Los límites diarios de generación de imágenes de Grok xAI varían significativamente según el plan, y tras los enormes recortes de cuotas a mediados de 2026, son más estrictos que nunca.
| Nivel de suscripción | Límites diarios reales de imágenes | Límites de renderizado de video | Ventana de reinicio de cuota |
|---|---|---|---|
| Grok Free | ❌ Completamente desactivado (0/día) | ❌ Completamente desactivado | N/A (Requiere suscripción) |
| SuperGrok Lite ($10/mes) | Muy restringido (~5–7 imágenes/día) | ⚠️ Solo prueba (Volumen insignificante) | Ciclo fijo y rígido de 24 horas |
| SuperGrok ($30/mes) | ~10–15 imágenes / día (mucho menor en Modo Agente/Canvas) | ~15–20 videos (480p como alternativa); Elite 720p HD limitado a ~0–3/día | Ventana móvil compleja de 6h 15m a 24h (con temporizador en vivo) |
| SuperGrok Heavy | Relativamente generoso (cola prioritaria) | ~30–50 videos / día (limitado dinámicamente por la carga del servidor) | Ventana fluida móvil de 12 horas |
Como se muestra arriba, el acceso se prioriza estrictamente. El estado actual de la función de generación de video de grok xai 2026 resalta una clara división operativa: mientras que las herramientas de imagen se han estabilizado, el renderizado de video sigue siendo altamente volátil. Encontrarse con un límite de video de grok es ahora un comportamiento común, ya que el renderizado se reduce frecuentemente a 480p para proteger las funcionalidades básicas del LLM durante las horas pico. Además, xAI Grok NO permite a los usuarios gratuitos generar imágenes o videos. El nivel gratuito en X.com está estrictamente limitado a consultas basadas en texto usando modelos más ligeros como Grok 4 Mini. El acceso a la suite Grok Imagine sigue siendo una función exclusiva para suscriptores de pago.
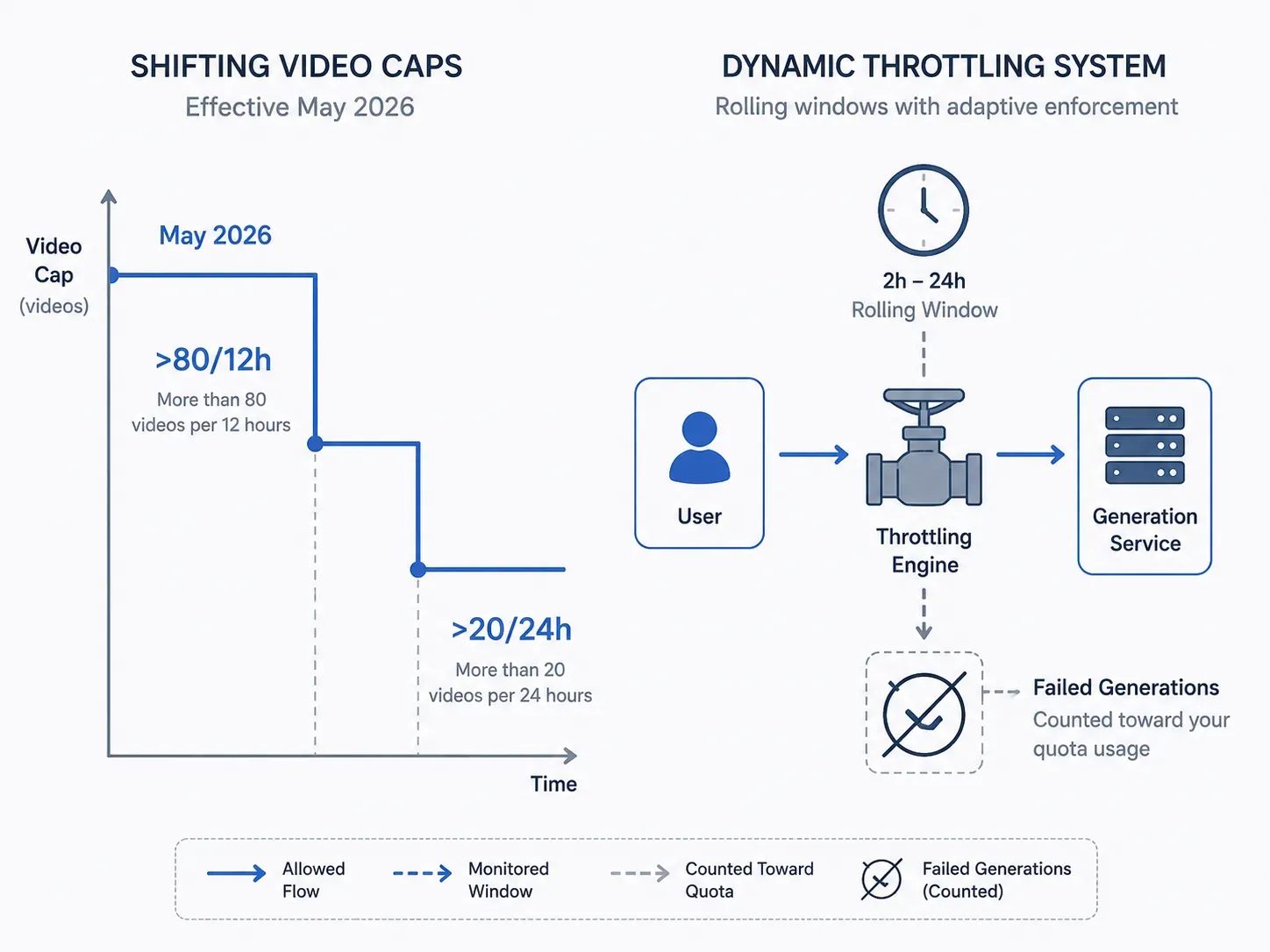
Lo que hace que los límites de imágenes de xAI sean especialmente frustrantes es lo silenciosamente que cambian: un correo de soporte de mayo de 2026 revisó los límites de video de SuperGrok Heavy a ">80 por cada 12 horas" (bajando de cifras anteriores), mientras que SuperGrok estándar cayó a ">20 videos" por cada 24 horas.
Los límites de Grok Imagine tampoco se basan puramente en cuotas. xAI aplica un "algoritmo de uso justo" que limita a los usuarios intensivos durante las horas pico, con ventanas de reinicio que van de 2 a 24 horas según la función; y algo fundamental: las generaciones fallidas siguen contando para tu límite.
La conclusión es que ningún límite del nivel SuperGrok es realmente estático. A medida que xAI escala su infraestructura en el clúster de GPU Colossus, las cuotas de procesamiento cambian constantemente. De hecho, muchos usuarios que monitorean el estado de la función de generación de video de grok xai 2026 han descubierto que las recientes actualizaciones multimodales afectan directamente la capacidad estándar de texto a imagen, convirtiendo los límites diarios estrictos en una necesidad operativa para la plataforma.
El límite diario oficial de generación de imágenes de Grok xAI según el nivel de suscripción
Aunque SuperGrok anuncia oficialmente 200 imágenes por día, el rendimiento real no siempre coincide con esa cifra. Cada prompt puede activar entre 12 y 20 renderizados internos que el usuario no puede controlar directamente, lo que significa que el resultado efectivo puede exceder las 200 imágenes, pero la cuota basada en prompts se alcanza más rápido de lo que la mayoría espera.
Niveles y umbrales oficiales de límites de tasa de la API de xAI
De acuerdo con la documentación oficial para desarrolladores de xAI, los límites de tasa de la API se rigen por dos dimensiones estrictas: Solicitudes por minuto (RPM) y Tokens por minuto (TPM). En lugar de una suscripción fija, tu concurrencia programática escala dinámicamente a través de 5 niveles de infraestructura basados totalmente en el gasto acumulado de tu equipo:
| Nivel de API | Umbral de gasto acumulado | Controles de límite de tokens y solicitudes | Acceso a imágenes (API de Grok Imagine) |
|---|---|---|---|
| Nivel 0 (Predeterminado) | $0 (Nivel de sandbox gratuito) | Límites básicos restrictivos | Solo pruebas de ráfagas restringidas |
| Nivel 1 | $50 | Escalamiento de RPM/TPM de nivel medio | Desbloquea tuberías de baja concurrencia |
| Nivel 2 | $250 | Rendimiento de tokens mejorado | Renderizado automatizado estándar |
| Nivel 3 | $1,000 | Límites operativos de alto volumen | Proyectos de equipo multihilo |
| Nivel 4 | $5,000 | Ancho de banda estándar máximo | Listo para producción empresarial |
| Enterprise | Disponible bajo solicitud personalizada | Escalamiento de rendimiento provisionado | Requiere integración de ventas directas |
Nota: La calificación de gasto se rastrea mediante compras de crédito prepago acumuladas o facturas cumplidas. Una vez que un equipo desbloquea un nivel superior de API, la calificación sigue siendo permanente; los niveles nunca bajan.
Cómo funciona el calendario de reinicio
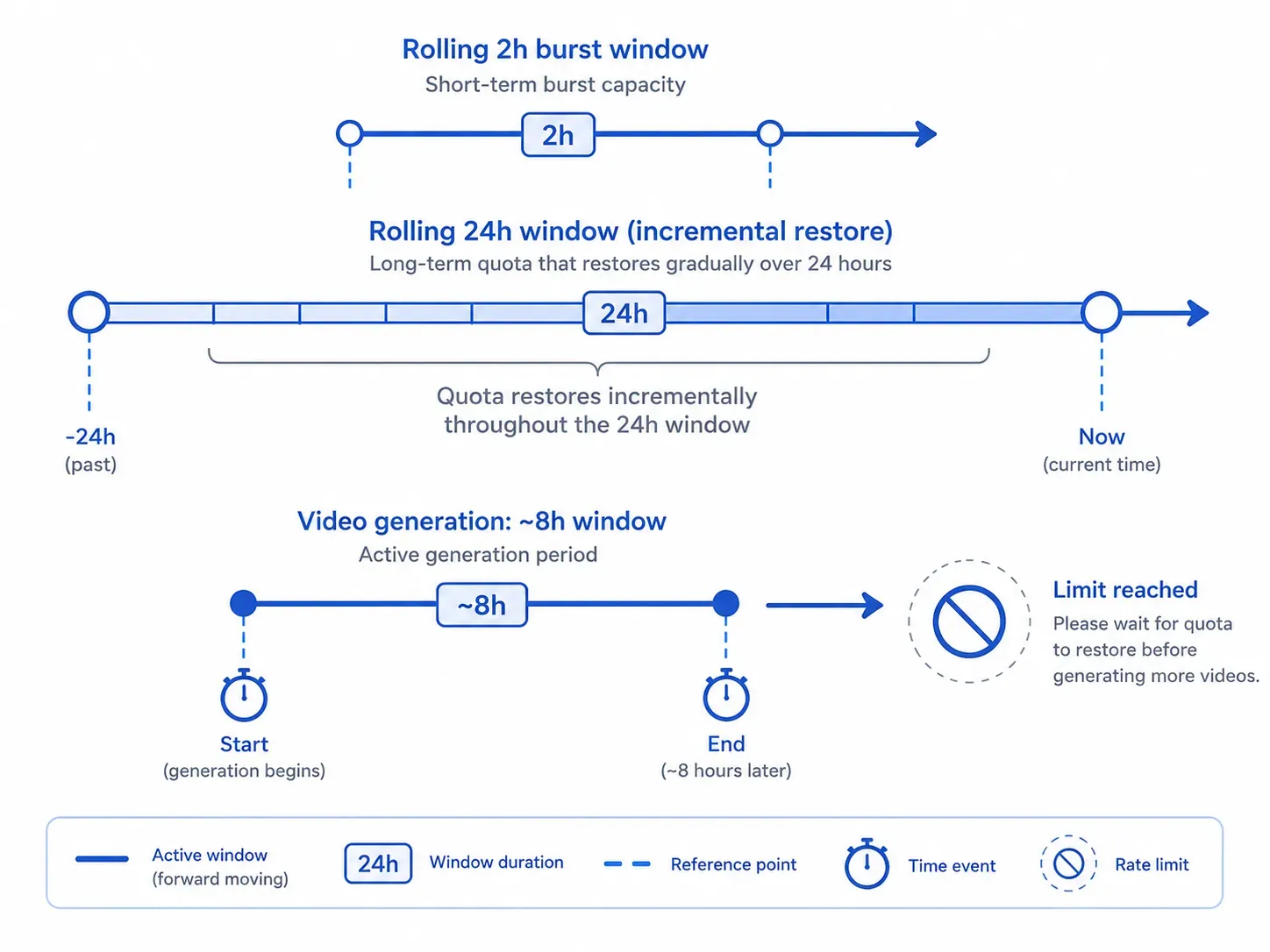
La cuota de generación de imágenes de SuperGrok funciona con ventanas móviles de 24 horas en lugar de reinicios fijos a medianoche, con una ventana móvil secundaria de 2 horas que rige la capacidad de ráfaga más corta. Esto significa que la cuota no se actualiza de repente a una hora establecida, sino que se restaura gradualmente según cuándo generaste por última vez.
Para la generación de imágenes estándar de Grok Imagine, el patrón de reinicio reportado comúnmente sigue una ventana móvil de 2 horas. Sin embargo, al observar el estado actual de la función de generación de video de grok xai 2026, esa ventana de infraestructura se extiende cerca de 8 horas debido a las altas cargas centrales.
El costo oculto del renderizado multivuelta (Contabilidad de TPM)
Un detalle crucial que a menudo pasan por alto los desarrolladores es qué cuenta realmente para tus límites. Bajo el tiempo de ejecución del desarrollador de xAI, la generación de imágenes a través de grok-imagine-image-quality no cuenta como una consulta de prompt 1 a 1. El presupuesto oficial de TPM agrega estrictamente:
- Tokens de prompt (incluyendo texto sin procesar y URLs de imágenes de entrada para ediciones).
- Tokens de razonamiento interno (muy activos durante el Modo Agente multivuelta o sesiones de Canvas).
- Activos de finalización de sub-renderizado (donde un solo prompt a menudo genera de 12 a 20 iteraciones internas de imagen).
Debido a que cada modificación de diseño, expansión de fondo o cambio de resolución a 2K (equivalente a $0.07 por token de salida) consume agresivamente tu límite de TPM concurrente, los desarrolladores en niveles de API más bajos (Nivel 0 a Nivel 2) se encuentran frecuentemente con errores HTTP 429 (Too Many Requests), incluso cuando no han excedido su presupuesto financiero mensual general.
¿Cuenta una generación fallida?
Sí. xAI ha confirmado que el consumo de cuota por generaciones fallidas se aplica; las generaciones moderadas o fallidas aún cuentan para el límite. Además, una vez que se alcanza un límite de video, la calidad de salida puede bajar de 720p a 480p.
El consumo de tokens: Declarado vs. Realidad
Muchos usuarios hacen referencia a los primeros anuncios de xAI que indicaban un techo de alto volumen de aproximadamente 200 generaciones de imágenes por día para los planes de primer nivel. Sin embargo, los flujos de trabajo de creación del mundo real rara vez ofrecen esa cifra teórica.
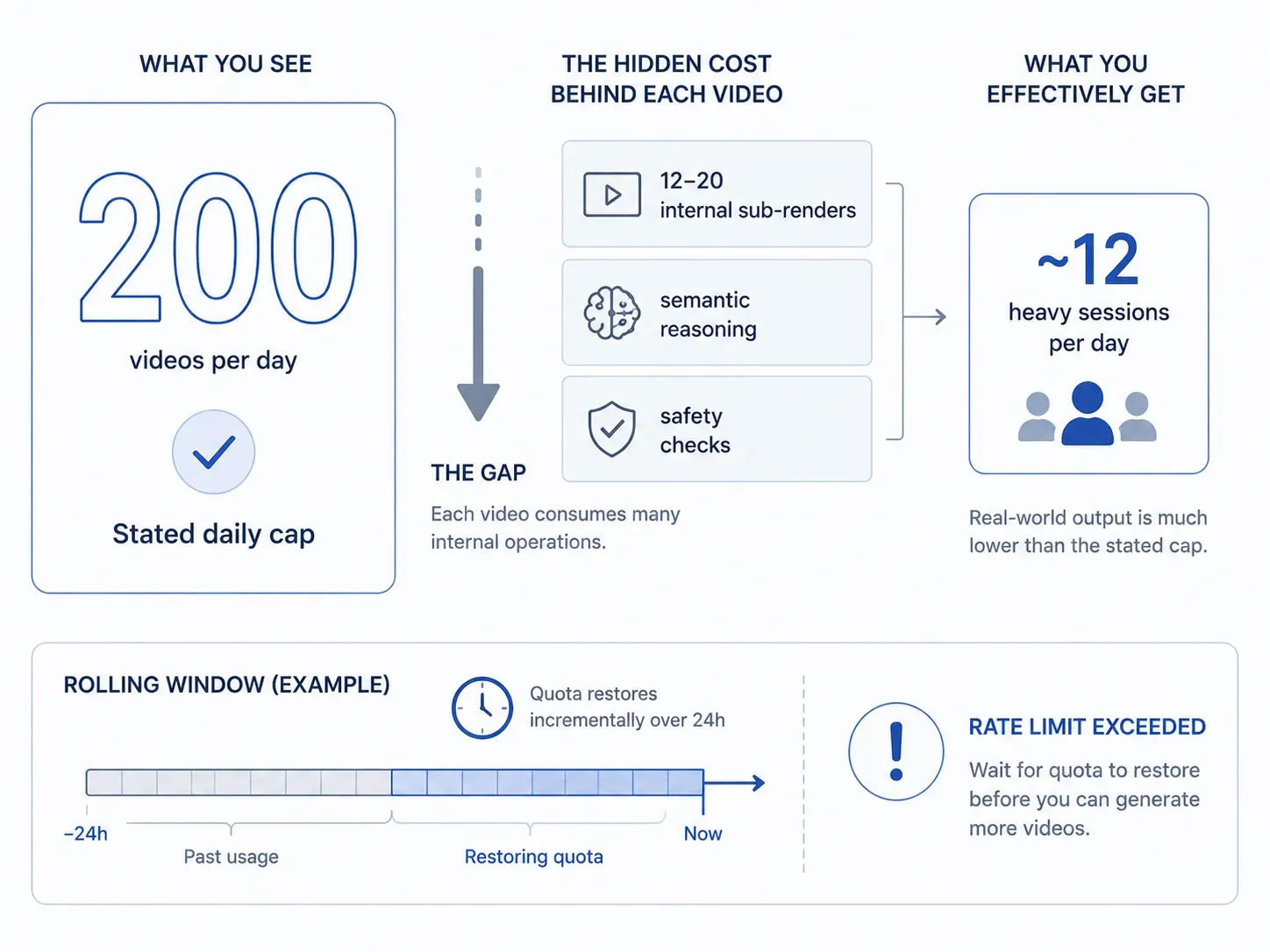
Esta brecha existe porque los límites de Grok Imagine no se calculan mediante simples conteos de prompts superficiales. Con la introducción en 2026 del Modo Agente multivuelta y el espacio de trabajo colaborativo Canvas, un solo prompt de texto ya no genera solo una salida estática aislada. En cambio, el sistema backend a menudo ejecuta de 12 a 20 sub-renderizados internos, pasos de razonamiento semántico y verificaciones de alineación de seguridad para compilar la imagen final.
💡 La realidad empresarial: Debido a que cada solicitud de modificación o re-prompt dinámico quema tokens computacionales masivos detrás de escena, la asignación diaria efectiva se alcanza mucho más rápido de lo esperado. Para los creadores que utilizan la plataforma a escala, estos ciclos técnicos ocultos son los que hacen que las cuentas estándar alcancen el muro de "límite de tasa excedido" después de solo una docena de sesiones de prompts intensivas e iterativas.
La conclusión clave: ningún nivel opera con un ciclo de reinicio de 24 horas limpio. Las ventanas móviles significan que tu límite efectivo depende en gran medida de cuándo y qué tan rápido generas, no solo de cuántas.
¿Por qué cambia o fluctúa el límite diario de generación de imágenes de Grok xAI?
Si has alcanzado un error de límite de tasa excedido después de generar solo 10–20 imágenes (muy por debajo de la asignación declarada de tu nivel), no has cometido ningún error. El límite mismo se movió.
La infraestructura detrás de la inestabilidad
Grok depende de la capacidad del enorme clúster de servidores Colossus de xAI y de la infraestructura en la nube adicional, que debe manejar simultáneamente consultas de chat regulares, generación de imágenes intensiva en computación, razonamiento en tiempo real y cargas de trabajo de entrenamiento activas. Cuando las integraciones externas o los lanzamientos de modelos internos consumen importantes recursos de GPU, las interacciones estándar de los usuarios pagan el precio.
La expansión agresiva de xAI agrava aún más el problema: el entrenamiento continuo de modelos junto con la posible compartición de computación para proyectos como Cursor puede reducir temporalmente los recursos disponibles para Grok, haciendo que la capacidad de generación disponible sea impredecible incluso en los niveles de pago.
La alternativa empresarial: Para creadores y desarrolladores que no pueden permitirse limitaciones a mitad de sesión o tiempos de inactividad impredecibles, cambiar de una suscripción de consumo volátil a endpoints de API dedicados se está convirtiendo en el estándar de la industria. Utilizar plataformas de desarrollo especializadas te permite evitar las colas de la web de xAI por completo, asegurando un tiempo de actividad estable y un costo por renderizado predecible al aprovechar la infraestructura en la nube de Modelos Grok Imagine sin restricciones.

Qué crea límites "fluidos" en la práctica
Los límites de generación fluidos no provienen de una sola causa. Varios factores superpuestos contribuyen:
| Causa | Efecto en tu límite |
|---|---|
| Carga de API concurrente en horas pico | El límite efectivo cae por debajo de la cuota declarada |
| Reasignación de GPU al procesamiento de video | La generación de imágenes se limita a mitad de la sesión |
| Automatización de bucles de respuesta de la plataforma X | El presupuesto compartido de la API se consume más rápido |
| Lanzamiento de nuevo modelo o ejecuciones de entrenamiento | Recursos de Colossus reducidos temporalmente |
| Uso rápido de ráfagas en una ventana corta | Límite de tasa a corto plazo activado independientemente |
El estado de la función de generación de video de grok xai 2026 suele ser un síntoma directo del macroentorno en 2026. Siempre que xAI lanza una actualización pública o prueba bucles de video de mayor frecuencia de cuadros en la plataforma X, se reasignan bloques masivos de GPU para manejar la carga de renderizado de video.
Ventanas móviles vs. reinicios fijos: ¿Por qué la confusión?
La mayoría de los usuarios asume que su cuota se reinicia a la medianoche. No es así. El sistema opera con ventanas móviles de 24 horas, con una ventana secundaria móvil de dos horas que rige la capacidad de ráfaga. Esto significa que un usuario que generó 40 imágenes entre las 9 y las 11 PM no recuperará toda esa cuota a la medianoche; la recuperará gradualmente a lo largo del día siguiente.
¿Por qué recibes un límite de tasa cuando no has usado Grok hoy?
Puede ser increíblemente frustrante ver un error de "límite de tasa excedido" en tu primer prompt del día. Según declaraciones de personas cercanas a xAI, esto sucede porque el sistema de limitación dinámica de Grok se adapta a la demanda global del servidor en tiempo real. Si el clúster Colossus de xAI está bajo una carga pesada debido al entrenamiento o tendencias virales en Twitter/X, tu cola local se ve afectada, independientemente de tu historial de uso personal.
Esto significa que, bajo una carga de servidor global pesada, la interfaz web podría reducir silenciosamente la fidelidad de tu imagen o bloquearte por completo para ahorrar ancho de banda. Si necesitas una salida consistente y perfecta píxel a píxel, enrutar tus prompts a través de un agregador de API garantiza un acceso sin restricciones a la resolución máxima.
Diferencias entre la generación de imágenes y los límites de renderizado de video
La generación de imágenes y el renderizado de video en Grok Imagine se rigen por sistemas de cuotas completamente separados, y confundirlos es una de las razones más comunes por las que los usuarios agotan su asignación más rápido de lo esperado.
Estado de la función de generación de video de grok xai 2026
La razón por la que las cuotas de imágenes de xAI se sienten como un objetivo móvil se debe en gran parte al estado actual de la función generación de video de grok xai en 2026. La generación de video requiere exponencialmente más tokens de computación que la difusión de imágenes estáticas. Debido a que ambos tipos de medios extraen energía de la misma arquitectura de clúster, los picos de renderizado de video activan directamente las temidas advertencias de "límite de tasa excedido" en tu panel de imágenes.
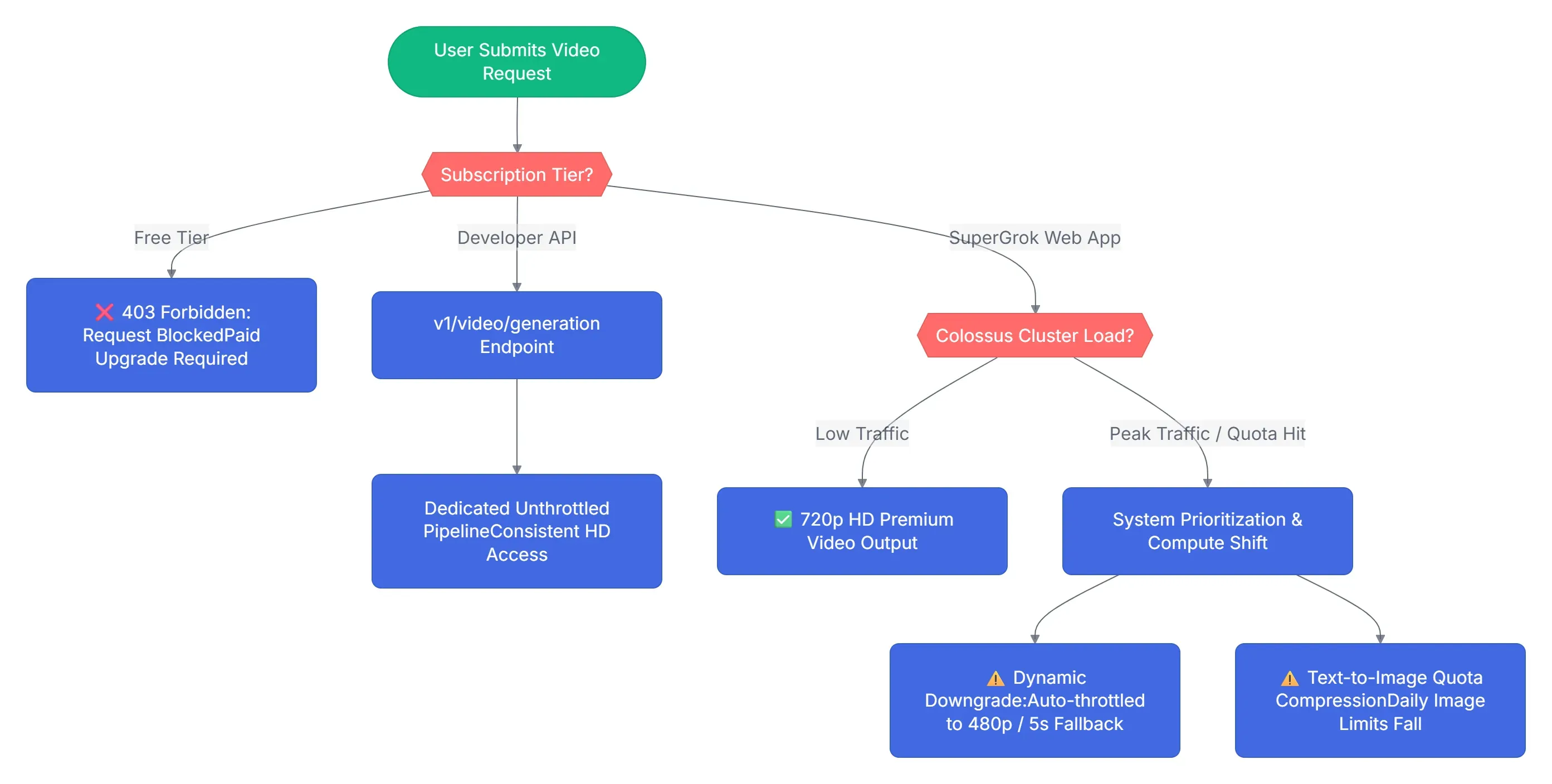
El ecosistema de funciones se divide en dos pistas operativas a mediados de 2026:
- Acceso a la aplicación web SuperGrok: Funcional pero altamente limitado. Los usuarios tienen asignado un tope suave de generaciones de video premium de alta definición por ventana móvil de 24 horas.
- El mecanismo de limitación: Para gestionar la tensión del servidor sin arrojar errores duros, xAI confía en un sistema automatizado de degradación de calidad. El sistema limita la salida de video a clips de 5 segundos a una resolución máxima de 480p una vez que se agota tu asignación prioritaria.
- Acceso a la API para desarrolladores (v1/video/generation): Disponible a través de acceso público de pago por uso. Aunque los niveles maduros de la API
grok-imagineestán ampliamente disponibles, los desarrolladores también pueden acceder a endpoints de video nativos mediante pago por uso, aunque esto sigue sujeto a una limitación de tasa dinámica basada en la priorización intensa del clúster de GPU.
El cuello de botella arquitectónico: Crear solo un video de 5 segundos a 30fps requiere mucha potencia. De hecho, utiliza aproximadamente el mismo ancho de banda de computación que renderizar 40 imágenes separadas de alta resolución. Cuando xAI experimenta tráfico pico en sus funciones de video, los límites de imágenes en todos los planes de suscripción más bajos se comprimen temporalmente.
Cómo difieren las dos cuotas
Mientras que los límites de imágenes están fuertemente influenciados por límites algorítmicos suaves y la limitación dinámica de tokens, los límites de renderizado de video operan con puertas rígidas de alta computación.
| Métrica arquitectónica | Sistema de cuota de Texto a Imagen | Sistema de cuota de Renderizado de Video |
|---|---|---|
| Tipo de asignación | Topes suaves basados en tokens | Puertas rígidas estrictas |
| Techo diario típico (SuperGrok) | ~10–15 ciclos de prompt premium | ~15–20 clips totales (Altamente volátil) |
| Comportamiento ante el límite | Error de bloqueo con temporizador | Degradación dinámica: 720p a 480p |
| Prompts fallidos/moderados | Cuentan contra tu límite | Cuentan contra tu límite |
| Consumidor principal | Sub-renderizados internos y tokens de razonamiento | Consumo de tokens de ancho de banda por segundo |
¿Generar un video drena tu cuota de texto a imagen?
Sí, y aquí es donde muchos usuarios son tomados por sorpresa. El límite oficial agrupa la cuota de texto a imagen vs. la cuota de video en el nivel estándar SuperGrok, lo que significa que se comparten 200 generaciones de imagen o video entre ambos formatos por cada 24 horas. Dado que los renderizados de video de 720p consumen significativamente más cuota que las imágenes estáticas, una breve sesión de video puede acabar con la mayor parte de tu asignación diaria.
Compensación entre calidad y cantidad
Una vez que un usuario alcanza su tope de video de 720p, el sistema degrada automáticamente la salida a 480p en lugar de bloquear la generación por completo; una alternativa suave que preserva el acceso pero reduce visiblemente la calidad.
Consejos profesionales para maximizar tu cuota de generación de imágenes de xAI
Trabajar de manera más inteligente con Grok Imagine comienza por entender cuándo y cómo se gasta la cuota, y luego ajustar tu flujo de trabajo en consecuencia.
✅ Lista de verificación para evitar límites de tasa
- Genera durante horas de poca actividad: Reduce la exposición a los tiempos de demanda pico del servidor.
- Usa grok.com directamente: A menudo está menos congestionado que las respuestas de la plataforma X.
- Prompts por lotes: Un prompt detallado ahorra más cuota que múltiples prompts cortos.
- Desactiva la generación automática de video: Evita que la cuota de video se drene silenciosamente.
- Evita reintentos innecesarios: Reescribe el prompt en lugar de simplemente presionar "reintentar".
- Guarda imágenes sin editarlas: "Editar esta imagen" activa nuevas generaciones y consume créditos adicionales.
¿Cambiar entre puntos de entrada ayuda?
El error de "alta demanda" se comporta de manera diferente en distintas interfaces. Si grok.com está limitado, la integración de Grok dentro de la aplicación X a menudo sigue funcionando, ya que los usuarios de X Premium operan bajo una cuota de prioridad separada en la plataforma social. Cambiar entre ambos es una solución legítima y de bajo esfuerzo.
No existe una página de límites de tasa de consola de xAI que muestre el estado de la cuota en vivo. El método más confiable es verificar el mensaje de error: si Grok devuelve un temporizador de cuenta regresiva, esa cifra es más precisa que cualquier estimación general.
Veredicto final: ¿Vale la pena la generación de imágenes de Grok de pago?
La propuesta de valor del límite diario de generación de imágenes de Grok xAI está cada vez más dividida: sigue siendo sólida para los creadores casuales, pero se está volviendo altamente problemática para los profesionales de nivel de producción que exigen estabilidad en el flujo de trabajo.
Para los desarrolladores que necesitan generación de imágenes xAI programática sin el dolor de cabeza de los errores web de "límite de tasa excedido", migrar a una infraestructura de API ofrece un consumo granular y predecible. Aunque el precio de la API de pago por uso en varios proveedores refleja de cerca los costos nativos, el verdadero valor de utilizar una plataforma de desarrollo radica en el control avanzado de parámetros y la ejecución de tuberías concurrentes sin restricciones.
Si estás cansado de adivinar cuándo se reinicia tu ventana móvil de 2 horas, probar tu tubería con infraestructura de nube especializada como la de Atlas Cloud es el siguiente paso lógico.






