
MiniMax acaba de lanzar un adelanto sobre una aceleración de 15.6× en la decodificación para 1M de tokens. Si esa cifra se mantiene, el coste de ejecutar contextos de un millón de tokens se reduciría casi en un orden de magnitud, logrando al mismo tiempo que la generación sea más rápida, no más lenta.
Para cualquiera que desarrolle sobre estos modelos, esto cambia por completo lo que es rentable. Cargas de trabajo que hoy no salen a cuenta empiezan a ser viables: entregar a un agente de programación tu base de código completa en lugar de fragmentos, ejecuciones de agentes de varias horas que acumulan historiales enormes o búsquedas de recuperación sobre conjuntos de documentos completos en lugar de fragmentos troceados. La pregunta con la que lidia todo equipo —¿cuánta información puedo meter en la ventana de contexto antes de que la factura o la latencia destruyan el producto?— tiene ahora un techo mucho más alto.
El mecanismo es la atención dispersa (sparse attention), y MiniMax no está solo. DeepSeek la implementó en tres líneas de modelos, Qwen tiene su propia versión y ahora MiniMax. La tendencia está clara. Lo que cambia son las consecuencias: cuando todos los modelos de vanguardia pueden ejecutar contextos largos a bajo coste, el modelo deja de ser la ventaja competitiva (moat) —y ese es el punto que merece tu atención, al que volveremos al final.
Dos advertencias honestas primero, porque importan a cualquiera que pretenda implementar esto:
- Estas son las cifras de la propia MiniMax, sacadas de un único diagrama de adelanto de un modelo no lanzado, sobre su propia configuración. Es una señal clara de la dirección, no un benchmark de terceros. Considéralas como "lo que MiniMax afirma" y vuelve a probarlo con tu carga de trabajo cuando los pesos estén disponibles.
- M3 aún no es público. Esperamos llevarlo a Atlas Cloud con acceso desde el primer día (day-zero access) en cuanto se lance; hablaremos más de esto al final.
Entonces, ¿cómo lo está logrando MiniMax? El 26 de mayo, el líder de I+D de MiniMax, Skyler Miao, publicó un diagrama en X —con una paleta sobria pero denso en información— titulado MiniMax Sparse Attention, con dos curvas que contienen las cifras que captaron la atención de todos: 9.7× más rápido en prefill, 15.6× más rápido en decodificación con 1M de tokens. La comunidad lo interpretó de forma prácticamente unánime como el adelanto de M3. Lo analizamos para entender la arquitectura detrás de esas cifras.
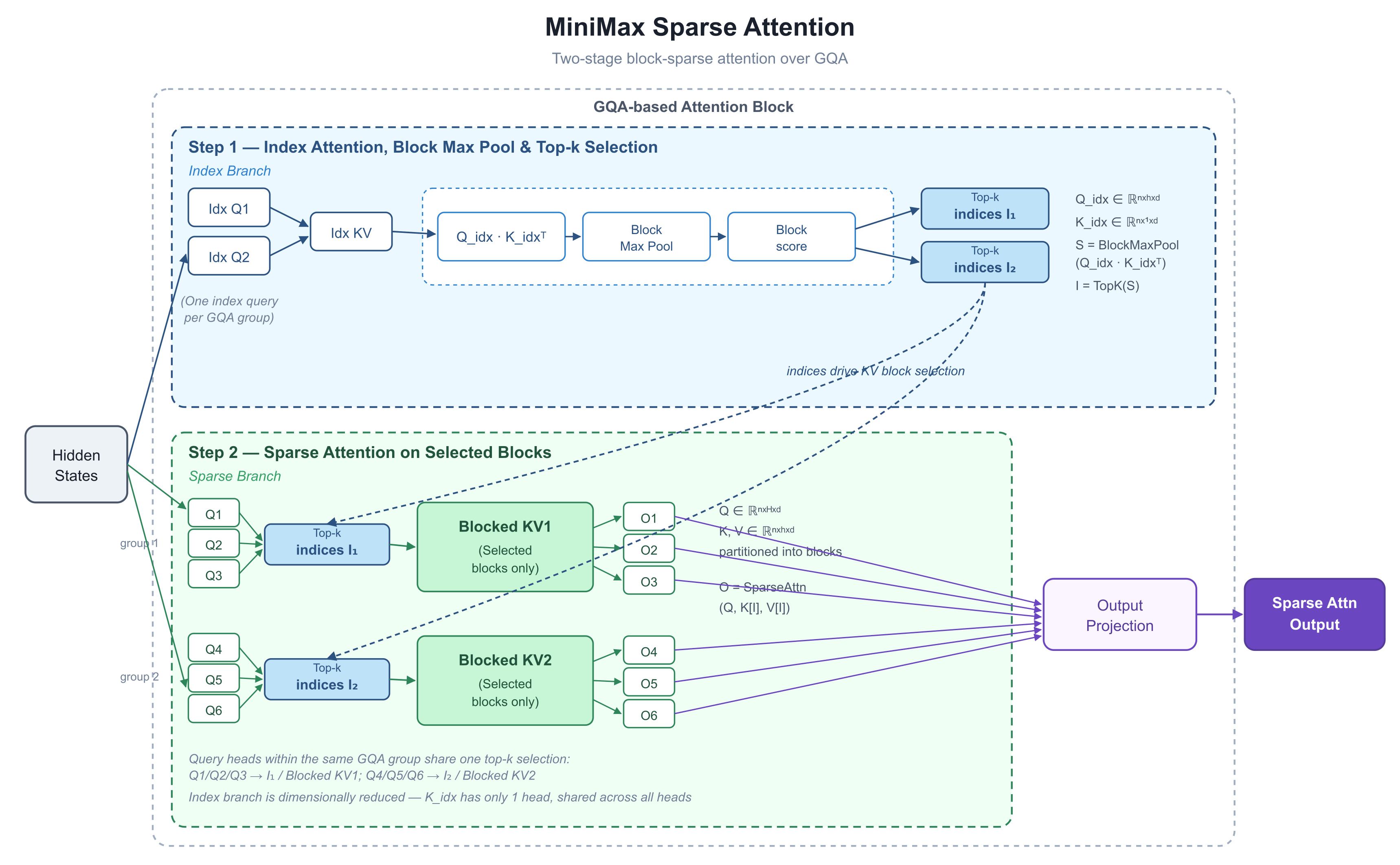
Un poco de contexto técnico antes del análisis. Tres términos explican toda la historia:
- Prefill es la pasada donde el modelo lee tu entrada de una sola vez.
- Decode es la fase más lenta, token por token, donde escribe la salida —y en contextos largos, la decodificación es lo que más penaliza, porque cada nuevo token debe mirar todo lo anterior.
- Atención dispersa es la solución: en lugar de que cada token atienda a todos los demás (la opción predeterminada, cuyo coste crece con el cuadrado de la longitud de la secuencia), el modelo atiende a un subconjunto cuidadosamente elegido, manteniendo la mayor parte de la calidad por una fracción del cómputo. La forma en que se elige ese subconjunto es lo que diferencia a cada laboratorio.
Y la razón por la que este adelanto tiene peso: en octubre, MiniMax publicó una entrada titulada ¿Por qué M2 terminó siendo un modelo de atención completa? —inusualmente directa, explicando que M2 omitió la "Lightning Attention" eficiente de M1 porque no estaba lista para producción. Seis meses después, M3 aparece con la atención dispersa como protagonista. El subtexto es una frase: esta vez, sí lo está.
1. Lo que muestra el diagrama: dos etapas, elige antes de computar
El diagrama es el despliegue interno de un solo bloque de atención. Su movimiento clave es separar "a qué tokens mirar" de "cómo computar la atención sobre ellos" en dos pasos claramente diferenciados.
Una nota sobre el sustrato: M3 está construido sobre GQA — Grouped-Query Attention (atención de consulta agrupada). En una capa de atención estándar, cada "cabezal de consulta" (query head) lleva su propio conjunto de claves y valores, lo cual es expresivo pero infla la memoria caché KV (la caché de claves y valores de todos los tokens previos, necesaria para no recalcularlos en cada paso). GQA divide los cabezales de consulta en grupos, y cada grupo comparte un conjunto de claves y valores. Es el diseño estándar para ahorrar memoria usado en la mayoría de los modelos de producción actuales. Quédate con esto: es la base de todo el diseño.
Paso 1: Rama de índice — puntúa todo de forma barata
La mitad superior es la rama de índice. Corre lateralmente a la ruta principal con una tarea: decirle al resto del bloque qué bloques de tokens merecen ser observados.
Cada grupo GQA comparte una consulta de índice (el diagrama muestra seis cabezales reales emparejados con dos consultas de índice, "Idx Q", una por grupo). El lado de las claves de esta rama está deliberadamente simplificado:

Nota que K_idx solo tiene un cabezal: todos los cabezales comparten la misma clave de índice. Eso hace que el paso de puntuación (Q_idx · K_idxᵀ) casi no tenga coste.
Block Max Pool comprime entonces esas puntuaciones a nivel de token en puntuaciones a nivel de bloque (divide la secuencia en bloques de tamaño fijo y conserva la puntuación más alta en cada uno):

Finalmente, TopK —"conservar los k elementos con mayor puntuación"— decide qué bloques KV sobreviven para esta capa y este grupo. El resultado es una lista corta de índices: I₁, I₂.
Paso 2: Rama dispersa — donde realmente corre la atención
La mitad inferior es la computación real. Las consultas, claves y valores siguen en formato GQA estándar. Usando I₁ y I₂ del Paso 1, el bloque extrae solo los subconjuntos seleccionados de las claves y valores completos, y ejecuta la atención solo sobre ellos:

La elección de diseño más importante: cada cabezal de consulta en un grupo comparte una única selección top-k. En el diagrama, Q1/Q2/Q3 usan I₁; Q4/Q5/Q6 usan I₂. Este es el principio de alineación de hardware en el que insiste el paper de NSA de DeepSeek: un grupo de consultas carga un conjunto de bloques KV, ese conjunto cabe en SRAM (la memoria interna del chip de la GPU, extremadamente rápida) en una sola pasada, y los kernels estándar tipo FlashAttention (la implementación dominante de atención optimizada) pueden reutilizarse sin cambios.
2. Tres sustracciones deliberadas respecto a la familia DeepSeek
La comunidad comparó esto de inmediato con los tres diseños de atención dispersa de DeepSeek:
- NSA — Native Sparse Attention. "Nativa" significa que la dispersión se entrena desde el inicio del preentrenamiento. Tres ramas paralelas (compresión + selección + ventana deslizante) más una puerta aprendida.
- DSA — DeepSeek Sparse Attention. La variante implementada en DeepSeek V3.2; selección a nivel de token con un indexador muy ligero.
- CSA — abreviatura comunitaria para la dirección a nivel de bloque asociada con DeepSeek V4.
La lectura rápida de la comunidad: M3 usa GQA en lugar de MLA, selección a nivel de bloque al estilo CSA, pero computa la atención sobre las claves y valores reales.
Resumido en una tabla:
| Dimensión | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (inferido) |
|---|---|---|---|---|
| Sustrato KV | MLA (latente) | GQA | MLA | GQA |
| Granularidad de selección | a nivel de token | a nivel de bloque | a nivel de bloque | a nivel de bloque |
| Ramas paralelas | 1 (indexador + selección) | 3 (compresión + sel + deslizante) | 1 | 1 (solo selección) |
| Donde corre la atención | K/V reales | fusión triple | KV comprimido | K/V reales |
| Coste del indexador | Indexador Lightning | rama de compresión | resúmenes de bloque | K de un cabezal + Max Pool |
| Puerta (Gating) | ninguna | puerta aprendida | ninguna | ninguna |
Esa tabla oculta un acrónimo importante: MLA — Multi-head Latent Attention, el truco distintivo de DeepSeek. En lugar de cachear claves y valores completos, MLA los comprime en un pequeño vector "latente" compartido, lo cachea y descomprime sobre la marcha. La caché KV se reduce drásticamente, pero las matemáticas ya no coinciden con la atención estándar, por lo que necesita kernels personalizados. Ese contraste impulsa la primera de las tres compensaciones de M3.
Primera sustracción: GQA como sustrato, no MLA. Dado que M3 permanece en GQA simple, el stack de servicio estándar —vLLM y SGLang (los servidores de inferencia de código abierto más utilizados) más FlashAttention— funciona con poca o ninguna modificación. No requiere la ingeniería necesaria para trabajar con la caché KV latente de MLA. Para un laboratorio que busca ser "listo para producción", es el camino de menor riesgo. Esta es la idea más legible desde el punto de vista empresarial en todo el diseño: MiniMax optimizó para lo que funciona inmediatamente en el hardware y software que todos ya tienen.
Segunda sustracción: selección a nivel de bloque, pero la atención corre sobre las claves y valores reales. A diferencia de CSA, que computa la atención sobre KV comprimido, M3 mantiene todo el poder expresivo de la atención softmax estándar. El coste: la caché KV no se reduce junto con la dispersión, pero intercambiar algo de memoria por calidad preservada es un trato razonable.
Tercera sustracción: las otras dos ramas de NSA han desaparecido. NSA ejecuta tres rutas paralelas más una puerta aprendida. M3 solo mantiene la selección. Es, en esencia, una NSA simplificada. En una frase: ingeniería primero. De las dos ramas eliminadas, lo más probable es que la ventana deslizante haya sido reemplazada por RoPE (Rotary Position Embedding) más un "attention sink", o simplemente por atención densa como respaldo por capa, tal como hacen Gemma 3 y Qwen3-Next. La rama de compresión se absorbe en ese "K de un cabezal + Block Max Pool" minimalista.
3. Cómo leer las cifras
| Etapa | Aceleración @ 1M | Qué significa |
|---|---|---|
| Prefill | 9.7× | Procesa 1M de tokens de entrada en una pasada |
| Decode | 15.6× | Genera token por token |
Que la decodificación supere al prefill tiene sentido. Durante el prefill, la rama de índice aún debe escanear la longitud total de la entrada, por lo que el ahorro solo afecta a la atención principal. Durante la decodificación, cada nuevo token interactúa solo con sus bloques KV seleccionados, y la presión sobre el ancho de banda de la memoria de la caché KV cae en un orden de magnitud —que es exactamente donde reside el coste en tiempo de decodificación.
Extrapolando la tasa de selección: asumiendo un tamaño de bloque de 64 tokens, 1M de tokens equivalen a ~16,000 bloques. Una aceleración de 15.6× en decodificación implica que cada consulta toca solo alrededor del 6–7% de los bloques; un campo receptivo efectivo de unos 60k–70k tokens. Esa proporción se sitúa casi exactamente en la tasa de dispersión que reporta el paper de NSA (6–10%). No es coincidencia: es el punto dulce para este tipo de diseño a escala de 1M.
4. Inferir el resto de M3
Extrapolando este bloque de atención al modelo completo:
- El backbone MoE probablemente se mantenga.MoE — Mixture of Experts — es el backbone del modelo (independiente de la atención): en lugar de enrutar cada token a través de una red gigante, un router envía cada token a unas pocas sub-redes "expertas" especializadas, obteniendo la calidad de un modelo grande con el cómputo activo de uno pequeño. M2 se lanzó con 230B de parámetros totales / ~10B activos / enrutamiento Top-2; M2.7 ya llevó el conteo de expertos a 256. No hay razón para que M3 abandone esto; el cambio probable es que sea más profundo y ancho.
- El stack de atención completa es reemplazado por GQA con dispersión por bloques. Es poco probable que la Lightning Attention de M1 regrese. M3 apuesta por la ruta de "expresividad softmax + selección de bloques top-k": coste sub-cuadrático preservando la calidad.
- Lo más probable es que sea dispersión entrenada de forma nativa. Esta es la lección central del paper de NSA: el patrón disperso debe entrar en los gradientes durante el preentrenamiento. MiniMax tiene su propia línea de investigación sobre cabezales de recuperación, así que deberían evitar ese error.
- El campo de batalla son contextos de 1M+. M1 fue entrenado en 1M y extrapolado a 4M en inferencia. M3 parece preparado para fijar eso mientras reduce drásticamente el coste de inferencia: una cadencia de producto muy natural.
5. Ubicando a M3 en el espacio de diseño de 2026
Entre 2025 y 2026, los diseños de atención dispersa han divergido rápidamente:
- DeepSeek V3.2 DSA: MLA + top-k a nivel de token, indexador muy ligero; calidad más estable, pero ingeniería de kernels compleja.
- DeepSeek NSA: GQA, tres ramas + puerta; techo de calidad más alto, más complejo de implementar.
- Qwen3-Next: mezcla por capas de atención densa y lineal; robusto pero relativamente conservador.
- MiniMax M3: GQA + selección de bloques de una sola rama; minimalista, aprovechando la tendencia del hardware.
El subtexto del diseño de M3 es inequívoco: no persigas la atención teóricamente óptima, persigue la que funciona inmediatamente, funciona rápido y permite reutilizar los kernels existentes. Es coherente con la decisión de volver a la atención completa en M2: estabilizar la calidad con métodos estándar primero, luego reemplazar limpiamente una vez que la tecnología sea verdaderamente madura.
6. Lo que esto significa si estás creando la próxima ola de aplicaciones IA
Da un paso atrás de la arquitectura y verás un patrón mayor. Todos los laboratorios serios están lanzando versiones de atención dispersa entrenada de forma nativa. La dirección está clara y la consecuencia es directa: cuando cada modelo de vanguardia puede ejecutar contextos largos de forma barata, el modelo en sí deja de ser la ventaja competitiva. El coste de inferencia bruta se comprime hacia la comoditización. La diferenciación se mueve un nivel hacia arriba: qué modelo ejecutas para qué carga de trabajo, cómo enrutas entre ellos y qué tan rápido adoptas el siguiente cuando llega seis semanas después.
Ese es un problema más difícil que "encontrar el endpoint más barato". Un equipo que gestiona una aplicación de producción equilibra cuatro cosas a la vez —calidad, latencia, coste y el resultado de negocio que la función impulsa— y la respuesta correcta difiere según la carga de trabajo y cambia en cada ciclo de lanzamiento.
Elegir el modelo más barato ya no es una estrategia ganadora para los desarrolladores. En cambio, lo serán aquellos que construyeron sobre una capa que les permite elegir, enrutar e intercambiar modelos sin tener que reintegrar cada vez que la frontera se mueve, y que dedican su presupuesto de ingeniería a su propio producto en lugar de perseguir notas de lanzamiento cada pocas semanas.
Esa es la capa en la que opera Atlas Cloud: una API sobre más de 300 modelos que abarcan LLM, vídeo, imagen y audio, con enrutamiento inteligente y acceso desde el primer día a nuevos lanzamientos. La misma lente que usamos para analizar este diagrama es la que usamos para decidir qué integrar y cómo enrutarlo. M3 aún no es público; cuando se abra, esperamos llevarlo a Atlas con acceso desde el primer día, para que los equipos que ya construyen sobre nosotros puedan ponerlo frente a sus usuarios el día que se lanza, no un trimestre después.
Reflexiones finales
Muchas cosas no pueden confirmarse desde un solo diagrama: si el patrón disperso se mezcla capa por capa, si hay un respaldo denso, si la rama de índice comparte embeddings con la red principal, cómo se formula la pérdida de la rama de índice, etc. Todo eso espera el paper oficial o los pesos.
Pero una cosa ya está resuelta: siguiendo a DeepSeek, otro laboratorio importante ha ensamblado atención dispersa + contexto largo + pesos abiertos en un stack funcional. En la segunda mitad de 2026, 1M de contexto en código abierto probablemente pasará de ser un punto de venta a ser la base, y eso, por sí solo, importa más que cualquier benchmark individual.
Referencias
- Skyler Miao (Líder de I+D de MiniMax), publicación original en X: Something BIG is coming — https://x.com/SkylerMiao7/status/2059285750458544561
- Resumen de la comunidad: MiniMax details its M3 sparse attention architecture — https://digg.com/ai/78gnmbpg
- Blog de MiniMax: Why Did M2 End Up as a Full Attention Model? — https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model
- Paper de DeepSeek NSA: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention — https://arxiv.org/pdf/2502.11089
- Análisis de DeepSeek V3.2 DSA: Architectural Efficiency in LLMs: DeepSeek-V3.2-Exp and DSA — https://gregrobison.medium.com/architectural-efficiency-in-large-language-models-a-comprehensive-analysis-of-deepseek-v3-2-exp-e9802adfcdbd
- Sebastian Raschka: A Technical Tour of the DeepSeek Models from V3 to V3.2 — https://magazine.sebastianraschka.com/p/technical-deepseek
- Reporte técnico de MiniMax-01: Scaling Foundation Models with Lightning Attention — https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf






