
Kling 2.6 es la actualización más importante de Kling AI hasta la fecha, pero viene con una advertencia notable que debes conocer antes de empezar.
Este lanzamiento marca la primera vez que Kling incluye un modelo de sincronización de audio nativa. Anteriormente, todos los videos generados eran esencialmente películas mudas. Antes, los creadores tenían que añadir voces en off, efectos de sonido y ruido de fondo manualmente tras crear el video. El nuevo modelo VIDEO 2.6 cambia todo esto: crea las imágenes, voces en off realistas, efectos de sonido a juego y audio de fondo, todo al mismo tiempo. Esta función sitúa a la herramienta en una categoría completamente distinta.
Lo que funciona bien
Este modelo es excelente para combinar imagen y sonido. El ritmo de la voz, el ruido de fondo y las acciones en pantalla se alinean perfectamente. Esto elimina la desconexión habitual entre el video y las pistas de audio independientes. Los sonidos cinematográficos se sienten increíblemente realistas; puedes escuchar claramente detalles como el crepitar del fuego, la lluvia en las calles y el ruido ambiental de una multitud. La compatibilidad abarca seis tipos de audio:
| Tipo de audio | Caso de uso |
| Narración de voz | Videos de producto, vlogs |
| Diálogo con varios personajes | Entrevistas, sketches |
| Canto / Rap | Interpretaciones musicales |
| Sonido ambiental | Naturaleza, escenas urbanas |
| Efectos de sonido (SFX) / Acciones | Impactos, ruido mecánico |
| Sonido mixto | Producciones inmersivas completas |
La limitación principal
Las escenas de diálogo con tres o más personajes pueden producir una atribución de voz inconsistente. Para lograr la sincronización audiovisual más fiable, los creadores deben limitarse a intercambios entre dos personajes o considerar encuadres alternativos.
Cómo se compara
La versión 2.6 es un gran salto respecto a los modelos anteriores, que eran mudos. Algunos usuarios podrían necesitar un control total o resultados masivos de alta calidad; para ellos, Kling 3.0 es la opción adecuada. Sin embargo, la mayoría de los creadores de contenido califican a Kling 2.6 de forma muy positiva, ya que ofrece una gran calidad en relación con su precio.
Anatomía del audio nativo de Kling: Análisis profundo de diálogos, SFX y ambiente
Kling 2.6 no solo añade audio sobre el video; genera las tres capas de audio simultáneamente con los fotogramas visuales en una sola pasada. Así es como funciona cada capa en la práctica:
Diálogos y voz
La generación de diálogos de Kling AI abarca un rango más amplio de lo que la mayoría espera. Este modelo gestiona fácilmente discursos individuales, diálogos entre personajes, narraciones, canto y rap, ajustando el tono emocional para adaptarse a cada estilo. Además, la herramienta es bilingüe y admite de forma natural salidas de voz tanto en inglés como en chino. Si introduces otros idiomas, el modelo los traduce automáticamente al inglés para la generación de voz sin afectar a la salida de video general.
El video de 8 segundos de arriba demuestra nuestra salida directa utilizando Kling 2.6 a través de la plataforma de orquestación de Atlas Cloud. Al cargar una imagen base de alta resolución del hablante y una pista de voz en inglés pregrabada de 8 segundos, el motor procesó la sincronización labial de forma nativa.
Observa cómo la sincronización de los músculos faciales se mapea suavemente con fonemas complejos sin la habitual distorsión robótica de la boca típica del "valle inquietante". Esto sirve como modelo perfecto para activos de portavoces de marca generados por IA rápidamente.
Reglas rápidas para ahorrar tiempo:
- Cuidado con las mayúsculas: usa minúsculas para las palabras cotidianas y reserva las mayúsculas para nombres y acrónimos.
- Identifica a tus personajes: dales una etiqueta como [Personaje A] o [Personaje B]. Esto evita que la IA mezcle sus voces.
- Describe el estado de ánimo: añade notas de tono justo al lado de la etiqueta. Por ejemplo: [Reportero, voz tranquila y constante].
Efectos de sonido (SFX)
Los efectos de sonido de IA en 2.6 se activan por contexto en lugar de asignarse manualmente. El modelo lee la descripción de la escena e infiere los sonidos apropiados. La IA genera sonidos basados directamente en las palabras de acción que utilices. Puede crear pisadas sobre grava, cristales rotos, chirridos de neumáticos o el zumbido de una máquina. Para obtener los mejores resultados, nombra la fuente del sonido claramente. Por ejemplo, escribir [Puerta de madera cerrándose de golpe, fuerte estruendo] funciona mucho mejor que simplemente decir "hay un ruido".
Sonido ambiental
La síntesis de audio ambiental maneja la capa del entorno: murmullo de cafetería, lluvia contra el cristal, viento en un campo abierto, llegada del metro. Estas pistas de fondo se reproducen bajo tus diálogos y efectos de sonido, añadiendo una gran profundidad a tu video. Debes nombrar el entorno específico en tu prompt; por ejemplo, usa términos como [acústica de sala pequeña] o [reverberación de vestíbulo abierto]. Esto da al modelo un objetivo claro y mejora el audio.
Duración: Salida de 5 frente a 10 segundos
Esta elección afecta directamente a la estabilidad del audio. La decisión entre video de 5 o 10 segundos en Kling es crucial para contenido con mucho diálogo.
| Tipo de contenido | Duración recomendada | Razón |
| Solo ambiente / SFX | 5s | Salida limpia y ajustada |
| Monólogo / Narración | Cualquiera | Depende de la longitud del guion |
| Diálogo de varios personajes | 10s | Cambio de voz más estable |
| Canto / Rap | 10s | Evita cortes en la letra |
Para escenas de canto o diálogo, se recomienda usar el parámetro de 10 segundos para obtener resultados más completos y estables. Los clips más cortos funcionan bien para atmósferas puras o efectos de sonido de acción, pero cualquier cosa que involucre líneas habladas se beneficia de la ventana más larga para evitar el desfase de audio en los segundos finales.
La fórmula perfecta de prompt para Kling 2.6 para una sincronización audiovisual impecable
La mayoría de los problemas de sincronización en Kling 2.6 no provienen del modelo, sino de prompts que dejan demasiado espacio a la interpretación. Piensa en tu prompt como en las instrucciones de un director: cuanto más precisamente definas cada elemento, menos tendrá que adivinar el motor de inferencia, y es al adivinar cuando el ritmo se rompe.
La fórmula base
Esta plantilla de prompt para Kling se mapea directamente a la forma en que el modelo procesa la generación:
Escena → Sujeto → Movimiento y cámara → Plano de audio
La estructura oficial es: Escena (descripción del entorno) + Elemento (descripción del sujeto) + Movimiento (descripción de la acción) + Audio (diálogo / canto / efectos / música) + Otros (estilo / emoción / cámara).
Cada bloque alimenta una parte diferente de la cadena de generación. Omitir cualquiera de ellos obliga al modelo a llenar el vacío, momento en el que el ritmo audiovisual se desmorona.
Desglose bloque a bloque
| Bloque | Qué incluir | Error común |
| Escena | Ubicación, iluminación, momento del día | Demasiado vago: "una habitación" |
| Sujeto | Apariencia, rol, posición en el encuadre | Personajes sin nombre o solo con pronombres |
| Movimiento y Cámara | Secuencia de acción, lenguaje de control de cámara (zoom lento, paneo, primer plano) | Sin instrucción de cámara |
| Plano de Audio | Diálogo entre comillas, etiqueta de emoción, etiqueta de SFX, capa ambiental | Diálogo enterrado en la prosa de la descripción |
Ejemplo listo para usar: La anatomía de un render perfecto
Debido a las restricciones de API regionales y cuellos de botella en las colas de la plataforma nativa de Kling, utilizar la pipeline kling-v2.6-std-avatar en Atlas Cloud es la vía más fiable para la producción automatizada de gran volumen. Aunque este nivel específico te restringe a un formato de "cabeza parlante" estática en lugar de escenas dinámicas con varios agentes, destaca enormemente en el mapeo fonético preciso.
Para demostrar la autoridad de nuestra fórmula central, ejecutamos el esquema exacto de arriba a través de Kling 2.6 (nivel kwaivgi-kling-v2.6-std-avatar) mediante la plataforma de orquestación de Atlas Cloud. El clip de 2 segundos de arriba representa la salida comercial intacta de una sola pasada.
Analicemos por qué este render logra un naturalismo impecable en lugar de caer en el "valle inquietante":
- Bloqueo de composición en el fotograma 0: Al utilizar una imagen inicial donde la presentadora ya está posicionada con el reloj inteligente junto a su mejilla, eliminamos el riesgo de deformación de las extremidades. La IA no tiene que adivinar mecánicas óseas complejas; solo anima las microexpresiones.
- Precisión de sincronización labial fonética: Observa cómo los movimientos de los labios y el seguimiento dental coinciden perfectamente con los cambios rápidos de sílabas de "Zero lag. All day battery."
- Iluminación cinematográfica y profundidad: La baja profundidad de campo (el desenfoque del fondo o bokeh) filtra gran parte del ruido ambiental, obligando a los procesos de IA a centrar el 100% de su capacidad computacional en renderizar poros de la piel realistas y texturas de ropa nítidas.
Duración y ventana de audio
Conocer la longitud máxima de clip de Kling AI es importante para la planificación del audio. Las salidas actuales alcanzan un máximo de 10 segundos. Para una demostración de producto como el ejemplo anterior, 10 segundos es la elección correcta: da espacio a la voz en off para terminar claramente sin cortar la última palabra. Los clips de 5 segundos se adaptan a atmósferas puras o parejas de acción-efectos donde no se necesita completar ninguna línea hablada.
Planifica la longitud de tu guion según la longitud de tu clip antes de escribir el prompt, no después.
Flujo de trabajo de imagen a video: Manteniendo la consistencia de los personajes con Kling Motion Control
Para los creadores profesionales, el camino de texto a video es solo un punto de entrada. El flujo de trabajo de imagen a video de Kling es donde se crea el contenido serio basado en personajes, y cuando se combina con Kling 2.6 motion control, te otorga un nivel de consistencia que el simple prompt de texto no puede igualar.
Cómo la pipeline I2V ancla la identidad
Cuando cargas una imagen de referencia en el modo de Imagen a Audio-Visual, actúa como un contrato visual con el modelo. La imagen de entrada especifica la apariencia, composición, estilo y otros rasgos visuales del sujeto, haciendo que el video generado sea más cercano a la imagen original. Esta es la base de la consistencia de personajes en IA: el modelo trata el rostro, la ropa y el encuadre cargados como restricciones fijas en lugar de sugerencias.
Esto es fundamental para:
- Contenido de portavoces de marca que requieren el mismo rostro en múltiples clips.
- Personajes de propiedad intelectual que necesitan mantener su apariencia a través de diferentes escenas.
- Presentadores de demos de producto donde la identidad visual es parte del activo.
Motion Control: Proyección de datos físicos
Una imagen de referencia bloquea la apariencia. Kling 2.6 motion control añade la capa física proyectando datos de gestos, postura y movimiento desde una referencia de movimiento sobre el personaje generado. La referencia de movimiento actúa como una plantilla de actuación, con el modelo transfiriendo la mecánica corporal mientras preserva la identidad visual anclada por la imagen de entrada.
Esta separación entre identidad (imagen) y movimiento (clip de referencia) es lo que hace que el enfoque de animación por IA con video de referencia sea más fiable que describir el movimiento solo con texto.
Sincronización labial y alineación de audio en I2V
La sincronización labial de Kling 2.6 se gestiona de forma nativa cuando el Audio Nativo está habilitado en el modo de Imagen a Video. La función de Control de Voz te permite vincular una voz específica a un personaje usando el formato [Personaje@NombreDeVoz], permitiendo al modelo replicar con precisión las características vocales para realizar el contenido especificado.
| Capa de entrada | Qué controla |
| Imagen de referencia | Rostro, ropa, encuadre, estilo visual |
| Referencia de movimiento | Gestos, cambios de postura, ritmo corporal |
| Vinculación de control de voz | Timbre, estilo de entrega, consistencia entre idiomas |
| Bloque de audio del prompt | Contenido del diálogo, etiqueta de emoción, capa ambiental |
Ejemplo: Aplicación de la fórmula central a flujos de trabajo de Imagen a Video (I2V)
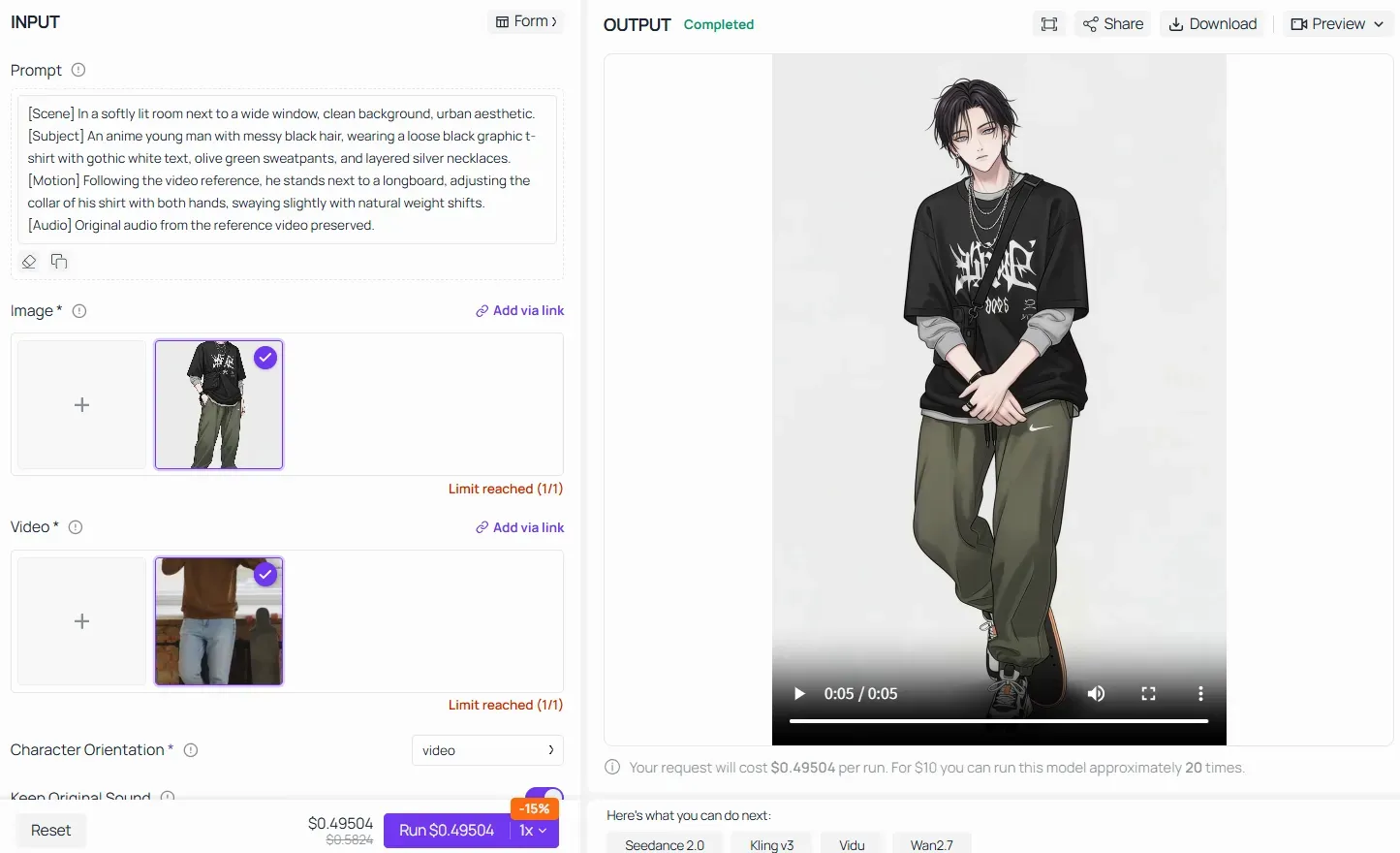
Al utilizar funciones avanzadas como Video Reference / Motion Transfer en plataformas como Atlas Cloud, la Fórmula Central mantiene su autoridad absoluta. En lugar de dar instrucciones vagas a la IA como "haz que el personaje de anime haga el mismo baile", debes estructurar el prompt desglosando la escena, congelando los rasgos del sujeto cargados y bloqueando el mapeo de movimiento:
Al completar cada bloque de la pipeline, te aseguras de que el modelo de IA transfiera perfectamente la mecánica ósea del video del mundo real al personaje de anime sin destruir su identidad visual.
Regla de oro para el Motion Control en Kling 2.6: Tu prompt de texto no necesita preocuparse por los pequeños detalles mecánicos (como "mueve el brazo 45 grados"). Deja que el video de referencia haga el trabajo pesado de la cinemática. En su lugar, usa tus bloques de [Sujeto] y [Escena] para bloquear implacablemente el estilo visual, las texturas y las paletas de colores, asegurando que la IA transfiera la actuación sin deformar la identidad de la imagen original.
Calidad de imagen y límites prácticos
Ten en cuenta una regla fundamental: tu video final solo se verá tan bien como la imagen que cargues.
Usa siempre imágenes de alta resolución. Una imagen de baja resolución hará que el video resulte granulado y borroso. La IA no puede arreglar esos detalles después. Este problema destaca especialmente en los primeros planos de rostros.
Utiliza una imagen fuente de mayor resolución y la consistencia de tu personaje se mantendrá tanto en ventanas de 5 como de 10 segundos sin degradación.
Solución de problemas técnicos: Resolución de cuellos de botella y desfase de audio
Incluso los creadores experimentados tienen fricciones con Kling 2.6. Los dos problemas más reportados son las generaciones que se bloquean a mitad del proceso y los diálogos que pierden la sincronización después de la mitad del clip. Ambos tienen causas identificables y soluciones prácticas.
Por qué Kling se queda bloqueado al 99%
Si tu video se queda al 99%, suele ocurrir por dos razones: los servidores están demasiado ocupados o tu prompt es demasiado complicado para el sistema. La IA intenta construir todos los sonidos y efectos visuales al mismo tiempo; si incluyes demasiado en tu prompt, las instrucciones chocan, lo que ralentiza o bloquea el sistema.
Soluciones a intentar:
- Inténtalo más tarde. Refresca la página y envía el prompt durante las horas de menos tráfico; las primeras horas de la mañana suelen ser las mejores.
- Simplifica: divide tu prompt complicado en dos partes más pequeñas y ejecútalas como generaciones de video separadas.
- Elimina las descripciones ambientales apiladas y mantén una capa de sonido dominante por clip.
- Reduce el número de personajes si usas tres o más hablantes en una sola generación.
Cómo arreglar el desfase del diálogo
Corrige el desfase del diálogo abordando su causa raíz: el procesamiento del modelo para múltiples hablantes se degrada después de los 5-6 segundos cuando compiten demasiadas instrucciones de voz. El rendimiento puede disminuir en escenas con tres o más personajes.
| Escenario | Solución recomendada |
| Diálogo de dos personas > 10s | Usa 10s de duración con señales claras de cambio de hablante |
| Tres o más hablantes | Divide en clips separados por pareja de hablantes |
| Monólogo largo con desfase | Acorta el guion para que encaje cómodamente en 10s |
| Canto que se corta | Usa siempre el parámetro de 10s para contenido musical |
Reducción de artefactos y optimización de créditos
Para reducir artefactos de generación, mantén los archivos de imagen a video en alta resolución y evita descripciones de escenas contradictorias. Sobre la optimización de créditos, ten en cuenta que el Audio Nativo habilitado cuesta 10 créditos por segundo en el modo profesional, frente a los 5 créditos por segundo con el audio desactivado. Haz borradores sin audio y habilítalo solo para los renders finales para aprovechar mejor tu presupuesto de limitaciones de plataforma.
Kling 2.6 vs. Kling 3.0 vs. Wan 2.6 vs. Veo 3.1: Comparativa directa
No esperes que una sola herramienta de video por IA lo haga absolutamente todo. Cuando buscas audio integrado, la "mejor" elección depende de tu presupuesto, tu flujo de trabajo y lo que necesite tu clip de video.
Comparativa rápida de funciones
| Función | Kling 2.6 | Kling 3.0 | Wan 2.6 | Veo 3.1 |
|---|---|---|---|---|
| Audio Nativo | Total (Diálogo/SFX/Ambiente) | Total (Sincronización en una pasada) | Total (Incluye sincronización labial) | Total (Audio espacial 3D) |
| Longitud máx. clip | 10s | 15s | 15s | 8s |
| Resolución máx. | 1080p | 4K nativo | 1080p | 4K nativo |
| Control de movimiento | Fuerte (Referencia esquelética/video) | Fuerte (Bloqueo de identidad total) | Moderado (Transferencia estilo/movimiento) | Moderado (Física de dinámica de fluidos) |
| Multi-toma | No | Sí (Hasta 6 tomas en una pasada) | Sí (Soporte de texto largo multiescena) | No |
| Control de voz | Sí | Sí | No (Depende del prompt) | No (Depende del prompt) |
| Precio | USD0.048 - 0.095/s | USD0.071 - 0.357/s | USD0.018 - 0.7/s | USD0.05 - 0.2/s |
Nota: Los precios se refieren a Atlas Cloud.
Donde Kling 2.6 tiene ventaja
Kling 2.6 frente a Wan 2.6 no es una competencia reñida en audio. Wan 2.6 solo tiene soporte de audio parcial, mientras que Kling 2.6 ofrece diálogo nativo completo, SFX y capas ambientales en una sola pasada. Para los creadores que necesitan clips completos y listos para usar sin postproducción, Kling 2.6 es el flujo de trabajo más limpio.
Kling 2.6 cuesta más de un 50% menos que Veo 3.1. Si no necesitas una calidad de video nivel Hollywood, Kling es la opción más inteligente. Te permite crear grandes cantidades de contenido sin arruinar tu presupuesto.
Donde Veo 3.1 destaca
Veo 3.1 frente a Kling video se reduce al realismo y a la espacialización del audio. Veo 3.1 genera entornos sonoros tridimensionales donde las fuentes de audio se mueven a través del campo estéreo, con una salida a 48 kHz y codificación estéreo AAC a 192 kbps. A marzo de 2026, ningún otro modelo importante de video por IA ofrece este nivel de espacialización. Para diálogos con calidad de transmisión y renderizado de texto, Veo 3.1 sigue siendo la mejor opción.
Comparativa de física en video por IA
En cuanto a la física en video por IA, los modelos divergen claramente. Kling 2.6 ofrece una excelente fluidez de movimiento con simulaciones físicas más realistas para el movimiento humano, mientras que Veo 3.1 muestra inconsistencias físicas ocasionales pero destaca en iluminación y texturas.
Marco de decisión
- Elige Kling 2.6 para: personajes controlados por voz, producción con presupuesto ajustado, contenido social y salida audiovisual completa en una sola pasada.
- Elige Kling 3.0 para: tomas cinematográficas más largas, guiones gráficos con múltiples escenas y salida 4K.
- Elige Wan 2.6 para: código abierto, iteración sin coste y pruebas de borrador.
- Elige Veo 3.1 para: audio espacial, renderizado de texto y anuncios de productos fotorrealistas.
Conclusión: El nuevo ritmo de la producción de video con IA
La cadena tradicional de producción de video —exportar visuales, generar voces en off por separado, añadir efectos de sonido y mezclar todo en postproducción— ya no se aplica al usar Kling 2.6. Toda esa secuencia se colapsa ahora en una sola entrega de prompt.
Los creadores que se mueven más rápido son los que tratan la escritura de prompts como un arte de dirección en lugar de como una búsqueda de información. El verdadero truco para un video de nivel profesional es sencillo: solo necesitas empaquetar tus planes de escena, sujeto, movimiento y sonido en un solo prompt claro.
Ahora mismo, Kling 2.6 es una de las mejores herramientas disponibles. Funciona muy bien para grandes equipos de contenido, creadores en solitario y estudios de marketing que desean video rápido y de alta calidad. El techo técnico seguirá subiendo, y dominar la estructura del prompt ahora construye la base creativa necesaria para escalar con él.






