
Los avatares de IA actuales pueden mantener una conversación en tiempo real e incluso permitirte interrumpirlos a mitad de una frase; además, puedes alojar uno tú mismo con un proyecto de código abierto, manteniendo todos tus datos en local. Este post detalla cómo se construye un humano digital en tiempo real listo para producción usando OpenTalking, y dónde se ahorra dinero en comparación con servicios por minuto como HeyGen.
Este fue el momento que captó mi atención: un avatar en mi pantalla estaba hablando, le interrumpí a mitad de la frase, se detuvo para escuchar y luego retomó la conversación desde lo que acababa de decir. No era un clip prerenderizado reproduciéndose. Era un intercambio real. Subtítulos desplazándose en sincronía, con una latencia lo suficientemente baja como para no sentir que era IA.
Y el primer paso para construirlo no me costó nada y no requirió una GPU.
¿Por qué empezar así? Porque cuando la mayoría de la gente escucha "humano digital", todavía se imagina al títere rígido de PowerPoint que leía guiones hace dos años: expresión congelada, reproducción unidireccional, sordo a lo que digas. Así que la verdadera pregunta no es "¿puede un humano digital generar dinero?". Es:
¿Qué tanto han avanzado los avatares de IA en 2026?
Lo suficiente como para haber pasado de ser "un video que se mueve" a "algo que te responde". Después de la demostración en tiempo real de GPT-4o, el estándar subió a tiempo real, interrumpible y capaz de hacerte preguntas. Este año, la escena de código abierto lanzó una oleada de ellos: SoulX-LiveAct, Mnn3dAvatar de Alibaba, duix.ai, LiveTalking. El que estoy analizando aquí conecta toda la infraestructura de una manera inusualmente limpia: OpenTalking.
Sin rodeos: analicemos tres cosas: qué hace, cuánto vale y cómo puede construirlo alguien que no es desarrollador.
1. Qué hace: un avatar que realmente responde
OpenTalking es un marco de trabajo (framework) de orquestación de conversaciones con humanos digitales en tiempo real de código abierto. En términos sencillos: encadena todo el ciclo — el usuario habla → conversión de voz a texto (STT) → un LLM piensa una respuesta → conversión de texto a voz (TTS) → el avatar habla y se transmite a tu navegador vía WebRTC — en una sola tubería de tiempo real.
Lo que realmente puede hacer:
- Conversación en tiempo real: te responde en directo, no es un video pregrabado.
- Interrupción: habla mientras lo hace y se detendrá a escucharte (esta es la parte que se siente humana).
- Eventos de subtítulos: los subtítulos se renderizan a medida que habla.
- Clonación: generación basada en audio/texto, para que puedas construir tu propio gemelo digital.
Si aplicas esto a un negocio, el panorama se vuelve concreto rápidamente: un presentador de transmisiones en vivo que vende 24/7 sin dejar de trabajar, o un agente de soporte que está en línea a las 3 a.m. y puede ser interrumpido con una pregunta de seguimiento.
2. Cuánto vale: las cifras sobre la mesa
Lo que realmente le importa a quien no es desarrollador: ¿esto ahorra dinero o lo genera? Esto es lo que dicen los datos públicos:
- Una transmisión en vivo de marca tradicional con un equipo humano cuesta entre 150.000 y 250.000 ¥ al mes; se estima que una transmisión en vivo con avatar de IA cuesta entre unos pocos miles y 20.000 ¥ al mes, lo que supone una reducción de costos de aproximadamente el 90% (según el Libro blanco sobre transmisiones en vivo de comercio electrónico con humanos digitales 2026 de iResearch).
- Un agente de soporte humano digital puede filtrar más del 60% de las consultas de alta frecuencia y reducir los costos operativos entre un 30% y un 60%.
Ahora, la otra opción: un SaaS comercial como HeyGen. Es realmente sencillo y el resultado es excelente, pero te cobra por minuto: la API cuesta alrededor de 1 USD por minuto para la generación estándar, 4 USD por minuto para Avatar IV, 3 USD por minuto para Avatar V; y el plan Creator (29 USD/mes) incluye 200 créditos, suficientes para solo unos 10 minutos de video de avatar premium.
Analiza esta diferencia: SaaS significa que cada minuto que usas, pagas por ese minuto. Una configuración de código abierto autohospedada se construye una vez, y luego solo incurres en gastos de electricidad y depreciación de la GPU. Para un negocio que opera de forma prolongada y con gran volumen (piensa en transmisiones en vivo diarias), esas dos curvas de costos no terminan un poco separadas: terminan en mundos diferentes.
3. Cómo construirlo sin ser desarrollador: empezando desde cero GPU
Este es el núcleo del análisis. La decisión de diseño más inteligente de OpenTalking es que no te obliga a comprar una GPU el primer día. Te ofrece tres niveles de despliegue que puedes escalar uno a uno:
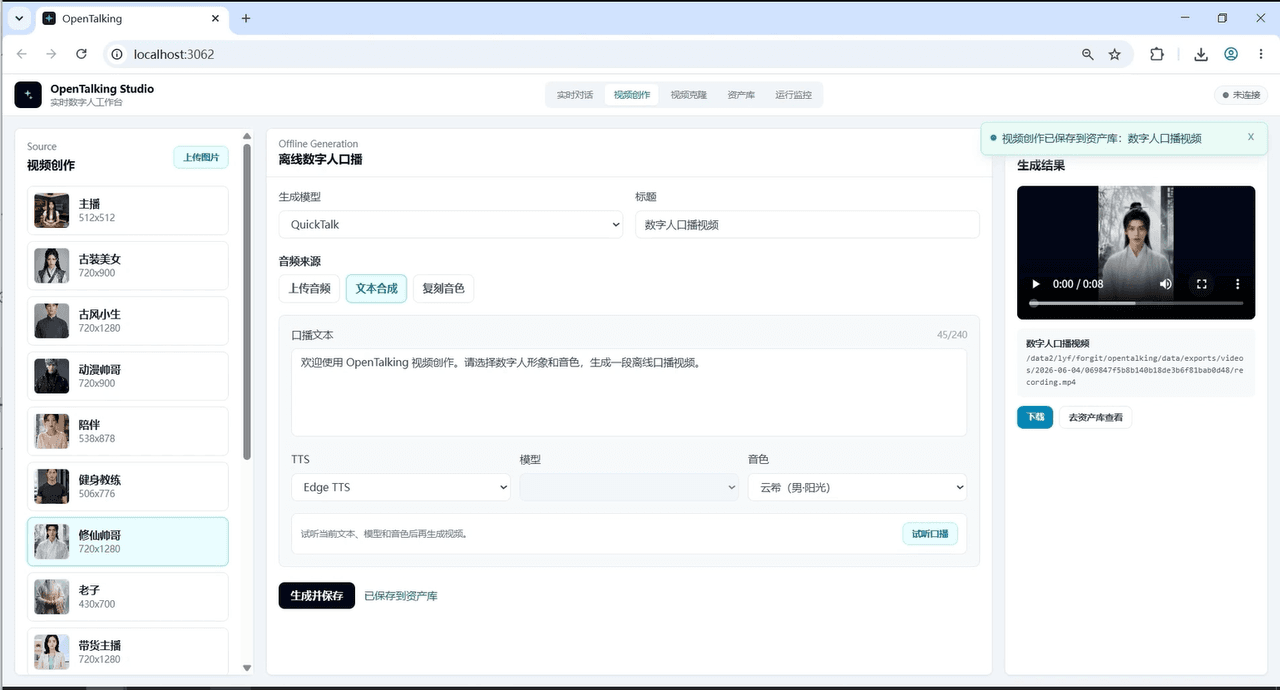
Paso 0: Modo simulado (cero GPU, prueba la lógica primero)
Pon en marcha todo el ciclo del producto con el backend simulado —interacción de frontend, estado de sesión, el flujo de conversación completo— en un ordenador normal. El objetivo: confirmar que esta forma de producto es lo que realmente quieres antes de gastar un centavo en una GPU. La mayoría de la gente se estanca en "necesito comprar una tarjeta solo para empezar". Aquí puedes hacer una prueba en seco primero.
Paso 1: Dale un cerebro y una boca (el LLM)
Para que el avatar responda, conecta un LLM para las respuestas. OpenTalking utiliza la API compatible con OpenAI, por lo que no tienes que tocar código: simplemente introduce un endpoint y una clave. Para este paso, obtuve una clave en AtlasCloud: una sola clave llama a DeepSeek, Seedance, Nano Banana y más, así que me ahorré el registro en un montón de cuentas separadas. La voz/TTS se selecciona directamente en la interfaz web.
Paso 2: Añade una GPU de consumo, cambia a un modelo de renderizado real
Una vez que la lógica funcione y el modelo esté conectado, elimina la simulación y conecta un backend de renderizado real. Localmente, una tarjeta de consumo como una RTX 3060 (8 GB de VRAM) es suficiente para empezar; es compatible con QuickTalk, Wav2Lip, MuseTalk, FlashTalk y más. Elige según la calidad frente a la velocidad.
Paso 3: Escala solo cuando el negocio lo haga
Cuando crezcas, el sistema escala a múltiples GPU e incluso NPUs como Huawei Ascend 910B2. Esto significa que esto crece contigo desde "jugueteando en mi portátil" hasta "despliegue privado empresarial", sin necesidad de cambiar de framework a mitad de camino.
4. Entonces, ¿por qué no usar un SaaS? Dónde ganan el código abierto y el autohospedaje
Tomemos los nombres que todos conocen y hagamos una comparación honesta (cada uno tiene sus puntos fuertes, sin exageraciones ni críticas):
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Dimensión | OpenTalking (código abierto, autohospedado) | HeyGen / D-ID (SaaS) | Flujos de trabajo de avatar en ComfyUI |
| Facilidad de configuración | Media (despliegue, pero la simulación ayuda) | Máxima (listo para usar, gran resultado) | Alta (conectar nodos, ajustar gráficos) |
| Facturación | Construir una vez; principalmente hardware/electricidad | Continua por minuto / por crédito | Gratis para ejecutar localmente |
| Datos | Locales, nunca salen de tu dominio | Subidos a sus servidores | Locales |
| Tiempo real + interrumpible | Nativo | Enfocado en generación de video; chat en vivo limitado | Principalmente renderizado offline |
| Personalización | Alta (backends conectables, orquestación editable) | Baja (producto estandarizado) | Alta (ecosistema de nodos flexible) |
Seamos justos: el SaaS estilo HeyGen realmente gana en "cero complicaciones". Si no quieres lidiar con el despliegue, solo quieres resultados y tu volumen es bajo, es la decisión correcta. El ecosistema de nodos y el control de ComfyUI también son potentes. La ventaja de OpenTalking no es "superar a nadie en calidad de imagen", sino dos cosas: los datos nunca abandonan tu máquina (un requisito estricto para gobiernos, finanzas, atención médica o cualquier negocio que no entregue las conversaciones de sus clientes a un tercero) y no hay un contador de minutos corriendo (lo cual compensa a gran volumen, a largo plazo).
Cuál es el adecuado depende de si tu negocio es de "clips ocasionales" o de "estar funcionando a toda hora", y de si te importa entregar tus datos.
Cierre
Volviendo a la pregunta inicial: ¿qué tanto han avanzado los avatares de IA? Lo suficiente como para que uno pueda chatear contigo en tiempo real, permitirte interrumpirlo y ejecutarse en tu propia máquina. La barrera es más baja de lo que piensas: pruébalo primero en modo simulado de costo cero, confirma que es lo que quieres y luego gasta. Para alguien que no es desarrollador y se adentra en este espacio, ese orden podría ser la forma más segura de empezar.
❓ Preguntas frecuentes
P: ¿Qué GPU necesito para construir esto?
R: Para ejecutar un modelo de renderizado real localmente, una tarjeta de consumo como una RTX 3060 (8 GB de VRAM) es suficiente para empezar; escala a múltiples GPU o una NPU Ascend más tarde. Pero ten en cuenta: el Paso 0 (modo simulado) no necesita ninguna GPU, por lo que un ordenador normal puede validar la lógica primero.
P: No tengo una GPU. ¿Puedo probarlo de todos modos?
R: Sí. El modo simulado valida todo el flujo de conversación sin necesidad de GPU; si quieres un modelo real pero no tienes tarjeta, dirígete a una inferencia en la nube/remota y descarga el renderizado en la nube.
P: ¿Cuánto ahorra realmente frente a HeyGen?
R: Estructuralmente, elimina la facturación por minuto. La API de HeyGen cuesta ~1-4 USD por minuto y los créditos de su plan cubren solo ~10 minutos al mes; el autohospedaje es una construcción única más el hardware y la electricidad. Cuanto más lo uses y más tiempo lo mantengas en marcha, más rentable resulta el autohospedaje. Para un puñado de clips ocasionales, el SaaS es de hecho menos complicado.
P: ¿Puedo usar esto comercialmente?
R: Técnicamente, cubre lo que requiere el uso comercial (conversación en tiempo real, soporte, gemelos para transmisiones en vivo) con despliegue privado y datos que permanecen en tu dominio. Pero antes de ponerlo en marcha, confirma la licencia/cumplimiento de los modelos de renderizado, voces y apariencias que utilices. Los avatares involucran el rostro y la voz de alguien; asegúrate de tener los derechos claros primero.
P: Soy principiante total. ¿Por dónde empiezo?
R: ① Ejecuta el proyecto en modo simulado y experimenta el flujo de conversación en tu navegador; ② conecta una clave LLM compatible con OpenAI (para mayor simplicidad, obtén una en AtlasCloud: múltiples modelos, una sola clave); ③ elige una voz; ④ añade una GPU y cambia a un modelo de renderizado real al final. Pruébalo primero, luego paga.






