Tu prompt se topó con un muro de rechazo. No porque fuera dañino, sino porque una palabra clave activó un filtro.
Los desarrolladores de la comunidad Ollama describen esto como "vectores de rechazo": bloqueos provocados por palabras clave que no tienen nada que ver con daños reales. Ingeniería inversa de malware para investigación de seguridad, documentación de casos de estudio médicos, creación de contenido para adultos, escritura de ficción oscura. La IA convencional bloquea todo esto. Esta lista clasifica los mejores modelos de IA sin censura de 2026 según datos reales de la comunidad, no por material de marketing. Cubre tres categorías: modelos LLM sin censura para texto y código, los mejores modelos de IA local sin censura de 2026 para despliegue en hardware privado, y modelos de IA sin censura de 2026 para generación de imagen y video vía API. Cada cifra está verificada y fechada a mayo de 2026.
Para una introducción al panorama general de herramientas, los lectores nuevos en este espacio encontrarán la guía de generadores de imágenes de IA sin censura como un punto de partida útil antes de seleccionar un modelo específico.
Cómo clasificamos los mejores modelos de IA sin censura de 2026
En 2026, las cifras de descargas de la comunidad en Ollama proporcionan una señal de clasificación más fiable que las puntuaciones de referencia (benchmarks), que pueden ser seleccionadas para notas de prensa en lugar de un rendimiento real (Ollama, búsqueda de modelos sin censura, 2026). Millones de descargas representan miles de configuraciones de hardware y tipos de prompts. Eso es más difícil de manipular que un conjunto de evaluación curado.
En este artículo se utilizan tres señales de clasificación. Para los modelos sin censura de Ollama, la señal principal es el número de descargas desde ollama.com, obtenido en mayo de 2026. Para los modelos de OpenRouter, la clasificación se basa en el recuento de parámetros y la ventana de contexto, ya que los números de descarga no están disponibles públicamente en esa plataforma. Para los modelos de imagen y video, la clasificación se basa en el precio por salida, listando primero los costos más bajos dentro de cada grupo.
La mayoría de los modelos de IA sin censura de 2026 se dividen en dos categorías técnicas: ajustados (fine-tuned) y "abliterados" (abliterated). Los modelos ajustados, como la serie Dolphin, se entrenan con conjuntos de datos que no refuerzan el comportamiento de rechazo. Los modelos "abliterados" tienen sus pesos de rechazo eliminados quirúrgicamente. La comunidad encuentra sistemáticamente que los modelos ajustados son más estables ante diversos tipos de prompts.
En la práctica, el número de descargas también se correlaciona con la estabilidad del modelo. Un modelo que alcanza más de 1 millón de descargas ha sido probado en una amplia gama de configuraciones de hardware, revelando errores e inestabilidades que grupos de prueba más pequeños pasan por alto por completo.
¿Cuáles son los 5 modelos de IA sin censura de Ollama más descargados?
En 2026, los cinco modelos de Ollama sin censura más descargados suman más de 9.2 millones de descargas, con llama2-uncensored liderando con 2.6 millones (Ollama, búsqueda de modelos sin censura, 2026). Estos son los mejores modelos de Ollama sin censura de 2026 según la validación de la comunidad, no por algún benchmark. El hardware es el filtro principal que la mayoría de los usuarios aplica primero: los requisitos de VRAM oscilan entre menos de 4GB y 40GB en este grupo.
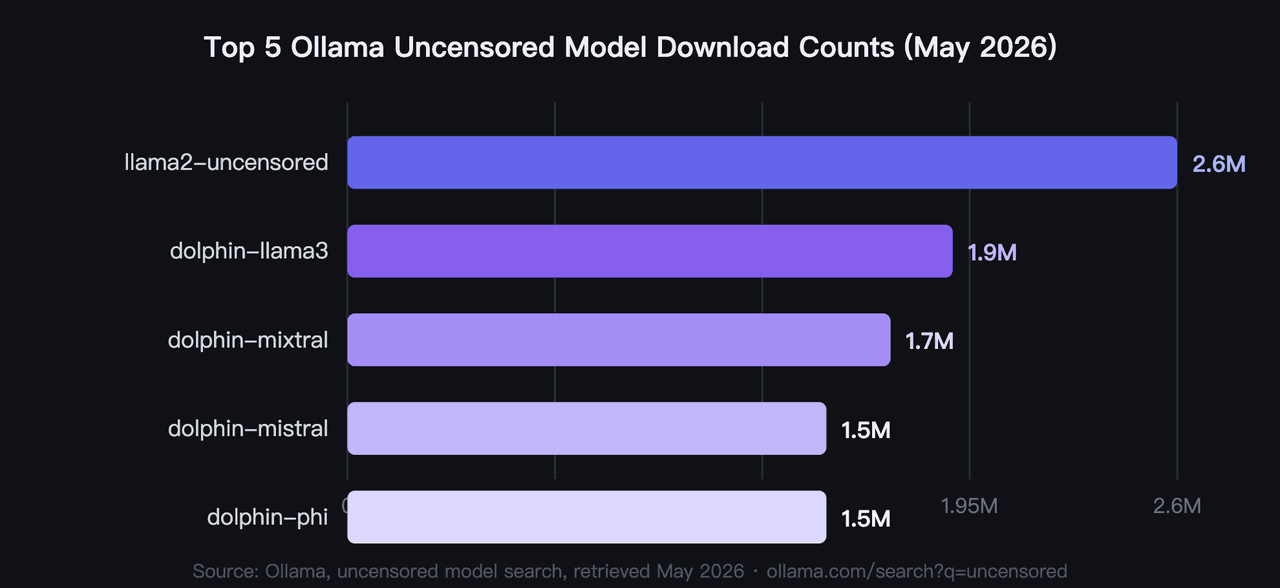
1. llama2-uncensored: El modelo de IA sin censura más descargado en Ollama
El estándar de la comunidad original para IA local sin censura. George Sung y Jarrad Hope lanzaron este ajuste para eliminar el comportamiento de rechazo de Llama 2 sin degradar la capacidad general. Es el modelo con el que comienzan la mayoría de los desarrolladores, y su cifra de 2.6 millones de descargas refleja más de dos años de uso en el mundo real. Ningún otro LLM sin censura ha igualado ese volumen de descargas.
- Parámetros: 7B o 70B
- VRAM: ~6GB (7B); ~40GB (70B)
- Ideal para: Chat de propósito general sin restricciones y generación de contenido
- Plataforma: Ollama
2. dolphin-llama3: El mejor LLM Llama 3 sin censura para flujos de trabajo de agentes
El Dolphin de Eric Hartford sobre una base Llama 3 es el modelo sin censura más descargado construido sobre una arquitectura moderna, con 1.9 millones de descargas (Ollama, página del modelo dolphin-llama3, 2026). Admite llamadas a funciones (function calling) y una ventana de contexto que va de 8K a 256K tokens según la configuración. La versión 8B pesa 4.7GB, encajando en la mayoría de las GPU de consumo de gama media.
- Parámetros: 8B o 70B
- VRAM: ~5GB (8B); ~40GB (70B)
- Ideal para: Programación, flujos de trabajo de agentes y llamadas a funciones
- Plataforma: Ollama
3. dolphin-mixtral 8x7B: Modelo de IA MoE sin censura para razonamiento complejo
Una arquitectura de mezcla de expertos (MoE) dirige cada token a través de un subconjunto de sus 8 capas de expertos. Esto produce una calidad de razonamiento cercana a la de un modelo de 70B con un menor costo de inferencia que un modelo denso de igual recuento total de parámetros. El ajuste sin censura de Eric Hartford mantiene un fuerte énfasis en la programación.
- Parámetros: 8x7B (los parámetros activos por paso de inferencia son mucho menores que el total)
- VRAM: ~12-16GB con cuantización
- Ideal para: Tareas de programación complejas, razonamiento técnico y cadenas de instrucciones largas
- Plataforma: Ollama
4. dolphin-mistral: Modelo de IA local 7B sin censura para respuestas rápidas
Más ligero y rápido que dolphin-mixtral en hardware con CPU limitada. Registra 1.5 millones de descargas por parte de desarrolladores que desean un modelo local receptivo para autocompletado de código sin necesidad de una GPU de alta gama. La arquitectura base Mistral le confiere una excelente relación rendimiento-tamaño para un modelo de 7B.
- Parámetros: 7B
- VRAM: ~5-6GB
- Ideal para: Asistencia de programación ligera y respuestas rápidas de chat
- Plataforma: Ollama
5. dolphin-phi 2.7B: El modelo de IA local sin censura más ligero
La arquitectura base Phi de Microsoft ofrece un razonamiento capaz en un recuento de 2.7B parámetros. El ajuste sin censura de Eric Hartford preserva esa eficiencia. Con menos de 4GB de VRAM, funciona en la mayoría de las computadoras portátiles modernas con GPU dedicada, convirtiéndolo en el punto de entrada accesible para los mejores modelos de IA local sin censura de 2026.
- Parámetros: 2.7B
- VRAM: Menos de 4GB
- Ideal para: Despliegue en portátiles, pruebas rápidas y entornos con hardware limitado
- Plataforma: Ollama
Mejores modelos LLM sin censura del 6 al 10: Programación, Roleplay y contexto largo
En 2026, la serie Dolphin ocupa 5 de los 10 primeros lugares en el catálogo sin censura de Ollama por número de descargas, una concentración que refleja la metodología de ajuste consistente de Eric Hartford aplicada a través de diferentes arquitecturas base (Ollama, página del modelo hermes3, 2026). Los modelos del 6 al 10 cubren roleplay, conversación general, herramientas para desarrolladores, seguimiento de instrucciones y contexto extendido: los casos de uso donde los rechazos de la IA convencional son más disruptivos.
6. hermes3: Modelo de IA sin censura para Roleplay y tareas de agentes
Nous Research construyó hermes3 para profundidad en el roleplay y uso estructurado de herramientas. Está disponible en cuatro tamaños, desde 3B hasta 405B, el rango más amplio de cualquier modelo en esta lista. Con 1.3 millones de descargas, la variante 8B se sitúa en un lugar práctico para la escritura creativa y flujos de trabajo de planificación de agentes (Ollama, página del modelo hermes3, 2026).
- Parámetros: 3B, 8B, 70B o 405B
- VRAM: ~2GB (3B); ~5GB (8B); ~40GB (70B)
- Ideal para: Roleplay, ficción creativa y planificación de tareas de agentes
- Plataforma: Ollama
7. wizard-vicuna-uncensored: Modelo de IA multiescala sin censura para uso general
Un modelo más antiguo pero probado construido sobre Llama 2, disponible en tres tamaños hasta 30B. Sus 1.2 millones de descargas provienen de usuarios que desean una opción sin censura fiable con un rango de parámetros más amplio. No iguala las capacidades de ventana de contexto de dolphin-llama3, pero maneja la conversación general y el contenido creativo de forma consistente.
- Parámetros: 7B, 13B o 30B
- VRAM: ~5GB (7B); ~9GB (13B); ~20GB (30B)
- Ideal para: Conversación de propósito general y contenido creativo con múltiples opciones de tamaño
- Plataforma: Ollama
8. dolphincoder: Modelo de IA de programación sin censura sobre base StarCoder2
Tener a StarCoder2 como base hace que dolphincoder sea un especialista genuino. Mientras otros modelos Dolphin son generalistas con ajustes sin censura, este se enfoca específicamente en el desarrollo de software. Sus 943 mil descargas provienen casi en su totalidad de desarrolladores, no de usuarios creativos. La variante 15B maneja bases de código más grandes de lo que la de 7B puede gestionar.
- Parámetros: 7B o 15B
- VRAM: ~5GB (7B); ~10GB (15B)
- Ideal para: Generación de código, depuración y documentación técnica
- Plataforma: Ollama
9. wizardlm-uncensored: LLM sin censura para seguimiento de instrucciones en flujos de investigación
Un modelo de seguimiento de instrucciones de 13B con 610 mil descargas. Su fortaleza es seguir instrucciones complejas de varios pasos sin evadir ni rechazar sub-tareas. En flujos de trabajo de investigación donde un rechazo interrumpe una cadena larga, esa fiabilidad tiene un valor de productividad directo. No tiene la arquitectura base moderna de dolphin-llama3, pero cumple con el trabajo de instrucciones de manera consistente.
- Parámetros: 13B
- VRAM: ~9GB
- Ideal para: Cadenas de instrucciones complejas de varios pasos y flujos de investigación
- Plataforma: Ollama
10. everythinglm: LLM sin censura con ventana de contexto de 16K
La característica destacada aquí es la ventana de contexto de 16K sobre una base Llama 2. La mayoría de los modelos 7B alcanzan un máximo de 4K o 8K tokens. Ese contexto adicional permite que everythinglm procese bases de código completas, documentos largos o historiales de conversación extensos sin truncamiento. Sus 536 mil descargas son modestas según los estándares de esta lista, pero llena un vacío que ningún otro modelo aquí cubre a este tamaño.
- Parámetros: 13B
- VRAM: ~9GB
- Ideal para: Análisis de documentos largos, chat de contexto extendido y revisión de bases de código completas
- Plataforma: Ollama
El dominio de la serie Dolphin en las descargas de Ollama refleja un patrón que la comunidad ha documentado: los modelos sin censura ajustados por un solo autor con una metodología consistente superan a los intentos de "abliteración" puntuales. La abliteración elimina los pesos de rechazo de un modelo individual; el ajuste fino construye un comportamiento sin censura estable en diversos tipos de prompts. Esa consistencia es la razón por la cual 5 de los 10 primeros lugares pertenecen al trabajo de Eric Hartford, y no a una arquitectura base específica.
¿Cómo configurar modelos de Ollama sin censura localmente?
En 2026, tres comandos instalan cualquier modelo de Ollama en Mac, Linux o Windows: instalar Ollama desde ollama.com, ejecutar ollama pull [nombre-del-modelo], luego ollama run [nombre-del-modelo] (Documentación de Ollama, 2026). No se requiere clave API. No se aplica moderación de contenido externa. Tu prompt nunca sale de tu hardware.
Para dolphin-llama3 como ejemplo concreto: ollama pull dolphin-llama3 descarga el archivo de 8B de 4.7GB. ollama run dolphin-llama3 abre un prompt interactivo. Todo el proceso de inferencia se ejecuta en tu GPU o CPU local.
LM Studio proporciona una interfaz gráfica de escritorio para usuarios que prefieren no trabajar en la terminal. Utiliza los mismos archivos de modelo GGUF que Ollama, con una interfaz visual para la selección de modelos y el ajuste de parámetros. llama.cpp es el motor de inferencia subyacente detrás de ambas herramientas, y admite el uso directo desde la línea de comandos cuando necesitas más control sobre los niveles de cuantización y los ajustes de longitud de contexto.
Los desarrolladores que deseen requisitos de hardware específicos y ajustes de cuantización para ejecutar los mejores modelos de IA local sin censura de 2026 en GPU de consumo encontrarán que la guía de configuración local completa cubre configuraciones mínimas de VRAM y errores comunes en detalle.
¿Qué modelos de OpenRouter sin censura están disponibles sin GPU local?
En 2026, OpenRouter aloja LLMs sin censura vía API, eliminando el requisito de GPU por completo. El modelo venice/uncensored está disponible como modelo de nivel gratuito a USD0 por cada millón de tokens de entrada y salida (OpenRouter, página del modelo venice/uncensored, 2026). Esto convierte a los modelos de OpenRouter sin censura en el punto de entrada práctico para usuarios sin hardware dedicado.
El compromiso es sencillo: OpenRouter enruta tu prompt a través de su infraestructura, por lo que la conversación no es privada de la misma manera que un modelo local. Los modelos locales de Ollama mantienen todo en tu dispositivo. Ningún enfoque es universalmente mejor; la elección correcta depende de tu modelo de amenazas y disponibilidad de hardware.
11. venice/uncensored: Modelo OpenRouter gratuito sin censura
El modelo Venice Uncensored en el nivel gratuito de OpenRouter. Una base Mistral-Small de 24B, ajustada para salida sin censura por Cognitive Computations en colaboración con Venice.ai. Ventana de contexto de 32K, USD0 por millón de tokens. El nivel gratuito de OpenRouter aplica un límite de plataforma de 200 solicitudes por día en todos los modelos gratuitos.
- Parámetros: 24B
- VRAM: Ninguna requerida (alojado en la nube)
- Ideal para: Probar LLMs sin censura sin hardware local; gratis dentro de los límites de tasa de la plataforma
- Plataforma: OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B: Modelo grande sin censura vía OpenRouter
Modelo creativo de roleplay y seguimiento de instrucciones de 70B de Sao10k, ajustado para salida sin censura. Basado en Llama 3.3 70B con 131K de contexto. Mantenido activamente con uso real en OpenRouter y buscable por nombre en la búsqueda global de la plataforma.
- Parámetros: 70B
- VRAM: Ninguna requerida (alojado en la nube)
- Ideal para: Escritura creativa compleja, roleplay y largas cadenas de instrucciones sin hardware local
- Plataforma: OpenRouter
13. Sao10K: Llama 3 8B Lunaris: Modelo ligero sin censura vía OpenRouter
Lunaris 8B es un modelo generalista y de roleplay versátil de Sao10k, basado en Llama 3 8B. Es una fusión estratégica de múltiples modelos diseñada para equilibrar la creatividad con una lógica mejorada y conocimiento general, ofreciendo una experiencia mejorada respecto a Stheno v3.2. La opción sin censura de menor costo en OpenRouter a USD0.04/USD0.05 por millón de tokens.
- Parámetros: 8B
- VRAM: Ninguna requerida (alojado en la nube)
- Ideal para: Conversación sin censura ligera y escritura creativa al costo mínimo
- Plataforma: OpenRouter
14. TheDrummer: Cydonia 24B V4.1: Modelo de escritura creativa sin censura vía OpenRouter
Cydonia 24B V4.1 es un modelo de escritura creativa sin censura de TheDrummer, basado en Mistral Small 3.2 24B, con buena memoria, adherencia al prompt e inteligencia. Ventana de contexto de 131K. Mantenido activamente y buscable directamente por nombre en la búsqueda global de OpenRouter.
- Parámetros: 24B
- VRAM: Ninguna requerida (alojado en la nube)
- Ideal para: Escritura creativa sin censura y roleplay sin hardware local
- Plataforma: OpenRouter
Cómo acceder a modelos de imagen y video sin censura vía Atlas Cloud
En 2026, la mayoría de los modelos de imagen y video sin censura requieren hardware GPU local o una plataforma API dedicada, porque los proveedores de nube convencionales aplican filtros de contenido que bloquean la salida NSFW al nivel de inferencia. Atlas Cloud es una plataforma de API de modelos construida específicamente para eliminar esa restricción, cubriendo más de 300 modelos curados en texto, imagen, video y audio.
Comenzar toma tres pasos:
- Crear una cuenta en atlascloud.ai
- Generar una clave API desde el panel de control
- Llamar al endpoint del modelo usando la clave — los modelos de imagen y video usan su propio formato REST; los endpoints de LLM siguen el formato de Chat Completions de OpenAI.
Por qué Atlas Cloud es relevante específicamente para casos de uso sin censura:
- La política de privacidad de la plataforma establece: "Tu contenido generado nunca se usa para entrenamiento y nunca es revisado por nadie". Este es un compromiso explícito publicado, no una suposición predeterminada.
- No se aplica límite diario de generación a ningún modelo del catálogo.
- El catálogo de imágenes sin censura cubre 33 modelos de texto a imagen comenzando en USD0.003 por imagen.
- El catálogo de video sin censura cubre más de 10 modelos de video NSFW comenzando en USD0.01/seg.
El catálogo completo de modelos sin censura se puede explorar en Uncensored AI. Los modelos del 15 al 20 en esta lista son accesibles a través de una única clave API de Atlas Cloud.
¿Cuáles son los mejores modelos de IA de imagen sin censura para NSFW y contenido adulto?
En 2026, la arquitectura FLUX impulsa la mayoría de la generación de imágenes sin censura de alta calidad, disponible vía API de Atlas Cloud a través de niveles de precio y calidad (Atlas Cloud, lista de modelos de texto a imagen, 2026). El catálogo de Atlas Cloud cubre 33 modelos de texto a imagen en total. Los casos de uso incluyen bellas artes, diseño de personajes, modelos de lencería sin censura, retratos adultos, creación de activos para juegos e ilustración por lotes.
Para un desglose completo de herramientas de imágenes sin censura basadas en navegador y API, la guía de los mejores generadores de imágenes de IA NSFW sin censura cubre ambas categorías con comparaciones de capacidad. Los desarrolladores enfocados específicamente en la arquitectura FLUX pueden leer la guía de generadores de imágenes FLUX sin censura para obtener detalles de ajuste y flujo de trabajo.
Para flujos de trabajo que comienzan a partir de una imagen existente en lugar de un prompt de texto, la guía de imagen a imagen de IA sin censura y la guía de mejores editores de imágenes de IA sin censura cubren tuberías de transformación y edición, respectivamente.
15. FLUX Schnell: El modelo de IA de imagen sin censura más rápido para generación por lotes
La opción de menor costo en el catálogo de imágenes de Atlas Cloud. A USD0.003 por imagen, es la herramienta adecuada para flujos de trabajo de generación por lotes donde la velocidad y el volumen importan más que el detalle fino. No se aplica límite diario y no se almacena contenido para entrenamiento.
- Precio: USD0.003/imagen
- VRAM: Ninguna requerida (acceso API)
- Ideal para: Generación de imágenes por lotes, prototipado rápido y salida sin censura de gran volumen
- Plataforma: Atlas Cloud API
16. FLUX Dev: El modelo de IA de imagen sin censura de mayor calidad para producción final
Cuatro veces el costo de FLUX Schnell, con una anatomía, iluminación y detalle de textura notablemente mejores. Para una salida de calidad final donde las imágenes individuales importan, el punto de precio de USD0.012 es un paso práctico. Se adapta a portafolios, contenido adulto comercial y activos de producción.
- Precio: USD0.012/imagen
- VRAM: Ninguna requerida (acceso API)
- Ideal para: Imágenes individuales de alta calidad, portafolios y activos de producción final
- Plataforma: Atlas Cloud API
17. FLUX Dev LoRA: Modelo de imagen sin censura con entrenamiento de estilo personalizado
El ajuste fino LoRA inyecta un estilo personalizado, apariencia de personaje o sujeto en la base FLUX Dev. Este es el modelo a usar cuando necesitas una apariencia de personaje consistente en un lote o deseas que se aplique un estilo específico a cada imagen de una serie. Atlas Cloud gestiona la carga de LoRA en el lado del servidor.
- Precio: USD0.015/imagen
- VRAM: Ninguna requerida (acceso API)
- Ideal para: Consistencia de personajes, entrenamiento de estilo personalizado y series de imágenes de marca
- Plataforma: Atlas Cloud API
18. Z-Image Turbo: Modelo de IA de imagen sin censura económico con calidad de nivel medio
Situado entre FLUX Schnell y FLUX Dev en la curva de precio-calidad. A USD0.01 por imagen, Z-Image Turbo ofrece una arquitectura diferente optimizada para la velocidad sin la simplificación de imagen que hace Schnell. Es la elección práctica cuando la calidad de Schnell no es suficiente y el costo de FLUX Dev es demasiado alto para el volumen necesario.
- Precio: USD0.01/imagen
- VRAM: Ninguna requerida (acceso API)
- Ideal para: Generación de volumen moderado donde la calidad y el costo deben equilibrarse
- Plataforma: Atlas Cloud API
¿Cuáles son los mejores modelos de IA de video sin censura para animación NSFW en 2026?
En 2026, la generación de video sin censura requiere una tubería separada de la generación de imágenes porque las plataformas de video convencionales aplican filtros de contenido idénticos y se niegan a animar contenido NSFW, incluso cuando la imagen fuente fue generada en otro lugar (Atlas Cloud, catálogo de modelos sin censura, 2026). La página de video sin censura de Atlas Cloud lleva el titular "Libertad creativa sin restricciones. Sin filtros. Sin límites" y cubre más de 10 modelos de video NSFW.
19. Wan 2.2 Turbo Spicy Infinite I2V: El modelo de video sin censura de menor costo
La opción de nivel de entrada para animación NSFW desde una imagen fija. A USD0.01/seg, es la forma más rentable de animar una imagen estática en contenido de video NSFW. La resolución alcanza los 1080p con duración de clip variable, lo que lo convierte en el punto de partida adecuado para tuberías de producción conscientes del presupuesto.
- Precio: USD0.01/seg
- Resolución: 1080p
- Duración: Variable
- Ideal para: Animación NSFW rentable y previsualización de conceptos de movimiento
- Plataforma: Atlas Cloud API
20. Seedance v1.5 Spicy: El modelo de video sin censura de mayor calidad para salida final
La opción de calidad cinematográfica en el catálogo. A USD0.049/seg, cuesta aproximadamente 2.5 veces más que Wan 2.2 Turbo Spicy Infinite, pero produce un movimiento más fluido, mejor coherencia del sujeto entre fotogramas y transiciones más naturales. Para una salida de video NSFW de calidad final donde la fidelidad visual es la preocupación principal, esta es la mejor opción en la línea de video sin censura de Atlas Cloud.
- Precio: USD0.049/seg
- Resolución: 720p
- Duración: 5s
- Ideal para: Video NSFW de calidad final, contenido adulto profesional y listo para entrega
- Plataforma: Atlas Cloud API
Guía de selección rápida de modelos de IA sin censura
| Necesidad | Recomendación |
|---|---|
| Mejor LLM sin censura general | llama2-uncensored o dolphin-llama3 |
| Tareas de programación | dolphin-mixtral 8x7B o dolphincoder |
| Roleplay y escritura creativa | hermes3 |
| Menos de 4GB VRAM | dolphin-phi 2.7B |
| Generación de imagen sin censura | FLUX Schnell vía Atlas Cloud (USD0.003/imagen) |
| Video NSFW desde imagen | Wan 2.2 Turbo Spicy Infinite vía Atlas Cloud (USD0.01/seg) |
Preguntas frecuentes sobre modelos de IA sin censura
¿Cuál es el modelo de IA más sin censura en 2026?
Por recuento de descargas en Ollama, llama2-uncensored lidera con 2.6M de descargas, lo que lo convierte en la opción más validada por la comunidad (Ollama, búsqueda de modelos sin censura, 2026). Por capacidad bruta, dolphin-llama3 ofrece más: llamadas a funciones, hasta 256K de contexto y una arquitectura base Llama 3.
¿Qué modelos sin censura funcionan en Ollama?
Diez modelos de esta lista funcionan como modelos Ollama sin censura: llama2-uncensored, dolphin-llama3, dolphin-mixtral, dolphin-mistral, dolphin-phi, hermes3, wizard-vicuna-uncensored, dolphincoder, wizardlm-uncensored y everythinglm. Todos se instalan con ollama pull [nombre-del-modelo].
¿Qué modelos sin censura están disponibles en OpenRouter?
En 2026, OpenRouter aloja LLMs sin censura vía API. Las opciones incluyen el modelo venice/uncensored de nivel gratuito a USD0 por millón de tokens, además de modelos de pago como Sao10K Euryale 70B, Lunaris 8B y TheDrummer Cydonia 24B.
¿Cuál es la diferencia entre un modelo abliterado y uno ajustado?
La abliteración elimina los pesos de rechazo de un modelo quirúrgicamente. Los modelos sin censura ajustados como la serie Dolphin se entrenan con conjuntos de datos que no refuerzan el comportamiento de rechazo. La comunidad encuentra constantemente que los modelos ajustados son más estables: la abliteración puede introducir salidas inconsistentes, mientras que el ajuste fino produce resultados fiables.
¿Puedo ejecutar modelos de IA sin censura localmente en una computadora portátil?
Sí. dolphin-phi 2.7B funciona con menos de 4GB de VRAM. Con 6-8GB de VRAM puedes ejecutar cualquier modelo 7B de esta lista. Los gráficos integrados no funcionarán.
Conclusión
El mejor modelo de IA sin censura en 2026 depende de tu caso de uso. Para LLM general, dolphin-llama3 es la opción más capaz en Ollama. Para portátiles, dolphin-phi cubre el requisito de menos de 4GB de VRAM. Para acceso a LLM en la nube sin hardware, venice/uncensored en el nivel gratuito de OpenRouter es el punto de partida práctico a USD0 por millón de tokens. Para generación de imágenes sin censura a escala, FLUX Schnell vía Atlas Cloud produce salida a USD0.003 por imagen. Para video NSFW, el catálogo de Atlas Cloud comienza en USD0.01/seg con una política verificada de no entrenamiento y no revisión.






