Las API de generación de video con IA tienen fama de ser temperamentales, y por una buena razón. Las finalizaciones de texto fallan inmediatamente con un error 400 cuando algo sale mal. El renderizado de video es diferente y más impredecible. Un trabajo puede quedar estancado para siempre en una cola de GPU sin previo aviso. Puede devolver solo la mitad de los clips solicitados. A veces, el renderizado termina perfectamente, pero el video final parece físicamente imposible o distorsionado.
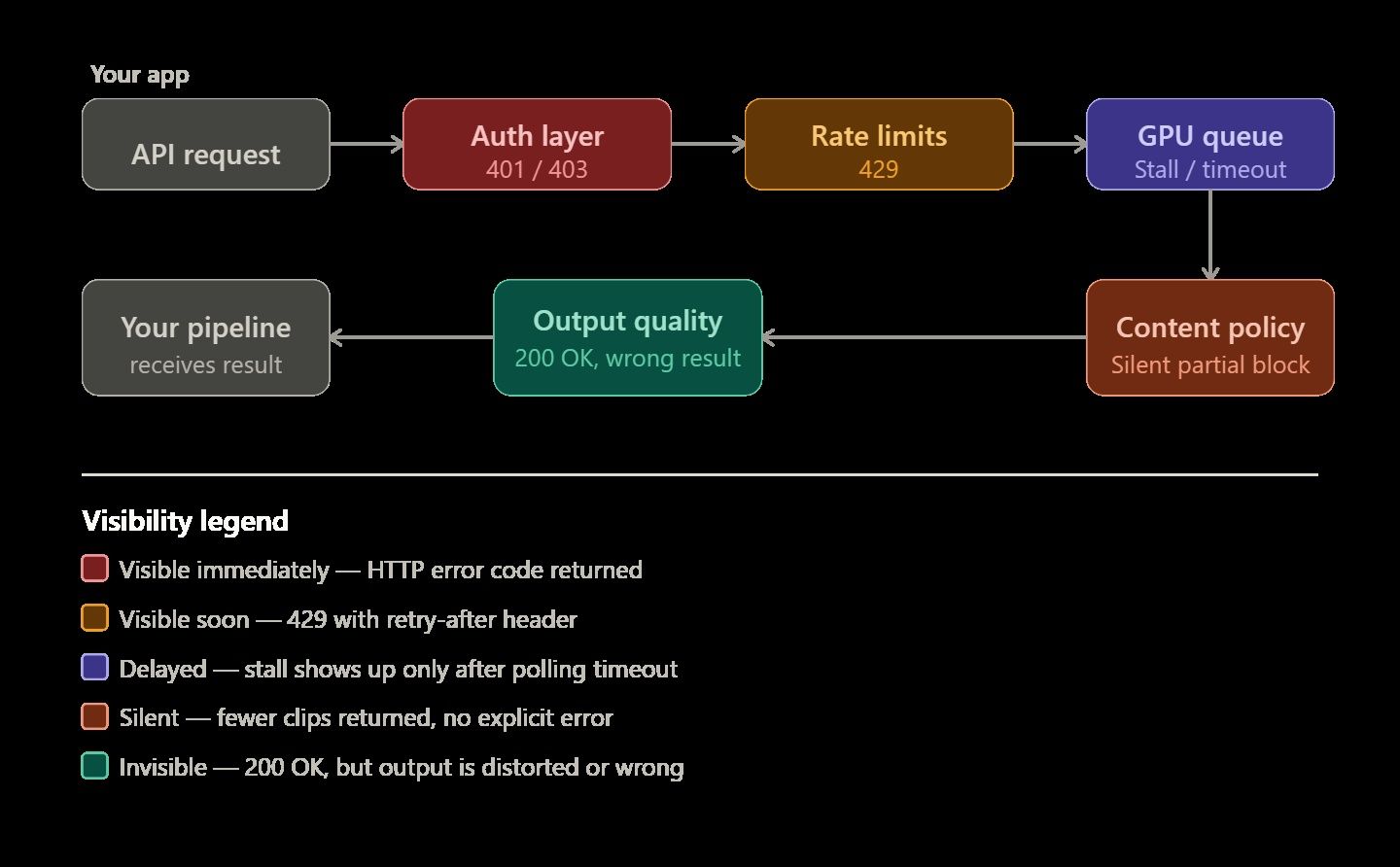
Debes saber por qué ocurren estos errores específicos para construir un sistema confiable. Este conocimiento es la diferencia principal entre una demostración simple y un pipeline de video que realmente funcione para usuarios reales.
Esta guía analiza los modos de falla más comunes, cómo leer las respuestas de la API con precisión y estrategias concretas para construir un pipeline de renderizado de video que cueste menos y se rompa con menos frecuencia. Los ejemplos de código utilizan la API de Atlas Cloud, una plataforma de inferencia unificada que proporciona acceso a más de 300 modelos de video y multimodales a través de un único endpoint, lo que la convierte en una referencia útil para patrones multimodelo.
Las cinco categorías de errores de la API de video IA
Los errores en los pipelines de video con IA suelen encajar en cinco grupos específicos. Conocer la categoría correcta te ayuda a resolver problemas más rápido, como corregir tu código, reescribir tu prompt o simplemente esperar.
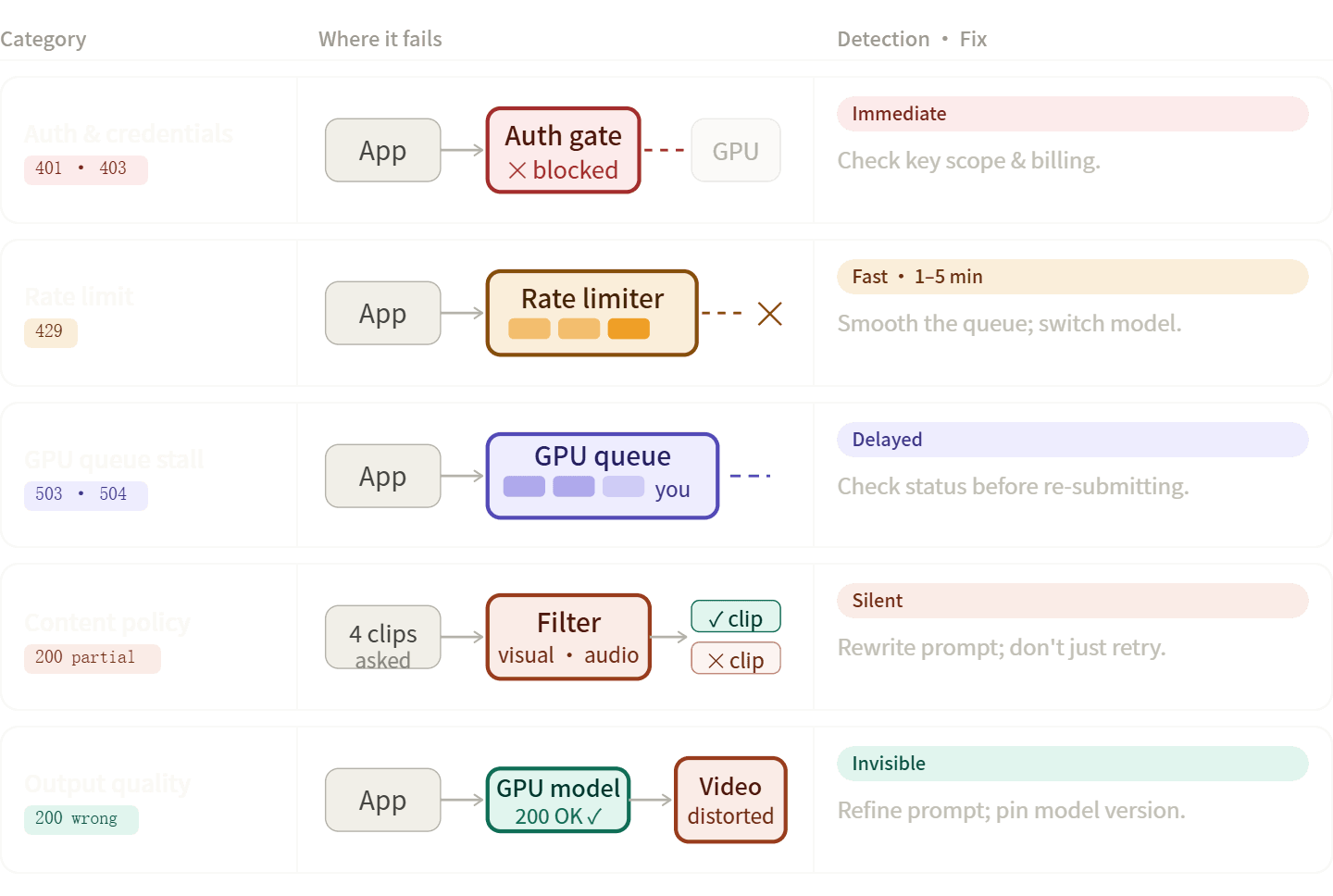
Errores de autenticación y credenciales (401, 403)
| Código | Causa típica | Solución |
| 401 Unauthorized | Falta el encabezado Authorization: Bearer o está mal formado | Verifica que la clave se cargue desde variables de entorno, no hardcodeada |
| 403 Forbidden (cuota) | Créditos de API agotados | Agrega facturación o mejora el plan |
| 403 Forbidden (permiso) | La clave carece de alcance para el modelo solicitado | Regenera la clave con los permisos correctos |
La gente suele confundirse aquí. Un 403 por alcanzar una cuota y un 403 por permisos denegados usan el mismo código pero requieren soluciones diferentes. No te limites a mirar el número de estado. Lee siempre el mensaje de error completo en el cuerpo para ver qué salió mal.
En plataformas como Atlas Cloud, una sola clave de API cubre todos los modelos, lo que significa que el "deriva de autenticación" (auth drift), donde las claves para el Proveedor A funcionan pero las del Proveedor B han caducado, simplemente no ocurre.
Errores de límite de tasa (429)
Los límites de tasa en las API de video son más severos que en las de texto porque cada solicitud mantiene un espacio en la GPU durante 30 a 90 segundos. Un puñado de solicitudes simultáneas puede saturar un límite que parece generoso en papel.
Distinciones clave a verificar primero:
- RPM: Los modelos de producción en la API de Veo 3.1 de Google permiten 50 RPM; los modelos de vista previa tienen un tope de 10 RPM con un máximo de 10 solicitudes concurrentes por proyecto.
- Límites de solicitudes concurrentes: Incluso dentro de tu presupuesto de RPM, alcanzar el límite de concurrencia te dará un error 429.
- TPM (tokens por minuto): Menos común para video, pero relevante en plataformas con facturación unificada entre modalidades.
Lo que realmente ayuda:
| Enfoque | Cuándo funciona | Cuándo no funciona |
|---|---|---|
| Back-off exponencial + reintento | 429 causados por ráfagas momentáneas | Cuando la concurrencia es el límite real |
| Suavizado de ráfagas / encolado de solicitudes | Pipelines de procesamiento por lotes | UX interactiva y sensible a la latencia |
| Programación fuera de hora (lotes nocturnos) | Flujos de trabajo de pregeneración de contenido | Generación en tiempo real |
| Enrutamiento a una variante menos cargada | Plataformas unificadas con modelos equivalentes | Configuraciones de un solo proveedor |
Rechazos por políticas de contenido y filtros de seguridad
Son fáciles de diagnosticar erróneamente porque la respuesta de la API no siempre es un error claro; puede que simplemente sean menos clips de los solicitados. La documentación de Veo de Google señala explícitamente que, si se devuelven menos videos de los solicitados, parte de la salida pudo haber sido bloqueada por filtros de seguridad en lugar de que toda la solicitud fallara en la capa de transporte.
Dos superficies de activación distintas:
- Prompts visuales: Temática, contexto de la escena o violencia implícita/contenido explícito.
- Prompts de audio/diálogo: El contenido del habla, las solicitudes de canciones y los paisajes sonoros densos activan pilas de filtros separadas.
Si tu clip falla solo cuando el audio es parte del prompt, depura el audio por separado de la escena visual. Reintentar un prompt bloqueado por políticas rara vez lo resuelve: el prompt debe cambiar.
Errores de transporte e infraestructura (500, 503, 504)
| Código | Tiempo de resolución típico | Qué hacer |
|---|---|---|
| 429 RESOURCE_EXHAUSTED | 1–5 minutos | Back-off y reintento |
| 503 Service Unavailable | 30–120 minutos | Esperar; revisar el dashboard de estado |
| 504 Gateway Timeout | Variable | Verificar si el renderizado sigue procesando antes de reenviar |
| 500 Internal Server Error | Depende | Registrar el ID de predicción; no reintentar sin verificar el estado |
La regla crítica con los errores 500/504: verifica si tu renderizado sigue en proceso antes de reenviar. Los reintentos a ciegas en un 504 pueden resultar en renderizados duplicados y costos duplicados.
Fallas en la calidad de salida
Estos no son errores HTTP: la API devuelve un 200, pero la salida es incorrecta. Formas comunes:
- Artefactos visuales o inexactitudes geométricas: El video con IA es probabilístico. El modelo interpreta las entradas en lugar de calcularlas físicamente.
- Falta de audio en modelos que lo soportan: Generalmente un problema de prompt o parámetro, no una falla de infraestructura.
- Duración o resolución incorrectas: Provocado por combinaciones no admitidas; no todos los modelos soportan todos los pares de duración/resolución.
- Caídas silenciosas del pipeline: Algunos pipelines de codificación descartan silenciosamente videos bajo ciertos formatos, apareciendo solo durante el control de calidad (QA).
Lectura de respuestas asíncronas: IDs de predicción y sondeo de estado
La generación de video con IA es asíncrona por diseño. El ciclo de solicitud-respuesta tiene dos fases:
- POST al endpoint de generación → recibir un
prediction_id - GET al endpoint de resultados con ese ID → sondear (poll) hasta un estado terminal
El esquema de respuesta de Atlas Cloud ilustra cómo se ve una predicción completada:
plaintext1{ 2 "id": "pred_abc123", 3 "status": "completed", 4 "model": "bytedance/seedance-2.0/text-to-video", 5 "outputs": ["https://storage.atlascloud.ai/outputs/result.mp4"], 6 "metrics": { "predict_time": 45.2 }, 7 "created_at": "2025-01-01T00:00:00Z", 8 "completed_at": "2025-01-01T00:00:45Z" 9}
Los tres estados terminales:
| Estado | Significado | Acción |
|---|---|---|
| completed | Renderizado exitoso; salidas disponibles | Descargar dentro de la ventana de expiración |
| failed | Fallo en el renderizado; revisar el campo de error | Registrar mensaje de error; decidir reintento |
| expired | Salidas ya no disponibles | Reenviar si aún se necesitan |
El error de sondeo más común
Los desarrolladores verifican rutinariamente el estado === "failed" pero nunca leen el campo de error que lo acompaña. Ese campo es donde reside la información procesable; sin él, sabes que un render falló pero no si debes arreglar el prompt, verificar tu cuota o esperar a que pase un bache de infraestructura.
Patrón de sondeo listo para producción
plaintext1import time 2import requests 3 4def poll_prediction(prediction_id: str, api_key: str, max_wait: int = 600) -> dict: 5 url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 6 headers = {"Authorization": f"Bearer {api_key}"} 7 terminal_states = {"completed", "failed", "expired"} 8 wait = 5 9 10 for _ in range(max_wait // wait): 11 resp = requests.get(url, headers=headers).json() 12 status = resp.get("status") 13 14 if status in terminal_states: 15 if status == "failed": 16 print(f"Render failed: {resp.get('error')}") 17 return resp 18 19 time.sleep(wait) 20 wait = min(wait * 1.5, 60) # cap back-off at 60s 21 22 raise TimeoutError(f"Prediction {prediction_id} did not complete within {max_wait}s")
Registra metrics.predict_time en cada renderizado completado. Los picos en este valor son un indicador líder de degradación de la infraestructura, una señal útil antes de empezar a ver fallas directas.
Estructuración de un pipeline de renderizado resiliente
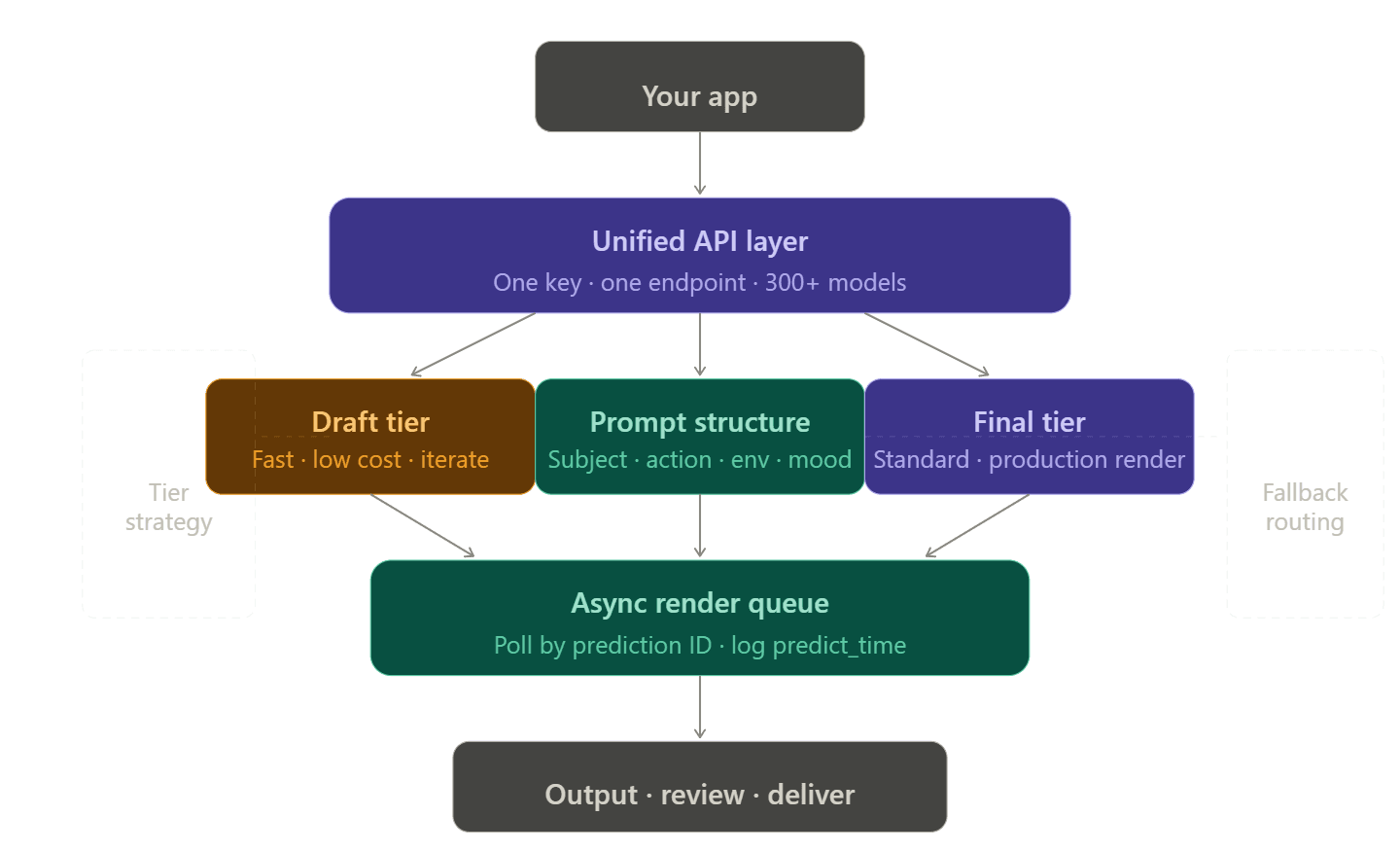
Arquitectura de API de proveedor único vs. unificada
Gestionar múltiples cuentas, tokens y páginas de facturación para cada proveedor de video es un dolor de cabeza real. Los desarrolladores suelen llamar a esto el "impuesto de integración". Empeora rápidamente. Si un modelo alcanza un límite, necesitas un respaldo. Ese respaldo luego necesita su propia clave de API, configuración de facturación y código personalizado para manejar errores.
Las plataformas de API unificada eliminan esto enrutando múltiples proveedores a través de un único endpoint. En Atlas Cloud, cambiar de openai/sora-2/text-to-video a bytedance/seedance-2.0/text-to-video requiere cambiar una cadena: los encabezados, la autenticación y la facturación permanecen idénticos.
Niveles de borrador a final
Una de las mejoras de costo y confiabilidad de mayor impacto es simplemente elegir el nivel de modelo correcto para la etapa correcta del flujo de trabajo:
| Etapa | Nivel recomendado | Por qué |
|---|---|---|
| Exploración de prompts / pruebas | Nivel Rápido / Presupuesto | Ahorro del 78%+ vs Estándar; los errores se detectan barato |
| Borradores de revisión interna | Nivel Rápido | Suficiente para revisión de stakeholders |
| Renderizados de producción final | Nivel Estándar / Pro | La diferencia de calidad justifica el costo |
| Contenido por lotes (redes sociales) | Nivel Rápido | El volumen hace que el delta de costo sea significativo |
En Atlas Cloud, el nivel Rápido de Seedance 2.0 funciona a USD0.081/seg frente a USD0.10/seg para Estándar; una diferencia que se acumula rápidamente a escala. Un equipo que genere 200 clips de diez segundos al mes gastaría USD162 en Rápido frente a USD200 en Estándar para el mismo conjunto de prompts.
Ingeniería de prompts como prevención de errores
Los prompts vagos son una fuente subestimada de fallas en el pipeline. Un prompt como "una persona caminando" obliga al modelo a tomar demasiadas decisiones arbitrarias, produciendo una salida inconsistente que requiere más reintentos.
Una estructura de prompt de 4 componentes confiable:
plaintext1[Sujeto + detalle] + [Acción + estilo de movimiento] + [Entorno + iluminación] + [Cámara + estado de ánimo] 2 3Ejemplo: 4"Una mujer con abrigo rojo caminando apresuradamente por una calle de Tokio bajo la lluvia 5por la noche, reflejos de neón en pavimento mojado, toma de seguimiento media, cinemática y tensa"
Al utilizar modelos que admiten entrada multimodal (Seedance 2.0 acepta hasta 12 archivos de referencia: imágenes, clips de video y audio), proporcionar referencias visuales reduce la ambigüedad que conduce a fallas de calidad en la salida.
Elección del modelo correcto
No todas las herramientas de video con IA fallan por la misma razón. Esto se debe a que están construidas para objetivos diferentes. Usar el modelo incorrecto para tu tarea específica es un error grave. Conduce a resultados pobres que parecen errores técnicos, pero usualmente el modelo simplemente no está hecho para ese trabajo.
Referencia de capacidades de modelos
| Modelo | Fortaleza | A tener en cuenta | Precio (Atlas Cloud) |
|---|---|---|---|
| wan 2.7 | Simulación física, interacción realista con objetos | Solo referencia de imagen única; mayor costo | USD0.1/seg |
| Kling 3.0 | Salida de alta resolución; sincronización labial nativa | Tiempos de generación más largos a máx. resolución | USD0.071-0.143/seg |
| Veo 3.1 | Calidad cinemática; fuerte cumplimiento de seguridad | Límites de tasa del modelo de vista previa (10 RPM) | USD0.05–0.20/seg |
| Seedance 2.0 | Control de entrada multireferencia; audio nativo | Requiere una construcción de prompt más cuidadosa | USD0.081–0.10/seg |
| Wan 2.6 | Menor costo; contenido de alto volumen | Sin audio nativo; máximo 1080p | USD0.018-0.07/seg |
Precios obtenidos de la documentación de Atlas Cloud, abril de 2026. Para precios específicos, consulte el sitio web oficial.
Cuándo cambiar de modelo vs. corregir la solicitud
Cambia de modelo si:
- Los clips fallan constantemente solo cuando hay audio o diálogo en el prompt; el modelo puede carecer de capacidad de audio.
- La calidad física o de interacción con objetos es la falla, no el prompt.
- Estás en un modelo de vista previa alcanzando límites de tasa que un modelo de producción no tendría.
Corrige el prompt si:
- La salida es estilísticamente incorrecta pero estructuralmente correcta.
- Los filtros de seguridad se activan por lenguaje específico.
- Los parámetros de duración o resolución están siendo rechazados.
Fija una cadena de versión específica (ej. kling-v3.0-std no kling-latest). Las actualizaciones silenciosas del modelo pueden introducir regresiones de calidad que son casi imposibles de depurar sin fijar la versión.
Tu kit de herramientas de depuración
Qué registrar en cada etapa
El registro (logging) es la forma más rápida de reducir el tiempo de depuración a la mitad. Un registro mínimo efectivo captura:
En la solicitud:
- ID y versión del modelo.
- Hash del prompt, no el prompt completo; mantiene los registros compactos.
- Parámetros de duración, resolución y modo.
- Marca de tiempo.
En la respuesta:
- ID de predicción.
- Estado inicial.
- Cualquier mensaje de error inmediato.
Al completar el sondeo:
- Estado final.
predict_timede las métricas.- Contenido del campo de error (si falló).
- URL de salida (si se completó).
Lectura de errores de infraestructura vs. aplicación
Cuando una generación falla, una secuencia de diagnóstico rápida ahorra tiempo:
- Revisa primero el dashboard de salud de la API: si la plataforma está degradada, estás depurando la cosa equivocada.
- Lee los encabezados de respuesta
x-deny-reason: las denegaciones del proxy de salida aparecen aquí y parecen errores de modelo sin este encabezado. - Busca errores CORS si estás llamando desde un frontend; producen el mismo síntoma que los errores de autenticación en las DevTools del navegador.
- Verifica las restricciones de archivo antes de asumir un error del modelo; la mayoría de las plataformas imponen un tamaño máximo de archivo de entrada (a menudo 16 MB) y un conjunto limitado de formatos aceptados.
El panel de monitoreo de Atlas Cloud muestra el estado de escalado automático y los datos de uso por solicitud, lo que ayuda a distinguir un día de infraestructura lenta de un problema de prompt o de código.
Optimización de costos
Las tres palancas
El costo de renderizado es producto de tres variables. Optimizar las tres simultáneamente —en lugar de solo elegir un modelo más barato— produce los mayores ahorros:
| Palanca | Elección de bajo costo | Elección de alto costo | Multiplicador típico |
|---|---|---|---|
| Nivel de modelo | Rápido | Estándar/Pro | 3–5× |
| Duración | 4–5 segundos | 12–15 segundos | 3× |
| Resolución | 720p | 4K | 2–4× |
Un solo renderizado Estándar 4K de 8 segundos puede costar entre 6 y 8 veces más que un equivalente Rápido de 720p a la misma duración. Si tu canal de distribución son redes sociales o web, 720p o 1080p suele ser indistinguible para los usuarios finales.
Facturación basada en uso vs. suscripción
Los planes de IA para consumidores, como Google AI Pro a USD19.99/mes o AI Ultra a USD249.99/mes, proporcionan generación de video limitada a través de la interfaz de Google AI, pero no incluyen acceso a la API. Este es un error de planificación presupuestaria común para equipos que pasan de herramientas de consumidor a pipelines de producción.
Atlas Cloud utiliza facturación basada en el uso para ajustar tus costos a lo que realmente construyes. Esto funciona mejor si las necesidades de tu proyecto cambian de una semana a otra. Debes realizar un seguimiento del costo por segundo de video terminado. Esta es la mejor forma de comparar diferentes modelos y niveles de precios de manera justa.
Reutilización de activos de referencia
Si estás generando muchos clips con los mismos personajes, escenas o referencias de estilo, preregistra esos activos:
- Sube imágenes o videos de referencia una vez; almacena el ID de activo devuelto.
- Pasa
asset://<ark_asset_id>en solicitudes posteriores en lugar de volver a subirlos. - Las subidas de archivos de referencia no se contabilizan en la mayoría de las plataformas; solo se factura la duración de la salida generada.
Lista de verificación de preparación para producción
Antes de enviar un pipeline de generación de video a producción, verifica cada uno de los siguientes puntos:
Autenticación
- Clave de API cargada desde variables de entorno, no hardcodeada.
- La clave tiene los alcances correctos para todos los modelos en uso.
- Política de rotación implementada.
Límites de tasa y concurrencia
- Límites de RPM y de solicitudes concurrentes confirmados para cada nivel de modelo.
- Suavizado de ráfagas o encolado implementado para flujos de trabajo por lotes.
- Modelo de respaldo configurado para escenarios de límites de tasa.
Manejo de errores
- Todos los estados terminales (completed, failed, expired) gestionados.
- Campo
errorcapturado y registrado en cada estado fallido. - Tiempo de espera (timeout) de subproceso/solicitud establecido en ≥ 10 minutos para renderizados largos.
- Sin reintento automático a ciegas en 500/504 sin verificar el estado primero.
Contenido y prompts
- Prompts revisados previamente contra las pautas de contenido de la plataforma.
- Disparadores de audio y visuales aislados en las pruebas.
- Estructura de prompt de 4 componentes adoptada como estándar de equipo.
Configuración del modelo
- Cadena de versión específica fijada (no
latest). - Nivel de modelo adaptado a la etapa del flujo de trabajo (Rápido para borradores, Estándar para finales).
- Todos los parámetros requeridos confirmados para el modelo elegido (duración, resolución, audio).
Controles de costos
- Panel de facturación basado en uso configurado con alertas.
- Nivel Rápido por defecto para todos los renderizados no finales.
- IDs de activos de referencia utilizados para activos recurrentes.
Observabilidad
- ID de predicción, estado y
predict_timeregistrados en cada renderizado. - Dashboard de salud de la API marcado y revisado antes de una depuración profunda.
- Alertas sobre picos de
predict_timeconfiguradas.
Un pipeline de video que maneja errores no es mucho más difícil de construir que uno que se rompe. Solo necesitas ser inteligente sobre cómo lidias con las fallas en cada paso. Asegúrate de que tu registro sea sólido y mantente en versiones específicas de los modelos. Antes de preocuparte por cualquier otra cosa, configura un pipeline que pase de borradores rápidos a renderizados finales. El resto vendrá de forma natural.
Preguntas frecuentes
¿A qué se deben los errores "429 Resource Exhausted" en el plan premium?
El error 429 solo significa que has alcanzado tus límites de tasa. Para seguir funcionando sin problemas, los proveedores limitarán tus solicitudes y tokens.
- La solución: Agrega backoff exponencial a tu código. Esto ayuda al sistema a esperar y reintentar por sí solo. Revisa también tu "Nivel de Uso" en el panel. Debes gastar más para desbloquear velocidades más rápidas.
¿Cómo se pueden evitar los falsos positivos de "Moderación de contenido"?
Los filtros de seguridad a menudo malinterpretan los prompts técnicos como violaciones de políticas.
- La solución: Corrige tu prompt cambiando palabras vagas por técnicas. No digas "energía caótica" cuando te refieras a "movimiento de cámara de alta velocidad". También puedes usar un LLM para limpiar tus prompts. Esto los convierte en descripciones claras que la máquina entiende y evita errores.
¿Cómo se puede reducir la latencia de mi pipeline de renderizado?
La latencia suele provenir de un mal sondeo o de tamaños de modelo grandes. Usa Webhooks en lugar de sondeo manual para recibir datos de finalización. Si realizas autohospedaje, aplica cuantización FP8 para acelerar la inferencia. Para usuarios de API, cambia al procesamiento asíncrono para manejar múltiples generaciones en paralelo en lugar de secuencialmente.






