
Si estás evaluando modelos de código abierto para tareas de programación, razonamiento o pipelines de agentes, tanto Kimi K2.6 como GLM 5.1 aparecerán en tu lista de candidatos. Ambos provienen de laboratorios de IA chinos líderes, funcionan con APIs compatibles con OpenAI y son capaces de manejar el tipo de tareas complejas que realmente interesan a los desarrolladores.
El problema es que no son intercambiables. Tienen diferentes ventanas de contexto, estructuras de costos y puntos fuertes que se manifiestan en casos de uso específicos. Elegir el modelo incorrecto para tu carga de trabajo significa que estarás desperdiciando rendimiento o pagando de más por una capacidad que no necesitas.
Este artículo desglosa las diferencias reales entre ambos modelos: qué significan los números en la práctica, dónde destaca cada uno y dónde no, y cómo se ven los costos al ejecutar cualquiera de ellos a escala.

Kimi K2.6 vs GLM 5.1: Resumen rápido
Kimi K2.6 es el modelo más reciente de Moonshot AI en su serie K2, su línea insignia actual. Moonshot es la empresa detrás del asistente Kimi, y K2.6 es su apuesta por el razonamiento de contexto largo y precios competitivos. Su ventana de contexto de 262K es una de sus características principales.
GLM 5.1 proviene de Zhipu AI, una de las organizaciones de investigación en IA más consolidadas de China. La serie GLM (General Language Model) ha evolucionado a través de varias generaciones, y la 5.1 es la oferta actual de primer nivel de Zhipu. Goza de una sólida reputación en la comunidad de código abierto por su precisión al seguir instrucciones y la calidad de sus salidas estructuradas.
Ambos modelos exponen una API compatible con OpenAI, por lo que conectarlos a herramientas como Claude Code, Codex o OpenClaw es sencillo. La elección se reduce a tres factores reales: cuánto contexto necesitas por solicitud, cómo se ven tus costos de tokens al volumen esperado y si tus tareas se inclinan hacia las fortalezas relativas de cada modelo.
Los modelos detrás de los nombres
Comparativa de ventanas de contexto: Kimi K2.6 vs GLM 5.1
La ventana de contexto es uno de los diferenciadores más claros y objetivos aquí. Kimi K2.6 admite una ventana de contexto de 262K tokens, mientras que GLM 5.1 admite 200K. Es una diferencia del 31% en la capacidad máxima de entrada.
Para tareas de codificación típicas, ninguno de los dos modelos alcanza esos límites en el día a día. Una revisión de código estándar, una sesión de depuración o una solicitud de generación de documentación cabrán cómodamente en ambas ventanas. La brecha se vuelve significativa en escenarios específicos:
- Análisis de grandes bases de código: Pasar decenas de miles de líneas en una sola solicitud para refactorización o revisión de arquitectura.
- Sesiones largas con agentes: Conversaciones que acumulan un contexto sustancial a lo largo de muchos turnos y llamadas a herramientas.
- Pipelines con muchos documentos: Tareas de investigación, resumen o análisis que requieren grandes bloques de texto en una sola llamada.
Si tu carga de trabajo se acerca regularmente a los límites de contexto con otros modelos, la ventana de 262K de Kimi K2.6 te da más margen antes de tener que implementar lógica de fragmentación (chunking) o resumen de contexto. Si tus solicitudes típicas son inferiores a 50K tokens, ambos modelos ofrecen capacidad de sobra y la diferencia de ventana deja de ser un factor relevante.

Fortalezas en codificación y razonamiento
Ambos modelos son capaces en tareas de programación, aunque sus prioridades de diseño generan comportamientos distintos en la práctica.
Kimi K2.6 está diseñado para la comprensión de contexto largo. Esto lo hace muy adecuado para la refactorización de múltiples archivos, entender cómo los cambios en una parte del código afectan a otras y cadenas de razonamiento extendidas donde el modelo necesita mantener mucho estado a lo largo de varios pasos. Moonshot AI ha posicionado a K2.6 específicamente para estos casos de uso.
GLM 5.1 se centra en el enfoque de Zhipu AI: seguimiento preciso de instrucciones y salidas estructuradas. Tareas como generar código siguiendo especificaciones detalladas, producir formatos estructurados a partir de lenguaje natural o gestionar esquemas complejos de llamadas a herramientas aprovechan sus fortalezas. Su tasa de salida ligeramente más alta en los precios (7.99 vs 7.26) también sugiere una tendencia hacia completados más exhaustivos y detallados.
Para la mayoría de los desarrolladores que comparan ambos, la diferencia de rendimiento en tareas de codificación habituales es menor de lo que cabría esperar por la marca de cada empresa. Los diferenciadores más claros están en las especificaciones y el costo, donde los números son concretos.
Kimi K2.6 vs GLM 5.1: Costos de tokens y tasas de crédito
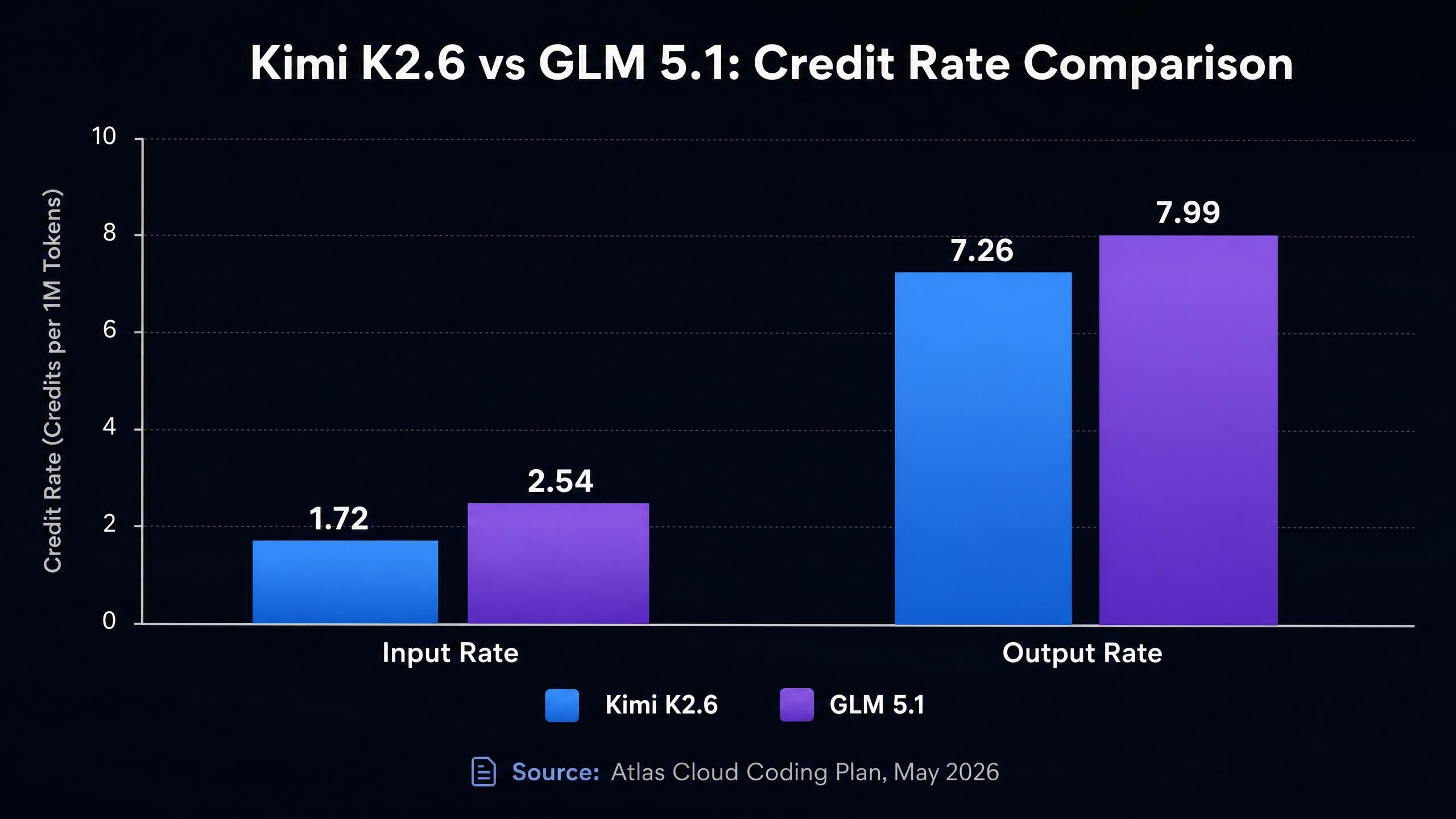
Aquí es donde la comparación se vuelve específica. Ambos modelos están disponibles a través del Plan de Codificación de Atlas Cloud, y las tasas de crédito son las siguientes (Plan de Codificación de Atlas Cloud, mayo de 2026):
| Modelo | Contexto | Tasa Entr. | Tasa Sal. | Caché Escrit. | vs. Oficial |
| Kimi K2.6 | 262K | 1.72 | 7.26 | 0.290 | 45% más barato |
| GLM 5.1 | 200K | 2.54 | 7.99 | 0.472 | 45% más barato |
Algunos puntos destacan.
La tasa de entrada de GLM 5.1 (2.54) es aproximadamente un 48% más alta que la de Kimi K2.6 (1.72). En contextos de programación donde pasas contenidos de archivos, historiales de código extensos o largas acumulaciones de conversación, los tokens de entrada suelen representar la mayor parte de tu costo. Un pipeline que ejecute 1,000 solicitudes al día con 10K tokens de entrada por solicitud costaría aproximadamente un 48% más en entrada con GLM 5.1 que con Kimi K2.6.
Las tasas de salida son más cercanas, pero siguen favoreciendo a Kimi K2.6 (7.26 vs 7.99, una brecha del 10%). Las tasas de escritura en caché también favorecen a Kimi K2.6 (0.290 vs 0.472), lo que se nota en flujos de trabajo que utilizan caché de prompts para prompts del sistema repetidos o contexto estático.
Poniendo ambos datos juntos: para una solicitud con 5,000 tokens de entrada y 1,000 tokens de salida, los costos en créditos son:
- Kimi K2.6: (5,000 × 1.72) + (1,000 × 7.26) = 8,600 + 7,260 = 15,860 créditos
- GLM 5.1: (5,000 × 2.54) + (1,000 × 7.99) = 12,700 + 7,990 = 20,690 créditos
Kimi K2.6 es aproximadamente un 23% más barato por solicitud en esta relación de entrada/salida. A gran volumen, esto se traduce en una diferencia presupuestaria real.
Ambos modelos tienen un precio un 45% inferior a sus tarifas oficiales de API a través de la pasarela, lo cual es constante en este nivel de modelos.
Kimi K2.6 vs GLM 5.1 en flujos de trabajo con agentes
Las herramientas de agentes amplifican cada diferencia de costo y capacidad entre modelos.
En un agente de programación de varios pasos, cada llamada a la herramienta es una solicitud de API independiente. Cada solicitud lleva el contexto de entrada de la conversación acumulada, genera una salida que alimenta el siguiente paso y aumenta tu factura total. Un flujo de trabajo que ejecuta 40 llamadas a la API en una sesión no solo cuesta 40 veces el precio de una sola solicitud; también acumula contexto rápidamente, lo que aumenta el número de tokens de entrada a medida que avanza la sesión.
Donde Kimi K2.6 tiende a comportarse mejor en agentes: Sesiones largas donde el contexto acumulado crece mucho, tareas que implican leer y modificar archivos de código grandes, y pipelines donde mantener costos razonables a través de muchas llamadas es vital. La ventana de contexto más amplia también implica menos reinicios de sesión, lo que interrumpe menos la memoria de trabajo del agente.
Donde GLM 5.1 tiende a funcionar mejor: Pipelines donde cada paso requiere una salida precisa y bien estructurada, y donde la precisión de las instrucciones en cada llamada individual importa más que la profundidad del contexto en toda la sesión. Si tu agente necesita generar código siguiendo esquemas de tipos estrictos, gestionar firmas de funciones complejas o producir una salida formateada consistente en cada turno, las fortalezas de GLM 5.1 al seguir instrucciones son más relevantes.
Ambos modelos funcionan perfectamente con Claude Code, Codex, OpenClaw y Cursor mediante configuraciones estándar compatibles con OpenAI. La integración es idéntica; solo cambia el ID del modelo.
Cómo ejecutar ambos y elegir el que realmente funciona para ti
Kimi K2.6 vs GLM 5.1: Eligiendo sin adivinar
La forma más fiable de decidir entre estos dos modelos no es leer artículos de comparación (incluido este). Es ejecutar ambos en tus tareas reales y comparar la calidad de la salida tú mismo. La buena noticia es que es fácil hacerlo cuando ambos modelos se encuentran detrás de la misma clave API y URL base.
El Plan de Codificación de Atlas Cloud coloca a Kimi K2.6 y GLM 5.1 en el mismo endpoint bajo una única clave API. Cambiar entre ellos es un cambio de configuración de una sola línea, lo que significa que puedes ejecutar tu carga de trabajo real en ambos modelos sucesivamente sin reconstruir ninguna integración.
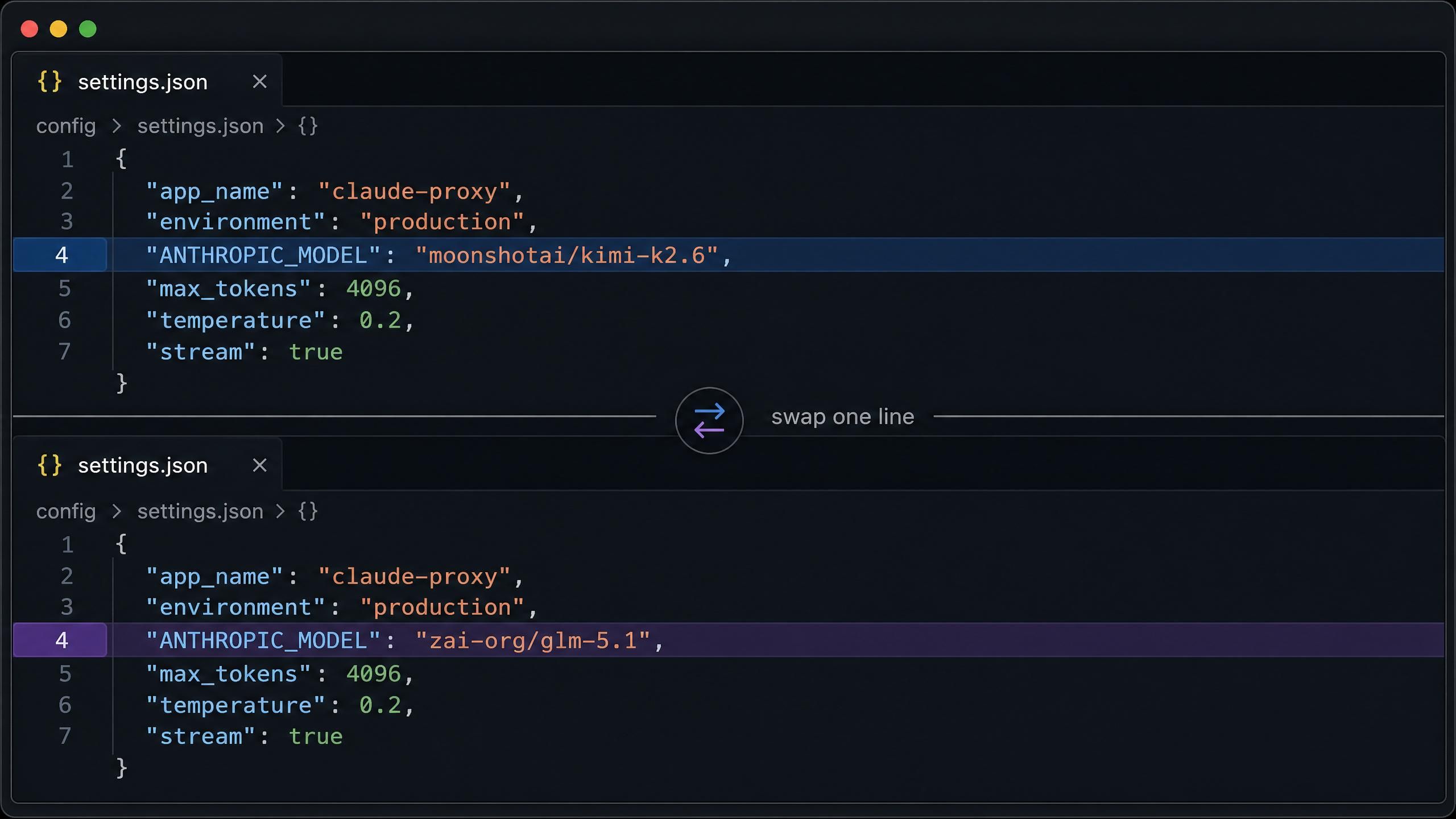
Para Claude Code en macOS o Linux, la configuración completa va en ~/.claude/settings.json. Configúralo primero en Kimi K2.6:
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "tu-clave-api-atlas", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "moonshotai/kimi-k2.6", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "moonshotai/kimi-k2.6", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "moonshotai/kimi-k2.6", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Para cambiar a GLM 5.1, cambia moonshotai/kimi-k2.6 por zai-org/glm-5.1 en los tres campos de modelo. Todo lo demás permanece igual. Ten en cuenta que la URL base de Claude Code es https://api.atlascloud.ai sin el sufijo /v1.
Para Codex, la configuración se divide en dos archivos. ~/.codex/config.toml:
plaintext1model_provider = "atlas_coding_plan" 2model = "moonshotai/kimi-k2.6" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
~/.codex/auth.json:
plaintext1{ 2 "OPENAI_API_KEY": "tu-clave-api-atlas" 3}
Para OpenClaw, ejecuta openclaw onboard, elige QuickStart y luego Custom Provider. Introduce https://api.atlascloud.ai/v1 como la URL base, pega tu clave Atlas y selecciona el ID del modelo que quieres probar.
El plan de Atlas Cloud viene en dos formatos: suscripción mensual con recarga diaria de créditos (mejor para uso diario constante) y un paquete de pago por uso con una ventana de 90 días (mejor para cargas de trabajo variables o experimentales). Dado que probablemente estarás probando ambos modelos, la opción de pago por uso te brinda flexibilidad sin comprometerte a un volumen mensual.
Kimi K2.6 vs GLM 5.1: Preguntas frecuentes
¿Qué modelo cuesta menos ejecutar a escala?
Kimi K2.6 es más barato por token tanto en entrada como en salida. La brecha es mayor en la entrada (la tasa de entrada de GLM 5.1 es aproximadamente un 48% más alta), lo cual es crucial en flujos de trabajo de programación que envían grandes cantidades de contexto. A altos volúmenes de solicitudes, esto se traduce en una diferencia presupuestaria significativa.
¿Qué modelo maneja mejor las tareas en chino?
Ambos modelos tienen capacidades sólidas en el idioma chino, como es de esperar dado su origen. GLM 5.1 de Zhipu AI tiene un historial particularmente consolidado en tareas en chino, construido a lo largo de varias generaciones de la serie GLM. Kimi K2.6 también maneja bien el chino debido al enfoque de producto de Moonshot AI en los usuarios chinos. Para tareas principalmente en chino, ambos son sólidos, con una ligera ventaja para GLM 5.1 basada en su trayectoria.
¿Puedo mezclar ambos modelos en el mismo pipeline?
Sí. A través de una pasarela unificada, puedes dirigir diferentes pasos en el mismo pipeline a diferentes modelos cambiando solo el parámetro del modelo por solicitud. Podrías usar Kimi K2.6 para pasos de análisis con mucho contexto (menor costo de entrada, ventana más amplia) y GLM 5.1 para pasos de generación de salida estructurada (mejor seguimiento de instrucciones), todo con una sola clave API.
¿Vale la pena prestar atención a la diferencia de contexto de 262K vs 200K?
Para la mayoría de las tareas de programación diarias, no. Ambas ventanas son lo suficientemente grandes para las solicitudes típicas. La diferencia importa si tus sesiones acumulan regularmente 150-200K tokens, si pasas archivos de código grandes para su análisis o si ejecutas sesiones de agentes largas sin reinicios. Si raramente alcanzas los 50K tokens por solicitud, no es un factor determinante.
¿Estos modelos necesitan una configuración especial para funcionar con Claude Code?
No, más allá de lo mostrado anteriormente. Claude Code lee su configuración de modelo desde ~/.claude/settings.json, y siempre que lo dirijas a una pasarela que sirva estos modelos en formato compatible con OpenAI, se conectará correctamente. Lo único a tener en cuenta es el formato de la URL base para Claude Code: utiliza https://api.atlascloud.ai sin /v1, a diferencia de la mayoría de las otras herramientas.
Veredicto final: Kimi K2.6 vs GLM 5.1
La elección entre estos dos modelos se basa más en cómo se ajustan a tu carga de trabajo que en un ganador claro.
Kimi K2.6 es la opción predeterminada más rentable. Es más barato por token, maneja más contexto por solicitud y es muy adecuado para el tipo de tareas de gran volumen y contexto extenso que generan los agentes de programación. Si estás optimizando costos a escala o trabajando regularmente con bases de código grandes, es la opción más sólida según los números.
GLM 5.1 justifica su precio ligeramente más alto en tareas que exigen un seguimiento preciso de instrucciones y salidas estructuradas consistentes. Si tu pipeline no es tan pesado en contexto pero requiere una alta precisión en cada paso de generación individual, vale la pena probarlo contra tu tipo de tarea específico.
El enfoque práctico: comienza con Kimi K2.6 por su ventaja de costo y mayor ventana de contexto, ejecuta tu carga de trabajo real a través de él y compara GLM 5.1 en las mismas tareas si tienes dudas sobre la calidad de la salida estructurada. Con ambos modelos detrás de la misma clave API en el Plan de Codificación de Atlas Cloud con un 45% de descuento sobre las tarifas oficiales, el costo de comparación es lo suficientemente bajo como para dejar que el rendimiento real guíe la decisión.
Las especificaciones del modelo y las tasas de crédito se basan en la documentación del Plan de Codificación de Atlas Cloud a mayo de 2026. Las capacidades del modelo reflejan información disponible públicamente de Moonshot AI y Zhipu AI. Las tarifas están sujetas a cambios; verifica las cifras actuales directamente con cada proveedor.






