
Hace unos meses, nos fijamos un objetivo engañosamente simple: producir video coherente de alta calidad de más de 15 segundos, en una sola GPU y en mucho menos de un minuto de tiempo real. Los modelos de difusión de video actuales, como Wan2.2, son buenos para clips de 3 a 5 segundos. Ampliar eso a 10, 30 o 60 segundos es donde las cosas se ponen interesantes.
Esta publicación documenta el camino que realmente tomamos. Analizamos seis enfoques que aparecen en artículos recientes e informes técnicos —TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk y Helios—, medimos las ventajas y desventajas y, finalmente, nos decidimos por SVI (Stable Video Infinity), conectado a TurboWan en nuestro motor DiffSynth. Repasaremos cada una de esas rutas, cómo funciona SVI y los números de producción.
Por qué el video largo es difícil
Tres cosas fallan cuando superas los cinco segundos.
El muro de la VRAM
Wan2.2 utiliza Full Attention con un coste de O(n²) en el número de tokens latentes. Las matemáticas son implacables:
5s (81 frames): ~32.7k tokens, matriz de atención ~10 GB.
10s (165 frames): ~65.5k tokens, matriz de atención ~40 GB: ya supera la capacidad de una sola GPU.
30s (~500 frames): ~200k tokens, inviable.
En la práctica, Self Forcing por sí solo llena la mayor parte de los 129 GB de una H200 a 165 frames solo por la caché KV.
Desviación temporal (Temporal drift)
Incluso cuando la memoria es suficiente, aparecen tres modos de desviación. El artículo de Helios los denominó: desplazamiento de posición (sujetos que vagan por el encuadre), desviación de color (cambio gradual de tono y brillo) y desviación de restauración (el modelo sobrecorrige y produce discontinuidades visibles).
Consistencia causal
La difusión de video estándar utiliza Full Attention bidireccional: cada frame atiende a todos los demás. Eso significa que no hay salida por streaming: no puedes mostrar el frame 1 hasta que el frame N esté terminado.
Nuestro objetivo concreto era modesto: video de ≥15 segundos, continuidad visual fluida, sujetos estables en todo el clip, tiempo de espera total inferior a 60 segundos, entrenamiento mínimo y una fuerte preferencia por reutilizar los pesos que ya tenemos.
El estudio
Analizamos seis familias. Los nombres son en su mayoría títulos de artículos; las categorías serán importantes más adelante.
Ruta 1 · TTT (Test-Time Training)
Artículo: One-Minute Video Generation with Test-Time Training (arXiv 2504.05298, abr 2025).
La idea es ajustar el modelo durante la inferencia para que recuerde lo que ya ha generado. Se inserta una pequeña capa TTT (un MLP de 2 capas, más una puerta y una atención local) después de la Atención en cada bloque Transformer, y el modelo se entrena con un plan de estudios que va desde clips cortos hasta un minuto completo.
Inserción por bloque: después de la atención estándar, se empalma una puerta, una capa TTT y una atención local, seguidas de una LayerNorm.
Plan de estudios: entrenamiento en ventanas progresivamente más largas: 3s → 9s → 18s → 30s → 60s.
Coste: 256 H100 durante ~50 horas.
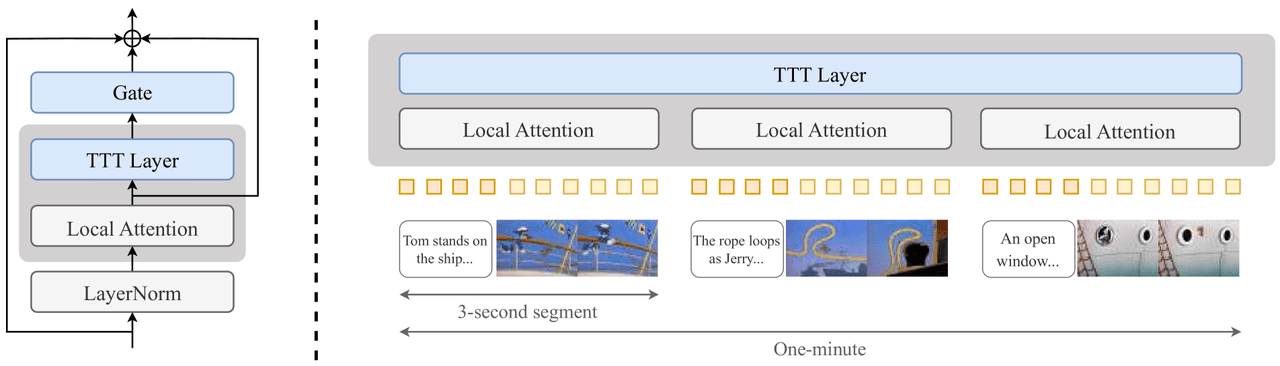
TTT — izquierda: punto de inserción (Puerta + Capa TTT + Atención local + LayerNorm, conectada después de la Atención estándar mediante residual). Derecha: video segmentado en clips de 3 segundos, cada uno manejado internamente por la Atención local, con la capa TTT llevando la memoria global a través de los segmentos.
Funciona: el artículo logra la generación de 1 minuto. Pero el coste de entrenamiento es enorme, los experimentos solo cubren CogVideoX 5B (la transferencia a Wan2.2 14B no está probada) y las capas TTT insertadas entran en conflicto con las optimizaciones de kernel en las que ya confiamos. Veredicto: no seleccionado.
Ruta 2 · LoL (Longer than Longer)
Artículo: LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914, ene 2026).
LoL se dirige a un modo de fallo específico en el video largo autorregresivo: el colapso del sumidero (sink-collapse), donde la atención de múltiples cabezales converge en el frame de anclaje y el video vuelve periódicamente a su estado inicial. La solución es Multi-Head RoPE Jitter: perturbaciones de fase aleatorias por cabezal que rompen la homogeneidad entre cabezales. Sin entrenamiento, tipo plug-in.
Modo de fallo: colapso del sumidero: bajo RoPE autorregresivo, las fases posicionales de los frames distantes se realinean periódicamente con el anclaje, la atención se concentra y el contenido vuelve al frame de anclaje.
Solución: dar a cada cabezal de atención su propio pequeño cambio de fase aleatorio. Los cabezales ya no pueden colapsar en la misma columna. No requiere reentrenamiento, se integra en modelos existentes.
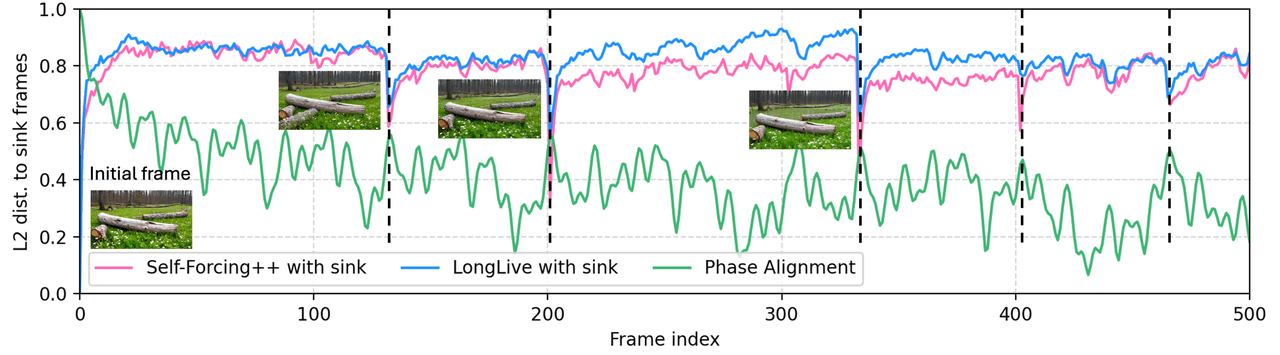
Distancia L2 al anclaje vs. índice de frame. Self-Forcing++ (rojo) y LongLive (azul), ambos con sumidero, vuelven repetidamente a posiciones de frame específicas; esos son eventos de colapso de sumidero donde el video vuelve al anclaje. La Alineación de Fase de LoL (verde) elimina ese retorno.
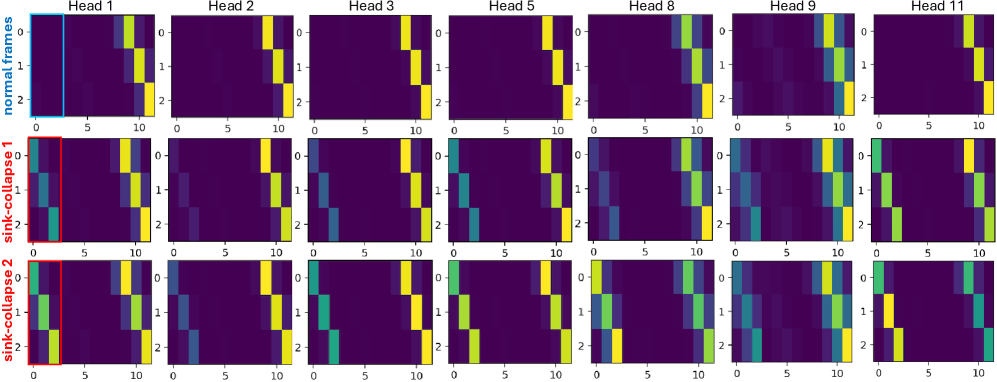
Mapas de atención por cabezal. Fila superior: frames normales: los cabezales tienen patrones visiblemente diferentes. Filas inferiores: durante el colapso del sumidero: cada cabezal se ve igual, todos colapsados en la columna del frame de anclaje. RoPE Jitter restaura la diversidad por cabezal.
LoL alcanza 12 horas de video en CogVideoX/HunyuanVideo con poca pérdida de calidad. El problema es que todas las demos son escenas estáticas; no sabemos cómo sobrevive a bailes, deportes o cualquier cosa con movimiento fuerte. Además, tendríamos que modificar la atención de Wan2.2. Veredicto: el coste de adaptación es demasiado alto para ganancias no probadas en contenido con movimiento. No seleccionado.
Ruta 3 · Self Forcing (Wan2.2 causal)
Artículo: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009, NeurIPS 2025 Spotlight).
Self Forcing reemplaza la Full Attention bidireccional de Wan2.2 con atención causal: un frame solo atiende a los frames anteriores. Ese único cambio desbloquea la generación por streaming: una vez que el primer fragmento está hecho, se decodifica y se envía.
Bidireccional: cada frame atiende a todos los demás → se deben terminar los 40 pasos de eliminación de ruido antes de mostrar cualquier frame. Causal: un frame solo ve su pasado → el primer fragmento puede emitirse en cuanto termina.
El truco de entrenamiento es lo que le da nombre al artículo. En lugar de entrenar con contexto de verdad fundamental limpio (Teacher Forcing) o con máscaras de atención personalizadas (Diffusion Forcing), Self Forcing despliega la ruta de inferencia real con una caché KV rodante, de modo que las distribuciones de entrenamiento e inferencia coinciden.
Bucle de generación: elimina el ruido del siguiente pequeño fragmento de frames usando el cronograma de pasos comprimidos de DMD, condicionado a una caché KV rodante construida a partir de frames ya generados.
Stream: tan pronto como termina un fragmento, el VAE lo decodifica y lo emite.
Carry-over: empuja los latentes del nuevo fragmento a la caché KV para que el siguiente fragmento los atienda.
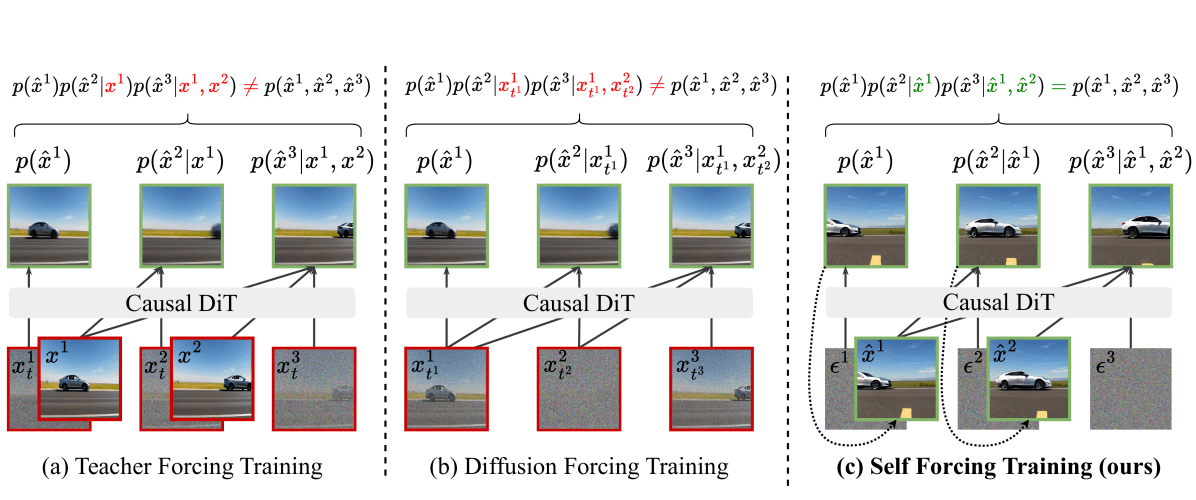
Tres paradigmas de entrenamiento comparados: (a) Teacher Forcing entrena en frames limpios: en la inferencia, los frames ruidosos causan deriva fuera de distribución; (b) Diffusion Forcing usa máscaras de atención personalizadas pero aún tiene desajuste entre entrenamiento e inferencia; (c) Self Forcing repite el proceso de inferencia real usando una caché KV rodante, alineando completamente el entrenamiento y la inferencia.
Lo medimos en el framework FastVideo, con una sola H200:
| Duración | Frames | Tiempo | VRAM |
|---|---|---|---|
| 5s | 81 frames | 70s | — |
| 10s | 165 frames | 168s | 129 GB (casi al límite) |
| 20s | 321 frames | 287s | 129 GB (caché KV limitada a 42 frames) |
Esta es arquitectónicamente la respuesta más limpia, y realmente nos gusta. Pero 10s ya satura la VRAM de una H200, la calidad cae a 165 frames, el modelo original necesita un ajuste fino de atención causal y el streaming real también necesita una Conv3D Causal en el VAE.
Veredicto: esperar a que la comunidad resuelva los problemas de VRAM y calidad. No adoptado por ahora.
Ruta 4 · Self Forcing++
Artículo: Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283, oct 2025).
Se basa en Self Forcing con tres adiciones: Inicialización de Ruido Inverso (cada nuevo fragmento comienza a partir de ruido integrado hacia atrás desde frames ya generados, eliminando discontinuidades en los límites de los fragmentos); alineación DMD extendida (recortar ventanas de 5s de un despliegue largo y alinearlas contra la salida de ventana corta de un profesor); y una etapa de GRPO con recompensa de flujo óptico para impulsar un movimiento más dinámico.
Paso 1. Auto-despliegue del estudiante durante mucho más de 5 segundos, acumulando un borrador largo usando una caché KV rodante. Paso 2. Recortar ventanas aleatorias de 5s de ese borrador, ejecutarlas a través de DMD extendido contra la distribución de ventana corta del profesor para alinear. Paso 3. Refinar con GRPO usando la magnitud del flujo óptico como recompensa, empujando al modelo hacia un movimiento más dinámico. Truco. Cada nuevo fragmento comienza con ruido integrado hacia atrás desde el fragmento anterior, no desde un gaussiano fresco, por lo que los límites de los fragmentos ya no aparecen.
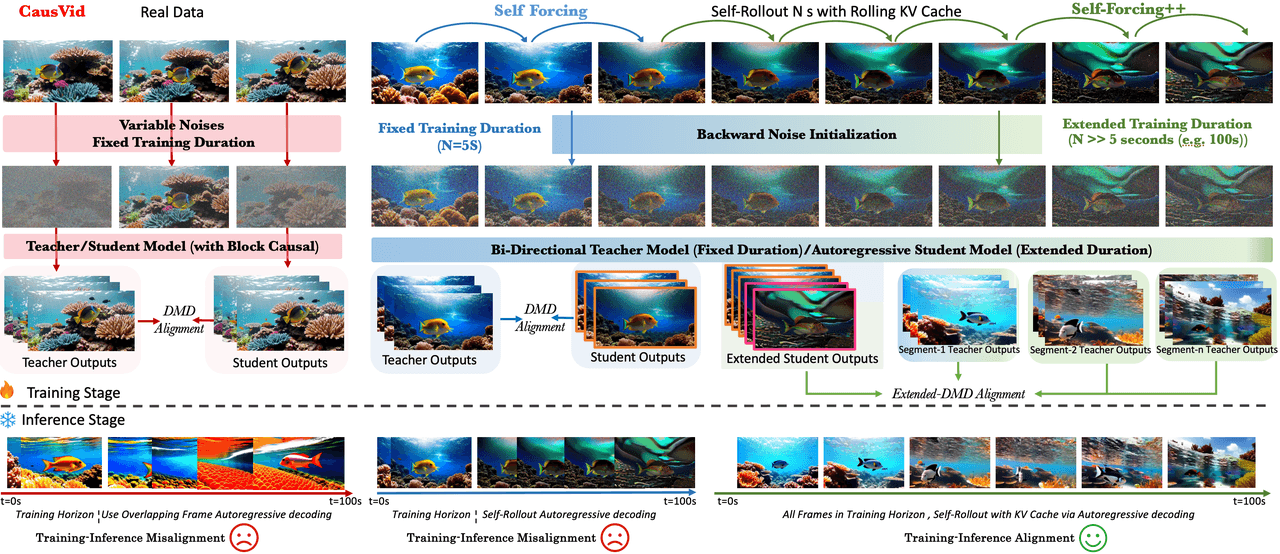
De izquierda a derecha: CausVid (duración de entrenamiento fija, desajuste entrenamiento-inferencia) → Self Forcing (duración fija + alineación DMD) → Self-Forcing++ (duración extendida + Inicialización de Ruido Inverso + alineación DMD extendida). Las filas inferiores muestran la correspondencia entre la etapa de entrenamiento y la etapa de inferencia.
Resultado: video a escala de minutos (hasta unos 4m15s) en un Wan2.1 de 1.3B. Gran artículo. Para la producción, golpeamos dos muros: el contenido es mayormente estático (poco movimiento), el modelo base es de 1.3B (muy por debajo de Wan2.2 14B), y no hay código o pesos lanzados para arrancar. Veredicto: no seleccionado por ahora.
Ruta 5 · Infinite Talk (A2V)
Un tipo de problema completamente diferente: Audio-a-Video, donde el audio impulsa la generación continua de cabezas parlantes.
Paquete de entrada por fragmento: los nuevos latentes ruidosos del fragmento, las características de audio para esa ventana de tiempo, la imagen de referencia proporcionada por el usuario, el último frame del fragmento anterior y un peso de condicionamiento suave. Identidad de referencia: la imagen de referencia mantiene estable la apariencia a largo plazo. Restricción adaptativa: el peso suave ajusta o relaja la referencia según la desviación de similitud. Puente de movimiento: el último frame del fragmento anterior transporta el movimiento a través de los límites.
Es bueno para lo que es: cabezas parlantes, indefinidamente. Pero la arquitectura difiere lo suficiente de Wan2.2 que requiere un entrenamiento dedicado, y no se generaliza a escenas generales. Veredicto: valioso en un carril estrecho, no es una solución general de video largo.
Ruta 6 · Helios
Artículo: Helios: Real Real-Time Long Video Generation Model (PKU-YuanGroup, arXiv 2603.04379, mar 2026).
Al momento de escribir este artículo, Helios es el SOTA para video largo: 14B parámetros, 19.5 FPS en tiempo real en una sola H100. El truco consiste en comprimir los frames históricos en una pirámide de tres niveles e inyectarlos en la eliminación de ruido del frame actual, de modo que el presupuesto de tokens se mantenga constante sin importar cuán largo sea el video.
Memoria de Términos Múltiples. La historia a corto plazo (últimos 3 frames) mantiene la resolución completa; la de mediano plazo (últimos 20 frames) obtiene una compresión moderada; la de largo plazo (todo lo anterior) obtiene una compresión fuerte. El presupuesto total de tokens es constante independientemente de la longitud del video. Atención de guía. Dentro de cada bloque DiT, las KV históricas limpias y las QKV actuales ruidosas se procesan por separado para que el ruido histórico no pueda contaminar la eliminación de ruido actual. Muestreo piramidal. Muestrear a baja resolución primero para definir la estructura, luego refinar a alta resolución para añadir detalle: unos 2.3× menos tokens en general.
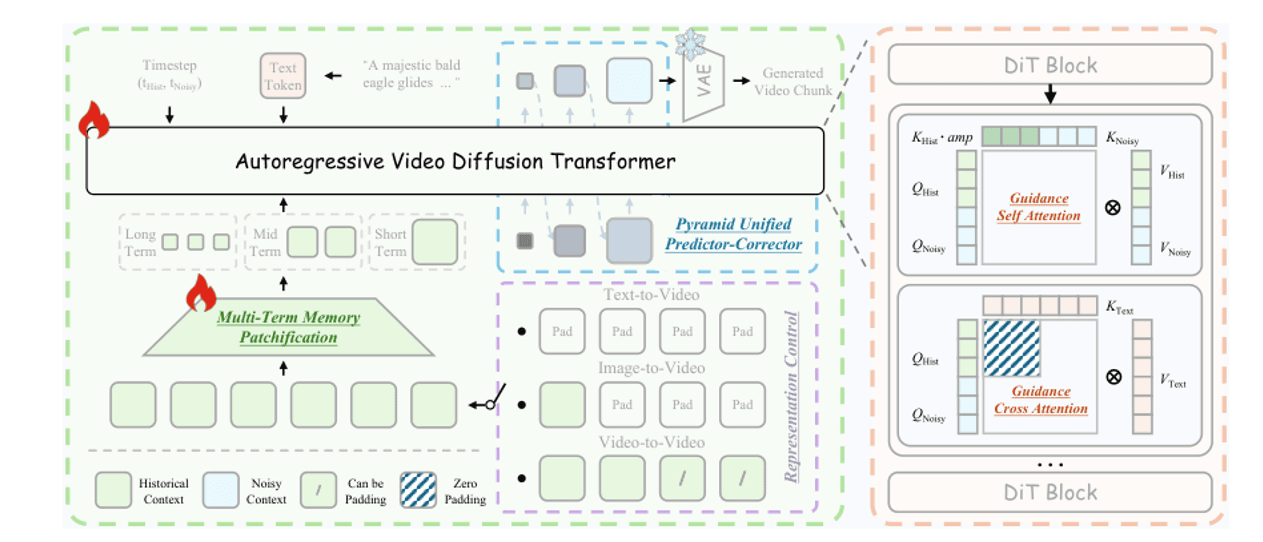
Arquitectura Helios. Izquierda: Inyección de historia unificada: historia a corto/mediano/largo plazo comprimida a diferentes ratios, concatenada con el frame actual antes de entrar al DiT. Derecha: Predictor-Corrector Unificado Piramidal: bajo recuento de tokens primero para definir la estructura, luego alto recuento de tokens para refinar detalles, reduciendo el cálculo en ~2.3×.

El artículo de Helios define y visualiza sistemáticamente tres categorías de deriva en la generación de video largo: (a) desplazamiento de posición, (b) desviación de color, (c) desviación de restauración (ruido), (d) desviación de restauración (desenfoque). La Atención de Guía está diseñada específicamente para abordar los tres.
El rendimiento medido de Helios en H200 es sorprendente: básicamente plano con la longitud:
| Duración | Tiempo | Rendimiento |
|---|---|---|
| 240 frames (10s) | 24s | ~10 FPS |
| 480 frames (20s) | 42s | ~11.4 FPS |
| 960 frames (40s) | 82s | ~11.7 FPS |
| H100 sola GPU (Helios-Distilled) | — | 19.5 FPS |
El problema es que la "Patchification" de memoria de términos múltiples necesita un reentrenamiento completo de un modelo de 14B. No hay pesos liberados, solo un informe técnico, por lo que no podemos simplemente añadir un LoRA. Veredicto: una dirección a mediano-largo plazo; no desplegable hoy.
Resumen de comparación de rutas
Las seis rutas lado a lado, con SVI añadido como la fila por la que finalmente apostamos:
| Enfoque | Duración Máxima | Calidad | Entrenamiento Requerido | Dificultad Ing. | Generalidad | Rec. |
|---|---|---|---|---|---|---|
| TTT | 1 minuto | Alta | Entrenamiento pesado | Alta | Media | ★★☆ |
| LoL | Escala de hora | Media (solo estático) | Entrenamiento necesario | Media | Media | ★★☆ |
| Self Forcing | Teor. ilimitada | Media (cae > 10s) | Modelo existente | Alta (VRAM) | Alta | ★★★ |
| Self Forcing++ | Escala de minutos | Baja (may. estático) | Entrenamiento necesario | Muy alta (sin código) | Alta | ★☆☆ |
| Infinite Talk | Ilimitada | Alta (cab. parlante) | Entrenamiento necesario | Alta | Baja (solo A2V) | ★★☆ |
| Helios | Teor. ilimitada | Alta (SOTA ind.) | Reentrenamiento completo | Muy alta (sin pesos) | Alta | ★★★☆ |
| SVI | Ilimitada | Media-Alta | LoRA de código abierto | Media | Alta | ★★★★ |
Una taxonomía que surgió del estudio
Si entrecierras los ojos, cada enfoque que analizamos cae en uno de tres cubos.
Tipo A: extender el rango de atención en sí (Self Forcing, LoL, TTT). Hacer que el modelo procese secuencias más largas directamente. Calidad teórica más alta. La VRAM crece cuadráticamente, por lo que la ingeniería se topa con un muro alrededor de los 10s hoy en día.
Tipo B: compresión jerárquica de historial (Helios). Comprimir frames pasados e inyectarlos como condicionamiento. Evita la VRAM. Cuesta un reentrenamiento completo de un modelo de 14B.
Tipo C: generación continua basada en estados (SVI, Infinite Talk). Descomponer el video largo en clips cortos con estados superpuestos. VRAM constante, duración ilimitada, entrenamiento solo con LoRA. El costo son posibles discontinuidades en los límites de los clips y una deriva a largo plazo sin límites que puedes gestionar pero no eliminar.
Para este trimestre, el Tipo C es lo que enviamos. Para el próximo año, el Tipo B es donde estamos observando la literatura.
En la próxima publicación, profundizaremos en cómo fue realmente el lanzamiento: seis enfoques para la generación de video de ≥15 segundos, por qué elegimos SVI y cuáles son los números de producción. Leer Parte 2 →






