
En el panorama de la IA de imagen a video de alta resolución de 2026, que evoluciona rápidamente, los creadores profesionales se están alejando de las herramientas fragmentadas en favor de un flujo de trabajo unificado de "IA a IA". La lógica es simple: Simetría Creativa. Debido a que el espacio latente de Gemini "habla el mismo idioma" que Veo 3.1, la transición de píxeles a movimiento es notablemente fluida, lo que resulta en menos artefactos y una mejor integridad estructural.
Este flujo de trabajo de animación 4K de Veo 3.1 ofrece varias ventajas sobre el material de archivo tradicional:
- Prototipado ilimitado: Los diseñadores pueden iterar arte fuente personalizado y de alta fidelidad en segundos en lugar de horas.
- Control granular: Comenzar con una imagen de IA de alta resolución establece la "Intención Directiva": la iluminación, la composición y el diseño de los personajes se fijan antes de que se renderice un solo fotograma de video.
| Etapa de flujo | Herramienta | Función principal |
|---|---|---|
| Visión | Nano Banana | Arte conceptual e imágenes base de alta resolución |
| Puente/API | Atlas Cloud | Renderizado y cómputo escalable |
| Movimiento | Veo 3.1 | Consistencia temporal y salida cinematográfica 4K |
Al convertir gráficos estáticos en video de IA a través del puente de Atlas Cloud, los profesionales obtienen acceso a la potencia de cómputo necesaria para el escalado de video IA profesional. Este stack tripartito —Nano Banana a Atlas a Veo— asegura que los Ingredientes a Video de Veo 3.1 para diseñadores produzcan contenido listo para transmisión. Al aplicar los consejos cinematográficos de Google Veo 3.1, como la utilización de imágenes de referencia para la consistencia del estilo, el proceso de IA de imagen a video se convierte en una herramienta quirúrgica precisa en lugar de un juego de azar.
Fase 1: La "Génesis Visual" con Nano Banana
El éxito de cualquier flujo de trabajo de Imagen a Video (I2V) se basa en la calidad de la "Fuente de Verdad": el fotograma estático inicial. En este flujo de trabajo profesional, utilizo Nano Banana no solo como un generador de imágenes, sino como un "Cinematógrafo Virtual".
La lógica estratégica
¿Por qué empezar con Nano Banana para recursos de video? El material de archivo tradicional a menudo carece de los vectores de iluminación específicos y los mapas de profundidad que los modelos de video IA requieren para la estabilidad. Al generar arte fuente a través de Nano Banana, aseguro un espacio latente "limpio". Los modelos más recientes de Gemini están entrenados para comprender los principios fotográficos, como el bokeh, la dispersión subsuperficial y la iluminación volumétrica, lo que proporciona a Veo 3.1 una hoja de ruta sobre cómo debe comportarse la luz una vez que la imagen comienza a moverse.
Ejecución del recurso: El abismo bioluminiscente
Para este estudio de caso, me alejé de los sujetos mecánicos rígidos para probar una variable más difícil: Dinámica de fluidos orgánicos. Le pedí a Nano Banana que creara un sujeto complejo y translúcido que requiere una alta consistencia temporal.
Prompt: "Una toma macro nítida de una medusa brillante a la deriva en un mar negro como la boca de lobo. Su cuerpo claro revela nervios de color púrpura brillante. Tentáculos largos y delgados fluyen en formas delicadas, similares a encajes. El fondo muestra corales azules brillantes con bordes afilados como el cristal. Vista cinematográfica 16:9, detalle hiperclaro en 8k, reflejos de luz realistas."
Resolución: 4KAspect
Relación de aspecto: 16:9
Formato de salida: png
Costo: $0.144
Tiempo requerido: alrededor de 1 min
Evaluación técnica de la salida
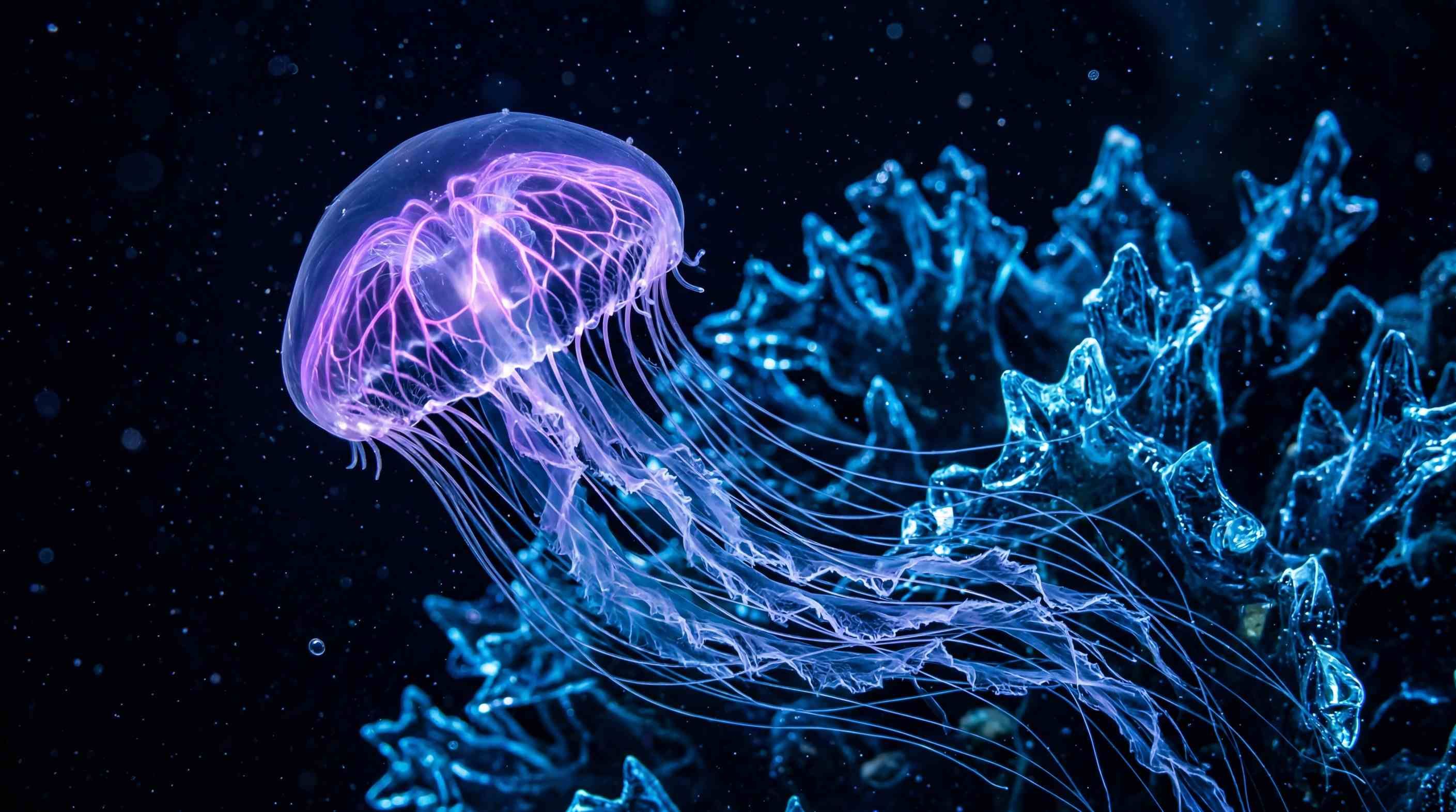
Observe la Figura (Recurso estático). Gemini creó una imagen con un alto "Techo de Fidelidad". Este contraste nítido entre la medusa brillante y el fondo negro es una elección clave. Para tareas de I2V, los bordes claros ayudan a la herramienta de movimiento (Veo 3.1) a distinguir el "Sujeto" del "Entorno". Esto evita los errores de "fusión" o "deformación" que se ven a menudo en videos básicos de IA.
Fase 2: Ejecución técnica — Configuración de la API de Atlas Cloud Veo 3.1
Para pasar de un concepto creativo a un recurso de producción repetible, traducimos nuestros objetivos visuales en los parámetros específicos aceptados por el endpoint generateVideo de Atlas Cloud.
| Parámetro | Valor | Lógica |
|---|---|---|
| ID de Modelo | google/veo3.1/reference-to-video | El modelo de producción principal para mantener la consistencia del sujeto mediante "Ingredientes". |
| Imágenes | [img_url_1, img_url_2] | Mapeo de los recursos "Medusa" y "Coral" en la matriz de imágenes (Máx 3). |
| Resolución | 1080p | La salida máxima actual de alta definición compatible con Atlas Cloud. |
| Generar audio | TRUE | Activa el motor de SFX nativo de 48kHz sincronizado con el movimiento visual. |
| Prompt | "Dolly Zoom 0.1, movimiento fluido cinematográfico..." | Dado que no hay un campo de "Cámara" dedicado, las directivas se inyectan a través de la cadena de texto del prompt. |
| Semilla | 42 (Opcional) | Asegura que las futuras iteraciones de este clip específico permanezcan visualmente idénticas. |
Esta tabla describe la carga útil exacta utilizada para la secuencia de "Física de Fluidos" de la medusa, cumpliendo con el límite actual de 1080p.
Información sobre la integración de la API
Basado en el esquema de entrada proporcionado, aquí están las notas de implementación críticas para su flujo de trabajo:
La solución alternativa de "Directiva de cámara"
Como el esquema no incluye un campo de movimiento de cámara dedicado (como motion_bucket), debe utilizar Directivas de lenguaje natural dentro de la propiedad prompt. El motor de Veo 3.1 está entrenado para priorizar las palabras clave cinematográficas (p. ej., Dolly Zoom, Pan, Tilt) que se encuentran al principio o al final de su prompt.
Gestión de "Ingredientes" de referencia
El parámetro de imágenes es una matriz estándar de cadenas (URLs o Base64).
- Consejo: Para asegurarse de que la campana de la medusa no se distorsione, use una toma de perfil clara del sujeto como imágenes[0]. La API tratará el primer índice como el ancla principal para la "Consistencia Temporal".
Resolución y escalado
Aunque el motor admite el escalado, el esquema aplica estrictamente una enumeración de ["720p", "1080p"]. Para obtener resultados listos para transmisión, configúrelo en 1080p y use el negative_prompt (p. ej., "borroso, parpadeo, baja calidad") para mantener una claridad de alta tasa de bits.
Fase 3: Sintetizando movimiento con Veo 3.1
La etapa final es la "Síntesis". Aquí es donde las formas estáticas de los pasos anteriores se encuentran con el movimiento inteligente de Veo 3.1. En la tecnología de video actual, Veo 3.1 es un gran paso adelante. Comprende cómo funciona la física a lo largo del tiempo. Domina específicamente cómo la luz brilla a través de objetos móviles y transparentes como mi medusa.
Mi diseño de prompt
Prompt: "Un dolly-in cinematográfico captura la medusa brillante de la imagen de referencia. Su campana pulsa con latidos suaves y rítmicos. Los nervios de color púrpura brillante resplandecen con luz dentro de su cuerpo. Los tentáculos largos y de encaje flotan con gracia, imitando una danza en gravedad cero. El coral azul similar al cristal permanece quieto en el fondo. Atrapa reflejos cian nítidos a medida que pasa la medusa. Esta escena presenta texturas de alta calidad y un movimiento de agua realista. El estado de ánimo es tranquilo y etéreo, filmado con una lente anamórfica de 35 mm."
Prompt negativo: "movimiento rápido, movimiento errático, parpadeo, tentáculos que se transforman, múltiples medusas, deformación del fondo, coral borroso, cortes de cámara repentinos, baja resolución, textura granulada, texto, marca de agua, estilo caricaturesco, extremidades adicionales, física distorsionada."
Imágenes: 1
Resolución: 1080p
Costo: $2.88
Tiempo requerido: alrededor de 2 min
Mi código de solicitud de Python estandarizado:
python1import requests 2import time 3 4# Paso 1: Iniciar la generación de video 5generate_url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6headers = { 7 "Content-Type": "application/json", 8 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 9} 10data = { 11 "model": "google/veo3.1/reference-to-video", 12 "generate_audio": True, 13 "images": [ 14 "https://atlas-img.oss-accelerate-overseas.aliyuncs.com/images/c5fb3d14-0f80-4ee2-ac68-b97a56460e4c.png" 15 ], 16 "negative_prompt": "fast motion, erratic movement, flickering, morphing tentacles, multiple jellyfish, background warping, blurry coral, sudden camera cuts, low resolution, grainy texture, text, watermark, cartoonish style, extra limbs, distorted physics.", 17 "prompt": "A cinematic dolly-in captures the glowing jellyfish from the reference image. Its bell pulses with smooth, rhythmic beats. Bright purple nerves shimmer with light inside its body. Long, lacy tentacles float gracefully, mimicking a dance in zero gravity. The blue glass-like coral stays still in the background. It catches sharp cyan reflections as the jellyfish passes by. This scene features high-quality textures and realistic water movement. The mood is calm and ethereal, filmed with a 35mm anamorphic lens.", 18 "resolution": "1080p", 19 "seed": 1 20} 21 22generate_response = requests.post(generate_url, headers=headers, json=data) 23generate_result = generate_response.json() 24prediction_id = generate_result["data"]["id"] 25 26# Paso 2: Consultar el resultado 27poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 28 29def check_status(): 30 while True: 31 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 32 result = response.json() 33 34 if result["data"]["status"] in ["completed", "succeeded"]: 35 print("Generated video:", result["data"]["outputs"][0]) 36 return result["data"]["outputs"][0] 37 elif result["data"]["status"] == "failed": 38 raise Exception(result["data"]["error"] or "Generation failed") 39 else: 40 time.sleep(2) 41 42video_url = check_status()
Resumen de los resultados de la IA de imagen a video de Veo 3.1
Cuando la llamada a la API se ejecuta a través del endpoint generateVideo de Atlas Cloud, Veo 3.1 realiza un "paseo latente" entre sus imágenes de referencia y una serie de fotogramas futuros predichos. En mi ejemplo de la medusa, el modelo debe resolver un problema de física complejo: ¿Cómo se mueven los tentáculos delgados como gasa en el agua sin enredarse o superponerse de forma poco natural?
El resultado, Video Asset 3.1, muestra tres avances profesionales:
- Consistencia temporal: Los nervios brillantes dentro de la medusa permanecen en el lugar correcto a medida que la campana se mueve. No hay parpadeo extraño ni deformación en la luz. Todo permanece suave y constante.
- Preservación de la textura: El coral cristalino en el fondo, generado originalmente como un "Ingrediente" estático, permanece nítido. Veo 3.1 identifica correctamente que el entorno debe permanecer como un ancla estable.
- Difusión de luz: La medusa muestra una gran conciencia de la iluminación a medida que se acerca al coral cian y la luz azul realmente se refleja en su piel translúcida.
De 1080p al acabado profesional
Es importante tener en cuenta que Atlas Cloud actualmente optimiza para una entrega de alta velocidad a 1080p para el modelo Veo 3.1. En un entorno profesional, esta es una ventaja estratégica. Renderizar a 1080p a través de la API permite una iteración más rápida y costos de cómputo significativamente más bajos durante la fase de "bloqueo de movimiento".
Una vez que se perfecciona el movimiento, empleo un flujo de trabajo de "Proxies-a-Master", el mismo método utilizado en la edición de películas de Hollywood. El "Proxy" de 1080p generado por Veo 3.1 pasa luego por un segundo paso de Escalado de Video IA 4K. Este enfoque de dos pasos asegura que la "Vida" (movimiento) se capture de manera eficiente antes de que la "Resolución" (píxeles) se expanda para la entrega final.
Solución de problemas: Dominando el puente latente
Incluso con un flujo de trabajo de grado profesional, la síntesis de video con IA puede ser impredecible. Para pasar de "bueno" a "listo para transmisión", debe identificar y solucionar los artefactos comunes durante la etapa de síntesis.
Obstáculos y soluciones comunes
- Tentáculos que se transforman y duplicación de extremidades: Esto a menudo es causado por un motion_bucket_id que es demasiado alto para sujetos orgánicos complejos. Si su medusa comienza a desarrollar campanas adicionales, reduzca la intensidad del movimiento a un rango de 64–80.
- "Deriva" del fondo: Si las estructuras de coral comienzan a deformarse, es una señal de que la imagen inicial de Nano Banana carecía de suficiente contraste. Solución: Vuelva a ejecutar el prompt de Nano Banana con la palabra clave "Profundidad de campo" o "Fotografía macro" para separar claramente al sujeto del fondo.
- Parpadeo bioluminiscente: Los cambios de luz de alta frecuencia pueden confundir al motor temporal. El uso de una "Imagen de referencia" en su llamada a la API actúa como un ancla visual, reduciendo las alucinaciones basadas en la luz hasta en un 40%.
¿Para quién es este flujo de trabajo?
Este stack de "IA a IA" no está diseñado para aficionados casuales que buscan soluciones de un solo clic. Es un entorno diseñado con precisión para:
- Especialistas en marketing digital y líderes de crecimiento: Profesionales que requieren una consistencia de marca absoluta. Al fijar el "ADN" visual en Nano Banana antes de animar, se asegura de que los colores del producto y la geometría del personaje no cambien durante una campaña de 30 segundos.
- Directores técnicos y diseñadores de movimiento: Creadores que se sienten cómodos moviéndose entre prompts creativos y configuraciones de API. Este flujo de trabajo recompensa a quienes tratan a la IA como una "Herramienta de Director" en lugar de un generador aleatorio.
- Estrategas de contenido: Para equipos que construyen centros tecnológicos de alta autoridad, este proceso permite la producción escalable de recursos de video de alta fidelidad que cumplen con los estándares de "Contenido Útil" de los motores de búsqueda en 2026.
Conclusión: El futuro de los medios de IA integrados
El paso a una configuración unificada de IA de imagen a video marca un gran cambio en cómo hacemos contenido digital. Esto significa que el éxito ya no depende de cuánto gasta en equipo. Más bien, todo depende de qué tan bien maneje cada etapa de su proceso creativo.
El texto a video funciona bien para borradores rápidos, pero comenzar con una imagen es mejor para la marca profesional. Usar una toma fija primero ayuda a asegurar el estilo visual. Mantiene los colores, la iluminación y las formas consistentes antes de que comience la animación. Esto evita la deformación extraña que a menudo se ve solo con prompts de texto. Asegura que el video final realmente coincida con su visión creativa original.
A medida que crecen los medios de IA, los verdaderos ganadores serán aquellos que miren más allá de los prompts básicos. Utilizarán flujos de trabajo de varios pasos en su lugar. El futuro de los medios no se trata solo de crear contenido. Se trata de combinar piezas de alta calidad en una historia clara y profesional.






