
En la Parte 1, analizamos seis enfoques para la generación de video largo (TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk y Helios) y concluimos que SVI es el único camino viable hoy en día sin tener que reentrenar un modelo de 14B. Esta publicación trata sobre cómo fue el proceso de desarrollo: cómo funciona el bucle de unión de clips, por qué es vital el Error-Recycling y las cifras de producción de nuestra primera implementación en TurboWan.
La elección: SVI (Stable Video Infinity)
La filosofía central de SVI es convertir la generación de duración infinita en la unión de un número finito de clips cortos con una transferencia de memoria cuidadosamente diseñada. Esto suena modesto hasta que te das cuenta de que resuelve la mayoría de los problemas de ingeniería de golpe: sin reentrenamiento del modelo base (un pequeño LoRA montado sobre TurboWan), VRAM constante, compatible con la destilación de velocidad existente y pesos LoRA oficiales públicos.
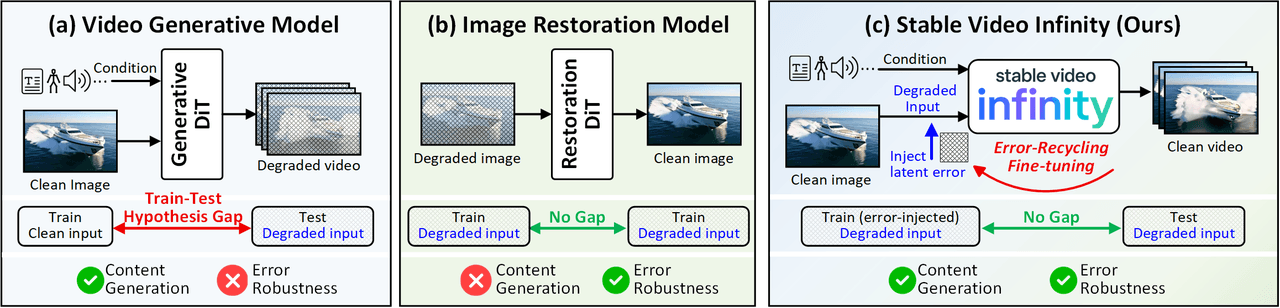
Modelo mental de SVI. (a) Los modelos generativos de video estándar tienen una brecha de hipótesis entre entrenamiento y prueba: entrenan con entradas limpias pero enfrentan entradas con ruido y errores acumulados durante la inferencia. (b) Los modelos de restauración de imágenes son robustos a errores pero no pueden generar contenido nuevo. (c) El ajuste fino por Error-Recycling de SVI actúa como puente: utiliza los errores autogenerados como señales de supervisión para que el modelo aprenda activamente a identificar y corregir sus propios errores de generación.
Cómo funciona la unión de clips
Cada clip dura 81 fotogramas (5s a 16fps). La generación es simplemente un bucle: condicionar el siguiente clip a un ancla de identidad global y a un puente de movimiento a corto plazo del clip anterior, y luego concatenar.
Clip 1. Entradas: imagen de referencia + memoria de movimiento vacía. Salida: clip de 5s. Extraer memoria de movimiento: el latente de los últimos 4 fotogramas. Clip 2. Entradas: imagen de referencia + memoria de movimiento del clip 1. Salida: clip de 5s. Extraer memoria de movimiento de su parte final. ... Repetir para N clips, luego concatenar clip 1 + clip 2 + … + clip N en el video largo.
Lo elegante es que no se necesita modificar la atención del DiT. El contexto histórico se concatena a nivel de entrada como latentes, y un pequeño LoRA enseña al modelo a utilizar ese prefijo.
Latente de ancla. Imagen de referencia proporcionada por el usuario, codificada por el VAE → mantiene la consistencia global en la apariencia del sujeto/personaje. Latente de movimiento. Latente de los últimos 4/8/12 fotogramas del clip anterior → indica al modelo cómo terminó el segmento anterior. Relleno (Padding). Alinea la forma de entrada para que el DiT vea una secuencia concatenada limpia: ancla + movimiento + relleno.
Ajuste fino mediante Error-Recycling
El detalle que permite que SVI mantenga la calidad a lo largo de muchos clips es cómo se entrena su LoRA. La inferencia estándar siempre comienza la eliminación de ruido a partir de ruido gaussiano puro, pero en la unión de videos largos, los errores de los clips anteriores contaminan el condicionamiento de los siguientes. Si solo entrenas con entradas de referencia limpias, habrás integrado la brecha entre entrenamiento e inferencia.
Entrenamiento estándar: Las entradas de referencia de cada clip son datos limpios reales; el modelo nunca ve el tipo de contexto histórico con ruido que enfrenta en la inferencia, por lo que las discontinuidades se acumulan.
Error-Recycling: Durante el entrenamiento, se inyectan deliberadamente los errores pasados del modelo en las entradas de referencia, de modo que el LoRA aprenda explícitamente a operar con un contexto histórico ruidoso. Las discontinuidades visuales en los límites de los clips disminuyen drásticamente.
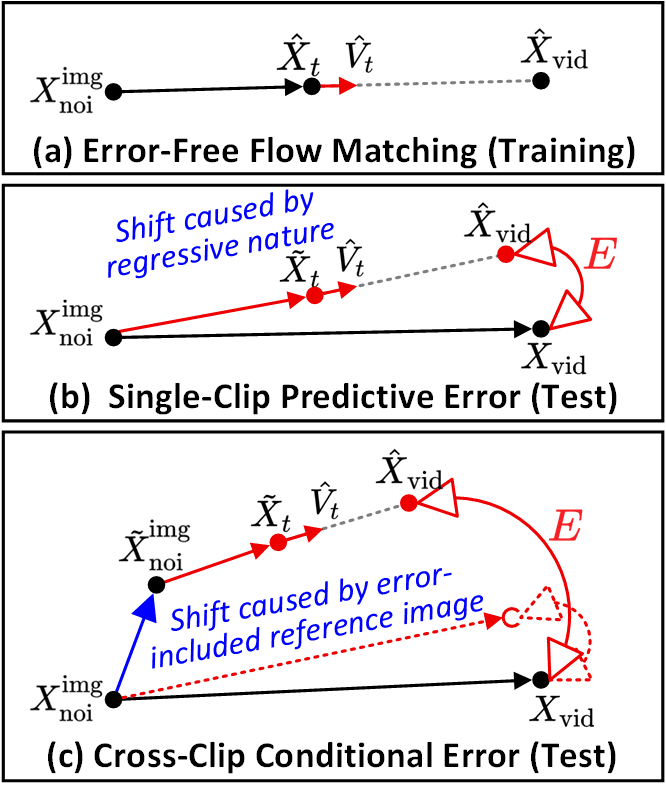
SVI identifica dos tipos de errores principales. (a) El Error-Free Flow Matching es la trayectoria durante el entrenamiento. (b) Error predictivo por clip: la desviación entre la ruta de eliminación de ruido y la trayectoria ideal. (c) Error condicional entre clips: las imágenes de referencia contaminadas con errores causan una desviación en cascada. El Error-Recycling inyecta ambos explícitamente.
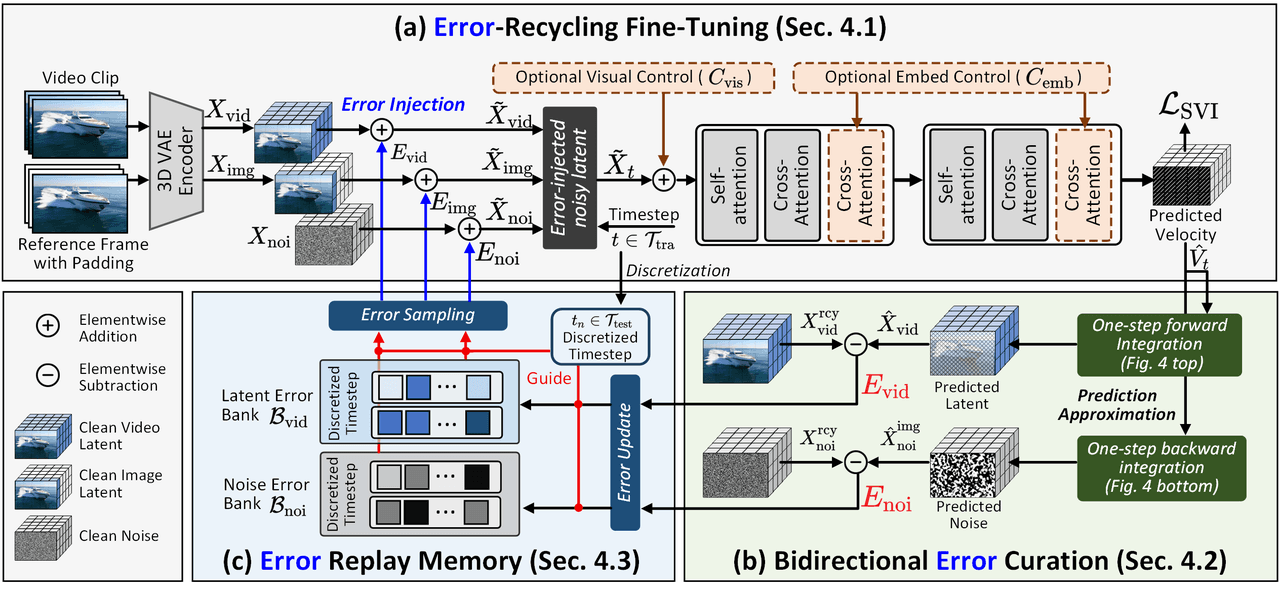
Marco de entrenamiento de SVI. (a) Inyectar errores autogenerados por el DiT en el espacio latente para romper la suposición de "sin errores". (b) Calcular eficientemente errores bidireccionales mediante integración hacia adelante/atrás de un solo paso. (c) Almacenar errores en una memoria de reproducción (Replay Memory) y volver a muestrear dinámicamente para su reutilización, creando un ciclo de supervisión de errores de bucle cerrado.
SVI separa dos tipos de errores. El error predictivo por clip es la desviación per-clip entre la trayectoria de eliminación de ruido y la ideal. El error condicional entre clips es la desviación en cascada que ocurre cuando las imágenes de referencia contaminadas fluyen hacia el siguiente clip. El Error-Recycling inyecta ambos, por lo que el LoRA aprende una tolerancia explícita a los errores.
Variantes de LoRA
SVI ofrece tres variantes: SVI-Shot para imagen estática a clip corto, SVI-Dance para movimiento humano (también puede tomar una secuencia de poses como entrada) y SVI-Film para videos largos de múltiples tomas/transiciones de escena. Hiperparámetros: 81 fotogramas por clip, num_motion_frames ∈ {4, 8, 12}, rango de LoRA típicamente 16–64.
Apilamiento en TurboWan
Montamos el LoRA de SVI sobre TurboWan (una versión acelerada de Wan optimizada por Atlas) y mantenemos nuestro LoRA especializado en la pila para el control de estilo. En la inferencia, se superponen varios pesos de LoRA simultáneamente.
Base. TurboWan. LoRA 1. LoRA especializado (control de contenido/estilo). LoRA 2. SVI LoRA (consistencia de video largo). Combinado. Velocidad de TurboWan + continuidad de video largo de SVI + estilo, todo en una sola pasada de inferencia.
El flujo de inferencia completo es sencillo: codificar la referencia en un latente de ancla, concatenarlo con el latente de movimiento del clip anterior y el relleno, ejecutar la eliminación de ruido de TurboWan, decodificar, añadir y actualizar el latente de movimiento desde el final del clip recién generado. Tras N iteraciones, se concatena todo en un solo video.
1. Codificar imagen de referencia → latente de ancla. 2. y = concat(latente de ancla, latente de movimiento, relleno). 3. Ejecutar eliminación de ruido de 5 pasos de TurboWan condicionada a y y al embedding de texto. 4. Decodificar el clip mediante VAE y añadir a la lista de salida. 5. Establecer el latente de movimiento = final (últimos num_motion_frames) del clip recién generado. 6. Repetir para N clips, luego concatenarlos todos.
Algunas cifras de producción
Prueba estándar: una sola imagen de referencia y 3 prompts, generando ~15s de salida (3 clips × 5s):
| Métrica | Valor |
|---|---|
| Duración generada | 15s (3 clips) |
| Tiempo de inferencia por clip | ~14s (TurboWan fp8, una GPU) |
| Tiempo de inferencia total | ~42s |
| Consistencia del sujeto | Buena |
Un ejemplo práctico: Aventura gatuna
Para hacer concreto el comportamiento entre clips, ejecutamos un caso de 15 segundos con una referencia y tres tomas. El prompt de estilo fijó un look tipo Pixar con iluminación cálida; el personaje era un gatito atigrado naranja con ojos curiosos; las tres tomas lo llevaron del alféizar de una ventana a la acera, y luego a conocer a un golden retriever, cada una con su propia dirección de cámara.

Clip 1 (0–5s): el gatito naranja tipo Pixar en un alféizar, con la cámara alejándose lentamente de un primer plano. El estilo y el personaje se mantienen estables entre fotogramas.

Clip 2 (5–10s) en el límite de transición: la apariencia del gatito coincide con el Clip 1, luego gira y cambia de postura al saltar. El latente de movimiento ha trasladado el estado de movimiento a través del límite.

Clip 3 (10–15s): se introduce un golden retriever y la escena transita hacia un límite interior/exterior. El estilo Pixar del gatito permanece estable en los tres clips.
Métricas agregadas para la ejecución:
| Métrica | Valor |
|---|---|
| Duración total | 15s (3 clips × 5s) |
| Fotogramas totales | 240 fotogramas (16fps) |
| Tiempo de inferencia total | 33s (TurboWan, una GPU) |
| Ratio tiempo-a-video | 2.2 s/s |
| Consistencia del sujeto | Gatito naranja Pixar estable todo el tiempo |
| Discontinuidad en límites | Sin cortes bruscos evidentes |
Eso es un video de 15 segundos en 33 segundos usando una sola GPU, con consistencia del sujeto entre clips, muy por debajo de los ≤ 60s de espera que fijamos como objetivo. En un conjunto de pruebas interno de 14 casos, 9 regresaron sin problemas evidentes (tasa de éxito del 64%).
La conclusión honesta es que en la generación de video, la velocidad, la duración y la calidad son tres vértices de un triángulo de hierro. Ningún enfoque actual






