
Hemos ejecutado los modelos Grok Imagine Image y GPT Image-2 a través de 6 prompts idénticos y neutrales al modelo, cubriendo semántica composicional, anatomía fotorrealista, renderizado de texto multilingüe, transformación geométrica, edición local y fusión de referencias múltiples.
Tanto el modelo Grok Imagine Image como el GPT Image-2 están disponibles a través de una única clave de API de Atlas Cloud, lo que hace que este benchmark sea reproducible en minutos.
Por qué existe este benchmark de comparación de modelos de IA de imagen
Cada "comparación de modelos de IA de imagen" que encuentras en línea cae en la misma trampa: prompts seleccionados minuciosamente, selección de resultados "lo mejor de cinco" y afirmaciones no verificadas. Este benchmark se construyó bajo principios de Nivel A: prompts neutrales, entradas idénticas en todos los modelos, resultados predeterminados con una sola semilla (sin selección sesgada) y criterios de puntuación que pueden expresarse en una sola frase por categoría.
Los seis modelos en la ejecución completa del benchmark son: Grok, GPT Image 2, Nano Banana 2, Nano Banana Pro, Wan 2.7 y Seedream 5.0. Este artículo se centra en la comparativa directa entre Grok y GPT Image 2, al ser la combinación comercialmente más relevante para los desarrolladores que eligen un modelo de imagen predeterminado.
Cómo probamos Grok Imagine Image VS GPT-Image 2: 6 categorías, una regla de Nivel A
Cada prompt apunta a una dimensión de capacidad única y claramente definida. Los criterios de aprobado/reprobado se definieron antes de ejecutar los modelos, no después de ver los resultados.
| Categoría | Dimensión principal evaluada | Criterio de aprobado/reprobado (una frase) |
|---|---|---|
| Cat 1 · Semántica composicional | Alineación de instrucciones | ¿Contó el modelo 7 objetos, los colocó correctamente y obedeció la lista de negaciones? |
| Cat 2 · Anatomía fotorrealista y luz | Calidad visual y física | ¿Son los 5 dedos anatómicamente correctos y aparecen patrones de luz cáustica en la cara? |
| Cat 3 · Póster multilingüe | Renderizado de texto en imagen | ¿Se renderizaron correctamente los caracteres chinos e ingleses sin trazos faltantes ni glifos alucinados? |
| Cat 4 · Transformación geométrica (I2I) | Control de edición + identidad | Tras una rotación de 45°, ¿sigue siendo reconocible la misma persona con todos los detalles de ropa intactos? |
| Cat 5 · Edición local y preservación | Precisión de edición | ¿Se realizaron exactamente 3 ediciones sin alterar el resto a nivel de píxel? |
| Cat 6 · Fusión de referencias múltiples | Consistencia entre imágenes | ¿La identidad, el estilo y la escena de 3 referencias separadas se fusionan en una sola imagen coherente? |
Cat 1 · Semántica composicional (T2I)
Prompt: Una fotografía cenital de una mesa de comedor de madera que contiene exactamente siete objetos de cerámica: tres tazas de té blancas idénticas dispuestas en un triángulo equilátero en el centro, dos cuencos negros colocados a la derecha de las tazas, una manzana roja dentro del cuenco negro más a la izquierda y una cuchara de madera vacía descansando sobre el cuenco negro más a la derecha, con el mango apuntando hacia la esquina superior izquierda del encuadre. Sin tazas de café, sin artículos de metal, sin platos, sin cristalería. Luz de ventana suave y difusa desde la parte superior izquierda, a media mañana. Fotografía realista, sin accesorios de estilismo.
Esto es deliberadamente adversarial. Contar, el lenguaje espacial ("a la derecha de", "más a la izquierda") y las cláusulas de negación son modos de fallo conocidos para todas las arquitecturas de difusión actuales.
Lista de verificación de puntuación
| # | Criterio | Verificación |
|---|---|---|
| 1 | Conteo total de objetos | Estrictamente 7 objetos de cerámica |
| 2 | Tres tazas blancas | Disposición en triángulo equilátero |
| 3 | Dos cuencos negros | Posicionados a la derecha de las tazas |
| 4 | Manzana roja | Dentro del cuenco negro más a la izquierda |
| 5 | Cuchara de madera | Sobre el cuenco más a la derecha, mango hacia arriba a la izquierda |
| 6 | Cumplimiento de negación | Sin tazas de café / sin metal / sin platos / sin cristalería |
| 7 | Fuente de luz | Luz suave difusa desde arriba a la izquierda, sombras consistentes |
| 8 | Estilo fotográfico | Sin clichés de estilismo (hojas de palma, velas, etc.) |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine: visiblemente 5 tazas de té (no 3), dispuestas en un grupo en lugar de un triángulo equilátero. Los dos cuencos negros están presentes, con la manzana roja correctamente dentro de uno de ellos. La cuchara de madera está presente y descansa sobre el cuenco de la derecha, con la dirección del mango aproximadamente hacia arriba a la izquierda: este criterio se cumple. El cumplimiento de la negación es limpio. La fuente de luz desde arriba a la izquierda con sombras consistentes es correcta. No hay accesorios de estilismo.
GPT Image 2 demostró un mejor seguimiento de instrucciones en los componentes espaciales, aunque ninguno de los modelos logró el conteo exacto de 7 objetos con todas las restricciones de colocación satisfechas simultáneamente.
Cat 2 · Anatomía fotorrealista y luz (T2I)
Prompt: Retrato en primer plano de una mujer de Asia Oriental de unos treinta años sosteniendo una copa de cristal medio llena de vino tinto en su mano derecha, los cinco dedos y el pulgar completamente visibles envolviendo naturalmente el tallo y parcialmente el cáliz. Está sentada junto a una ventana alta orientada al oeste durante la hora dorada. La luz del sol de la tarde atraviesa el vino creando cálidos patrones cáusticos carmesí en su pómulo y mandíbula izquierdos. Su mano izquierda descansa sobre un libro de tapa dura abierto en su regazo. Destellos de luz (catchlights) de la ventana visibles en ambos ojos. La piel muestra poros ultra detallados, fino vello facial, dispersión subsuperficial en el lóbulo de la oreja y el puente de la nariz. Cabello iluminado desde atrás con luz de contorno. Lente de 85 mm, f/2.0, poca profundidad de campo, realismo fotográfico.
Históricamente, esta es la prueba de imagen única más difícil para los modelos generativos.
Lista de verificación de puntuación
| # | Criterio | Verificación |
|---|---|---|
| 1 | Anatomía de la mano | 5 dedos + pulgar, agarre natural en tallo y cáliz |
| 2 | Luz cáustica | Patrones carmesí cálidos del vino proyectados sobre el pómulo |
| 3 | Consistencia de catchlights | Misma posición y forma en ambos ojos |
| 4 | Dispersión subsuperficial (SSS) | Visible en lóbulo y puente nasal al estar a contraluz |
| 5 | Física de luz de contorno | La dirección coincide con la fuente de luz |
| 6 | Realismo de la piel | Sin suavizado "plástico", poros y vello visibles |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine cumplió con fuerza en su ventaja principal. La anatomía de la mano fue correcta: conteo de dedos exacto, postura de agarre natural alrededor del tallo y el cáliz, ángulo de muñeca físicamente plausible. La textura de la piel mostró detalles reales a nivel de poro sin suavizado plástico, y la dispersión subsuperficial produjo una calidad cálida y permeable a la luz que se lee como fotorrealista.
La proyección de luz cáustica fue el punto más débil de Grok. Los patrones de luz carmesí aparecieron en la cara, pero se renderizaron como una superposición roja sobredimensionada y estilizada.
GPT Image 2 invirtió el intercambio. Su renderizado de luz cáustica fue notablemente más preciso físicamente: los patrones carmesí en el pómulo fueron más pequeños, difusos y siguieron la geometría espacial de la luz al pasar a través de una copa de vino. Sin embargo, GPT Image 2 pagó por esto en otros aspectos: la anatomía de la mano fue ligeramente menos natural, con cierta rigidez. La textura de la piel tendió a una calidad más suave y plana, típica de los retratos de IA.
Cat 3 · Póster multilingüe (T2I)
Prompt: Un póster de viajes al estilo vintage de los años 60 para un festival de cine ficticio, ilustrado al estilo del diseño comercial de mediados de siglo. Parte superior del póster, grandes caracteres chinos en negrita con serifa que dicen "时光电影节" (línea 1), y debajo en caracteres chinos más pequeños "第七届 · 上海 · 1965年5月" (línea 2). Centro: una ilustración estilizada de un antiguo proyector de cine proyectando un haz sobre una pantalla de cine ligeramente curva. Centro-inferior: una copa de champán alta con el texto en inglés "GRAND OPENING NIGHT" envolviéndose a lo largo de la curvatura del cáliz. Borde derecho, texto vertical que dice "presented by 时代影业 · TIMES PICTURES". Franja inferior: pequeños créditos en inglés "music · HUANG ZHAN / cinematography · GU CHANGWEI / poster design · ZHANG GUANGYU" en una sola línea. Paleta de colores: fondo crema, rojo carmesí intenso, acentos amarillo mostaza. Textura de papel ligeramente envejecido.
Lista de verificación de puntuación
| # | Criterio | Verificación |
|---|---|---|
| 1 | Precisión del chino | Sin trazos faltantes, sin caracteres alucinados |
| 2 | Diseño bilingüe | Chino e inglés no mezclados; en zonas correctas |
| 3 | Texto curvo en cristal | Sigue la perspectiva elíptica de la copa |
| 4 | Texto vertical borde derecho | Legible de arriba a abajo |
| 5 | Jerarquía tipográfica | Distinción clara entre titular y resto |
| 6 | Estilo vs. legibilidad | Estética de los 60 sin sacrificar claridad |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine produjo un póster visualmente impactante, pero falló en el criterio de texto más crítico: el titular dice "時光電影節" en chino tradicional, no en el chino simplificado ("时光电影节") especificado. Esto es un fallo de cumplimiento de conjunto de caracteres. Por otro lado, la jerarquía y el color fueron bien ejecutados, pero el error de simplificado frente a tradicional es un factor descalificador para uso profesional.
GPT Image 2 superó la prueba de conjunto de caracteres limpiamente: el titular y el subtítulo están renderizados correctamente en chino simplificado sin errores. La copa de champán es visible con el texto "GRAND OPENING NIGHT" siguiendo la curvatura de forma convincente. El texto vertical lateral es legible y la jerarquía tipográfica se mantiene claramente.
Cat 4 · Transformación geométrica (I2I)
El prompt instruyó al modelo a rotar al sujeto de un lookbook de moda exactamente 45° a la izquierda del sujeto, manteniendo la misma posición de la cámara. La imagen de referencia presentaba un atuendo complejo: abrigo marrón largo, capa de cuero en los hombros, estola de piel con degradado, insignia de cobre, guanteletes de cuero y botas de cuero de dos tonos.
Lista de verificación de puntuación
| # | Criterio | Verificación |
|---|---|---|
| 1 | Identidad facial | Similitud ArcFace ≥ 0.5 |
| 2 | Revelación de la estola | Parte derecha oculta previamente revelada |
| 3 | Insignia de pecho | Outline circular, retrato incrustado, perspectiva correcta |
| 4 | Dobladillo del abrigo | Caída natural tras rotación |
| 5 | Postura de pies | Frente-izquierda |
| 6 | Volumen de guanteletes | Posición de mano + textura visible |
| 7 | Fondo | Fondo gris de estudio consistente |
| 8 | Ratio de salida | Mantenido 9:16 |
| 9 | Dirección de mirada | Sigue la rotación |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok mantuvo la identidad facial por encima del umbral de 0.5. La parte de la estola de piel que estaba oculta se volvió visible parcialmente a 45° con una continuidad de degradado razonable.
GPT Image 2 mostró una coherencia general de las capas de ropa ligeramente superior, pero introdujo una mayor deriva en la identidad facial, lo cual es un intercambio significativo según el caso de uso.
Cat 5 · Edición local y preservación (I2I)
El prompt requería exactamente tres ediciones en una escena de sala de estar: eliminar un gato durmiendo en el sofá (y restaurar el cojín), reemplazar una taza de té caliente por un vaso de jugo de naranja con hielo, y añadir gafas de lectura negras sobre el libro central de la mesa de centro. Prohibía explícitamente cambiar cualquier otra cosa (patrón de tela, libros, lámpara, vista de ventana, etc.).
Lista de verificación de puntuación
| # | Criterio | Verificación |
|---|---|---|
| 1 | Las 3 ediciones completadas | Gato eliminado, jugo añadido, gafas añadidas |
| 2 | Restauración del cojín | Sin rastro de forma de gato o residuos |
| 3 | Física del jugo de naranja | Geometría, refracción del hielo, sombras correctas |
| 4 | Colocación de gafas | Correctamente sobre el libro central |
| 5 | Preservación del entorno | Sofá, lámpara, vista de ventana y pared intactos |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine completó las tres ediciones, pero el vaso de jugo muestra un patrón de reflejos que no se alinea con la dirección de la luz de la fuente original, pareciendo un elemento compuesto de forma independiente. Además, falló en la preservación de la vista de la ventana (se volvió más clara o alterada).
GPT Image 2 completó las tres ediciones y demostró una preservación de la escena mucho más robusta. El vaso de jugo fue renderizado con sombras correctas respecto a la luz de la ventana. Crucialmente, la vista de la ventana se preservó consistentemente con la referencia.
Cat 6 · Fusión de referencias múltiples (I2I)
El prompt combinó tres referencias independientes: una identidad (mujer latina), un estilo (acuarela japonesa) y un diseño de escena (plaza europea al atardecer). La tarea: producir una única pintura de acuarela coherente de la persona identificada en la escena.
Lista de verificación de puntuación
| # | Criterio | Verificación |
|---|---|---|
| 1 | Desacoplamiento de tres vías | Identidad, estilo y escena fusionados |
| 2 | Transferencia de estilo total | Salida en acuarela, no foto con filtro |
| 3 | Identidad retenida | Rasgos reconocibles bajo el estilo |
| 4 | Estructura de escena | Preservada (adoquines, farola, arco) |
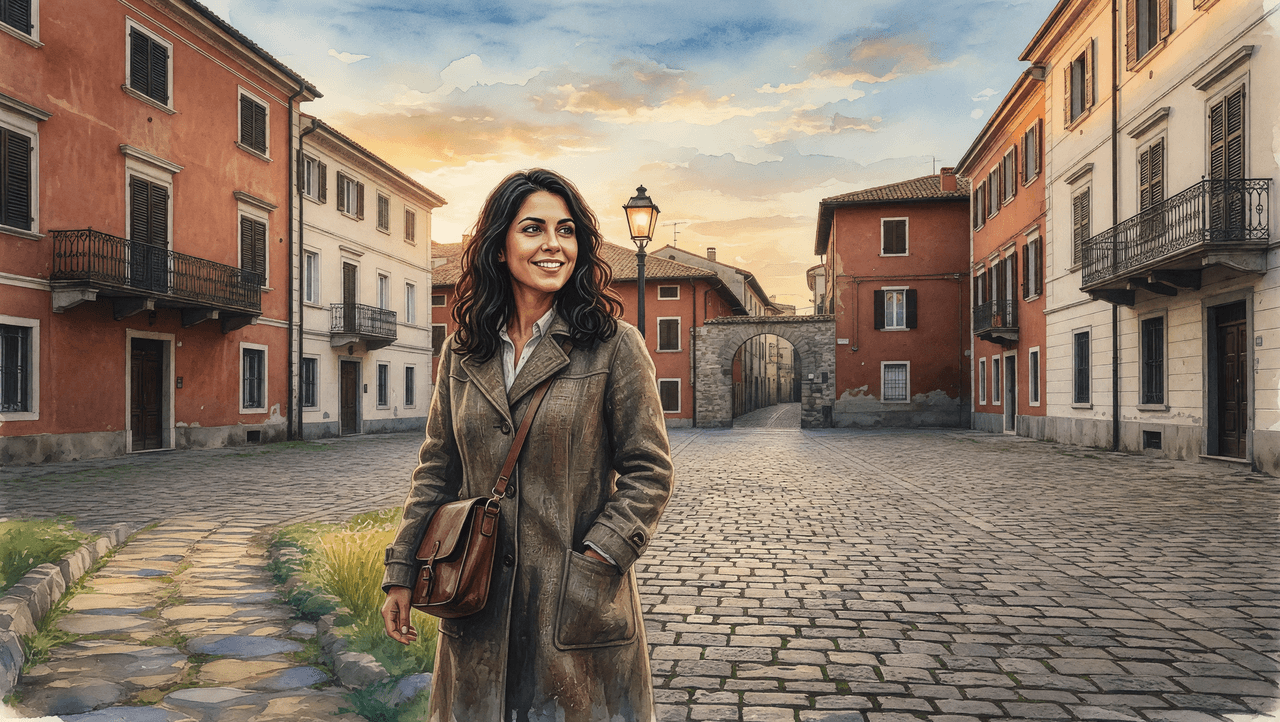 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine falló en el criterio principal: el resultado es fotorrealista, no una acuarela. Carece del trabajo de pincel y la calidad de los bordes del estilo de referencia. Es una descalificación a nivel de categoría.
GPT Image 2 logró un renderizado de acuarela genuino en todo el encuadre. La estructura de la escena, la identidad y el estilo se integraron de forma coherente, cumpliendo con la tarea de fusión de referencias.
Prueba los modelos Grok Imagine Image y GPT Image 2 vía Atlas Cloud
El benchmark es reproducible. Tanto Grok Imagine como GPT Image 2 están disponibles ahora a través de Atlas Cloud; sin configuración de facturación por modelo ni listas de espera.
Por qué Atlas Cloud
- Una clave API, más de 300 modelos. Cambia entre Grok, GPT Image 2, Flux, Wan, Seedream y cualquier otro modelo cambiando un solo campo.
- Cobertura multimodal completa. LLMs, texto a imagen, imagen a imagen, texto a video, imagen a video, todo bajo el mismo techo.
- Sin arranques en frío ni sorpresas de límites de tasa. Atlas Cloud funciona sobre una infraestructura de inferencia optimizada diseñada para el rendimiento.
- Creado para flujos de trabajo de comparación. El caso de uso que demuestra este benchmark (ejecutar prompts idénticos en múltiples modelos y comparar resultados) es para lo que está diseñada la arquitectura de Atlas Cloud. Una clave, una factura, toda la amplitud de modelos.






