Google Gemini Omni es un modelo de IA integral de Google DeepMind, presentado en Google I/O el 19 de mayo de 2026. Su mayor hito es la multimodalidad nativa. Esto significa que maneja y crea texto, imágenes, sonido y video dentro de un mismo sistema, en lugar de conectar diferentes herramientas. Está diseñado para creadores, desarrolladores y empresas que desean producir y editar videos mediante una conversación sencilla, sin tener que cambiar de aplicación.
El resumen de funciones de Gemini Omni comienza con una idea: crear cualquier cosa a partir de cualquier entrada. A diferencia de las herramientas independientes de IA de texto a video, Omni combina el razonamiento de Gemini con la renderización de medios avanzada en un solo paso.
Principales capacidades de un vistazo
| Función | Detalle |
|---|---|
| Entradas aceptadas | Texto, imagen, audio, video |
| Salida principal | Video (imágenes y audio próximamente) |
| Estilo de edición | Conversacional, prompts de múltiples pasos |
| Primer modelo | Gemini Omni Flash |
| Disponibilidad | Suscriptores de Google AI Plus, Pro y Ultra |
Dónde acceder
- App Gemini — Suscriptores de AI Plus/Pro/Ultra a nivel global
- Google Flow — Flujos de trabajo completos de cortometrajes
- YouTube Shorts / YouTube Create — Creación de formato corto
- API para desarrolladores — Disponible en pocas semanas
¿Qué es Google Gemini Omni y cómo funciona?
Google Gemini Omni es un salto adelante masivo. Es el modelo principal de IA creativa "todo en uno" de Google DeepMind. Presentado en Google I/O 2026, el sistema procesa texto, imágenes, sonido y video simultáneamente para crear contenido de video de alta calidad. Reemplaza oficialmente a Veo dentro del ecosistema de Gemini.
El motor principal: Explicación de la multimodalidad nativa
La mayoría de las herramientas de IA de video anteriores seguían una secuencia lineal: convertían la entrada en descripciones de texto y luego enviaban esas descripciones a un renderizador de video separado. Gemini Omni funciona de manera distinta. Está construido sobre un modelo multimodal nativo, capaz de procesar todos los tipos de medios simultáneamente dentro de un único motor central, sin necesidad de pasos aislados.
Esto es importante porque, al eliminar las capas de conversión, el modelo conserva un contexto mucho más rico. Cuando proporcionas una foto de referencia junto con un prompt de texto, Omni razona sobre ambos elementos a la vez, preservando detalles visuales que un paso de conversión a texto normalmente eliminaría.
La entrada multimodal de Gemini Omni en la práctica
La entrada multimodal de Gemini Omni admite estas combinaciones en un solo prompt:
| Tipo de entrada | Ejemplo de uso |
|---|---|
| Solo texto | Describir una escena desde cero |
| Imagen + Texto | Animar una foto fija con una instrucción escrita |
| Video + Texto | Editar un clip existente de forma conversacional |
| Audio + Texto | Guiar el tono junto a un prompt visual |
| Mixta (las cuatro) | Combinar clips de referencia, imágenes de estilo y narración |
Procesamiento en tiempo real y control conversacional
Como el razonamiento ocurre dentro de un solo modelo, el procesamiento en tiempo real de las instrucciones de edición es muy práctico. Omni refina los resultados mediante conversaciones de varios turnos: cambia un fondo, ajusta la iluminación o estabiliza una toma simplemente describiendo el cambio. No hace falta volver a empezar desde cero.
Nicole Brichtova, de Google DeepMind, lo describió como "más que una actualización de Veo": es el razonamiento de Gemini fusionado con la renderización de medios en un sistema coherente.
IA de edición de video conversacional: Cómo usar Gemini Omni para la modificación avanzada de recursos
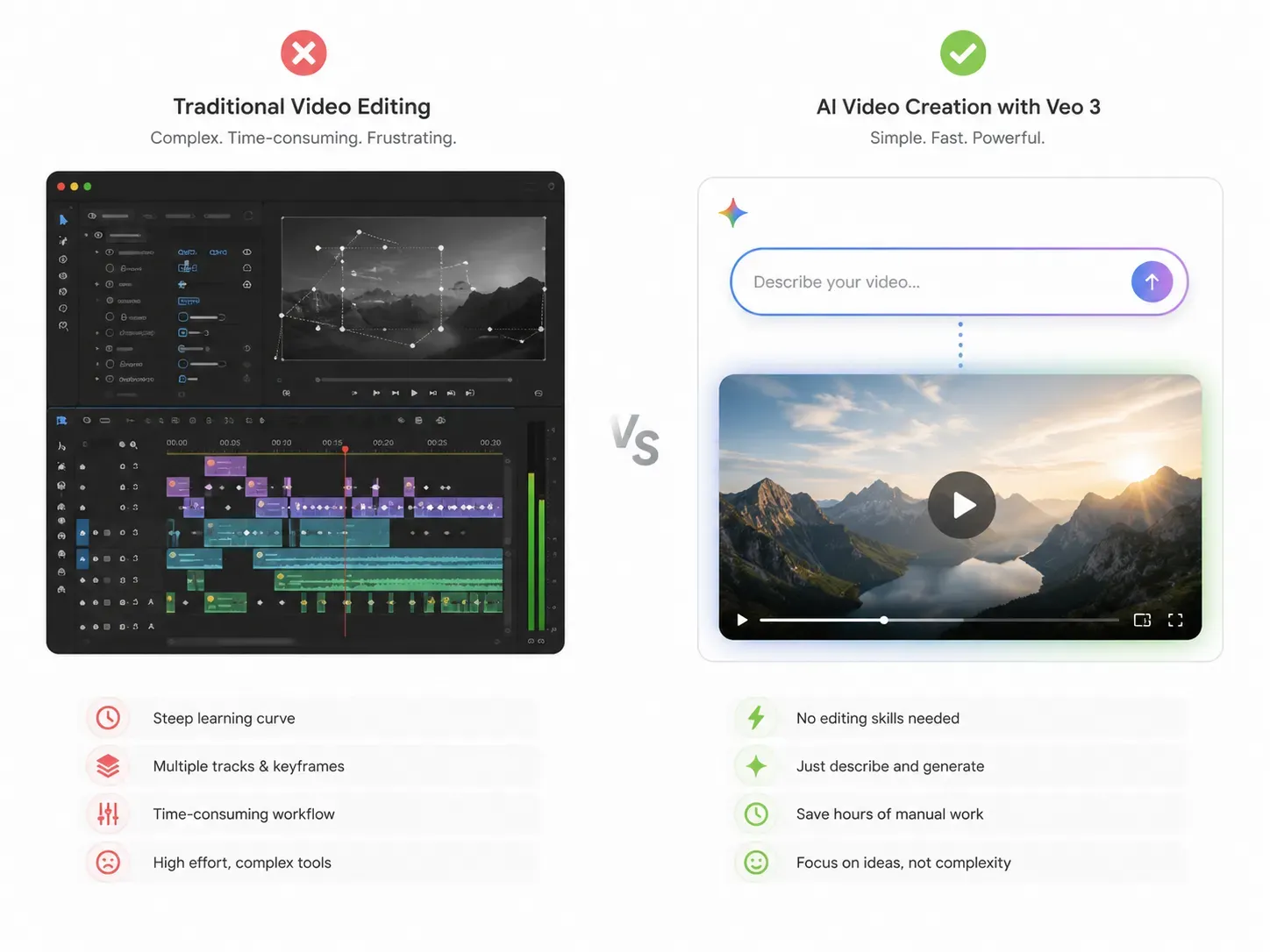
Entender la arquitectura es una cosa; ponerla a trabajar es otra. Aquí es donde la capacidad de IA de edición de video conversacional de Gemini Omni se distingue de las herramientas convencionales.
Los editores de video tradicionales exigen líneas de tiempo, capas y fotogramas clave manuales. Gemini Omni reemplaza ese flujo de trabajo por completo. Sube tu material, escribe o di qué debe cambiar, y el modelo volverá a renderizar el clip. Sin plugins. Sin software externo.
¿Puede Gemini Omni manejar el reemplazo complejo de elementos de video con IA?
Sí, y es una de sus funciones más útiles. Según la documentación oficial de Google, las tareas de modificación de recursos de video soportadas incluyen:
- Cambios de fondo — reemplazar el entorno detrás de un sujeto manteniendo al personaje
- Cambios de vestuario y estilo — modificar la ropa o transferir un estilo visual a través de un clip
- Sustitución de objetos — cambiar un elemento específico en una escena a mitad de toma
- Ajustes de iluminación — cambiar el ambiente o la intensidad de la luz de la escena mediante una sola instrucción
- Estabilización de video — suavizar imágenes movidas mediante un prompt en lenguaje natural
- Cambios de personaje — reemplazar un sujeto por otro usando una imagen de referencia
Edición de video interactiva mediante conversación de varios turnos
Lo que convierte a esta función en edición de video interactiva en lugar de una generación de un solo intento es el bucle de varios turnos. Cada instrucción de edición se basa en la anterior, por lo que el modelo mantiene la coherencia de la escena (el mismo fondo, la misma lógica de iluminación y la misma identidad del personaje) a lo largo de las rondas de refinamiento.
Por ejemplo, un creador podría instruir primero: "cambia el fondo a una calle de la ciudad", seguir con "haz la iluminación más cálida" y, finalmente, "estabiliza la toma", todo sin reiniciar la generación.
Reemplazo de elementos de video con IA: Qué esperar ahora mismo
El reemplazo de elementos de video con IA en el modelo actual Gemini Omni Flash está optimizado para clips de 10 segundos. Está prevista una modificación de recursos de video más compleja para formatos más largos, así como tipos de salida adicionales como imágenes y audio independientes, en futuras versiones.
Domina el bucle de varios turnos: Guía práctica de prompts para Gemini Omni
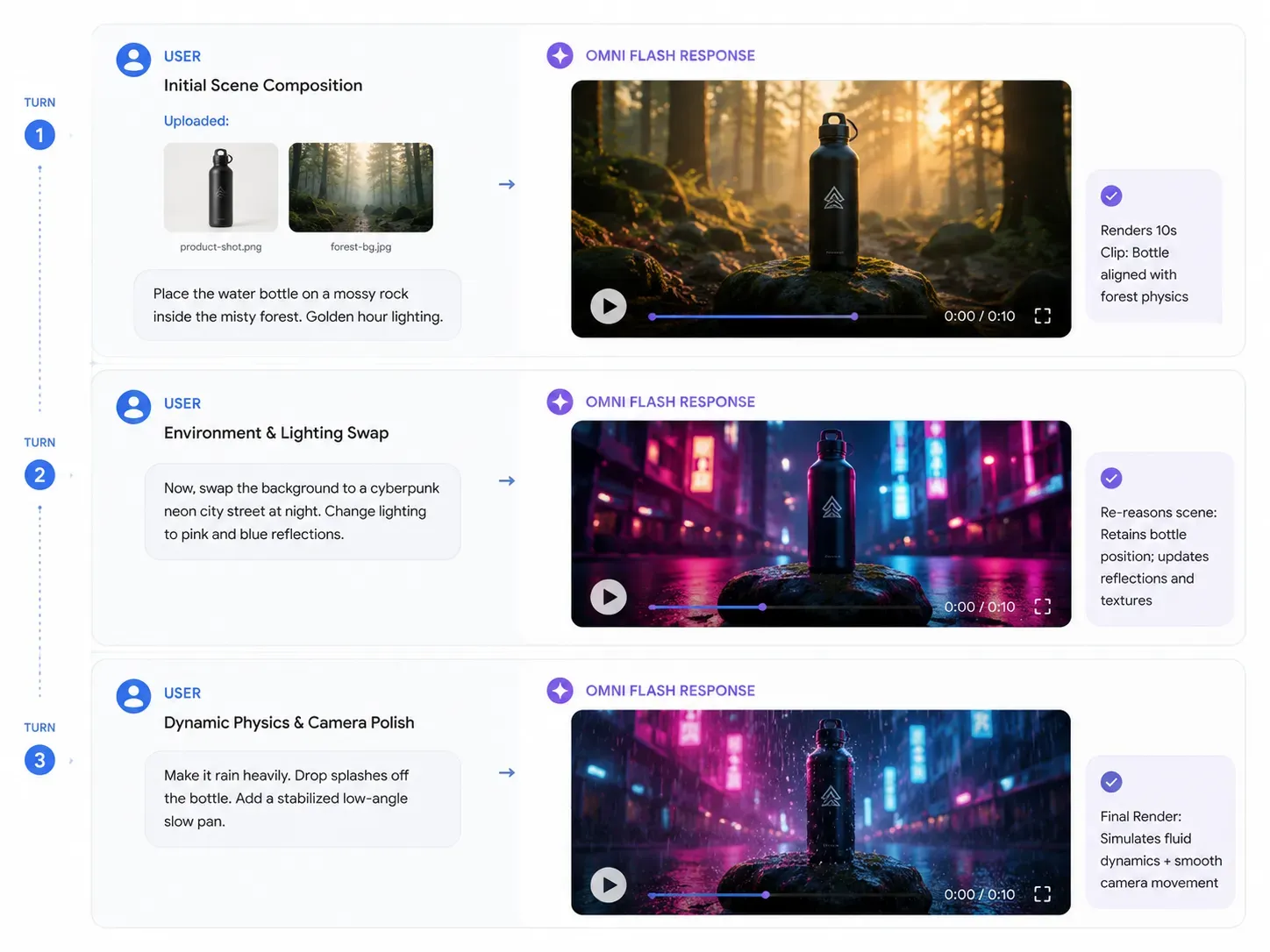
Para desbloquear todo el potencial de la multimodalidad nativa de Gemini Omni, tu estrategia de prompts debe pasar de la generación de un solo disparo a una conversación continua. Debido a que el motor de física del modelo mundial retiene la lógica del entorno, puedes añadir instrucciones paso a paso.
Aquí tienes un ejemplo práctico y listo para producción para un flujo de trabajo comercial:
Turno 1: La entrada de referencia inicial
Recursos de entrada: Sube marca-producto.png (una botella de agua metálica) y referencia-fondo.jpg (un bosque con niebla).
Prompt: "Genera una presentación de producto cinematográfica de 10 segundos. Coloca la botella de agua metálica de la imagen sobre una roca cubierta de musgo dentro del bosque con niebla. Configura la iluminación como si fuera la hora dorada de la mañana."
Salida de IA esperada: Omni razona sobre ambas imágenes simultáneamente, colocando la botella de forma realista sobre la roca con una física de peso precisa y una proyección de sombras inicial correcta.
Turno 2: La modificación dinámica de recursos
Contexto de entrada: Chat continuo dentro de la misma sesión (no hace falta volver a subir nada).
Prompt: "Ahora, cambia el fondo. Sustituye el bosque con niebla por una calle minimalista de una ciudad cyberpunk de noche. Cambia la iluminación para que los reflejos azul frío y rosa intenso de las luces de neón impacten en la superficie metálica de la botella."
Salida de IA esperada: El entorno del fondo cambia al instante. Lo más importante es que la posición de la botella en la roca permanece constante, pero sus reflejos superficiales cambian dinámicamente para reflejar las nuevas fuentes de luz de neón.
Turno 3: El pulido físico
| Acción del prompt | Comando objetivo |
|---|---|
| Añadir física ambiental | "Haz que empiece a llover intensamente en la escena. Asegúrate de que las gotas salpiquen de forma realista sobre la tapa de la botella y se formen ondas en el suelo." |
| Aplicar control de cámara | "Haz un paneo lento de la cámara desde un ángulo bajo hacia arriba y aplica estabilización de video en lenguaje natural para suavizar la transición." |
Aunque dominar el bucle de varios turnos dentro de Google Flow optimiza tu canal de prompts, los desarrolladores que escalan flujos de trabajo multimodelo a menudo requieren mayor flexibilidad. Implementar APIs de IA multimodal unificadas permite a plataformas como Atlas Cloud servir más de 300 modelos —incluidos motores de video avanzado, imagen y razonamiento LLM— bajo una sola capa de orquestación.
Simulando la realidad: El poder del motor de física del modelo mundial de Gemini Omni
La edición conversacional produce excelentes resultados solo cuando el modelo entiende por qué una escena luce de determinada manera. Ahí es donde la capa de física del modelo mundial de Gemini Omni se vuelve crítica.
En Google I/O 2026, el CEO de Google DeepMind, Demis Hassabis, describió a Gemini Omni no como un generador de video, sino como un modelo mundial: un sistema que construye una comprensión interna de la realidad y razona sobre lo que debería suceder a continuación en cualquier escena dada.
Qué significa "modelo mundial" en la práctica

La mayoría de las herramientas de IA de video anteriores predecían el siguiente fotograma mediante la coincidencia de patrones de píxeles a gran escala. Producían imágenes que parecían reales pero que no se comportaban de manera consistente: los personajes se transformaban entre cortes, las sombras ignoraban las fuentes de luz y los fluidos se movían como una textura en lugar de como una sustancia.
Gemini Omni está entrenado de forma diferente. Según Google, el modelo incorpora una comprensión del mundo real sobre física, movimiento y IA de conciencia espacial para basar sus resultados en cómo funciona realmente el mundo físico.
Propiedades físicas que Gemini Omni está entrenado para simular
Google afirma que el modelo tiene una comprensión intuitiva de las siguientes propiedades físicas, basándose en Genie, la plataforma de simulación de mundos de juego de DeepMind:
| Propiedad física | Efecto práctico en el video |
|---|---|
| Gravedad | Los objetos caen y aterrizan con un peso preciso |
| Energía cinética | El impulso se conserva en las colisiones |
| Dinámica de fluidos | El agua, el humo y los líquidos se comportan naturalmente |
| Consistencia lumínica | Las sombras se desplazan correctamente al editar escenas |
| Anatomía espacial | Las proporciones del personaje se mantienen entre cortes |
Por qué esto es importante para la generación de video consistente
Durante la conferencia I/O 2026, esta capa fue puesta a prueba creando una explicación muy precisa en arcilla sobre el plegamiento de proteínas, demostrando que el modelo va más allá de la simple coincidencia de píxeles para comprender la realidad científica y espacial.
Esta base de modelo mundial es lo que permite una generación de video consistente a través de ediciones de varios turnos. Cuando un usuario cambia un fondo o ajusta la iluminación mediante una conversación, el modelo no solo superpone una capa nueva, sino que vuelve a razonar la relación física entre el sujeto, el nuevo entorno y la fuente de luz. El resultado es la simulación de la realidad física a nivel de escena, en lugar de parchear píxeles.
El cambio de paradigma: Coincidencia de píxeles vs. Simulación del mundo
| Herramientas de IA de video heredadas (Vieja era) | Google Gemini Omni (Modelo mundial) |
| ❌ Carece de lógica central; solo predice la probabilidad estadística del siguiente grupo de píxeles. | 🧠 Comprende la masa de los objetos, el impulso cinético y la conservación de la energía de los fluidos. |
| ❌ Las sombras se deforman y las texturas se rompen dinámicamente cuando cambia el ángulo de cámara. | 🧠 Simula la iluminación global, asegurando que los rayos de luz y los reflejos se refracten naturalmente. |
| ❌ La anatomía del personaje y las estructuras del fondo se distorsionan tras 3–5 segundos. | 🧠 Conserva un entorno unificado, lógica de iluminación e identidad a través de ediciones de varios turnos. |
Avatares digitales personalizados: ¿Puede Gemini Omni crear un avatar de IA para creadores de contenido?
La física del modelo mundial descrita hace que el metraje generado luzca real. La función de avatar hace que luzca como tú.
¿Puede Gemini Omni crear un avatar de IA? Sí. Gemini Omni Flash incluye una herramienta dedicada de avatar que permite a los creadores construir una apariencia digital propia —utilizando su propia imagen y voz— y desplegarla directamente dentro de videos generados sin tener que volver a subir material de referencia cada vez.
![]()
Cómo funciona el registro del avatar
Para evitar el uso indebido, Google ha añadido un paso de verificación estructurado antes de que se cree el avatar. Según TechCrunch, los usuarios completan un proceso de registro dedicado que implica grabarse a sí mismos y leer una serie de números. La imagen grabada se almacena y reutiliza en futuras sesiones.
La edición de voz completa de clips de terceros sigue bajo revisión mientras Google trabaja en un despliegue responsable. Todos los avatares digitales personalizados y videos generados llevan la marca de agua digital SynthID de Google, que es verificable a través de la app Gemini, Gemini en Chrome y la Búsqueda de Google.
¿Cómo se integra Gemini Omni con YouTube Shorts y Google Flow?
La siguiente tabla muestra el acceso actual por plataforma:
| Plataforma | Nivel de acceso | Notas |
|---|---|---|
| App Gemini | Suscriptores AI Plus, Pro & Ultra | Funciones completas de Omni Flash, incluido avatar |
| Plataforma Google Flow | Suscriptores AI | Incluye Flow Agent, edición por lotes, Flow Music |
| Herramientas de YouTube Shorts | Gratis, sin suscripción | Disponible desde la semana de Google I/O 2026 |
| App YouTube Create | Gratis | Mismo calendario de despliegue que Shorts |
| API para desarrolladores | Próximamente | Acceso para empresas y Google AI Studio |
La plataforma Google Flow recibió actualizaciones adicionales junto con Omni Flash: un Flow Agent para lluvia de ideas y generación por lotes, una función de herramientas personalizadas para flujos de trabajo sin código compartibles, y soporte de Flow Music para la creación completa de videos musicales y transformación de estilo.
Seguridad de contenido y origen: Cómo la marca de agua de video Google SynthID protege los medios
Las potentes herramientas de creación de avatares y edición de video plantean una pregunta obvia: ¿qué impide que se utilicen para crear contenido engañoso? La respuesta de Google es una marca de agua imperceptible y obligatoria integrada en cada clip que produce Gemini Omni.
¿Qué es la marca de agua de video Google SynthID?
La marca de agua de video Google SynthID no es un logotipo visible ni una etiqueta de metadatos eliminable. Es una señal incrustada directamente en los píxeles de un video en el momento de su generación: invisible al ojo humano pero legible por las herramientas de detección de Google. Según la conferencia I/O 2026 de Google, SynthID ha marcado ya más de 100 mil millones de imágenes y videos generados por IA desde su lanzamiento.
Es fundamental destacar que la señal está diseñada para sobrevivir a operaciones comunes de postprocesamiento que de otro modo borrarían un marcador superficial:
- Compresión y recodificación
- Cambio de tamaño y recorte
- Conversión de formato
Para Gemini Omni específicamente, SynthID está activado por defecto y no se puede desactivar.
Cómo funciona la verificación de procedencia de medios de IA
La procedencia de medios de IA se puede verificar a través de tres superficies de Google: la app Gemini, Gemini en Chrome y la Búsqueda de Google. Los usuarios suben un clip y el detector resalta las marcas de tiempo específicas donde se encuentra la señal de marca de agua, ofreciendo una verificación contextual en lugar de un simple resultado sí/no.
SynthID como estrategia de mitigación de deepfakes
| Capa de seguridad | Qué hace |
|---|---|
| Marca de agua a nivel de píxel | Sobrevive a la compresión, recorte y recodificación |
| Incrustación obligatoria | El usuario no puede desactivarla |
| Adopción multiplataforma | OpenAI y ElevenLabs están adoptando el estándar C2PA |
| Verificación de avatar | Requiere verificación de voz antes de guardar la imagen |
| Edición de voz restringida | Edición retenida hasta un despliegue responsable |
Sundar Pichai citó el contexto claramente en I/O 2026: los estudios demuestran que la gente identifica correctamente los videos deepfake de alta calidad solo alrededor de una cuarta parte de las veces. SynthID, junto con la restricción de la edición de voz, forma el enfoque en capas de Gemini Omni para la mitigación de deepfakes y las funciones de seguridad de contenido.
Gemini Omni Flash vs Pro: Niveles de suscripción, precios de tokens y acceso a API
Con el conjunto de funciones claro, la siguiente pregunta es práctica: ¿cuánto cuesta el acceso y qué nivel se ajusta a tu flujo de trabajo?
¿Cómo obtener acceso a Gemini Omni Flash ahora mismo?

Gemini Omni Flash comenzó a desplegarse el 19 de mayo de 2026. Las rutas de acceso dependen de cómo pretendas usarlo:
| Nivel de plan | Precio mensual | Almacenamiento | App Gemini y funciones principales |
|---|---|---|---|
| Google AI Plus | USD7.99 / mes | 200 GB | Límites de uso: 2x mayor que sin plan; acceso a modelo Flash Thinking; |
| Google AI Pro | USD19.99 / mes | 5 TB | Límites de uso: 4x mayor que sin plan; acceso a modelo Pro, Deep Research y más; |
| Google AI Ultra | USD99.99 / mes | 20 TB | Límites de uso: 5x más que Pro; límites más altos que en Pro, acceso a funciones como Deep Think; |
Cómo obtener acceso a Gemini Omni dentro de Google Flow depende de los créditos Google Flow Omni asignados al plan: pasando del acceso básico en AI Plus, a canales de filmación de varios turnos en AI Pro, hasta límites de computación de estudio de alta capacidad en AI Ultra.
Para despliegues de aplicaciones estándar, el modelo de pago por token de Vertex AI de Google mantiene los costos predecibles. Sin embargo, para canales de renderización de nivel de producción que alcanzan límites rígidos de API, cambiar a modelos de precios de GPU bajo demanda ofrece una alternativa más rentable, dando a los equipos control sobre el hardware sin compromisos mínimos.
Gemini Omni Flash vs Pro: ¿Cuál es la diferencia?
En la comparación Gemini Omni Flash vs Pro, un lado está confirmado y el otro aún no está disponible. Flash genera clips de 10 segundos (un límite de despliegue deliberado para gestionar la demanda de cómputo en el lanzamiento, no un límite del modelo, según Nicole Brichtova de Google DeepMind).
Omni Pro ha sido anunciado, pero no tiene fecha de lanzamiento. Google dice que llegará cuando el equipo vea "un cambio cualitativo por encima de Flash". Hasta entonces, Flash es el único modelo Omni disponible públicamente.
Gemini Omni vs Google Veo: ¿Qué ha cambiado?
Gemini Omni vs Google Veo es un cambio arquitectónico, no una mejora de versión. Veo 3.1 sigue activo con acceso API GA para la generación de texto a video. Omni añade una capa de razonamiento, acepta los cuatro tipos de entrada simultáneamente e introduce la edición conversacional de varios turnos, algo para lo que Veo no fue diseñado.
Una API unificada para la generación de video de producción
Mientras Google despliega Gemini Omni Flash dentro de la app Gemini y Google Flow para los usuarios finales, los desarrolladores y equipos de producto que desean integrar el mismo motor de video multimodal en sus propios flujos de trabajo necesitan una capa de API estable y predecible.
Atlas Cloud ofrece Gemini Omni Flash a través de una API unificada y compatible con OpenAI, junto con más de 300 otros modelos de imagen, video y LLM, para que puedas integrar el modelo multimodal nativo de Google sin tener que gestionar cuentas, portales de facturación o SDKs de proveedores separados.
Ambas variantes de Gemini Omni Flash están activas en Atlas Cloud:
| Variante | Ideal para | Entradas | Resolución | Duración | Precio inicial |
| Gemini Omni Flash Text-to-Video (Developer) | Generación cinematográfica basada en prompts | Texto (hasta 20,000 carac.) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
| Gemini Omni Flash Image-to-Video (Developer) | Video consistente basado en referencias reales | Texto + hasta 7 imágenes ref. | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
Inicio rápido: Genera un video con Gemini Omni Flash en 5 líneas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "Un bosque con niebla durante la hora dorada, toma cinematográfica dolly", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
La API devuelve un ID de predicción de inmediato; consulta /api/v1/model/prediction/{id} para obtener la URL del MP4 renderizado. El esquema completo, muestras de código en 7 lenguajes y un área de juego sin código están disponibles en las páginas del modelo vinculadas arriba.
Conclusión: El futuro del contenido multimodal
Gemini Omni representa algo más que un mejor generador de video. Al fusionar el motor de razonamiento de Gemini con la generación multimodal nativa, Google ha reducido lo que antes requería cuatro herramientas separadas (prompts de texto, referencias de imagen, renderizado de video y edición de postproducción) en un solo flujo de trabajo conversacional.
Las implicaciones aumentan rápidamente. La física del modelo mundial significa que las ediciones lucen creíbles sin necesidad de composición manual. La procedencia de SynthID significa que la responsabilidad está integrada. La creación de avatares significa que los creadores pueden producir a escala sin tener que ponerse frente a una cámara cada vez. Y con Omni Flash ya en vivo en la app Gemini, Google Flow y YouTube Shorts, la barrera de entrada es lo suficientemente baja tanto para creadores individuales como para equipos empresariales.
Lo que venga después (Omni Pro, acceso más amplio a la API y modalidades de salida expandidas) definirá hasta dónde llega este cambio.
Ahora queremos conocer tu opinión. ¿Qué función de Gemini Omni probarás primero en tu flujo de trabajo: ediciones de fondo conversacionales, creación de avatares o generación de escenas basadas en la física? Deja tu respuesta en los comentarios a continuación.






