
La mayoría de los desarrolladores asumen que la CLI de Codex funciona como un chatbot: envías un mensaje, el modelo responde y listo. Eso no es lo que sucede. Codex ejecuta un bucle de agente, lo que significa que cada tarea implica múltiples llamadas a la API y la ventana de contexto se expande con cada iteración. Para cuando Codex termina una tarea de complejidad moderada, el recuento total de tokens suele ser de tres a cinco veces mayor de lo que esperarías de una sola llamada.
Esa es la causa raíz detrás de casi todas las historias de "alcancé mi límite". No estás luchando contra una política de límite de velocidad. Estás lidiando con la economía natural de un flujo de trabajo de agentes, y esa economía se complica rápidamente.
Una vez que entiendes de dónde proviene realmente el costo, las soluciones alternativas se vuelven obvias en lugar de ser un juego de adivinanzas.
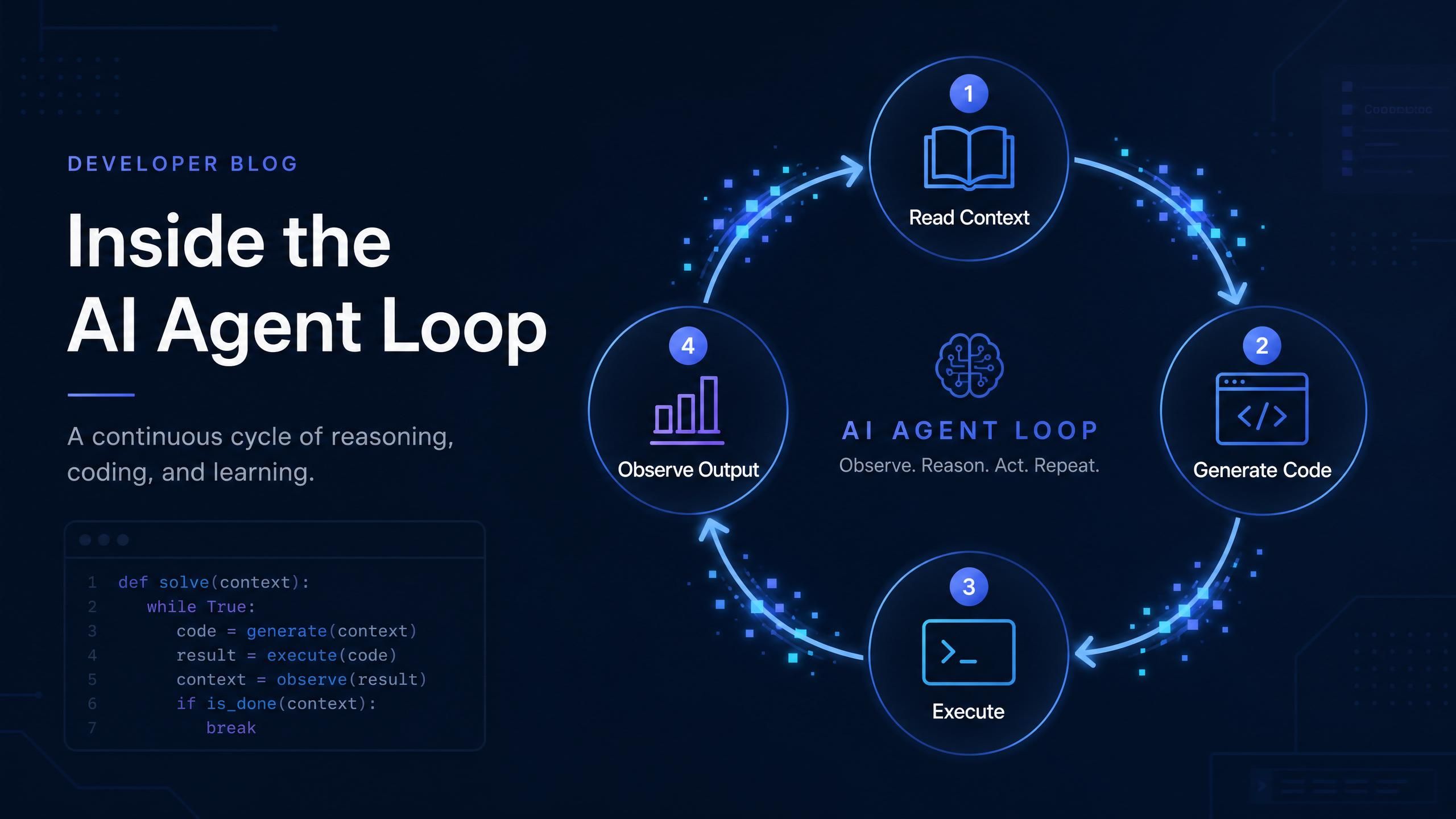
Cómo construye realmente Codex CLI el costo a lo largo de una sesión
Una tarea típica de Codex que toma cuatro iteraciones no cuesta 4 veces el precio de una llamada. Cuesta considerablemente más, porque el contexto crece con cada turno.
Esto es lo que sucede detrás de escena. En la primera iteración, Codex lee los archivos de tu proyecto más la descripción de tu tarea, envía aproximadamente de 5.000 a 7.000 tokens de entrada al modelo y obtiene una respuesta. En la segunda iteración, incluye el historial de la conversación previa más nuevas observaciones de la ejecución del código generado. El recuento de tokens de entrada para esa llamada podría saltar a 8.000 o 10.000. Para la cuarta iteración, el contexto acumulado podría ser de 14.000 tokens de entrada para lo que, teóricamente, sigue siendo la misma tarea.
Crecimiento del contexto en una tarea de Codex de 4 iteraciones
| Iteración | Tokens de entrada |
|---|---|
| Iteración 1 | ~5.000 |
| Iteración 2 | ~7.000 |
| Iteración 3 | ~9.500 |
| Iteración 4 | ~14.000 |
| Total | ~35.500 |
El tamaño del contexto aumenta a través de las iteraciones en una sesión de agente. Una tarea de 4 iteraciones podría consumir 35.500 tokens de entrada totales frente a los 5.000 de una llamada de un solo turno. Los recuentos reales varían según el tamaño del proyecto y el contexto del archivo.
La implicación práctica: una tarea de cuatro iteraciones no cuesta 4 veces una llamada de un solo turno. El contexto creciente significa que cuesta cerca de 7 u 8 veces más. Para este ejemplo, eso es aproximadamente 35.500 tokens de entrada y 4.000 tokens de salida a lo largo de toda la tarea. El modelo que elijas determinará si esa tarea te cuesta 9.000 créditos o 120.000 créditos, en la misma CLI de Codex con la misma descripción de tarea.
Esa diferencia de 13x es donde reside la verdadera solución a los límites de uso de Codex: no en la limitación de solicitudes (throttling), sino en elegir qué modelo ejecuta el bucle.
Solución a los límites de uso de Codex: delimitación de archivos antes que nada
Esta es la optimización que no cuesta nada y tiene el efecto inmediato más grande.
Codex lee los archivos de tu proyecto para construir el contexto antes de realizar cualquier llamada a la API. Respeta tu .gitignore, pero la mayoría de las bases de código tienen grandes cantidades de contenido que .gitignore no excluye: archivos de declaración de tipos, documentación de proveedores, directorios de salida compilados, fixtures de prueba, datos de seed, CSS o SVG generados. Todo eso aterriza en la ventana de contexto de la primera iteración y aumenta el costo base de cada llamada posterior.
La solución es la exclusión deliberada. Agrega un archivo .codexignore a la raíz de tu proyecto, usando la misma sintaxis que .gitignore. Patrones comunes que vale la pena agregar:
plaintext1dist/ 2.next/ 3build/ 4node_modules/ # en caso de que .gitignore tenga lagunas 5*.d.ts # archivos de declaración de TypeScript 6*.min.js 7*.min.css 8test/fixtures/ 9test/snapshots/ 10docs/vendor/
Alternativamente, cuando la tarea se limita a un módulo específico, ejecuta Codex desde dentro de ese directorio en lugar de la raíz del proyecto. El agente lee desde su directorio de trabajo, por lo que una sesión de cd packages/auth && codex solo ve los archivos de ese paquete en lugar de todo el monorepo.
Los desarrolladores que discuten esto en r/LocalLLaMA informan constantemente que el contexto de archivos no controlado es el principal impulsor del gasto inesperado en la API con herramientas de agentes. Hacer esto bien antes de tocar cualquier otra configuración generalmente reduce el recuento de tokens por sesión entre un 30 y un 60 por ciento en proyectos de tamaño mediano.
Ejecutar Codex desde el subdirectorio del paquete relevante en lugar de la raíz del monorepo en un proyecto multipaquete redujo el contexto por tarea de ~18.000 tokens a ~5.000 tokens en la primera llamada. Esa diferencia se acumula en cada iteración.
La solución a los límites de uso de Codex que cambia la matemática a largo plazo
Una vez que hayas ajustado el contexto de los archivos, la siguiente solución estructural es el modelo que estás ejecutando.
Codex CLI admite proveedores de API personalizados a través de su config.toml. Cualquier proveedor que implemente el formato de chat completions de OpenAI funciona como un reemplazo directo. Esto significa que puedes ejecutar exactamente el mismo flujo de trabajo de Codex CLI, pero con la potencia de un modelo diferente a un costo por token sustancialmente distinto.
¿Por qué importa esto? Porque el multiplicador de créditos (o la tasa por token) se multiplica por cada token en cada iteración. En una tarea de 4 iteraciones que consume 35.500 tokens de entrada y 4.000 tokens de salida, cambiar de un modelo de multiplicador alto a uno de multiplicador bajo no es un pequeño ajuste. Es la diferencia entre consumir 9.545 créditos y 119.145 créditos para la misma tarea.
El Coding Plan de Atlas Cloud ofrece un conjunto de modelos de código abierto con un 45 a 55 por ciento de descuento sobre las tarifas oficiales de la API, todo accesible a través de una sola clave de API en un endpoint compatible con OpenAI. Apuntas Codex a https://api.atlascloud.ai/v1, configuras tu ID de modelo, y nada más en tu flujo de trabajo cambia.
Leyendo los multiplicadores: qué solución a los límites de uso de Codex se adapta a cada tarea
Aquí están las matemáticas que hacen que la selección del modelo sea concreta. Usando nuestra tarea de 4 iteraciones (35.500 tokens de entrada, 4.000 tokens de salida en total), aquí está el costo en créditos por tarea entre los modelos disponibles:
Créditos por tarea de Codex de 4 iteraciones según el modelo
| Modelo | Créditos / Tarea | vs. Más barato |
|---|---|---|
| deepseek-v4-flash | 9.545 | 🟢 línea base |
| deepseek-v3.2 | 17.390 | 1.8x |
| minimax-m2.5 | 31.845 | 3.3x |
| kimi-k2.5 | 60.695 | 6.4x |
| deepseek-v4-pro | 119.145 | 12.5x |
| glm-5.1 | 122.025 | 12.8x |
Fuente: Calculado utilizando multiplicadores publicados por Atlas Cloud, junio de 2026. DeepSeek V4-Flash a 9.545 es 12.5 veces más barato por tarea que DeepSeek V4-Pro a 119.145 para sesiones donde cualquiera de los dos modelos completaría la tarea.
Con 800.000 créditos diarios en el plan Starter ($10/mes), puedes ejecutar:
- DeepSeek V4-Flash: 800.000 / 9.545 = 83 tareas de cuatro iteraciones por día
- DeepSeek V4-Pro: 800.000 / 119.145 = 6,7 tareas por día
En el plan Lite ($20/mes, 2,2 millones de créditos por día según la configuración actual del nivel):
- DeepSeek V4-Flash: 2.200.000 / 9.545 = 230 tareas por día
- DeepSeek V4-Pro: 2.200.000 / 119.145 = 18 tareas por día
El marco de trabajo práctico es el siguiente: DeepSeek V4-Flash maneja bien la gran mayoría de las tareas de Codex. Escribir funciones de utilidad, generar pruebas, corregir errores de lint, renombrar variables, crear boilerplate: estas no requieren una capacidad de razonamiento de frontera. V4-Flash admite una ventana de contexto de 1 millón de tokens y completa estas tareas con competencia. Vale la pena recurrir a V4-Pro y Kimi K2 para problemas genuinamente difíciles: refactorización compleja de múltiples archivos, depuración de problemas oscuros en producción, trabajo con frameworks desconocidos.
Usar el modelo correcto para la tarea correcta no es una concesión en cuanto a calidad. Es no usar un mazo para clavar un clavo pequeño.
La diferencia entre V4-Flash y V4-Pro no es solo "barato vs. calidad". En las tareas rutinarias de Codex, la diferencia de calidad es marginal. La diferencia de costo es de 12.5 veces. Reservar V4-Pro para sesiones genuinamente complejas es la optimización de mayor apalancamiento después de la delimitación de archivos.
Solución a los límites de uso de Codex mediante límites de sesión
Un cambio de comportamiento que se acumula significativamente durante una semana: sé deliberado acerca de cuándo iniciar una nueva sesión de Codex en lugar de continuar con una existente.
Cada sesión acumula el historial de la conversación. Cuanto más larga sea la sesión, mayor será el contexto base para cada llamada posterior. Una sesión que comienza con un primer turno de 5.000 tokens y se ejecuta durante seis intercambios podría tener un contexto de 18.000 tokens al final. Si cambias a una tarea nueva y no relacionada dentro de esa misma sesión, ahora estás pagando por incluir todo ese contexto previo irrelevante en cada nueva llamada.
Iniciar una sesión nueva no cuesta nada. Codex se inicializa limpio y solo lee los archivos relevantes para tu directorio de trabajo actual. La regla general aproximada:
- ¿Tarea completada limpiamente y la siguiente es independiente? Empieza de cero.
- ¿Cambiando de un módulo a otro sin código compartido? Empieza de cero.
- ¿Continuando iterando en el mismo archivo con el mismo objetivo? Sigue adelante.
- ¿Transicionando de la implementación a la documentación? Empieza de cero.
Esto es menos dramático que la delimitación de archivos o la selección de modelos, pero se suma a ahorros significativos durante una semana laboral completa, especialmente durante sprints intensivos.
Solución a los límites de uso de Codex: cómo funcionan en la práctica los créditos con reinicio diario
Entender el modelo de facturación te ayuda a planificar el uso de manera realista.
Un fondo de créditos de API estándar te da X tokens por mes para gastar como quieras. El problema estructural: los días de mucha programación agotan el fondo rápidamente, dejando el resto del mes con menos margen del que planeaste. Si consumes el 40 por ciento de tu presupuesto mensual en dos días de sprint intensivo, estarás gestionando ese déficit durante las siguientes tres semanas.
El modelo de reinicio diario funciona de manera diferente. Obtienes un número establecido de créditos por día y se actualizan a medianoche, independientemente de lo poco que hayas usado el día anterior. Un martes ligero no penaliza un jueves pesado. Cada día comienza con el mismo presupuesto diario completo.
Asignación diaria de créditos por nivel de plan
Todos los niveles se reinician diariamente a medianoche · Los paquetes de pago por uso se acumulan encima como desbordamiento
| Plan | Precio | Créditos diarios |
|---|---|---|
| Starter | $10 / mes | 800K / día |
| Lite | $20 / mes | 2,2M / día |
| Plus | $50 / mes | 4,8M / día |
| Max | $100 / mes | 9,8M / día |
Fuente: Coding Plan de Atlas Cloud, junio de 2026 · Los créditos no utilizados no se acumulan, pero tampoco comienzas nunca un día con un presupuesto agotado por sesiones pesadas anteriores.
Cuando tus créditos diarios se agotan en una sesión particularmente intensa, los paquetes de recarga de pago por uso llenan el vacío automáticamente. Estos paquetes son válidos por 90 días, puedes acumular múltiples paquetes simultáneamente y solo se utilizan después de que tus créditos de suscripción diaria se hayan agotado. La suscripción cubre tu línea base; los paquetes cubren el desbordamiento.
La actualización entre niveles se prorratea si cambias de opinión a mitad del ciclo. La fórmula es sencilla: (precio nuevo - precio actual) × (días restantes / 30). Pasar de Starter a Lite con 14 días restantes cuesta ($20 - $10) × (14 / 30) = $4,67. El límite de crédito diario más alto se aplica inmediatamente una vez que actualizas.
Configuración de tu solución a los límites de uso de Codex: configuración completa
La configuración para apuntar Codex CLI a un proveedor personalizado consiste en dos archivos. En macOS o Linux:
Paso 1: Crea o edita ~/.codex/config.toml
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-flash" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
Paso 2: Crea o edita ~/.codex/auth.json
plaintext1{ 2 "OPENAI_API_KEY": "tu-clave-de-api-de-atlas" 3}
La bandera requires_openai_auth = true le dice a Codex que lea la clave de API del campo OPENAI_API_KEY en auth.json. Tu clave de API proviene del panel de gestión de planes en Atlas Cloud después de comprar un Coding Plan.
Para cambiar de modelo para una sesión específica, cambia la línea model en config.toml. Si deseas utilizar un modelo más pesado para una tarea compleja, cambia a deepseek-ai/deepseek-v4-pro o moonshotai/kimi-k2.6 y vuelve a cambiar al modelo más ligero después. Es una edición de una sola línea.
Después de la configuración, inicia Codex normalmente:
plaintext1codex
Selecciona la opción para omitir la verificación de actualización, y estarás ejecutando Codex con los modelos de Atlas Cloud. La interfaz y los comandos son idénticos a la experiencia predeterminada de Codex.
Preguntas frecuentes sobre las soluciones a los límites de uso de Codex
¿Por qué Codex usa más tokens de los que espero por tarea?
Codex ejecuta un bucle de agente en lugar de una sola llamada a la API. Cada iteración incluye el historial de conversación acumulado más nuevas observaciones de la ejecución del código. En una tarea de cuatro iteraciones, la ventana de contexto en la iteración cuatro podría ser el doble del tamaño de la iteración uno. El consumo total de tokens en todas las iteraciones suele ser de tres a cinco veces lo que costaría una sola llamada para la misma tarea.
¿Cuál es la mejor solución a los límites de uso de Codex para alguien que recién comienza?
Comienza con la delimitación de archivos: agrega un archivo .codexignore para excluir directorios dist/, build/, archivos *.d.ts, fixtures de prueba y otro contenido que no sea de carga. Esto es gratuito y generalmente reduce el tamaño del contexto entre un 30 y un 60 por ciento en proyectos de tamaño mediano. Una vez que hayas hecho eso, el siguiente cambio más impactante es cambiar a un modelo de bajo multiplicador como DeepSeek V4-Flash para tareas rutinarias, lo que reduce el consumo de créditos por tarea hasta en 12 veces en comparación con modelos más pesados en las mismas sesiones.
¿Puedo ejecutar Codex con Atlas Cloud en Windows?
Sí. En Windows, coloca tus archivos de configuración en %USERPROFILE%.codex\config.toml y %USERPROFILE%.codex\auth.json. El formato de archivo y los nombres de campo son idénticos a las versiones de macOS/Linux. La URL base, la clave de API y el ID de modelo funcionan igual en todas las plataformas.
¿Qué sucede cuando se agota mi asignación diaria de créditos?
Si tienes paquetes de crédito de pago por uso activos, el uso continúa automáticamente extrayendo de esos paquetes una vez que se agotan tus créditos de suscripción diaria. Si no tienes paquetes, las solicitudes adicionales serán rechazadas hasta que tus créditos diarios se actualicen a medianoche. Puedes comprar paquetes de recarga en cualquier momento desde el panel de control del plan; se activan inmediatamente y son válidos por 90 días.
¿Necesito cambiar mi flujo de trabajo de Codex después de apuntarlo a un proveedor personalizado?
No. Los comandos, las banderas y el comportamiento de Codex CLI son idénticos independientemente del proveedor subyacente. La única diferencia visible es el modelo que responde a tus tareas. Si has configurado un modelo en el que Codex no se entrenó de forma nativa, las respuestas pueden sentirse ligeramente diferentes en estilo, pero la operación de la herramienta sigue siendo la misma. La mayoría de los desarrolladores no notan ninguna interrupción en el flujo de trabajo después del cambio de configuración inicial.
Conclusión
La visión central en este artículo es que los costos de Codex CLI no son misteriosos. Provienen de un lugar predecible: un contexto que crece a través de iteraciones, multiplicado por cualquier tarifa por token que cobre tu modelo. Una vez que ves eso claramente, las intervenciones son mecánicas:
- Reduce lo que lee Codex mediante la delimitación de archivos (gratis, alto impacto)
- Ajusta el modelo a la complejidad de la tarea (cambia el costo hasta en 12 veces por tarea)
- Inicia sesiones nuevas cuando las tareas sean independientes (evita el aumento de contexto acumulado)
- Utiliza un plan de crédito de reinicio diario para evitar el problema de agotamiento a mitad de mes
Cualquiera de estas ayuda. Las cuatro juntas hacen que Codex sea sostenible para el uso diario intenso sin alcanzar límites ni ver cómo tu factura de API sube de forma impredecible.
Si deseas probar la ruta del proveedor personalizado, el Coding Plan de Atlas Cloud admite Codex junto con Claude Code, OpenCode, Cursor y llamadas directas a la API. El nivel Starter a $10/mes y 800K créditos diarios es un punto de partida razonable; puedes actualizar a mitad del ciclo de forma prorrateada si necesitas más.
Elegir entre DeepSeek V4-Flash y V4-Pro para diferentes tipos de tareas de Codex → guía para la selección de modelos para flujos de trabajo de codificación de agentes






