención sobre las partes del contexto previo que más importan.
MiniMax indica que MSA particiona la caché KV en bloques y selecciona a nivel de bloque. La caché KV almacena los vectores de clave y valor de tokens anteriores, y maneja una gran parte del tráfico de memoria en la inferencia de contexto largo. MiniMax también describe un diseño de operador llamado "KV outer gather Q": los bloques KV se convierten en el bucle exterior, las consultas que llegan a un bloque se reúnen en él, cada bloque se lee una vez y el acceso a memoria se mantiene contiguo.
En el post de lanzamiento de MiniMax, ese diseño corre más de 4x más rápido que Flash-Sparse-Attention de código abierto y flash-moba bajo la configuración de cabezales de M3. MiniMax también afirma que MSA igualó la atención completa en la gran mayoría de las ablaciones.
La afirmación de ingeniería importa porque una ventana de 1M de tokens no tiene valor si los equipos no pueden permitirse usarla. MSA es la razón por la que MiniMax puede argumentar que el contexto largo es parte del modelo operativo normal de M3, no un modo de demo de una sola vez. Tampoco es único: el V4 de DeepSeek envía un híbrido de Atención Dispersa Comprimida y Atención Fuertemente Comprimida por la misma razón. El contexto largo y barato se está convirtiendo en un estándar arquitectónico.
La tendencia más amplia: los lanzamientos de modelos se están convirtiendo en eventos de enrutamiento
M3 no es un lanzamiento aislado. Se ajusta a un patrón que se ha ido construyendo en todo el mercado.
La tendencia más clara es el calendario. En aproximadamente seis semanas, se lanzaron cuatro modelos de 1M de contexto:
- DeepSeek V4-Pro y V4-Flash — 24 de abril, pesos abiertos, 1M de contexto, modos de pensamiento/no pensamiento.
- Qwen3.7-Max — 20 de mayo, bandera de razonamiento solo de texto, 1M de contexto (el Qwen3.7-Plus multimodal siguió a principios de junio).
- Claude Opus 4.8 — 28 de mayo, con ventana de 1M de contexto para la familia Opus.
- MiniMax M3 — 1 de junio, 1M de contexto más multimodalidad nativa y una ruta de pesos abiertos.
Una ventana de un millón de tokens ha pasado de ser un diferenciador a un requisito básico en un solo trimestre. Lo mismo está sucediendo con la atención dispersa, los interruptores de pensamiento, los benchmarks de agentes y el precio escalonado de contexto largo. Espera que las páginas de modelos sigan convergiendo en las mismas características destacadas.
El ritmo también supera al marketing. Los propios benchmarks de lanzamiento de M3 de MiniMax comparan contra Opus 4.7, pero Opus 4.8 salió cuatro días antes. El modelo contra el que comparaste la semana pasada no es el modelo que tu competidor está ejecutando esta semana. Ese es el mundo de los eventos de enrutamiento en un solo ejemplo.
Eso no hace que M3 sea irrelevante, pero cambia lo que los desarrolladores deberían optimizar.
La ventaja del modelo decaerá más rápido que el trabajo de integración a su alrededor. Si un equipo codifica rígidamente un proveedor en su stack de agentes, cada lanzamiento mayor se convierte en un proyecto de migración. Si un equipo enruta por tarea, precio, latencia, modalidad y resultado de evaluación, cada lanzamiento mayor se convierte en una actualización de enrutamiento.
El ganador no es el equipo que elige un modelo y lo defiende durante un año. El ganador es el equipo que puede probar M3 hoy, compararlo contra GPT-5.5, Claude Opus 4.8, Qwen3.7 y DeepSeek-V4 mañana, y mover el tráfico cuando los números indiquen que deben hacerlo.
Qué pueden copiar otros proveedores y qué no
Los proveedores pueden copiar primero el área de superficie:
- ventanas de contexto más largas
- variantes de atención dispersa
- modos de pensamiento encendido/apagado
- páginas de benchmarks de agentes de codificación
- demos de lanzamiento multimodales
- mensajería de pesos abiertos o adyacentes a pesos abiertos
Las partes más difíciles toman más tiempo:
- servicio estable de contexto largo bajo concurrencia real
- calidad profunda en el contexto, especialmente con distractores
- fiabilidad del agente tras muchas llamadas a herramientas
- alineación multimodal entre texto, imágenes, gráficos y video
- precios que se mantienen cuando los clientes usan toda la ventana
- IDs de modelo, versiones y respaldos claros en los que los equipos de producción puedan confiar
Esa brecha es donde los desarrolladores deberían invertir su tiempo de evaluación. No preguntes solo si otro proveedor puede anunciar una ventana de 1M. Pregunta si el modelo sigue la instrucción enterrada en el token 750,000, si puede comparar dos capturas similares sin desviarse, si la latencia se mantiene aceptable y si la economía sobrevive al tráfico real de usuarios.
Por qué ejecutarlo a través de Atlas Cloud
Atlas Cloud da a los equipos una clave API para más de 300 modelos a través de cargas de trabajo de LLM, imagen, video y audio. Eso importa más a medida que los lanzamientos de modelos convergen en las mismas características destacadas.
Puedes probar M3 contra los modelos que ya están en tu stack, enrutar el tráfico donde rinda y mantener la superficie de integración estable a medida que llegan nuevos lanzamientos. Puedes mantener GPT-5.5 donde gana en trabajo de uso de computadora, mantener Claude Opus 4.8 donde gana en agentes de codificación de larga ejecución, usar Qwen3.7-Plus donde ganan los agentes GUI multimodales, usar DeepSeek-V4 donde gana la relación precio/rendimiento, y añadir M3 donde el contexto largo más la multimodalidad nativa cambian el resultado.
Usa M3 donde su contexto largo y multimodalidad se paguen por sí mismos. Mantén otros modelos donde aún ganen. Cambia basado en evaluaciones, no en el hype de la semana de lanzamiento.
[CTA - intención del desarrollador: Ejecuta M3 en Atlas Cloud -> atlascloud.ai/models | Obtén una clave API -> console.atlascloud.ai]






