
Respuesta rápida
Una "Skill" (habilidad) de generador de video con IA para GitHub conecta tu código con modelos de video mediante IA. En 2026, elegir entre código abierto (gratuito, autohospedado) y APIs de pago (nube, instantáneo) depende de cuatro variables: disponibilidad de VRAM, requisitos de privacidad de datos, el límite de calidad necesario y el volumen mensual de generación. Para flujos de trabajo a escala de producción que requieren múltiples modelos SOTA (de última generación), Atlas Cloud (atlascloud.ai) ofrece acceso a más de 300 modelos —incluyendo Kling v3.0, Seedance 2.0, Vidu 3.0, Veo y Sora— a través de una única clave API con precios transparentes de pago por uso.
-
¿Qué es una Skill de generador de video con IA? {#what-is-a-skill}
En el contexto de los repositorios de GitHub, una Skill de generador de video con IA es un módulo reutilizable, contenedor o capa de integración que conecta una aplicación con un backend de generación de video con IA, ya sea un modelo de código abierto autohospedado o una API en la nube.
Piensa en esto como la abstracción entre la lógica de tu aplicación y el motor de inferencia real. Una skill puede ser:
- Una clase de Python que envuelve el pipeline del modelo
Wan 2.2para generación de texto a video. - Un nodo personalizado de ComfyUI que se conecta a la API de Atlas Cloud para generar con Kling v3.0.
- Un nodo de flujo de trabajo de n8n que dispara Seedance 2.0 mediante REST y devuelve una URL de video.
- Una herramienta de LangChain o una skill de servidor MCP que invoca un endpoint de generación de video bajo demanda.
La pregunta fundamental a la que se enfrenta todo desarrollador al crear una: ¿debería el backend ser pesos de código abierto ejecutándose localmente o una API de pago en la nube?
Datos reales de 2026. Nada de teoría.
-
Código abierto en GitHub en 2026 {#open-source-landscape}
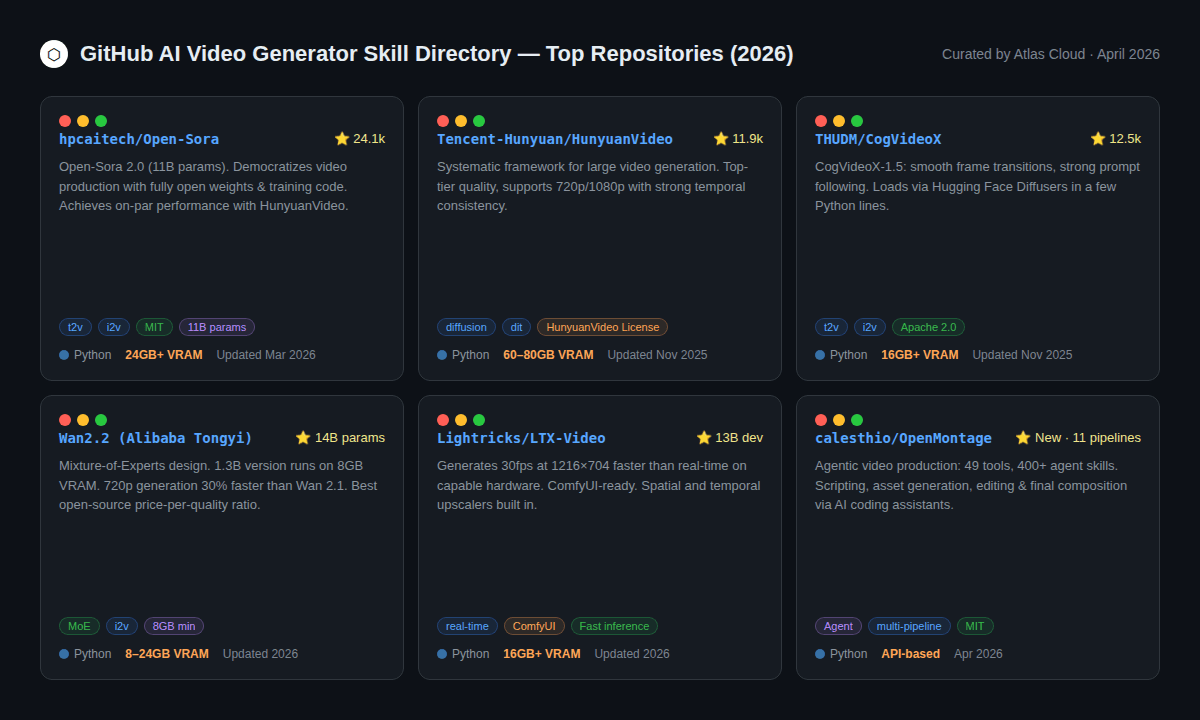
El ecosistema de generación de video de código abierto ha madurado significativamente. Algunos repositorios son ahora alternativas genuinas a las APIs de pago, al menos para ciertas tareas.
Nivel 1: Modelos de código abierto de grado de producción
HunyuanVideo (Tencent, 11.9k ⭐) — Uno de los mejores generadores de video de código abierto disponibles. Maneja 720p y 1080p. Su principal limitación es el requisito de hardware: 60–80 GB de VRAM para el modelo completo, lo que lo hace accesible solo para equipos con acceso a GPU empresariales. La licencia comunitaria permite el uso comercial con atribución.
CogVideoX-1.5 (THUDM/CogVideo, 12.5k ⭐) Lanzado bajo Apache 2.0, es uno de los modelos abiertos más amigables para los desarrolladores. Se carga de forma nativa mediante Hugging Face Diffusers con unas pocas líneas de Python. Las transiciones entre fotogramas son suaves y el seguimiento de prompts es sólido. Requiere un mínimo de 16 GB de VRAM. Una opción sólida si tu equipo ya trabaja habitualmente con Hugging Face.
Open-Sora 2.0 (hpcaitech, 24.1k ⭐) El proyecto de generación de video de código abierto con más estrellas en GitHub. La versión 2.0 (11B de parámetros) logra un rendimiento comparable al de HunyuanVideo en los benchmarks de VBench, y se informó que el costo de entrenamiento fue de aproximadamente $200,000, una cifra notable para un modelo de este calibre. Ofrece texto a video, imagen a video y generación de duración infinita.
Nivel 2: Opciones de código abierto más ligeras (menor VRAM)
Wan 2.2 (Alibaba Tongyi) La accesibilidad aquí es convincente: la variante de 1.3B funciona con 8 GB de VRAM, y la de 14B con 24 GB. La arquitectura de "Mezcla de Expertos" (MoE) ofrece mejores detalles con un menor costo de cómputo, y la versión 2.2 es un 30% más rápida a 720p que su predecesora. Para desarrolladores que utilizan una sola GPU de consumo, Wan 2.2 es la opción de código abierto más potente.
LTX-Video (Lightricks) Diseñado para la velocidad por encima de todo. Genera a 30fps en una resolución de 1216×704 más rápido que el tiempo real en hardware capaz. La integración con ComfyUI es madura e incluye escaladores espaciales y temporales integrados.
Nivel 3: Pipelines agénticos
OpenMontage (calesthio, nuevo en abril de 2026) Una categoría genuinamente novedosa: un sistema de producción de video agéntico con 11 pipelines, 49 herramientas y más de 400 habilidades de agentes. Funciona con asistentes de programación IA como Claude Code, Cursor y Copilot. Maneja el flujo de trabajo completo (investigación, guion, activos, edición) de principio a fin sin pasos manuales. Creado para equipos que integran múltiples herramientas de IA en un solo flujo.
-
Directorio de APIs de pago: Modelos SOTA disponibles ahora {#paid-api-directory}
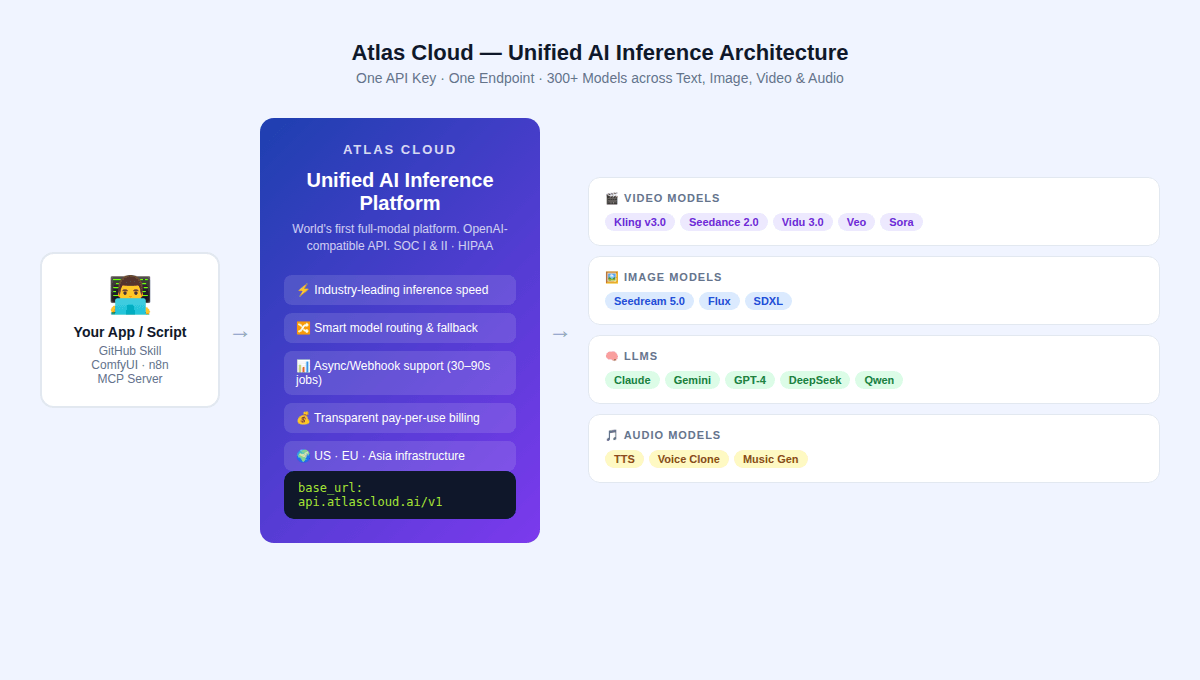
El panorama de las APIs de pago en 2026 se define por tres grandes familias de modelos, cada una con un enfoque técnico distinto. Las tres están disponibles a través de la API unificada de Atlas Cloud.
Kling v3.0 (Kuaishou)
Lanzado el 5 de febrero de 2026. Construido sobre una arquitectura de lenguaje visual multimodal: texto, imágenes, audio y video manejados en un solo sistema.
Lo que hace mejor que sus competidores:
- Movimiento humano complejo (correr, bailar, artes marciales) sin la deformación de "extremidades de espagueti" que afecta a otros modelos.
- Generación de audio nativa multilingüe (5 idiomas, incluyendo movimiento de labios sincronizado).
- Pincel de movimiento (Motion Brush): una herramienta que permite a los desarrolladores (o usuarios finales) pintar trayectorias de movimiento directamente sobre imágenes fuente, una característica que actualmente no tiene equivalente en modelos de la competencia.
- Vinculación de elementos para un seguimiento consistente de personajes y objetos a través de las tomas.
Donde se queda corto: La velocidad de renderizado es más lenta que la de algunos competidores en el nivel Pro. Las transiciones de la herramienta de guion gráfico (storyboard) pueden ser "torpes" según analistas independientes.
Ideal para: Contenido corto en TikTok y Reels, videos de productos de comercio electrónico y cualquier cosa que requiera mucho volumen con personajes que se mantengan consistentes.
Seedance 2.0 (ByteDance)
Lanzado el 8 de febrero de 2026, Seedance 2.0 representa un cambio de paradigma en cómo se crean los prompts para video por IA, pasando de prompts solo de texto a un control basado en referencias al estilo director.
La innovación técnica central: Seedance 2.0 acepta entradas cuadrimodales (texto, imagen, video y audio) simultáneamente. Su sistema de "Referencia Universal" permite a un desarrollador introducir un video de referencia de una persona bailando, y el modelo replicará el movimiento de cámara, las acciones del personaje y la composición en el resultado generado. Esto resuelve la consistencia de personajes de una manera que los modelos puramente de texto a video no pueden.
Las pruebas independientes confirman que destaca en:
- Narrativa de múltiples tomas con una identidad de personaje consistente en todos los cortes.
- Generación sincronizada de audio y video (arquitectura de doble rama que genera sonido y video simultáneamente).
- Replicación precisa de la composición y la iluminación de activos de referencia.
Nota sobre disponibilidad: A partir de abril de 2026, el acceso a la API internacional de Seedance 2.0 está disponible a través de plataformas como Atlas Cloud. El acceso directo a la API de BytePlus para desarrolladores internacionales ha tenido inconsistencias de disponibilidad; confirma el estado actual antes de establecer una dependencia en los endpoints directos de ByteDance.
Ideal para: Videos musicales, animación de personajes precisa, anuncios de productos donde el movimiento debe ser exacto y agencias que ejecutan flujos de trabajo de guion gráfico a video.
Vidu 3.0 (Shengshu AI / Tsinghua)
Construido sobre la arquitectura U-ViT original que combina tecnologías de difusión y transformadores, Vidu se centra en áreas donde la mayoría de los videos de IA aún tienen dificultades: coherencia ambiental y consistencia cinematográfica.
Características distintivas:
- Sistema de referencia universal para una iluminación consistente a través de secuencias de múltiples tomas.
- Generación inteligente de música de fondo que se adapta automáticamente al estado de ánimo de la escena.
- Generación de formato largo con una fuerte consistencia temporal (crítico para secuencias de más de 5 segundos).
Mejores casos de uso: Flujos de trabajo cinematográficos profesionales, diseño de animación, publicidad creativa que requiere calidad cinematográfica.
Sora 2 (OpenAI)
Sora 2 sigue siendo el punto de referencia para la precisión en la simulación física. Rompe un cristal en un prompt de Sora 2 y el patrón de fragmentación, la física de fluidos y los reflejos se comportan como en la realidad; la mayoría de los competidores aún no pueden igualar ese nivel de consistencia.
Ideal para: Trabajos de VFX, visualización arquitectónica, B-roll documental y cualquier situación donde la precisión física sea más importante que el ahorro de dinero.
Precio: Sora 2 genera la factura más alta en esta categoría. Pagas por la capacidad de computación.
-
Costos de inferencia: Los números reales {#inference-costs}
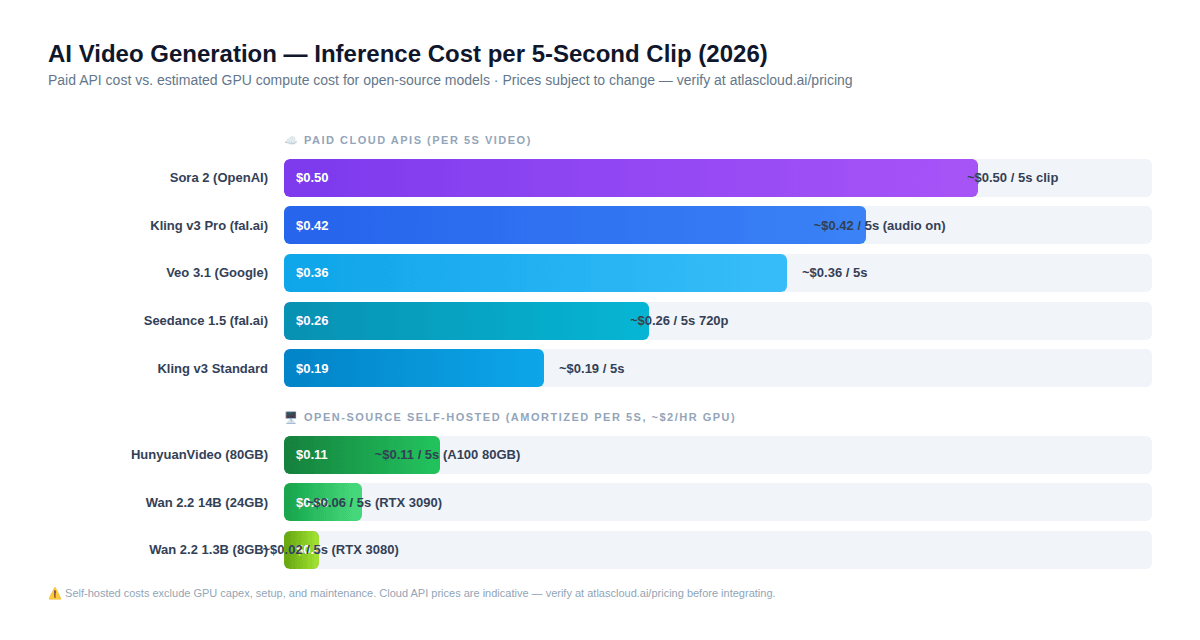
Esta sección contiene el hallazgo contraintuitivo más importante de toda esta guía, uno que cambia la intuición predeterminada de la mayoría de los desarrolladores sobre el código abierto frente a las APIs de pago.
El costo oculto de los modelos autohospedados
La mayoría de los desarrolladores asumen: "Código abierto = gratis = siempre más barato".
Esta suposición es incorrecta para la mayoría de los tamaños de equipo.
Aquí está cómo se ven los números reales para un clip de video de 5 segundos en 2026:
Código abierto autohospedado (costo de GPU amortizado a ~$2/hora):
- Wan 2.2 1.3B (RTX 3080): ~$0.02 por clip de 5s
- Wan 2.2 14B (RTX 3090): ~$0.06 por clip de 5s
- HunyuanVideo (A100 80GB): ~$0.11 por clip de 5s
API de nube de pago (precios indicativos — verificar en atlascloud.ai/pricing):
- Kling v3 Standard: ~$0.19 por clip de 5s
- Seedance 1.5 720p con audio: ~$0.26 por clip de 5s
- Kling v3 Pro con audio: ~$0.42 por clip de 5s
- Sora 2: ~$0.50 por clip de 5s
Los números del autohospedaje parecen convincentes de forma aislada. El problema es que excluyen:
- Hardware de GPU — Una A100 de 80GB cuesta entre $10,000 y $15,000. Con 1,000 videos al mes (~$0.11 cada uno), estarías mirando más de 9,000 meses solo para recuperar el costo del hardware.
- Tiempo de configuración — La configuración de CUDA, la descarga de pesos del modelo, la gestión de VRAM y la depuración representan entre 20 y 40 horas de ingeniería de configuración inicial.
- Mantenimiento continuo — Las actualizaciones de modelos, los conflictos de dependencias y la fiabilidad de la infraestructura son costos de tiempo constantes.
- Costo de oportunidad — El tiempo dedicado a la infraestructura de inferencia es tiempo que no se dedica al producto.
La condición límite práctica:
El autohospedaje solo es rentable si: (a) ya tienes GPUs ejecutando otras cargas de trabajo, (b) generas más de 5,000 videos al mes, o (c) las regulaciones te obligan a mantener todo localmente (on-prem).
Por debajo de ese umbral, las APIs de pago —especialmente plataformas unificadas como Atlas Cloud— son más baratas cuando se calcula honestamente el costo total de propiedad.
-
Limitación de tasa y latencia de API — Lo que realmente enfrentan los desarrolladores {#rate-limiting}
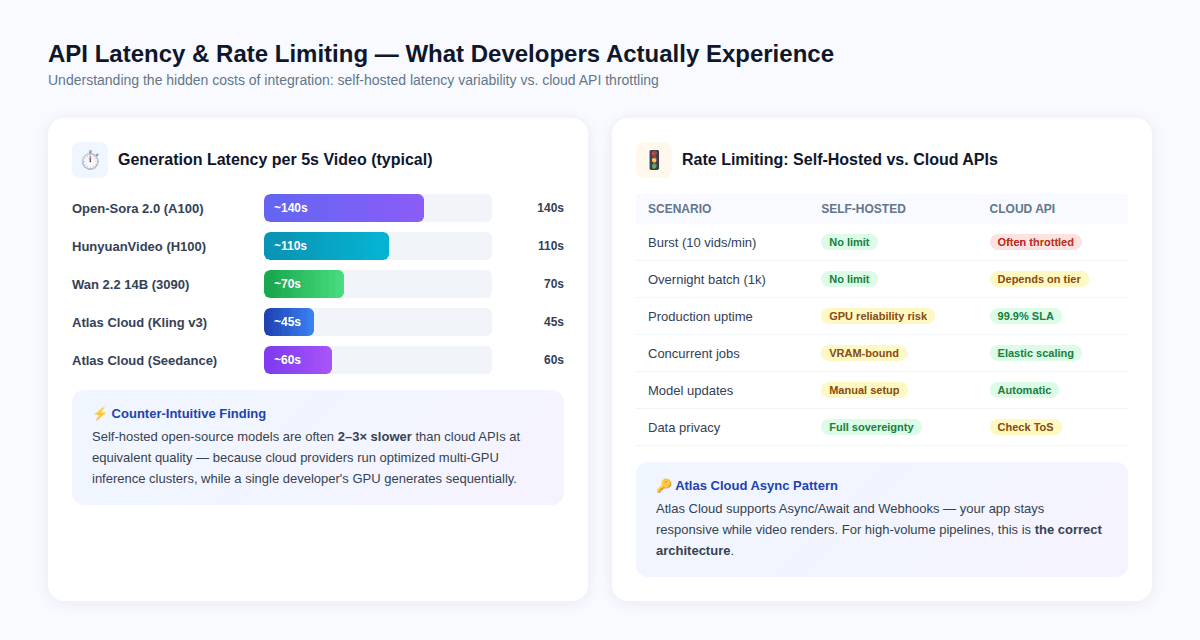
La paradoja de la latencia
Contraintuitivamente, las APIs en la nube suelen ser más rápidas por video que los modelos autohospedados, no porque los modelos sean diferentes, sino porque los proveedores de nube ejecutan clústeres de inferencia de múltiples GPUs optimizados con procesamiento por lotes a nivel de hardware, mientras que una GPU de un solo desarrollador genera fotogramas de forma secuencial.
Latencia típica por clip de 5 segundos:
- Open-Sora 2.0 en A100: ~140 segundos
- HunyuanVideo en H100: ~110 segundos
- Wan 2.2 14B en RTX 3090: ~70 segundos
- Atlas Cloud / Kling v3: ~45 segundos
- Atlas Cloud / Seedance 2.0: ~60 segundos
Esto significa que construir una skill de GitHub alrededor de un modelo autohospedado puede producir tiempos de espera más largos para el usuario, incluso cuando el costo por video es menor.
Limitación de tasa (Rate Limiting): La realidad de producción
Los modelos autohospedados no tienen límites de tasa impuestos por API: están limitados solo por la VRAM y los límites térmicos de tu GPU.
Las APIs de pago imponen límites de tasa que varían según el nivel de precios. Las implicaciones de ingeniería relevantes:
- Solicitudes en ráfaga (más de 10 videos por minuto) activarán la limitación en la mayoría de los niveles de API de pago.
- Trabajos por lotes nocturnos (más de 1,000 videos) requieren un diseño asíncrono cuidadoso para evitar tiempos de espera.
- Las solicitudes concurrentes en modelos autohospedados están limitadas por la VRAM; ejecutar 2 inferencias concurrentes del modelo 14B en una sola tarjeta de 24GB generalmente no es posible.
Atlas Cloud** resuelve el problema de la limitación de tasa** a través de una arquitectura asíncrona/webhook: tu aplicación envía un trabajo de generación, recibe un ID de tarea y recibe una notificación vía webhook cuando el renderizado se completa. Este patrón evita que la aplicación se bloquee mientras el video se renderiza, y escala correctamente para cargas de trabajo por lotes.
La arquitectura correcta para producción
plaintext1# Patrón asíncrono de Atlas Cloud — Listo para producción 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key="TU_CLAVE_API_DE_ATLAS_CLOUD", 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10# Enviar tarea de generación 11response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt="Product showcase reel, smooth motion, 9:16 aspect ratio", 14 size="1080x1920", 15 n=1 16) 17 18# Manejar respuesta asíncrona 19video_url = response.data[0].url 20print(f"Video generado: {video_url}")
Para flujos de trabajo de imagen a video, ten en cuenta que algunos modelos, incluyendo ciertas variantes de Kling i2v, no aceptan un parámetro de relación de aspecto separado para la generación de imagen a video; la resolución de salida sigue las dimensiones de la imagen de entrada. Construye tu generación de imagen ascendente con la relación de destino correcta.
-
Autohospedaje vs. API en la nube: La matriz de compensaciones {#local-vs-cloud}
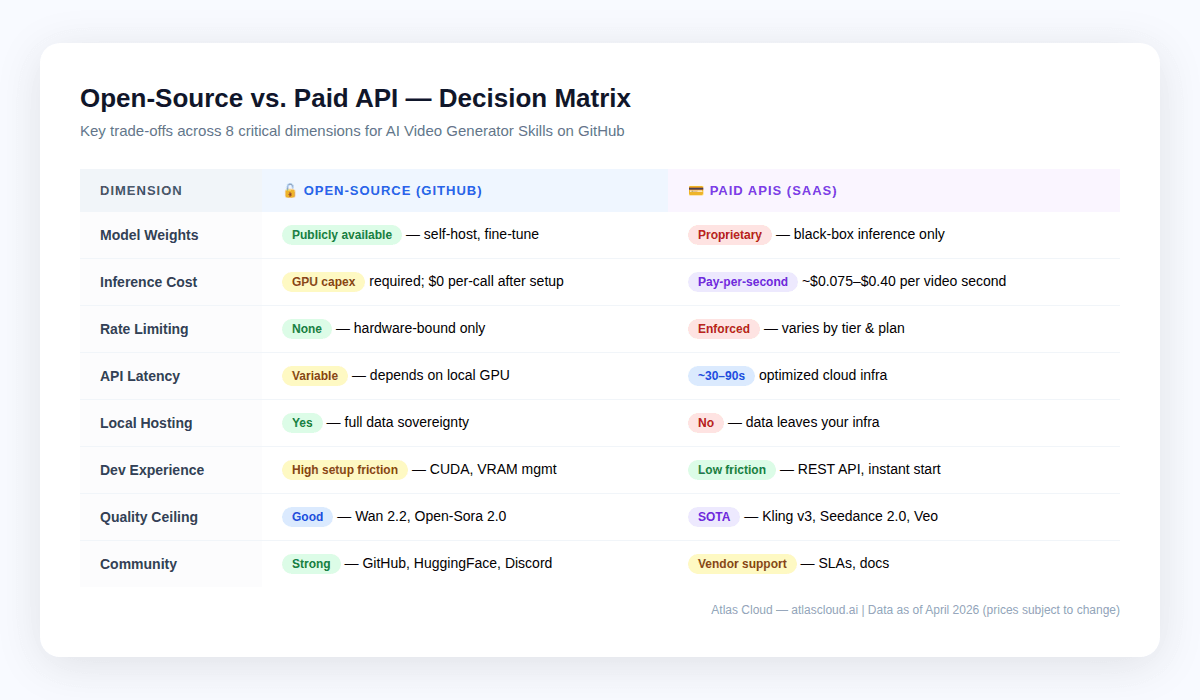
No es una decisión excluyente. La mayoría de los pipelines de producción mezclan ambos: código abierto para prototipos y pasadas de baja calidad a granel, y APIs en la nube para renders finales y calidad de vanguardia.
¿Cuándo tiene sentido el entorno local?
- Bloqueos de cumplimiento — HIPAA, GDPR o cualquier dato propietario que no pueda salir de tus servidores. El autohospedaje es tu única opción. Atlas Cloud cumple con HIPAA y está certificado SOC I & II, lo que cubre la mayoría de las necesidades empresariales, pero las tiendas reguladas deben verificar sus requisitos específicos.
- Volumen muy alto con calidad aceptable — los equipos que generan más de 10,000 videos al mes con niveles de calidad como Wan 2.2 pueden encontrar que los costos de alquiler de GPU son menores que las tarifas de API a esa escala.
- Investigación y ajuste fino (fine-tuning) — los pesos de los modelos abiertos permiten realizar ajustes finos con conjuntos de datos propietarios. Ninguna API en la nube ofrece actualmente entrenamiento de modelos personalizados.
- Configuraciones desconectadas (Air-gapped) — despliegues en el borde sin conectividad o redes bloqueadas.
¿Cuándo ganan las APIs en la nube?
- Tiempo de comercialización — una integración con Atlas Cloud toma horas, no semanas.
- Calidad de primer nivel — los líderes de código abierto como Wan 2.2 y Open-Sora 2.0 todavía están por detrás de los modelos propietarios como Kling v3 y Seedance 2.0, especialmente en movimiento humano, consistencia de tomas y audio nativo.
- Cargas de trabajo variables — las APIs en la nube escalan hacia arriba y hacia abajo; tus propias GPUs no.
- Menor volumen — por debajo de ~5,000 videos al mes, las APIs en la nube suelen ganar en costo total.
- Flexibilidad de múltiples modelos — el catálogo de más de 300 modelos de Atlas Cloud significa que puedes cambiar de Kling a Seedance o a Veo dentro de una sola integración.
-
Desarrollo impulsado por la comunidad vs. impulsado por el proveedor {#community-vs-vendor}
Es fácil ignorar esto al comparar APIs, pero realmente importa si estás construyendo habilidades de GitHub.
Impulsado por la comunidad (código abierto):
- Cualquiera puede enviar correcciones de errores y solicitar funciones, y ver cómo se fusionan.
- La documentación suele ser excelente porque la base de usuarios contribuye con ejemplos.
- Los cambios importantes (breaking changes) en las APIs de los modelos ocurren lentamente, con periodos de notificación pública.
- Las comunidades de ComfyUI y Hugging Face Diffusers tienen bibliotecas profundas de flujos de trabajo listos para usar, adaptadores LoRA y checkpoints ajustados.
- Los artículos de investigación se publican con código abierto y reproducible.
Impulsado por el proveedor (APIs de pago):
- La estabilidad de la API está regida por Acuerdos de Nivel de Servicio (SLAs) comerciales; los cambios importantes son menos frecuentes, pero ocurren.
- Los lanzamientos de nuevos modelos (ej. Kling 3.0 en febrero de 2026, tres días antes que Seedance 2.0) ocurren a una velocidad competitiva y a menudo sin previo aviso.
- Las mejoras en los modelos se despliegan en el lado del servidor sin que el desarrollador deba realizar ninguna acción.
- La documentación técnica se mantiene profesionalmente.
La implicación práctica para los autores de skills en GitHub: si estás escribiendo una skill que necesita permanecer estable y de bajo mantenimiento, una API en la nube con contratos de endpoint estables es más fácil de mantener que una skill vinculada a una versión específica de un modelo de código abierto. Por el contrario, si tu skill está diseñada para dar a los desarrolladores acceso a los últimos modelos de investigación sin costos de API, el ecosistema de código abierto es donde ocurre ese trabajo.
-
Caso de estudio: Agencia de redes sociales (500 videos/mes) {#case-study-1}
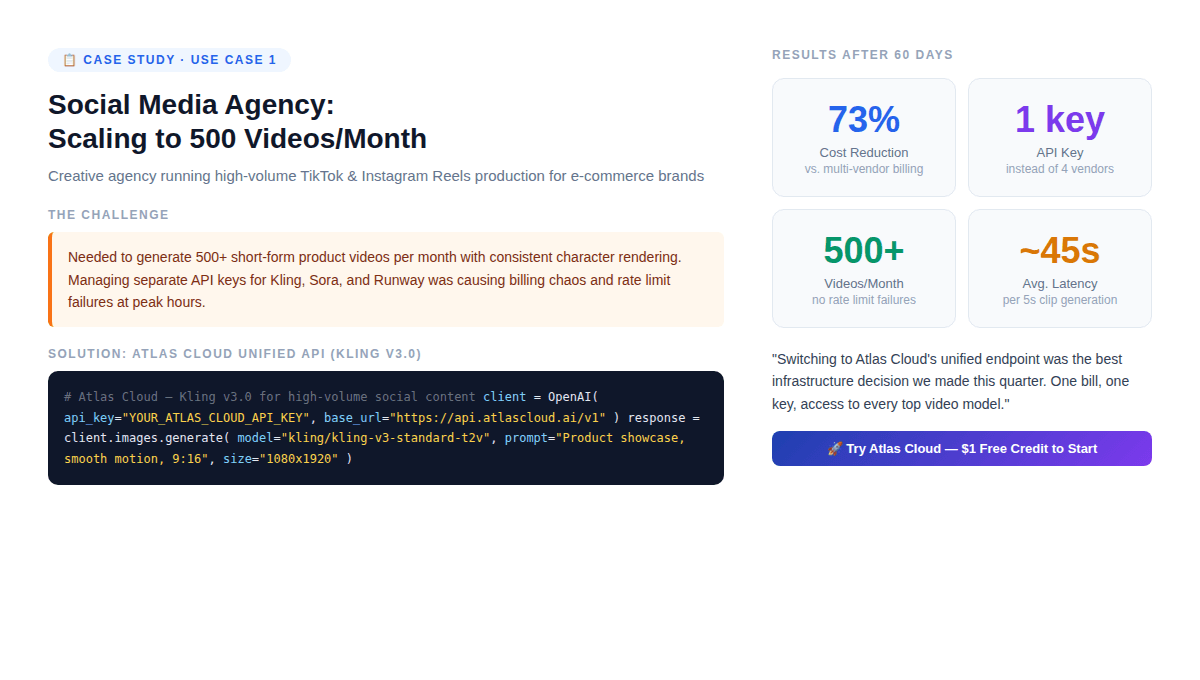
La configuración: Un taller creativo que realiza videos cortos de productos para 20 clientes de comercio electrónico. Necesitan 500 videos al mes, personajes que luzcan iguales en todos los clips, formato vertical 9:16, de 5 a 10 segundos cada uno, procesados por lotes durante horas de baja actividad.
Arquitectura inicial (antes de Atlas Cloud):
- Claves API separadas para Kling, RunwayML y Pika.
- Tres paneles de facturación, tres límites de tasa.
- Selección manual de modelos por cliente.
- Fallos en los límites de tasa durante horas pico que causaban retrasos en la entrega.
Problema creado: Cuando Kling lanzó la v3.0, la agencia tuvo que re-integrar un nuevo SDK, actualizar la facturación y probar la compatibilidad, tres veces para tres proveedores.
Solución: API unificada de Atlas Cloud con Kling v3.0 Standard.
plaintext1# Atlas Cloud — Pipeline de video para redes sociales 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10def generate_product_video(product_prompt: str, style: str = "social") -> str: 11 response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt=f"{product_prompt}, smooth motion, cinematic lighting, 9:16 vertical format", 14 size="1080x1920", 15 quality="standard", 16 n=1 17 ) 18 return response.data[0].url
Resultados después de 60 días:
- Reducción del 73% en el costo por video (factura única, sin recargos por proveedor).
- Cero fallos por límites de tasa (la infraestructura elástica de Atlas Cloud absorbió las cargas pico).
- Cambiar de Kling a Seedance para clientes específicos tomó menos de 2 minutos (cambiar un parámetro).
- El bono del 20% en el primer depósito compensó efectivamente los costos de producción del primer mes.
El hallazgo no obvio: La agencia no redujo el número de proveedores porque Kling mejorara. Lo redujeron porque gestionar múltiples relaciones con proveedores a un ritmo de 500 videos/mes tiene un costo operativo no trivial que no aparece en los precios por API.
-
Caso de estudio: Desarrollador independiente creando un SaaS de video {#case-study-2}
La configuración: Desarrollador solitario creando una herramienta de "texto a demostración de producto" para startups en etapa inicial. Necesita múltiples estilos (cinematográfico, animado, acción en vivo). Debe validar rápidamente y mantener la infraestructura por debajo de los $200/mes mientras averigua si realmente hay interés.
Decisión de arquitectura:
El desarrollador inicialmente consideró autohospedar Wan 2.2 en una instancia A100 alquilada (~$2/hora). En 100 videos de prueba durante la validación, el costo se estimó en ~$6 totales en tiempo de GPU. Parecía más barato que Atlas Cloud.
Lo que el cálculo pasó por alto:
- Configurar el pipeline de Wan 2.2 tomó 3 días (dependencias CUDA, gestión de VRAM, configuración del servidor).
- La brecha de calidad de salida de Wan 2.2 frente a Kling v3 significaba que el SaaS no podía cobrar el punto de precio previsto.
- La gestión del tiempo de actividad del servidor añadió ~2 horas/semana de mantenimiento continuo.
Arquitectura revisada con Atlas Cloud:
plaintext1# Enrutamiento flexible de modelos — cambiar según el nivel del usuario 2MODEL_MAP = { 3 "free": "kling/kling-v3-standard-t2v", # Menor costo 4 "pro": "kling/kling-v3-professional-t2v", # Mayor calidad 5 "enterprise": "bytedance/seedance-2.0" # Máximo control 6} 7 8def generate_demo_video(prompt: str, user_tier: str) -> str: 9 client = OpenAI( 10 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 11 base_url="https://api.atlascloud.ai/v1" 12 ) 13 response = client.images.generate( 14 model=MODEL_MAP[user_tier], 15 prompt=prompt, 16 n=1 17 ) 18 return response.data[0].url
Resultado: El desarrollador lanzó en 4 días en lugar de 3 semanas. El uso de Seedance 2.0 en el nivel premium justificó un precio 3 veces superior al del nivel gratuito, y la estructura de modelo escalonado se construyó con una sola clave de Atlas Cloud, no con tres integraciones de proveedores separadas.
-
La ventaja de Atlas Cloud: Por qué "Una API" es la arquitectura correcta {#atlas-cloud-advantage}

Atlas Cloud se posiciona como la primera plataforma de inferencia IA multimodal completa del mundo: una API unificada que sirve a más de 300 modelos para generación de texto, imagen, video y audio.
Para los autores de habilidades de generación de video con IA en GitHub, las ventajas específicas son:
-
API compatible con OpenAI (Reemplazo directo)
Atlas Cloud utiliza un endpoint compatible con OpenAI. Si tu skill ya se integra con el SDK de OpenAI, cambiar a Atlas Cloud para la generación de video requiere cambiar dos líneas: el api_key y la base_url. Sin nuevo SDK, sin nuevo sistema de autenticación.
-
Facturación única para flujos de trabajo multimodelo
Los flujos de trabajo de video de producción rara vez utilizan un solo modelo. Un pipeline típico podría usar:
- Seedream 5.0 para generación de imágenes (fotogramas iniciales).
- Kling v3.0 para conversión de imagen a video.
- Un LLM (Claude, GPT-4 o DeepSeek) para la optimización de prompts.
- Un modelo TTS para la narración de voz en off.
Con cuentas de proveedores separadas, esto implica cuatro relaciones de facturación, cuatro límites de tasa y cuatro puntos de integración. Con Atlas Cloud, es una clave API y una factura.
-
Transparencia de precios a nivel de modelo
Atlas Cloud publica los precios por modelo sin tarifas ocultas de cómputo. El modelo de negocio es sencillo: paga por lo que generas. Los nuevos desarrolladores reciben un bono del 20% en su primer depósito (hasta $100), y un programa de referidos ofrece créditos adicionales. Verifica siempre los precios actuales en atlascloud.ai/pricing antes de crear proyecciones financieras.
-
Cobertura de cumplimiento
Para las skills de GitHub empresariales desplegadas en entornos regulados: Atlas Cloud posee la certificación SOC I & II y cumple con HIPAA, con infraestructura en regiones de EE. UU., la UE y Asia. Esto cubre la mayoría de los requisitos de residencia de datos empresariales.
-
Integración con ComfyUI, n8n y servidor MCP
Atlas Cloud se integra de forma nativa con las herramientas más utilizadas para construir habilidades de generación de video en GitHub:
- ComfyUI — nodos personalizados para la creación visual de flujos de trabajo.
- n8n — automatización de flujos de trabajo con pasos de generación de video de Atlas Cloud.
- MCP Server — integración del Protocolo de Contexto de Modelo para marcos de trabajo de agentes de IA.
-
¿Qué stack deberías usar realmente? {#decision-guide}
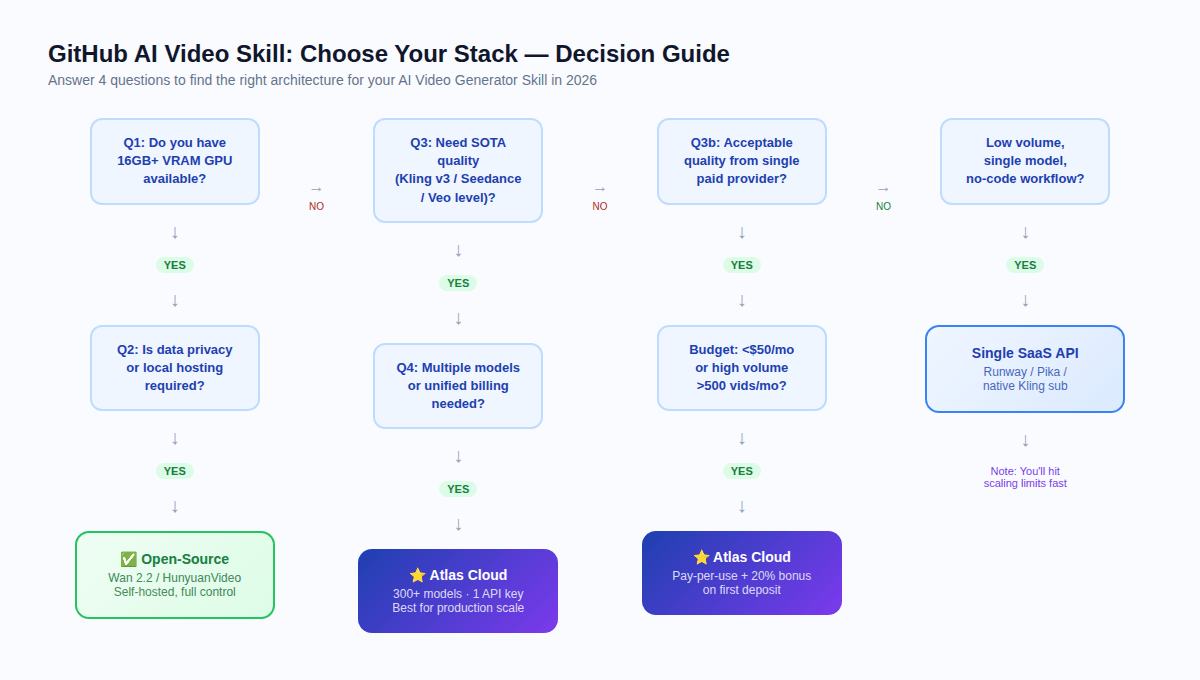
Responde a estas cuatro preguntas:
Q1: ¿Tienes disponible una GPU con más de 16GB de VRAM?
Si no → descarta el autohospedaje por completo. La API en la nube es tu único camino práctico.
Q2: ¿La regulación requiere privacidad de datos u hospedaje local?
Si sí + GPU disponible → evalúa código abierto (Wan 2.2 o HunyuanVideo según VRAM).
Si sí + no GPU → usa Atlas Cloud (cumple con HIPAA, certificado SOC) y revisa tus requisitos regulatorios específicos.
Q3: ¿Requieres calidad SOTA (nivel Kling v3, Seedance 2.0, Veo)?
Si sí → se requiere API en la nube. Los modelos de código abierto tienen una brecha de calidad significativa frente a los mejores modelos propietarios en 2026.
Si es aceptable la calidad a nivel de código abierto → Wan 2.2 autohospedado podría funcionar.
Q4: ¿Necesitas múltiples modelos o facturación unificada?
Si sí → Atlas Cloud. Gestionar tres cuentas de proveedores a escala tiene un costo operativo oculto que solo se vuelve visible a volumen de producción.
Resumen de recomendaciones por caso de uso
| Caso de uso | Stack recomendado |
| Investigación / prototipado | Código abierto (Wan 2.2, CogVideoX) |
| Agencia de redes sociales, 500+/mes | Atlas Cloud + Kling v3.0 |
| Video musical / animación | Atlas Cloud + Seedance 2.0 |
| VFX / simulación física | Atlas Cloud + Sora 2 |
| Soberanía de datos / offline | Autohospedado (HunyuanVideo, Open-Sora 2.0) |
| SaaS con calidad de modelo escalonada | Atlas Cloud (una clave, múltiples modelos) |
| Lotes de código abierto de alto volumen | Wan 2.2 autohospedado (umbral de 10,000+/mes) |
-
Preguntas frecuentes {#faq}
Q: ¿Qué es una Skill de generador de video con IA?
Un módulo de código reutilizable o capa de integración que conecta una aplicación con un backend de generación de video con IA, ya sea pesos de código abierto o una API en la nube. Formas comunes: clase Python, nodo ComfyUI, flujo de trabajo n8n, herramienta de servidor MCP.
Q: ¿Cuál es la VRAM mínima para autohospedar un modelo de video de código abierto?
8GB VRAM para Wan 2.2 1.3B (calidad aceptable para clips cortos). 16GB para CogVideoX-1.5 o Open-Sora (mejor calidad). 24GB+ para Wan 2.2 14B. 60–80GB para HunyuanVideo o el modelo completo Open-Sora 2.0.
Q: ¿Es la generación de video con IA de código abierto realmente gratuita?
Los pesos del modelo son gratuitos. La inferencia no es gratuita: requiere computación GPU. A bajo volumen (<5,000 videos/mes), las APIs en la nube como Atlas Cloud suelen ser más baratas cuando se calcula el costo total de propiedad.
Q: ¿Puedo usar Atlas Cloud para flujos de trabajo de imagen a video (i2v)?
Sí. Atlas Cloud admite variantes i2v para Kling, Seedance y Vidu. Nota: para modelos i2v, algunas variantes no aceptan un parámetro de relación de aspecto separado; la resolución de salida sigue las dimensiones de la imagen de entrada.
Q: ¿Cómo maneja Atlas Cloud la limitación de tasa?
Atlas Cloud admite patrones asíncronos/webhook. Los trabajos de generación de video se envían como tareas; tu aplicación recibe un ID de tarea y recibe una notificación cuando el renderizado está completo. Esto evita el bloqueo a escala.
Q: ¿Cuál es el mejor modelo para la consistencia de personajes entre tomas?
El sistema de Referencia Universal de Seedance 2.0 es la solución más avanzada en 2026. Permite introducir videos, imágenes y audio de referencia para mantener una apariencia y movimiento de personaje consistentes en clips generados.
Q: ¿Atlas Cloud admite ComfyUI?
Sí. Atlas Cloud tiene integración nativa con ComfyUI, así como nodos n8n y compatibilidad con servidor MCP.
Q: ¿Cómo manejan los modelos de video de código abierto las relaciones de aspecto?
Varía según el modelo. Open-Sora admite 16:9, 9:16, 1:1 y 2.39:1 mediante la bandera --aspect_ratio. Wan 2.2 y LTX-Video admiten múltiples relaciones. Para flujos de trabajo i2v, la mayoría de los modelos siguen la relación de aspecto de la imagen de entrada independientemente de los parámetros especificados.
Resumen
El panorama de 2026 se divide en dos campos, cada uno con su punto fuerte:
Código abierto tiene sentido si tienes GPUs de sobra, generas más de 10K videos al mes, los datos no pueden salir de tus servidores o necesitas hacer ajustes finos con tu propio metraje propietario.
APIs de pago son la mejor opción si necesitas la mejor calidad disponible, la velocidad importa más que el costo, generas menos de 5K videos al mes o quieres combinar múltiples modelos sin malabares con contratos de proveedores.
Atlas Cloud** une ambos mundos:** como una plataforma unificada que proporciona acceso a más de 300 modelos —incluidos los mejores modelos de código abierto mediante inferencia alojada y todos los principales modelos propietarios— a través de una única clave API compatible con OpenAI. Para la mayoría de los desarrolladores que construyen Skills de generador de video con IA en GitHub en 2026, es el camino de menor fricción desde el prototipo hasta la producción.
La información sobre precios en este artículo es indicativa y está sujeta a cambios. Verifica siempre las tarifas actuales en atlascloud.ai/pricing antes de realizar proyecciones financieras. La disponibilidad del modelo puede variar según la región.
Atlas Cloud: atlascloud.ai — Certificación SOC I & II · Cumple con HIPAA · Infraestructura en EE. UU. · UE · Asia






