La mayoría de la gente todavía piensa que mejores palabras equivalen a mejores imágenes. Eso era cierto hace dos años. Ya no.
En 2026, la verdadera brecha no está entre los modelos. Está entre los usuarios que describen y los usuarios que construyen. Un grupo escribe "iluminación cinematográfica, 4k, ultra detallado". El otro grupo construye escenas: dirección de la luz, capas de profundidad, ángulos de cámara.
Si tus imágenes siguen viéndose planas, el problema probablemente no sea el modelo. Es lo que no le estás diciendo.
Por qué tus prompts ya no son suficientes (Perspectiva de 2026)
Los prompts genéricos han dejado de funcionar. Los modelos han visto frases como "mejor calidad" y "alto detalle" millones de veces. Esas palabras apenas marcan la diferencia hoy en día.
¿Qué es lo que realmente importa? Las entradas estructuradas. ¿De dónde viene la luz? ¿Qué hay en el primer plano frente al fondo? ¿Qué lente estás usando? Los modelos modernos responden a estas variables. Ignoran el relleno.
Aquí hay un patrón común. Alguien escribe: "un retrato hermoso con iluminación suave". El modelo entrega algo plano. ¿Por qué? Sin dirección de luz. Sin separación de profundidad. Sin ángulo de cámara. El modelo tiene que adivinar. Y adivinar lleva a resultados promedio.
El cambio que debes hacer es simple. Deja de describir el resultado. Empieza a construir la escena.
Los 7 consejos avanzados
-
Dile a la luz hacia dónde ir
"Iluminación suave" es vago. Iluminación lateral, a contraluz, cenital... esas le dan al modelo algo concreto. La dirección crea sombras. Las sombras crean profundidad. La profundidad hace que una imagen parezca real.
Prueba esto en lugar de "iluminación de retrato suave":
Un retrato de una mujer, iluminación lateral desde la izquierda, sombras suaves en el lado derecho de la cara, sutil luz ambiental desde el fondo

Puedes ver la diferencia de inmediato. El modelo sabe exactamente dónde se sitúa la luz.
-
Usa configuraciones fotográficas reales
Iluminación de tres puntos. Luz de contorno (rim light). Iluminación Rembrandt. Estos no son solo términos elegantes. Son patrones que el modelo vio miles de veces durante el entrenamiento. Úsalos y tus resultados serán más estables.
Ejemplo:
Foto de producto de una zapatilla, configuración de iluminación de tres puntos, luz principal fuerte, luz de relleno suave, sutil luz de contorno que separa el producto de un fondo oscuro

Eso funciona mejor que "iluminación dramática" en cada ocasión.
-
Construye profundidad capa por capa
Las imágenes planas generalmente significan que todo está en el mismo plano. Soluciónalo nombrando el primer plano, el plano medio y el fondo explícitamente.
Ejemplo:
Una taza de café en una mesa de madera (primer plano), una persona trabajando en una computadora portátil (plano medio), el interior de una cafetería suavemente desenfocado con luces cálidas (fondo)

Ahora el modelo tiene relaciones espaciales con las que trabajar.
-
Usa lenguaje de cámara, no etiquetas de estilo
"Estilo cyberpunk" es difuso. "Lente de 35mm, ángulo bajo, plano general" es preciso. La configuración de la cámara se asigna directamente a cómo se construyen las imágenes.
Ten esto a mano:
- 35mm para un look natural y cotidiano
- 85mm para retratos con compresión
- Gran angular para drama y escala
- Ángulo bajo, a la altura de los ojos, cenital para perspectiva
Ejemplo:
Un retrato en primer plano, lente de 85mm, poca profundidad de campo, ángulo a la altura de los ojos, desenfoque de fondo suave

Eso le da al modelo instrucciones mucho más claras que "retrato estético".
-
Guía la atención a través del contraste
El detalle alto en todas partes no es el objetivo. El contraste sí lo es. Luz frente a sombra. Cálido frente a frío. Sujeto nítido frente a fondo borroso.
Tres tipos de contraste funcionan bien:
- Contraste de luz: sujeto brillante sobre un fondo oscuro
- Contraste de color: foco cálido sobre un fondo de tonos fríos
- Contraste de detalle: sujeto nítido, entorno borroso
Ejemplo:
Un sujeto iluminado por un foco cálido sobre un fondo oscuro de tonos fríos, iluminación de alto contraste, enfoque fuerte en el sujeto
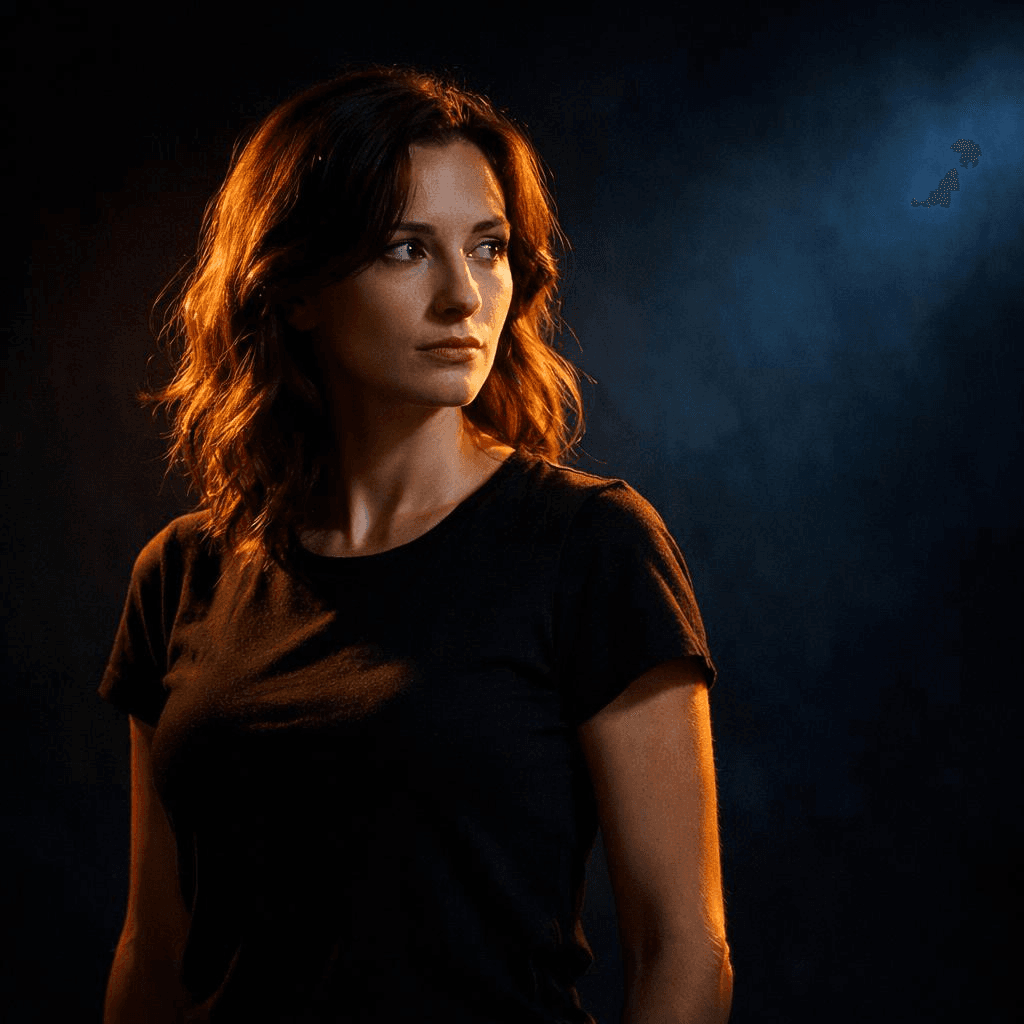
La mirada del espectador va exactamente a donde quieres.
-
Añade restricciones para limpiar el caos
Los prompts largos se vuelven desordenados. En lugar de añadir más detalles, añade límites. Dile al modelo lo que no quieres. Nada de desorden. Nada de distorsión. Sin objetos extra.
Ejemplo:
Foto de producto minimalista, composición centrada, fondo blanco limpio, sin desorden, sin texto, sin distorsión

Las restricciones a menudo hacen más que las descripciones adicionales.
-
Itera como un director, no como un apostador
Nadie obtiene la imagen final al primer intento. Los profesionales generan, ajustan y vuelven a generar.
Un flujo de trabajo simple:
- Paso uno: composición básica, sujeto y entorno
- Paso dos: añade iluminación direccional y contraste
- Paso tres: refina detalles, elimina el desorden
Cada pase mejora el resultado. Así es como pasas de la suerte a la consistencia.
Juntándolo todo: Un marco de trabajo profesional para prompts
Deja de escribir prompts como frases largas. Escríbelos como sistemas modulares.
Aquí hay una estructura que funciona:
plaintext1[Sujeto] + [Entorno] + [Iluminación] + [Cámara] + [Composición] + [Color] + [Restricciones]
Mira la diferencia entre un prompt básico y uno estructurado.
Ejemplo: De un prompt básico a un prompt profesional
Prompt Básico (Usuario típico):
Una modelo femenina vistiendo un vestido de verano blanco, fondo limpio, iluminación de estudio, alto detalle, estilo de comercio electrónico

Prompt Profesional (Estructurado):
Una modelo femenina vistiendo un vestido de verano blanco (sujeto), de pie en un estudio minimalista con un fondo de textura beige suave (entorno), iluminación lateral desde la derecha creando sombras suaves en el lado izquierdo del cuerpo, sutil luz de contorno separando la silueta del fondo (iluminación), tomada con una lente de 85mm, ángulo a la altura de los ojos (cámara), sujeto ligeramente descentrado con poca profundidad de campo, desenfoque de primer plano suave que añade profundidad (composición), tonos naturales cálidos, contraste suave (color), composición limpia, sin desorden, sin distorsión, sin objetos extra (restricciones)

Conclusión: De escribir prompts a dirigir
Conseguir una gran imagen está bien. Pero los proyectos reales necesitan cientos de visuales consistentes y de alta calidad. El prompting manual no escala.
Te encuentras con problemas prácticos: latencia, coste por imagen, mantener el mismo estilo visual entre lotes. El diseño de prompts por sí solo no puede resolver esto. Necesitas un sistema.
Ahí es donde la generación de imágenes basada en API se vuelve esencial. En lugar de escribir prompts en un "playground" cada vez, integras la generación en tu flujo de trabajo. Los prompts estructurados se reutilizan, se automatizan y se optimizan con el tiempo.
Plataformas como Atlas Cloud proporcionan una capa de API unificada para esto.
Y si eres:
• Desarrollador que busca acceso a IA fácil y asequible. • Equipo que maneja proyectos que necesitan IA en múltiples áreas. • Empresa que necesita IA confiable para trabajos importantes. • Usuario de herramientas como ComfyUI y n8n.
Prueba AtlasCloud y verás cómo pasas de experimentar a producir. No es necesario reconstruir la infraestructura desde cero.
El futuro no trata de escribir mejores prompts de forma aislada. Trata de construir sistemas visuales controlables, repetibles y listos para producción.
Preguntas frecuentes
¿Por qué mis imágenes de IA siguen viéndose planas?
Las imágenes planas suelen significar que omitiste las señales de profundidad. Piensa en cómo funciona la fotografía. La profundidad proviene de las sombras, los objetos que se superponen y las diferencias en el enfoque. Tu prompt tiene que especificar eso.
Toma un prompt simple: "una persona sentada en un escritorio". Eso no le dice nada al modelo sobre la profundidad. Prueba algo como esto en su lugar: "una persona sentada en un escritorio (plano medio), una ventana desenfocada con luces de ciudad (fondo), una taza de café en enfoque nítido (primer plano)". Ahora el modelo tiene capas con las que trabajar.
La iluminación es otro aspecto donde la gente falla. Muchos prompts solo mencionan la luz ambiental. Eso te da una iluminación plana y uniforme en toda la imagen. Añade una fuente direccional. Luz lateral. Contraluz. Luz de contorno. Elige una. El modelo comenzará a proyectar sombras y, de repente, tu imagen tendrá volumen.
Una cosa más: no intentes llenar cada rincón del encuadre con detalles. El espacio vacío y el desenfoque son útiles. Le dicen al espectador dónde mirar. A veces, menos detalle te da más profundidad.
¿Puede la IA reemplazar la fotografía de producto?
Sí, en muchos casos. Pero seamos honestos sobre dónde funciona y dónde no.
Si necesitas una foto principal para un reloj de lujo (del tipo donde cada reflejo en el metal importa y la textura de la correa de cuero debe ser exacta), la fotografía tradicional todavía gana. No puedes superar a un estudio real para eso.
Para casi todo lo demás, la IA es más rápida y barata. Imágenes de catálogo, escenas de estilo de vida, variaciones estacionales, creatividades para pruebas A/B. Puedes generar una foto de producto limpia sobre un fondo blanco en segundos. Luego, toma esa imagen y colócala en una escena de playa, una cabaña de invierno o una cocina moderna usando un generador de fotografía de producto por IA.
Sin alquiler de estudio. Sin equipo de iluminación. Sin retoques. Cada imagen cuesta centavos.
Para pequeñas marcas y startups directas al consumidor, esto cambia el juego. Ahora pueden producir visuales que compiten con empresas que tienen grandes presupuestos. Eso no era posible hace dos años.
¿En qué se diferencia el modelo de generación visual de OpenAI de las versiones anteriores?
El nuevo modelo, GPT-image-1.5, tiene algunos cambios arquitectónicos bajo el capó. Utiliza un transformador de difusión. Esa es una forma elegante de decir que maneja mejor las relaciones espaciales.
Las versiones anteriores a menudo dividían escenas complejas en piezas que no encajaban del todo. Una mano podía flotar cerca de una taza en lugar de sostenerla. Las sombras podían apuntar en direcciones incorrectas. La nueva versión mantiene las cosas conectadas. Una mano sostiene la taza. La sombra cae donde debe.
El renderizado de texto es otro gran salto. Los modelos anteriores producían caracteres distorsionados que parecían símbolos aleatorios. GPT-image-1.5 genera palabras legibles en múltiples idiomas. Puedes mezclar inglés y chino en la misma imagen. Eso realmente funciona ahora.
El modelo también admite resoluciones más altas de forma nativa: hasta 2K sin necesidad de escalado. Menos artefactos. Detalles más nítidos.
Hay una desventaja. El modelo es menos tolerante con los prompts vagos. No puedes simplemente decir "un buen retrato" y esperar magia. Tienes que ser más cuidadoso. Pero cuando le das instrucciones estructuradas (dirección de la luz, capas de profundidad, configuraciones de cámara), la calidad de salida es mejor que cualquier cosa de las generaciones anteriores.






