
Los laboratorios de IA chinos han desarrollado discretamente algunos de los modelos de programación de código abierto más capaces disponibles hoy en día. Para los desarrolladores que solo han seguido el mercado de Anthropic y OpenAI, la amplitud de lo que ahora ofrecen DeepSeek, Moonshot, Zhipu, MiniMax y Alibaba es realmente sorprendente.
La pregunta que vale la pena hacerse en 2026 no es si estos modelos son buenos. Es cuál se ajusta a cada carga de trabajo, cuánto cuesta ejecutarlos a escala y cómo integrarlos en las herramientas que ya utilizas. Esta guía cubre los tres aspectos: un perfil de cada laboratorio, una tabla completa de especificaciones y costes, una guía de enrutamiento práctico para casos de uso y las configuraciones para Claude Code, Codex y OpenClaw.
![]()
Por qué los mejores LLM de programación de código abierto están captando la atención
El punto de inflexión fue DeepSeek V3, lanzado en diciembre de 2024. Obtuvo un 89,1% en HumanEval y un 42,0% en SWE-bench Verified, siendo competitivo con Claude 3.5 Sonnet y GPT-4o en ese momento, a pesar de ser de código abierto y utilizar una arquitectura de mezcla de expertos (Mixture of Experts) que activaba solo 37 mil millones de sus 671 mil millones de parámetros totales por pasada (Informe técnico de DeepSeek-V3, diciembre de 2024). La eficiencia implícita en esa arquitectura explicaba por qué los costes de inferencia eran tan drásticamente inferiores.
Ese resultado atrajo la atención de los desarrolladores hacia el ecosistema de código abierto chino en general. Resultó que DeepSeek no era una anomalía. La serie Kimi K2 de Moonshot AI lideraba discretamente en los benchmarks de contexto largo. La serie Qwen2.5-Coder de Alibaba encabezaba las clasificaciones específicas de programación. La línea GLM-5 de Zhipu producía salidas estructuradas precisas, vitales para las pipelines de agentes.
La consecuencia práctica para los desarrolladores: cinco laboratorios diferentes lanzan ahora modelos capaces de manejar cargas de trabajo de programación en producción, con pesos abiertos o acceso comercial vía API, a precios muy inferiores a las alternativas propietarias.
Los laboratorios detrás de los mejores LLM de programación de código abierto
DeepSeek: Diseño enfocado en código y eficiencia MoE
DeepSeek AI, fundada en 2023 y respaldada por High-Flyer Capital (un fondo de cobertura cuantitativo chino), integró su enfoque en programación desde el inicio. DeepSeek-Coder fue uno de los primeros modelos dedicados a la generación de código en atraer la atención de la comunidad de código abierto. Las series V3 y V4 ampliaron esto al razonamiento general manteniendo un alto rendimiento en los benchmarks de programación.
La arquitectura MoE merece ser comprendida porque explica los precios. Al activar solo una fracción de los parámetros por token, el coste de computación por solicitud es significativamente menor que el de un modelo denso de calidad equivalente. Esa eficiencia se traslada a los precios de la API, por lo que la tarifa de entrada de 0,23 créditos por mil tokens de DeepSeek V4 Flash es alcanzable sin sacrificar calidad en tareas más simples.
Moonshot AI (Kimi), Zhipu AI (GLM), MiniMax y Alibaba (Qwen)
Moonshot AI (fundada en 2023, Pekín) se ganó su reputación con la inferencia de contexto largo. La serie Kimi K2 cuenta con una ventana de contexto de 262K tokens y está diseñada para tareas con mucho código y documentación donde es crucial integrar una base de código completa en una sola llamada.
Zhipu AI (fundada en 2019, surgida del Laboratorio KEG de la Universidad de Tsinghua) es una de las empresas de IA chinas más antiguas. La serie GLM ha pasado por cinco generaciones, cada iteración mejorando la fiabilidad de la salida estructurada y el seguimiento de instrucciones. GLM-5.1 refleja años de trabajo de alineación en la ejecución precisa de tareas.
MiniMax (fundada en 2021) se expandió del trabajo multimodal a los modelos de programación con la serie M2. MiniMax M2.5 y M2.7 cubren un rango de coste-calidad que satisface bien el segmento medio.
El equipo Qwen de Alibaba construyó Qwen3.6-plus sobre una sólida línea de modelos enfocados en código. La serie ha sido consistentemente fuerte en la generación de código multilingüe, y su ventana de contexto de más de 256K se sitúa en el nivel superior de las opciones disponibles (QwenLM GitHub, 2025).
Comparativa de los mejores LLM de programación de código abierto: Contexto, coste y especificaciones
Aquí está la tabla completa de modelos actuales ordenados por tasa de entrada, para que la estructura de costes sea legible al instante:
| Modelo | Laboratorio | Contexto | Tasa Entrada | Tasa Salida | Cache Write | vs Oficial |
| DeepSeek V4 Flash | DeepSeek AI | 1M | 0.23 | 0.46 | 0.046 | -50% |
| DeepSeek V3.2 | DeepSeek AI | 160K | 0.42 | 0.62 | 0.193 | -55% |
| MiniMax M2.5 | MiniMax | 200K | 0.65 | 2.18 | 0.109 | -45% |
| Kimi K2.5 | Moonshot AI | 262K | 1.09 | 5.45 | 0.182 | -45% |
| Kimi K2.6 | Moonshot AI | 262K | 1.72 | 7.26 | 0.290 | -45% |
| GLM-5 | Zhipu AI | 200K | 1.82 | 5.81 | 0.363 | -45% |
| MiniMax M2.7 | MiniMax | 200K | 2.36 | 4.00 | 0.109 | -45% |
| GLM-5.1 | Zhipu AI | 200K | 2.54 | 7.99 | 0.472 | -45% |
| DeepSeek V4 Pro | DeepSeek AI | 1M | 2.87 | 5.75 | 0.231 | -50% |
| Qwen3.6-plus | Alibaba | 256K+ | 3.30 | 9.90 | 0.660 | -50% |
Las tarifas son créditos por 1.000 tokens. "vs Oficial" es el ahorro en comparación con la tarifa de API directa de cada modelo.
Algunos puntos destacan. Primero, DeepSeek V4 Flash a 0,23 de entrada y V4 Pro a 2,87 son del mismo laboratorio, lo que supone un multiplicador de 12,5x entre el nivel más barato y el más capaz de una misma familia. Segundo, Kimi K2.5 a 1,09 de entrada ofrece una ventana de contexto de 262K a un precio de nivel medio, ideal para trabajo de contexto largo sin saltar a la tarifa completa de V4 Pro. Tercero, la tasa de salida de Qwen3.6-plus a 9,90 es la más alta del grupo, lo que sugiere finalizaciones más largas y exhaustivas como característica de diseño.
Dónde encaja mejor cada LLM de programación chino de código abierto
Esta es la sección práctica. Las tarifas anteriores se traducen en decisiones reales de enrutamiento al ejecutar una sesión de programación con agentes.
Tareas ligeras y de fondo: DeepSeek V4 Flash
Docstrings, cambio de nombre de variables, autocompletados simples, conversiones de formato y todas las llamadas de utilidad que un agente de programación realiza automáticamente en segundo plano. A 0,23 de entrada y 0,46 de salida, es el modelo más barato del grupo con diferencia. Cuando Claude Code enruta tareas de fondo a través del slot del modelo Haiku, configurar ese slot con DeepSeek V4 Flash mantiene el ruido de fondo barato mientras tu sesión principal usa un modelo más capaz.
Programación económica con rendimiento sólido: DeepSeek V3.2 y MiniMax M2.5
DeepSeek V3.2 ofrece la arquitectura V3 con un descuento del 55% sobre las tarifas oficiales y una ventana de contexto de 160K. Para desarrolladores que desean una capacidad sólida sin pagar precios de V4 Pro, V3.2 es una opción práctica. MiniMax M2.5 a 0,65 de entrada ocupa un lugar similar con una ventana de 200K, útil cuando el contexto importa más que el precio más bajo absoluto.
Cargas de trabajo de contexto largo: Kimi K2.5 y K2.6
Ambos modelos Kimi ofrecen ventanas de contexto de 262K. Para analizar grandes porciones de código, historiales largos de conversación o refactorización de múltiples archivos donde necesitas todo en un solo contexto, Kimi K2.5 a 1,09 de entrada te brinda la ventana sin pagar precios flagship. K2.6 (1,72 de entrada) añade capacidad sobre la ventaja de contexto de K2.5 para casos donde la calidad importa más que el coste puro.
Salida estructurada y precisión de instrucciones: GLM-5 y GLM-5.1
Los modelos GLM de Zhipu AI tienen una fortaleza particular en la adherencia a instrucciones. Para pipelines que necesitan una salida estructurada fiable (esquemas JSON específicos, artefactos de código formateados, formas de respuesta API consistentes), vale la pena probar GLM-5 a 1,82 y GLM-5.1 a 2,54 frente a otros modelos. Sus tasas de salida son de las más altas, lo que refleja su tendencia a completar tareas de forma minuciosa y detallada.
Razonamiento avanzado (Flagship): DeepSeek V4 Pro y Qwen3.6-plus
Para decisiones de arquitectura complejas, depuración de interacciones entre múltiples sistemas o tareas donde la calidad de la primera generación es crucial (porque los borradores iniciales pobres causan costosos bucles de reintento), V4 Pro y Qwen3.6-plus son el nivel superior. La ventana de contexto de 1M de V4 Pro es su especificación estrella; Qwen3.6-plus a 256K+ se sitúa en el extremo superior fuera de la familia DeepSeek.
Enrutamiento de modelos: La estrategia de LLM de programación de código abierto más subutilizada
La optimización de mayor impacto para los desarrolladores que utilizan cualquiera de estos LLM chinos no es elegir el mejor modelo único. Es enrutar diferentes tipos de tareas a diferentes niveles dentro de la misma sesión.
Considera una sesión típica de programación con agentes: planificar el enfoque (complejo, requiere V4 Pro), escribir un algoritmo central (complejo, V4 Pro), generar casos de prueba (nivel medio, MiniMax M2.5 o Kimi K2.5), escribir docstrings para funciones nuevas (ligero, V4 Flash), ejecutar observaciones de lectura de archivos (ligero, V4 Flash). Si usaras V4 Pro para todo, cada uno de esos pasos de nivel flash costaría 12,5 veces más de lo necesario.
Las matemáticas son claras. Supongamos que el 60% de las 50 llamadas a la API de tu sesión son tareas simples con una media de 2.000 tokens de entrada y 500 de salida cada una. Ejecutarlas en V4 Flash:
- Coste: 30 llamadas × (2.000 × 0,23 + 500 × 0,46) = 30 × (460 + 230) = 20.700 créditos
Ejecutar las mismas 30 llamadas en V4 Pro:
- Coste: 30 llamadas × (2.000 × 2,87 + 500 × 5,75) = 30 × (5.740 + 2.875) = 258.450 créditos
Es una diferencia de 12,5 veces solo en esas 30 llamadas. El enrutamiento de modelos se paga solo inmediatamente.
Cómo elegir el mejor LLM de programación de código abierto para tu flujo de trabajo
Un árbol de decisión que cubre la mayoría de situaciones de los desarrolladores:
Necesitas el máximo contexto por solicitud: DeepSeek V4 Pro (1M) o Qwen3.6-plus (256K+). Ambos manejan entradas de grandes bases de código sin fragmentación.
El coste es la limitación principal: DeepSeek V4 Flash para tareas simples, DeepSeek V3.2 o MiniMax M2.5 para trabajos de complejidad media.
Necesitas una salida estructurada fiable: Empieza con GLM-5.1 y pruébalo con tus requisitos de esquema específicos.
Estás construyendo una pipeline de agentes de múltiples pasos: Enruta según la complejidad del paso. Usa Flash para pasos de utilidad, Kimi K2.5 o GLM-5 para razonamiento de nivel medio, V4 Pro para planificación y depuración.
Quieres un solo modelo para probar primero: DeepSeek V4 Pro es el predeterminado natural para desarrolladores que evalúan LLM chinos por primera vez. Está bien documentado, tiene la mayor cobertura comunitaria en (r/LocalLLaMA) y ofrece una calidad de programación de alto nivel.
El inconveniente práctico: enrutar entre modelos de forma eficiente requiere que todos estén detrás de la misma clave API y URL base. Mantener diez cuentas API separadas no es viable. Esto es lo que resuelve una pasarela unificada: un punto final, una clave, y la selección del modelo es simplemente un parámetro.
Ejecutando el mejor LLM de programación de código abierto en tus herramientas
El Plan de Programación de Atlas Cloud pone los diez modelos cubiertos en esta guía detrás de una sola clave API y URL base, con tarifas un 45-55% por debajo de sus tarifas de API directas. La configuración para cada herramienta de programación principal sigue a continuación.
Nota sobre la URL base para ahorrarte una sesión de depuración: Claude Code utiliza https://api.atlascloud.ai sin el sufijo /v1. Cualquier otra herramienta (Codex, OpenClaw, OpenCode, Cursor) utiliza https://api.atlascloud.ai/v1 con el sufijo. Cometer un error aquí produce errores de autenticación que no señalan directamente la causa.
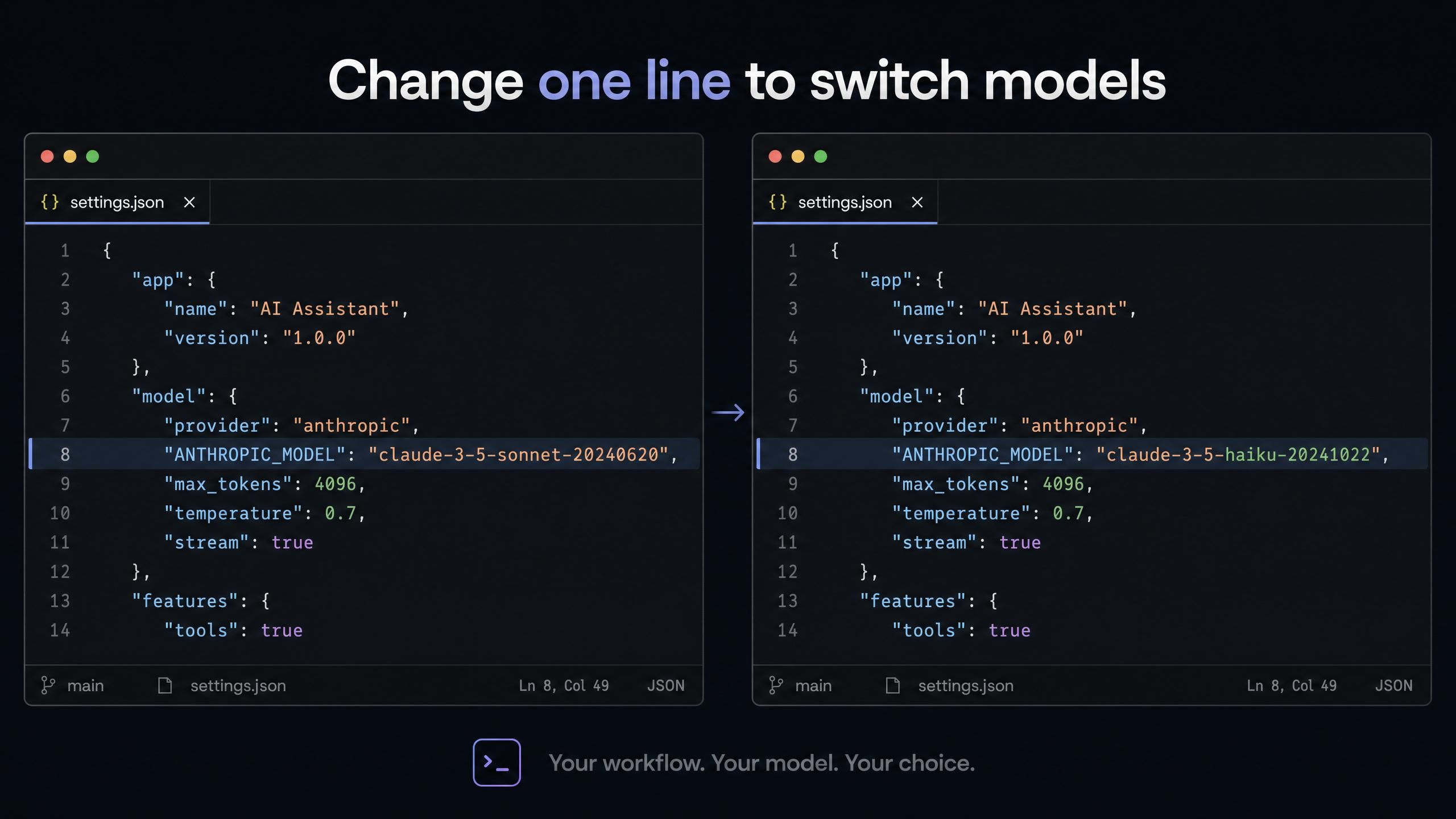
Claude Code (~/.claude/settings.json en macOS/Linux):
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "tu-clave-api-atlas", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "deepseek-ai/deepseek-v4-pro", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-ai/deepseek-v4-flash", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-ai/deepseek-v4-pro", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
El campo ANTHROPIC_DEFAULT_HAIKU_MODEL se asigna al slot de tareas de fondo de Claude Code. Usar DeepSeek V4 Flash ahí significa que todas las llamadas de utilidad automáticas (lecturas de archivos, comprobaciones de estado, observaciones) usan el modelo más barato disponible. Tus prompts principales usan V4 Pro. Obtienes enrutamiento automático sin lógica de enrutamiento compleja.
Para cambiar a GLM-5.1 en lugar de V4 Pro, cambia deepseek-ai/deepseek-v4-pro por zai-org/glm-5.1 en los dos campos Sonnet/main.
Codex (~/.codex/config.toml + ~/.codex/auth.json):
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-pro" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
plaintext1{ 2 "OPENAI_API_KEY": "tu-clave-api-atlas" 3}
OpenClaw: Ejecuta openclaw onboard, selecciona QuickStart, luego Custom Provider. Ingresa https://api.atlascloud.ai/v1 como la URL base, pega tu clave, luego ingresa el ID del modelo (ej. moonshotai/kimi-k2.5) y elige el protocolo compatible con OpenAI.
Cambiar de modelo en cualquiera de estas configuraciones es un cambio de una sola línea. La clave API y la URL base permanecen iguales sin importar qué modelo selecciones.
Mejor LLM de programación de código abierto: Preguntas comunes
¿Es DeepSeek realmente el mejor LLM de programación de código abierto?
Para la mayoría de los desarrolladores que empiezan, DeepSeek V4 Pro es la primera opción natural debido a su cobertura comunitaria, historial de benchmarks y la combinación de una ventana de contexto de 1M con precios competitivos. Pero "mejor" depende en gran medida de tu tipo de tarea. Para trabajos de contexto largo, Kimi K2.5 o K2.6 ofrecen 262K tokens a un precio menor. Para tareas de salida estructurada, GLM-5.1 merece ser probado. El punto es que "mejor" cambia dependiendo de lo que estés construyendo.
¿Cómo se comparan estos modelos con Claude Sonnet o GPT-4o en programación?
En benchmarks de programación estándar, la brecha entre los mejores modelos de código abierto y los modelos propietarios de EE. UU. se ha reducido considerablemente desde 2024. DeepSeek V3 igualó a Claude 3.5 Sonnet en varios benchmarks en su lanzamiento. Donde los modelos propietarios mantienen ventaja es en la interpretación matizada de instrucciones y tareas que se benefician de una extensa afinación mediante RLHF (aprendizaje por refuerzo a partir de la retroalimentación humana). Para la gran mayoría de las tareas de generación de código, refactorización y depuración, la diferencia práctica para la mayoría de los desarrolladores es pequeña.
¿Puedo usar varios LLM de programación de código abierto en la misma pipeline?
Sí. Cuando todos los modelos comparten la misma URL base y clave API a través de una pasarela, puedes especificar un ID de modelo diferente por solicitud. En la práctica, esto significa que puedes usar DeepSeek V4 Flash para un paso, Kimi K2.5 para otro y V4 Pro para un tercero, todo dentro de un flujo de trabajo automatizado, sin gestionar múltiples cuentas o contextos de autenticación.
¿Qué modelo debería probar primero si nunca he usado un LLM de código abierto?
Empieza con DeepSeek V4 Pro. Tiene la mayor documentación, la discusión comunitaria más amplia y el perfil de rendimiento más claro. Una vez que hayas establecido una base en tus tareas reales, prueba Kimi K2.5 en pasos con mucho contexto y DeepSeek V4 Flash en llamadas de utilidad de fondo. La diferencia de coste entre esas dos pruebas te mostrará si el enrutamiento de modelos tiene sentido para tu flujo de trabajo.
¿Son seguros los LLM de código abierto para código empresarial?
Esto depende de tu modelo de despliegue. Para acceso basado en API a través de una pasarela de terceros, se aplican las políticas de manejo de datos de esa pasarela. Los modelos de pesos abiertos que pueden ser autohospedados te dan un control total sobre dónde va tu código. Los desarrolladores en r/LocalLLaMA han discutido esto extensamente, y el consenso es que el uso basado en API necesita el mismo escrutinio de manejo de datos que aplicarías a cualquier API de terceros, no una categoría especial de preocupación.
La conclusión sobre los mejores LLM de programación de código abierto
Cinco laboratorios lanzan ahora modelos capaces de manejar trabajos serios de programación en producción, y abarcan un rango de costes y capacidades lo suficientemente amplio como para que la selección de un modelo "talla única" te haga perder dinero.
El manual práctico: elige una pasarela que te dé acceso a todos ellos bajo una sola clave, establece tu línea base en DeepSeek V4 Pro y luego usa la guía de enrutamiento anterior para mover tareas más simples a niveles más baratos. Para la mayoría de los desarrolladores que ejecutan sesiones de programación con agentes, ese enrutamiento por sí solo reduce los costes significativamente sin cambiar la calidad de la salida en las tareas que importan.
Las especificaciones y tarifas de los modelos se basan en la documentación del Plan de Programación de Atlas Cloud a fecha de mayo de 2026. Cifras de benchmark de DeepSeek V3 del Informe Técnico de DeepSeek-V3, diciembre de 2024. Las tarifas están sujetas a cambios; verifica las cifras actuales con cada proveedor antes de comprometerte con una decisión de facturación.






