
Grok Imagine Video Generation es el sistema de IA de vídeo multimodal de vanguardia de xAI, y ya ha redefinido lo que los creadores pueden esperar de una sola llamada a la API. Construido sobre el motor xAI Aurora, este modelo utiliza una red de mezcla de expertos autorregresiva. Procesa tokens de texto, imagen, vídeo y audio de forma conjunta. Este enfoque reemplaza por completo los métodos de difusión de transformadores que se encuentran en sistemas como Sora y Veo.
La principal ventaja es la sincronización natural de audio y vídeo creada durante un único paso de generación. No necesita una herramienta de doblaje adicional después.
De un vistazo: Especificaciones clave
| Característica | Detalle |
| Duración | 1–15 segundos |
| Frecuencia de fotogramas | 24 FPS |
| Resolución | 480p / 720p |
| Audio | Sincronización labial nativa, efectos de sonido, diálogos, música ambiental |
| Tabla de clasificación | n.º 1 en Artificial Analysis Video Arena (Elo 1404 ±6) |
Lanzado a finales de mayo de 2026, Grok imagine video generation debutó en lo más alto de la tabla de clasificación Image-to-Video de Artificial Analysis Video Arena, desplazando a Seedance 2.0 de ByteDance. Para cualquier flujo de trabajo digital moderno que exija vídeo rápido y listo para la producción con sonido integrado, este es el estándar a batir.
Entendiendo la arquitectura de Grok Imagine Video Generation de xAI
Para aprovechar al máximo las funciones de Grok, primero debemos mirar bajo el capó. A diferencia de los modelos de vídeo tradicionales que unen el sonido y la imagen a posteriori, Grok los trata como una entidad única. Entender este cambio fundamental explica por qué su comportamiento con los prompts y sus velocidades de renderizado difieren tan drásticamente de las alternativas del mercado.
¿Qué es Grok Imagine y cómo funciona?
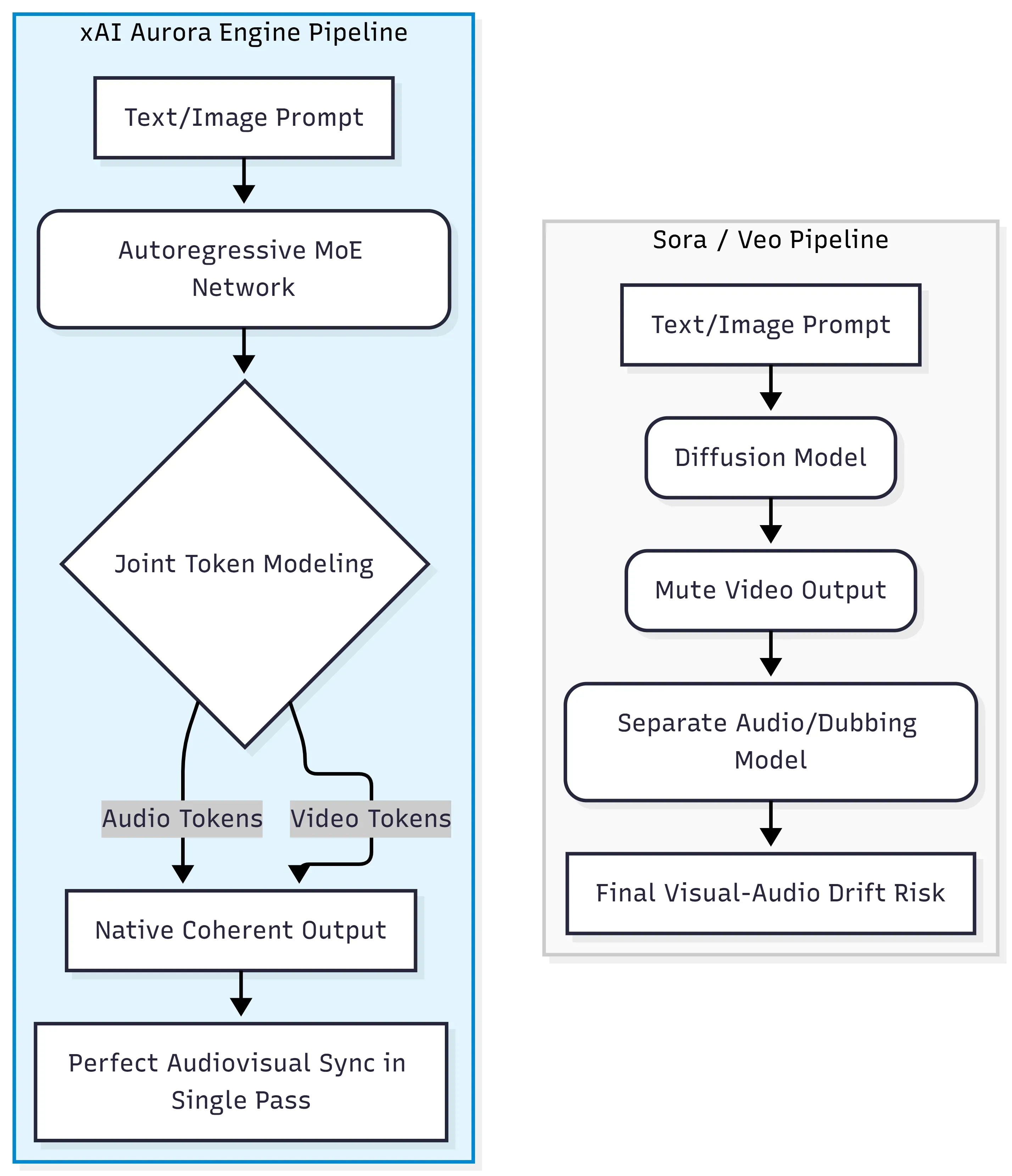
En esencia, Grok Imagine Video Generation funciona con el motor xAI Aurora, una red de mezcla de expertos (MoE) autorregresiva que predice el siguiente token a través de un flujo unificado de datos de texto, imagen, vídeo y audio. Esto es arquitectónicamente distinto del paradigma de difusión de transformadores utilizado por Sora de OpenAI y Veo de Google, donde el vídeo y el audio suelen generarse o alinearse en etapas separadas.
El alejamiento de los modelos de difusión de transformadores
Los modelos de difusión tradicionales funcionan eliminando gradualmente el ruido aleatorio hasta convertirlo en fotogramas coherentes. Destacan en calidad visual, pero tratan el audio como algo secundario, lo que requiere herramientas externas o pipelines de postproducción para añadir sonido. Aurora toma un camino completamente diferente.
| Enfoque | Arquitectura | Método de audio |
| Sora / Veo | Difusión de transformadores | Postproducción / modelo separado |
| Grok Imagine Video | MoE autorregresiva | Generación nativa de una sola pasada |
Procesamiento de tokens multimodales intercalados
En lugar de manejar las modalidades de forma secuencial, Aurora procesa datos multimodales intercalados, lo que significa que los tokens audiovisuales (diálogos, efectos de sonido, música ambiental) se generan junto con los fotogramas de vídeo en la misma pasada directa. Este modelado conjunto de tokens es precisamente lo que permite que la sincronización labial y los efectos de sonido alineados con eventos surjan del propio modelo, en lugar de sistemas de alineación separados.
Esta muestra de producción demuestra la ejecución en una sola pasada de Aurora, donde la frecuencia acústica del motor rugiendo se sincroniza perfectamente con la aceleración visual y la física de la fricción de los neumáticos.
Entrenamiento a escala: Colossus
Entrenaron este modelo en el superordenador Colossus de xAI. El enorme sitio utiliza alrededor de 555.000 GPUs NVIDIA y consume unos 2 gigavatios de energía. Es oficialmente el clúster de entrenamiento de IA en un solo sitio más grande del mundo. Esta configuración masiva es el secreto detrás de cómo Aurora mezcla cuatro tipos de medios diferentes sin reducir la calidad.
Capacidades clave: Image-to-Video, ajustes de formato y modos de calidad
Aunque Grok admite texto a vídeo, su verdadera utilidad empresarial brilla en los flujos de trabajo de Image-to-Video (I2V). Al alimentar el modelo con una imagen de referencia estática, bloqueas las características del personaje al instante, trasladando el trabajo pesado del texto descriptivo a controles mecánicos precisos. Antes de sumergirse en los modos de estilo, debe configurar las restricciones principales del pipeline.
¿Cuáles son los límites de vídeo, relaciones de aspecto y resoluciones para Grok Imagine?
Convertir imágenes en vídeos es una de las funciones más útiles de Grok Imagine. Solo tienes que subir una foto fija y escribir un prompt sencillo para describir el movimiento. El modelo anima entonces la imagen y añade audio coincidente al mismo tiempo. Puedes controlar completamente el formato final utilizando cuatro ajustes: duración, frecuencia de fotogramas, resolución y forma.
Duración y frecuencia de fotogramas
El control de duración granular le permite solicitar cualquier número entero de segundos de 1 a 15. Esto amplía el límite anterior de 10 segundos en un 50% mientras mantiene la consistencia temporal a través de la ventana más larga. Todas las salidas se renderizan a una base fija de 24 FPS.
Opciones de resolución
| Resolución | Calidad | Velocidad de procesamiento |
| 480p | Definición estándar | Más rápida (predeterminada) |
| 720p | HD (resolución 720p) | Más lenta |
Para entregas finales o distribución en redes sociales, 720p es la opción práctica. Utilice 480p para una iteración rápida y pruebas de prompts.
Variaciones de relación de aspecto
Se admiten siete variaciones de relación de aspecto:
| Relación | Mejor caso de uso |
| 16:09 | Pantalla panorámica / YouTube (predeterminado) |
| 9:16 | TikTok / Instagram Reels / Stories |
| 1:01 | Miniaturas sociales |
| 4:3 / 3:4 | Presentaciones / retratos |
| 3:2 / 2:3 | Formatos de fotografía |
Para la generación de imagen a vídeo, la salida se ajusta de forma predeterminada a la relación de aspecto nativa de la imagen de entrada, a menos que se sobrescriba.
Directrices de ingeniería de prompts para movimiento cinematográfico e identidad zero-shot
Dado que el motor xAI Aurora depende del modelado conjunto de tokens, su estrategia de creación de prompts debe cambiar. Ya no necesita gastar tokens describiendo la apariencia física de un personaje; la imagen de entrada se encarga de eso mediante la preservación de identidad zero-shot. En su lugar, su prompt debe centrarse estrictamente en el movimiento direccional, el comportamiento de la cámara y, fundamentalmente, el entorno acústico que desea que el motor genere al mismo tiempo.
¿Cómo escribir prompts para Grok Imagine Video para obtener los mejores resultados?
El principio más importante: dado que Grok Imagine admite la preservación de identidad zero-shot, el modelo traslada la apariencia del sujeto directamente desde la imagen de entrada. No es necesario volver a describir el color del pelo, la ropa o las facciones. Dedique cada palabra a la dinámica del movimiento, el entorno y la dirección de la cámara.
La sintaxis de prompt óptima
Mezcle y combine estos bloques de tokens optimizados para construir entornos cinematográficos altamente controlados:
| Acción y movimiento | Dinámica de cámara | Acústica y entorno |
| ...zancadas seguras hacia adelante, abrigo al viento | Zoom dolly se aleja lentamente | ...reflejos de neón ondulando en el pavimento mojado. SFX: Lluvia intensa chapoteando en el asfalto |
| ...corre a través de una multitud densa, mirando hacia atrás | Plano de seguimiento de ángulo bajo, ritmo rápido | ...bajo parpadeantes luces fluorescentes. SFX: Murmullo de multitud y jadeos |
| ...se da la vuelta lentamente, abriendo los ojos | Plano macro de seguimiento de izquierda a derecha | ...profundidad de campo baja, motas de polvo flotando. SFX: Bajo cinematográfico profundo |
Escenario A: Secuencia de persecución Cyberpunk, alto dinamismo, sincronización de audio pesada
Prompt:
Acción y sujeto: Un hombre corre rápido por un callejón mojado iluminado por letreros de neón.
Dinámica de cámara: La cámara se mantiene baja y lo sigue de cerca. El fondo se desenfoca y luces brillantes atraviesan la pantalla.
SFX: Música electrónica rápida mezclada con pasos en charcos y sirenas distantes. Los ritmos coinciden perfectamente con las luces de neón parpadeantes.
Objetivo de la prueba: Esta prueba comprueba qué tan bien maneja el motor Aurora las formas durante el movimiento rápido. También evalúa qué tan perfectamente sincroniza el motor los sonidos con las imágenes, como hacer coincidir los ritmos de sintetizador con las luces de neón parpadeantes.
Los aciertos (lo que Grok logró):
- Retención de identidad zero-shot: La transición desde la imagen semilla estática es impecable. La textura de cuero arrugado de la gabardina y el cabello oscuro y desordenado del personaje permanecen perfectamente estables sin ninguna transformación de identidad.
- Coherencia física: Grok maneja el sprint de alta velocidad sin duplicación de extremidades ni errores en la ropa, un punto de fallo notorio para sus rivales de difusión.
- Física de iluminación dinámica: Los reflejos de neón rosa y azul en el pavimento mojado cambian con precisión en sincronía con el ángulo de seguimiento hacia adelante de la cámara.
Las fallas (donde se atasca):
- Sesgo de tokens de audio: Aunque la sincronización de audio nativa de una sola pasada es impresionante, el motor priorizó fuertemente el token de "música synthwave", ahogando por completo los efectos de sonido localizados de "salpicaduras en charcos".
- Compresión de movimiento: A 720p, el movimiento rápido de la cámara causa un ligero desenfoque en los bordes y artefactos digitales alrededor de texto de fondo distante como "MIDNIGHT DINER".
Escenario B: Diálogo cinematográfico y oleada emocional
Prompt:
Acción y sujeto: Ella pronuncia un discurso tenso de película, susurrando "Esto termina esta noche" con total convicción.
Dinámica de cámara: La cámara se acerca lentamente a su rostro justo cuando una ráfaga de viento le revuelve el cabello.
SFX: Su voz suave coincide perfectamente con los movimientos de sus labios, mezclada con una ráfaga repentina y fuerte de viento que sopla hacia el micrófono y hace crujir su ropa.
Objetivo de la prueba: Esto sirve como una prueba de estrés definitiva para la integración de múltiples tokens del motor xAI Aurora. Obliga al modelo a ejecutar una sincronización labial nativa impecable y una mecánica muscular facial dinámica mientras calcula simultáneamente la caótica interacción física del movimiento del cabello/ropa, todo ello combinado con efectos de sonido ambientales realistas en una sola pasada de inferencia.
Los aciertos (lo que Grok logró):
- Sincronización labial nativa impecable: Las palabras pronunciadas "Esto termina esta noche" coinciden perfectamente con los movimientos de los labios y la mandíbula del personaje. Esto sucede de forma natural sin ninguna edición adicional.
- Retención de microexpresiones: Sus pecas faciales, parpadeos pequeños y mirada aguda permanecen exactamente en su lugar. Esto demuestra que el motor mantiene su identidad estable incluso durante planos macro de cerca.
- Simulación de física del viento: Justo cuando termina de hablar, una brisa repentina sopla a través de su cabello oscuro. Los mechones se mueven de forma realista y mantienen su volumen natural.
Las fallas (donde se atasca):
- Artefactos de audio: La voz generada, aunque bien sincronizada, exhibe un timbre robótico sintético ligeramente comprimido, perdiendo la textura cruda y entrecortada solicitada en el prompt.
- Micro-transformaciones temporales: Durante la secuencia de crujido del viento, se produce una mezcla de texturas menor alrededor de la oreja y la línea del cabello, donde el motor lucha ligeramente para separar el cabello en movimiento del fondo de piel estática.
Mitigación de errores: La matriz de contraejemplos
Debido a que Grok Imagine no admite un parámetro de prompt negativo dedicado en el endpoint público actual, los ingenieros de pipelines deben alejarse de las heurísticas tradicionales de prompts basados en difusión:
- ❌ El enfoque incorrecto (mentalidad de difusión): "Un hombre corriendo, muy detallado, 4k, sin desenfoque, sin distorsión, iluminación cinematográfica."
- Análisis editorial: Esto llena la ventana de contexto con tokens innecesarios e introduce frases negativas como "sin desenfoque". Una red MoE autorregresiva como Aurora puede malinterpretar estos términos como anclas semánticas, generando accidentalmente la distorsión que desea evitar.
- ✅ El enfoque correcto (mentalidad nativa de Aurora): "Zancadas hacia adelante dinámicamente. Enfoque nítido en todo momento, texturas cinematográficas prístinas, rayos divinos volumétricos atravesando el polvo."
- Análisis editorial: Esto reemplaza las exclusiones con descripciones espaciales y físicas afirmativas y deterministas, dirigiendo limpiamente el camino de predicción de tokens del motor hacia un renderizado nítido.
Consejos profesionales:
La coherencia temporal se degrada cuando los prompts introducen instrucciones espaciales contradictorias, como comandos simultáneos de zoom-in y desplazamiento a la derecha. Mantenga los movimientos de cámara singulares y direccionales. Para clips de más de 8 segundos, ancle el prompt en torno a un arco de movimiento continuo en lugar de múltiples cortes de escena.
Integración de la API de Grok Imagine Video Generation: Inicio rápido con Python y REST
La transición de la conceptualización creativa al escalado de producción requiere enviar estos parámetros a través de la puerta de enlace oficial de la API de xAI. Dependiendo de su infraestructura actual y de si prefiere un levantamiento automático en segundo plano o un bucle personalizado ligero, xAI proporciona dos rutas de implementación distintas.
¿Cómo llamo a la API de Grok Imagine para vídeo?
Existen dos rutas compatibles para llamar a la API de Grok Imagine: el cliente nativo xai_sdk (que maneja el polling automáticamente) y el enfoque REST de base_url compatible con OpenAI a través de https://api.x.ai/v1. Ambos requieren la autenticación mediante clave API configurada como variable de entorno.
Requisitos previos
Antes de escribir código, complete estos pasos:
- Genere una clave API en console.x.ai
- Expórtela en su terminal: export XAI_API_KEY="tu-clave-aqui"
- Instale el SDK: pip install xai-sdk
Ruta 1: xai_sdk nativo (Recomendado)
El cliente xai_sdk envuelve el bucle de polling asíncrono completo internamente, por lo que recibe un objeto de vídeo completado con una sola llamada al endpoint video.generate:
plaintext1import os 2import xai_sdk 3 4client = xai_sdk.Client(api_key=os.getenv("XAI_API_KEY")) 5 6# Asegúrese de pasar la imagen de referencia para flujos de trabajo de Image-to-Video 7response = client.video.generate( 8 model="grok-imagine-video", 9 image="tu imagen", # URL o base64 requerido 10 prompt="tu prompt", 11 duration=5, 12 aspect_ratio="16:9", 13 resolution="720p", 14) 15 16# CORREGIDO: Alineado con el esquema de respuesta estándar de xai_sdk 17print(f"Generación exitosa. URL del vídeo: {response.video.url}")
No se requiere polling manual. El SDK envía la solicitud, espera a que se complete y devuelve la URL.
Ruta 2: API REST estándar (bucle asíncrono personalizado)
Para entornos donde el SDK nativo no está disponible, utilice los endpoints HTTP subyacentes. Debido a que la generación de vídeo es asíncrona, debe implementar manualmente una secuencia de polling para realizar un seguimiento del estado de ejecución:
plaintext1import os 2import time 3import requests 4 5headers = { 6 "Authorization": f"Bearer {os.environ['XAI_API_KEY']}", 7 "Content-Type": "application/json", 8} 9 10payload = { 11 "model": "grok-imagine-video", 12 "image": "tu imagen", 13 "prompt": "prompt", 14 "duration": 5, 15 "aspect_ratio": "16:9", 16 "resolution": "720p" 17} 18 19# 1. Enviar la solicitud de generación de vídeo 20res = requests.post("https://api.x.ai/v1/videos/generations", headers=headers, json=payload) 21res.raise_for_status() 22request_id = res.json()["request_id"] 23 24# 2. Hacer polling al endpoint de estado hasta que esté listo 25while True: 26 poll = requests.get(f"https://api.x.ai/v1/videos/{request_id}", headers=headers) 27 data = poll.json() 28 29 if data["status"] == "done": 30 # CORREGIDO: Alineado con el retorno del esquema JSON oficial de xAI 31 print(f"¡Éxito! Recurso disponible en: {data['video']['url']}") 32 break 33 elif data["status"] in ["expired", "failed"]: 34 print(f"La generación falló con el estado: {data['status']}") 35 break 36 37 time.sleep(5) # Intervalo de limitación de tasa seguro
Referencia de estado de polling
La API devuelve uno de los cuatro valores de estado durante la generación:
| Estado | Significado |
| pending | Procesando todavía |
| done | Vídeo listo, URL disponible |
| expired | Tiempo de solicitud agotado |
| failed | Error de generación |
Haga polling cada 5 segundos para mantenerse dentro de límites de tasa razonables. El SDK usa intervalos predeterminados de 100 ms, pero 5 segundos es práctico para flujos de trabajo de producción.
Alternativa de producción: Agilización a través de la puerta de enlace API de Atlas Cloud
Para pipelines empresariales que requieren concurrencia avanzada, facturación unificada o enrutamiento de alta disponibilidad, la integración a través de una puerta de enlace gestionada de terceros como Atlas Cloud es una alternativa de producción viable. En lugar de gestionar sus propios bucles de polling asíncronos complejos y comprobaciones de estado localmente, el wrapper unificado de Atlas Cloud gestiona la puesta en cola del lado del servidor y la persistencia del estado automáticamente.
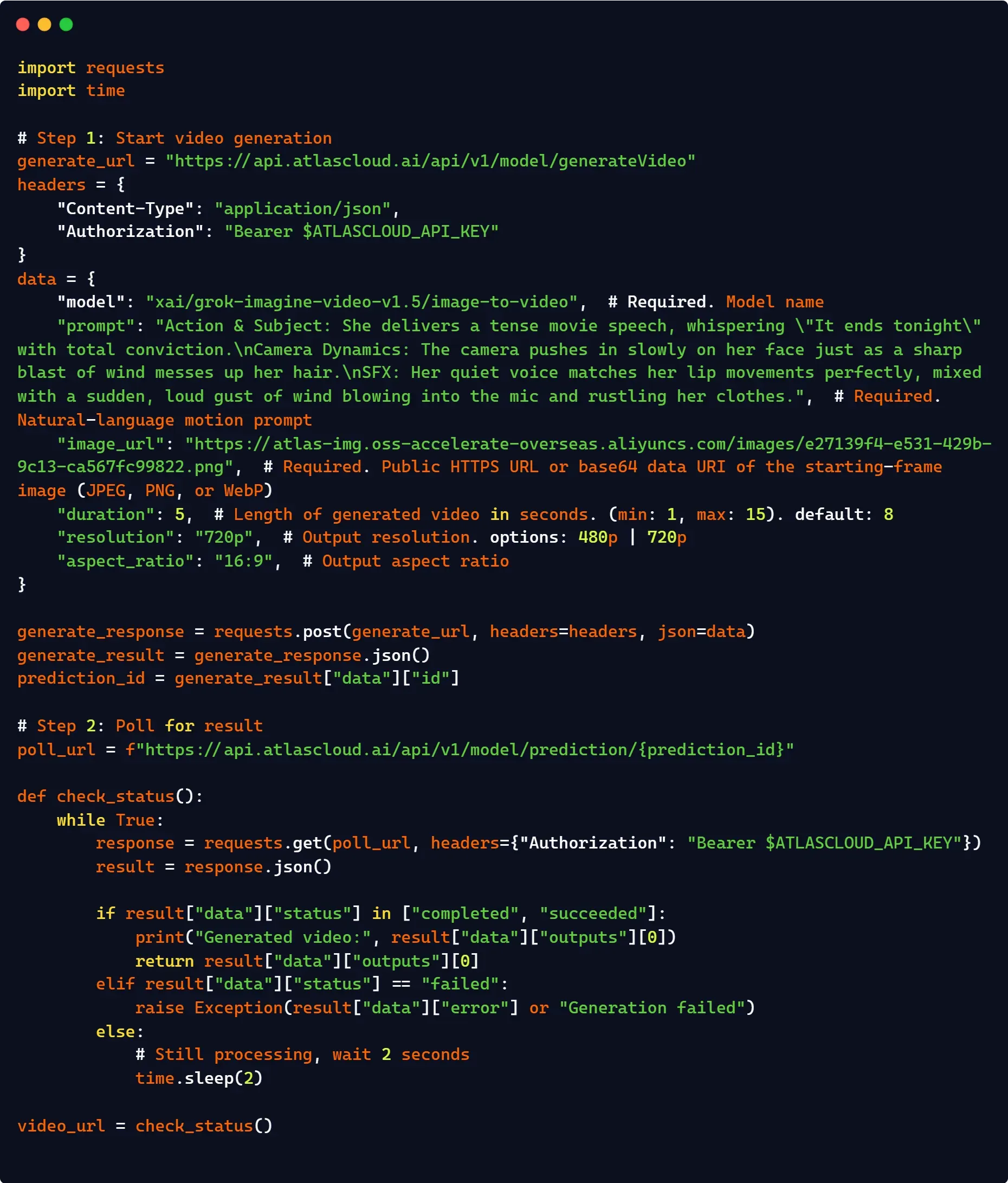
Además, ofrece un reemplazo sencillo al enrutar las solicitudes a través de una URL base unificada, minimizando los cambios de código y desbloqueando límites de tasa de nivel empresarial que normalmente superan los umbrales de nivel público estándar de xAI.
Rendimiento de referencia: coste, latencia y comparaciones con la competencia
Las salidas audiovisuales de alta fidelidad solo son viables para pipelines empresariales si se alinean con presupuestos informáticos estrictos y requisitos de latencia. Para ver dónde se sitúa Grok en el mercado, las pruebas de estrés de terceros mapean sus velocidades de generación y costes por segundo directamente frente a gigantes establecidos de la industria.
¿Es Grok Imagine Video más rápido y barato que otras herramientas de vídeo por IA?
En pruebas comparativas independientes, la respuesta es mayoritariamente sí. Grok Imagine Video debutó en el primer puesto de la tabla de clasificación de Image-to-Video de Artificial Analysis Video Arena con una puntuación Elo de 1404 ±6, desplazando a Seedance 2.0 de ByteDance de la posición superior.
Comparación frente a frente con la competencia
| Modelo | Desarrollador | Duración máx. | Resolución máx. | Audio nativo |
| Grok Imagine V1.5 | xAI | 15s | 720p | Sí |
| Seedance 2.0 comparación | ByteDance | 4–12s | 720p | Sí |
| Veo 3.1 | 8s | 1080p | Sí | |
| Sora 2 | OpenAI | 20s | 1080p | Sí |
| Runway Gen-4 | Runway | 10s | 1080p | Parcial |
Velocidad de inferencia y latencia
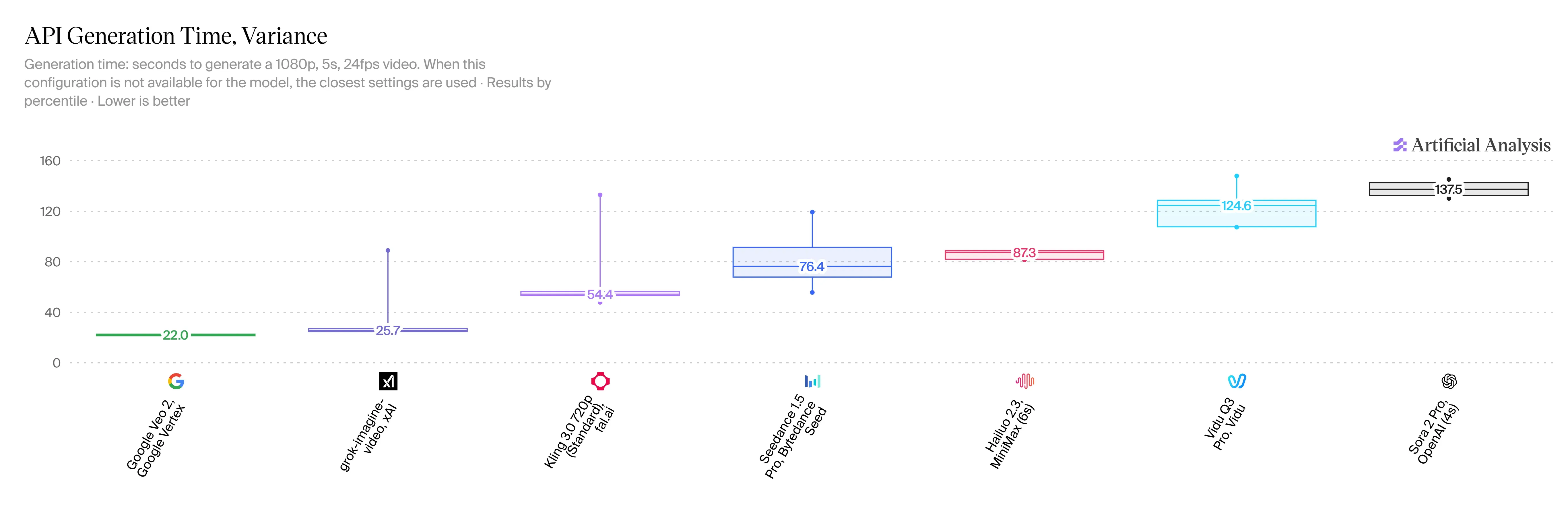
La V1.5 es increíblemente rápida, y esa es una gran victoria para los usuarios. Puede crear un clip de 5 segundos a 720p en solo 20 a 30 segundos. Comparado con HappyHorse 2.3, eso reduce su tiempo de espera de 2 a 3 veces. Todavía no tenemos estadísticas de velocidad oficiales para Veo 3.1, pero la gente en línea dice que tarda más de un minuto completo para un clip similar.
Estructura de precios
La estructura de precios por segundo a través de puertas de enlace de API de terceros como Atlas Cloud comienza en aproximadamente USD0.096 por segundo de vídeo generado. A ese ritmo, un clip de 10 segundos cuesta aproximadamente USD0.96, lo que hace que la experimentación rentable sea genuinamente accesible para creadores independientes y equipos pequeños que iteran sobre múltiples variantes de prompts antes de comprometerse con una ejecución de producción final.
Seguridad empresarial, privacidad de datos y cumplimiento de contenido
El despliegue de activos multimedia propietarios o contenido orientado al cliente en cualquier sistema de IA basado en la nube introduce cuestiones legales necesarias. Para las casas de producción comercial, saber dónde aterrizan sus entradas generativas, y cómo están aisladas, es tan importante como la calidad de la salida final.
¿Utiliza xAI mis datos de API o los vídeos generados para entrenar sus modelos?
Esta es una de las preguntas más comunes de los adoptantes empresariales, y merece una respuesta directa. Según los términos para desarrolladores de xAI, las entradas y salidas de la API procesadas a través de la plataforma están sujetas a una revisión de la política de contenido para el filtrado de seguridad, pero se manejan bajo principios de privacidad de datos por diseño que separan los datos de inferencia de los pipelines de entrenamiento públicos.
Resumen del marco de cumplimiento
Los proveedores de pasarelas API de terceros que ofrecen acceso a Grok Imagine, como Atlas Cloud, publican sus propias certificaciones de cumplimiento independientes:
| Estándar de cumplimiento | Estado |
| Cumplimiento SOC 2 Tipo II | Certificado |
| Residencia de datos GDPR | Alineado |
| HIPAA | Elegible |
Límites de privacidad clave para usuarios profesionales
Los profesionales que evalúen Grok Imagine para flujos de trabajo comerciales deben tener en cuenta lo siguiente:
- Las salidas de vídeo generadas se devuelven como URL alojadas temporalmente y no se almacenan de forma predeterminada permanentemente.
- La revisión de la política de contenido filtra las salidas para detectar violaciones de seguridad antes de la entrega, pero no retiene el contenido para su reutilización.
- Las exclusiones de entrenamiento de modelos se aplican a los usuarios de la API: sus prompts y medios generados no se introducen en los bucles de entrenamiento de modelos públicos.
- La alineación con la residencia de datos GDPR significa que las prácticas de manejo de datos cumplen con los estándares de procesamiento europeos para equipos que operan en diferentes jurisdicciones.
Para implementaciones empresariales que requieren acuerdos de procesamiento de datos formales o políticas de retención personalizadas, el siguiente paso apropiado es el compromiso directo con el equipo empresarial de xAI a través de x.ai.






