
Wan 2.7 image is a large text-to-image model developed by Alibaba's Tongyi Lab. It's new 'Thinking Mode' revolutionizes text-to-image by understanding spatial logic and intent before rendering. It stops being a basic tool you have to micromanage and becomes a true creative partner. The next era isn't about sharper resolution—it's about models that finally understand your vision.
WAN 2.6 vs WAN 2.7 Thinking Mode – Workflow & Cost Comparison Table
| Comparison Dimension | Wan 2.6 image | Wan 2.7 image (Thinking Mode) |
| Input Prompt | Requires more precise, well-crafted prompts; sensitive to wording. | Understands natural language. You just describe your idea like you're talking to a person. |
| Generation Process | Direct generation with limited internal reasoning; less iterative refinement. | Thinks first. Analyzes layout, lighting, and how subjects interact before rendering. |
| Output Creation | Good quality, but may miss intent or produce inconsistencies in complex scenes. | Highly cohesive scenes. It usually nails the vibe and structure on the first or second try. The text rendering capability can directly embed clear, readable text into the image, with no need for post-processing. |
| User Cost | Lower per generation, but may require multiple retries → higher total cost. | Low. Faster workflows, way fewer redos, and cheaper overall production costs. |
What Is Thinking Mode? What Has Really Been Upgraded in the Three Stages of Text-to-Image Generation?
WAN 2.6 model basically just "draw whatever you say"—even if the physics make absolutely no sense. Wan 2.7 image's Thinking Mode flips this entirely. It actually tries to understand what you’re trying to express first, and then it helps you build the final piece.
Instead of a blind art machine, it acts more like a co-director. Let's look at what actually happens under the hood during the three main generation stages.
Stage ① – Intent Interpretation (From Keywords to Relationships)
In the past, if you asked for a "knight and a dragon," you usually just got two separate objects awkwardly copy-pasted into a single frame. WAN 2.6 image always struggled with multi-subject AI generation.
Wan 2.7 image reads the intent behind your words. Instead of just dropping items on a canvas, it builds actual relationships between your subjects. If characters are interacting, it looks at eye contact, posture, and physical connection. It doesn't just read isolated keywords—it decodes the action. This totally takes the pain out of writing complex AI image prompts.
Stage ② – Spatial & Logical Reasoning (From Flat Generation to Depth)
We've all seen those weird AI glitches. Hands merging into tables, or shadows pointing the wrong way. That mostly happens because WAN 2.6 image model render things flat.
Wan 2.7 image applies deep AI spatial reasoning. It globally calculates the foreground and background logic before it even starts painting. It figures out the perspective and traces the light sources so shadows fall naturally. By leveraging true AI image layout control, it makes sure objects actually occupy 3D space. The result? The image looks like a real, unified world rather than a flat sticker book.
Stage ③ – Scene Construction (From Single Image to Narrative)
Most of us aren't great at describing every tiny visual detail. Honestly, that’s okay. During this final stage, the AI steps up and automatically fills in your visual blanks.
Say you want to generate posters with AI but only give a basic outline. Wan 2.7 image uses its multimodal AI understanding to choose the best cinematic composition. It dials in the narrative atmosphere for you—maybe adding some moody fog or a specific color grading. It transforms a simple, incomplete thought into a compelling story.
Case Study: WAN 2.6 image vs WAN 2.7 image in Production Environments
The real turning point for text to image tech isn't just making something that looks vaguely okay. It’s finally jumping to a place where you can actually use the result in a real project. Wan 2.7 image’s Thinking Mode seems to be the core engine driving a massive shift. It pushes AI generation into true production-grade territory.
Visual Test: "Rainy Street Scene"
To see how this works in practice, let's look at a quick visual test. I fed the exact same prompt into a Wan 2.6 and then into Wan 2.7 image.
The Prompt: "A girl walking her dog on a rainy city street, cinematic, neon lights at night."
Pretty standard, right? But the outputs couldn't have been more different.
Side-by-Side Evaluation Summary
WAN 2.6 image output: At first glance, it might seem fine. But look a little closer. There is A large, thick cloud of white smoke inexplicably bursts out from behind/under the dog's body. The fingers of the girl holding the umbrella are completely melted — the number of fingers is wrong, the joint structures are twisted, and they are fused directly into the umbrella handle. It might fool a casual scroller, but it totally falls apart under scrutiny.

Image generated by WAN 2.6 image
WAN 2.7 image Thinking Mode output: This one actually blew me away a bit. The ground reflections match the glowing signs perfectly. The girl and the dog are actually interacting. Because of its advanced AI spatial reasoning, the scene has real, physical depth. You could literally take this image and use it right away.

Image generated by WAN 2.7 image
WAN 2.6 image vs WAN 2.7 image Thinking Mode – Visual Quality Comparison Table
| Metric | WAN 2.6 image | WAN 2.7 image Thinking Mode |
| Composition | Good overall framing, but can feel generic or slightly unbalanced in complex scenes. | Uses smart AI image layout control for cinematic framing, better subject emphasis and balance. |
| Lighting | Decent lighting, but sometimes flat or inconsistent across elements. | Stronger, more coherent lighting with improved realism and mood control. |
| Spatial Logic | Occasional perspective errors; object relationships can break in detail. | Significantly improved spatial consistency and object coherence. |
| Prompt Adherence | Follows prompts reasonably well, but , drops details when given complex AI image prompts, may miss subtle constraints. | Much higher fidelity to nuanced prompts and multi-step instructions. |
| Success Rate | Moderate(~70–80%): noticeable variance, especially with complex prompts. | High (~85–95%): more reliable outputs, fewer retries needed. |
Business Value: Why WAN 2.7 image "Thinking Mode" Is a Game Changer
When text to image tech shifts from just "making pictures" to actually understanding what you want, everything changes. I’ve noticed it's not just about getting a prettier output anymore. The real win here is a massive leap in efficiency and business value. It turns AI from a tool you have to constantly micromanage into a real, collaborative teammate.
Lower Barrier, Higher Efficiency
I remember typing weird brackets and negative weights just to get a usable image. That's mostly over now. With Wan 2.7 image's multimodal AI understanding, natural language finally replaces all those complex AI image prompts.
You basically just talk to it. Because it thinks before it acts, the success rate is insanely high. A higher hit rate means a dramatically faster workflow. You get your asset in two minutes, not so many minutes.
Unmatched Controllability for Commercial Use
For a long time, AI art was mostly just good for weird, abstract concept art. It usually wasn't stable enough for real business tasks. But Wan 2.7 offers serious AI image layout control.
The composition stays incredibly solid. This means you can finally trust it for actual brand campaigns and e-commerce product mockups. It handles AI with legible text much better than WAN 2.6 image model.
Maximized ROI Across Teams
Bringing this model into your company changes how everyone operates. When you rely less on trial and error, the return on investment spikes. Here is how different teams actually use it:
Designers: Stop starting from scratch. You can quickly generate posters with AI, by it acclaimed text rendering, multilingual layout, and image set mode, as well as its ability to handle up to 3,000 tokens and support 12 languages, then you can spend your valuable time refining the details.
Marketing Teams: Need five visual variations of an ad? It easily handles multi-subject AI generation so your models and products look right every single time.
Developers: You can integrate these API features into your apps without worrying about your users generating glitchy, unusable nonsense.
Content Creators: Turn blog concepts into high-quality thumbnails instantly while keeping a consistent visual style across your whole channel.
Scaling WAN 2.7 image: Why Global Teams Use Atlas Cloud's Text-to-Image API
The new "Thinking Mode" is incredible, but I've learned the hard way that powerful features demand really powerful infrastructure. Relying on a single, official API for your text to image generation usually leads to a massive headache. You run into sudden rate limits, annoying queue delays, and deep integration bottlenecks right when you need to scale up.
That is why smart global teams are moving to aggregator platforms. Calling the Wan 2.7 image Model through Atlas Cloud just ends up being a much safer, smarter bet.
4 Reasons to Build with Atlas Cloud
- True Aggregator Flexibility
Using an official API means you are locked into just one model. Plus, you have to code all your own error handling and custom routing. It's honestly a pain. Atlas Cloud API gives you a single, unified endpoint. You get instant access to Wan 2.7 image, alongside other top-tier models. You can easily switch models depending on the task. The inputs and outputs are completely standardized. Whenever a brand new model drops, you can test it on day zero without rewriting your code.
- Low Latency and High Speed
Official APIs constantly get hammered by heavy user traffic. That means your requests get stuck in a queue and your app slows to a crawl. Atlas Cloud essentially bypasses that official congestion. They offer enterprise-scale speed with virtually no rate limits, enjoy your image generation requests actually go through fast.
- Enterprise-Grade Stability
During peak usage, Atlas Cloud has real-time load balancing. It evenly distributes tokens and reduces latency spikes on overloaded nodes, ensuring stable performance under any conditions.
- Serious Cost Effectiveness
Atlas Cloud platform genuinely lowers your base generation cost, costs as low as $0.03 per image. You end up paying significantly less per image without sacrificing any visual quality or speed.
FAQ: WAN 2.7 image and Text-to-Image API
You probably still have a few questions about how all of this actually works in practice. Here are the most common things people ask when they start looking into this new generation tech.
Does WAN 2.7 Thinking Mode increase text-to-image generation time?
Yes, Wan 2.7 image's Thinking Mode adds a slight inference delay (milliseconds to seconds) because it utilizes a Chain-of-Thought reasoning layer before generating. However, your total project time drops massively. Because you aren't forced to hit the "generate" button many times just to get one usable shot, you save times overall.
How is Wan 2.7 different from Midjourney or Flux?
Midjourney is famous for gorgeous, highly stylized artistic vibes. Flux is heavily praised for its raw speed. But Wan 2.7 image is built differently. It relies on deep multimodal AI understanding. It prioritizes logic, physics, and relationships over just making things look pretty. If you need reliable multi-subject AI generation where characters actually interact properly without melting into each other, Wan 2.7 image is usually the smarter choice.
Can Wan 2.7 image render text in images?
Yes, Wan 2.7 image boasts robust multilingual text rendering capabilities for UI design and posters.
Is Wan 2.7 image open source?
No, it hasn't been officially confirmed yet.
How do I integrate Atlas Cloud's Text-to-Image API into my application?
Yes, you just swap out your current URL for the Atlas Cloud unified endpoint. They use standard REST calls and return clean JSON. Developers usually have it running in an afternoon.
Conclusion
Looking back, the evolution of text to image tech has been pretty wild. We started with blurry, distorted shapes a few years ago. Then we moved to high-resolution images that still completely lacked basic physics. Now, we are finally stepping into an era where the AI actually thinks before it paints.
Models like Wan 2.7 image aren't just blind graphic generators anymore. They have become collaborative design partners. By understanding complex prompts and offering true layout control, they bridge the final gap between a raw idea and a finished, commercial-ready asset.
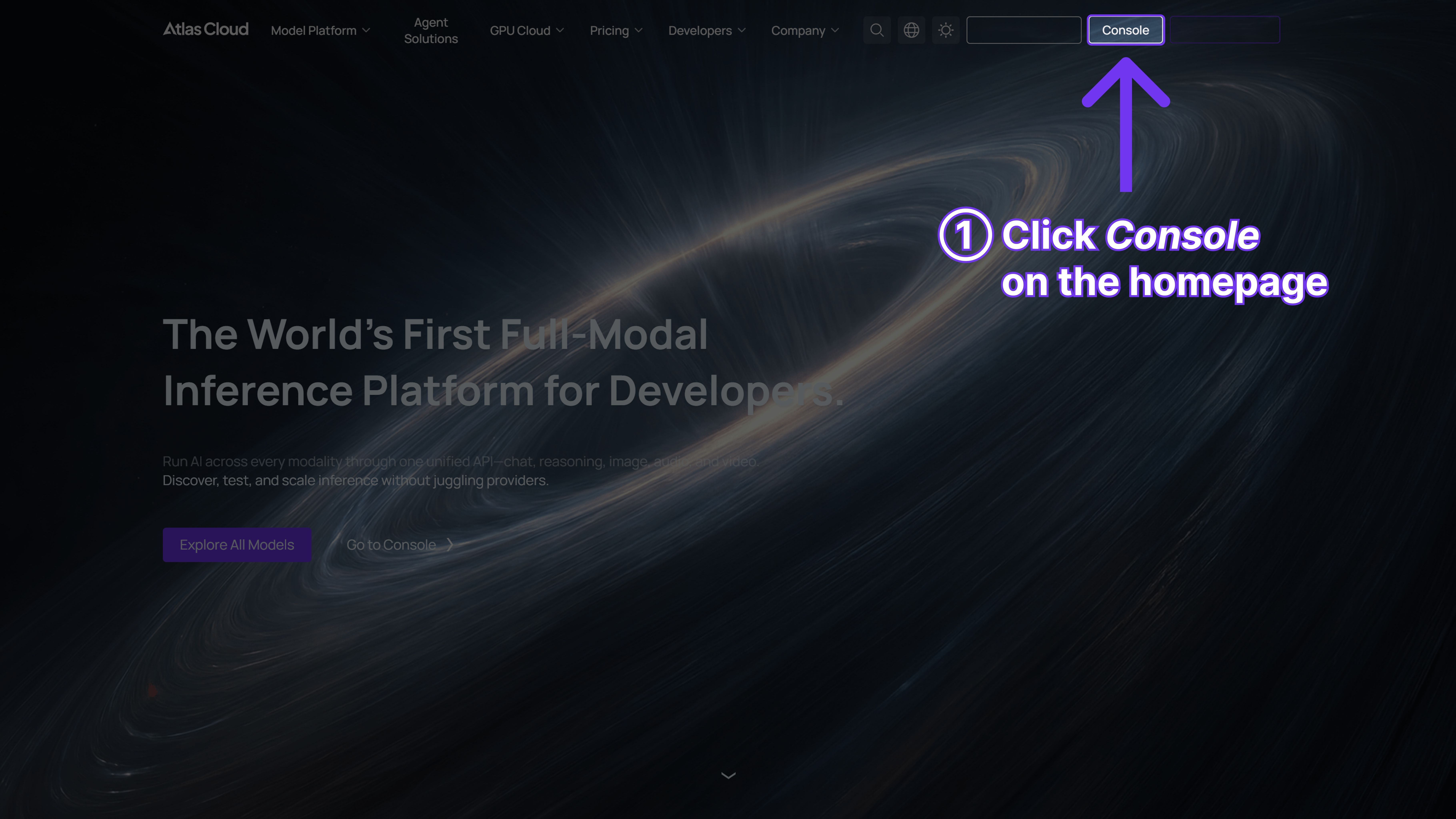
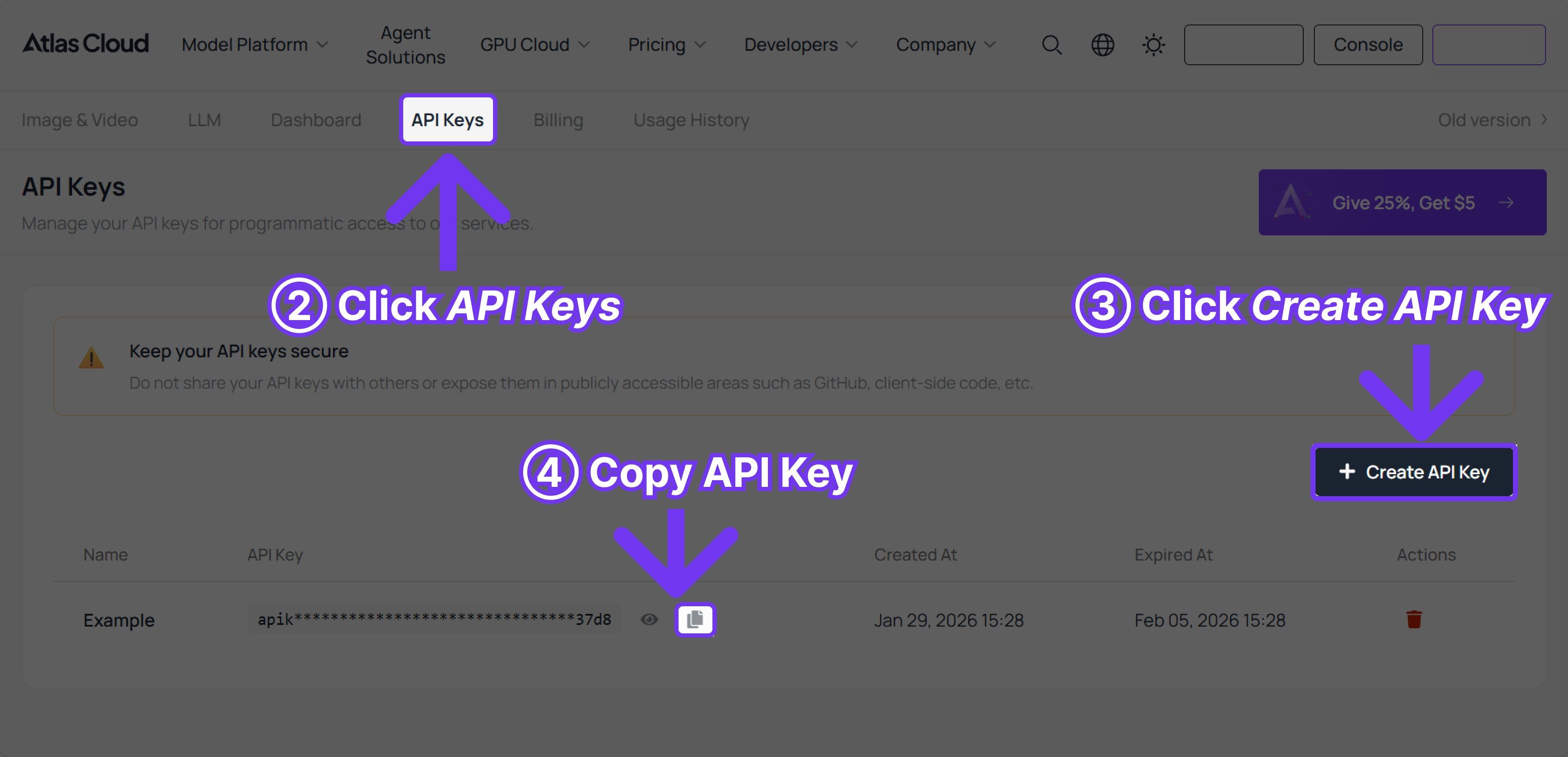
Ready to upgrade your application's generation capabilities?
Stop fighting with frustrating prompt engineering and unpredictable official API queues. Turn your AI into a true productivity engine. Get your free API key on Atlas Cloud today, and test Wan 2.7 image immediately.
Read our API documentation and make your first Wan 2.7 image call right now.






