
Google Nano Banana 2 Lite (conocido como el endpoint de API gemini-3.1-flash-lite-image) es una herramienta de IA pequeña y rápida, diseñada para configuraciones de aplicaciones ágiles. Es la API de imágenes de Google más asequible del mercado. Convierte texto en imágenes en solo 4 segundos, por lo que es ideal para aplicaciones empresariales de gran escala que necesitan procesar enormes volúmenes de imágenes rápidamente.

Esperar a que se procesen cientos de colas de generación de imágenes es un cuello de botella agotador para los desarrolladores que crean aplicaciones de alta concurrencia. Cuando tu plataforma necesita renderizar dinámicamente miles de variaciones de anuncios localizados, avatares de usuario o prototipos web al instante, depender de modelos creativos premium dispara rápidamente los costes de producción y perjudica la experiencia del usuario. La alta latencia y las elevadas tarifas por imagen a menudo obligan a los equipos de desarrollo a elegir entre la velocidad de la aplicación y su presupuesto operativo mensual.
Google aborda esta fricción con la última incorporación a su línea de modelos creativos. Al segmentar los niveles de rendimiento según las demandas específicas de carga de trabajo, los desarrolladores ahora pueden optimizar los flujos de trabajo de activos de alta velocidad sin pagar un extra por capacidades de renderizado innecesarias. La solución es un modelo de generación de imágenes ligero y especializado, diseñado directamente para despliegues programáticos rápidos.
Satisfacer la demanda de la API de imágenes de Google más barata
Para los equipos de ingeniería que ejecutan flujos de trabajo visuales de alto volumen, las API tradicionales de generación de imágenes presentan un desafío fiscal importante. Pagar varios centavos por imagen se vuelve insostenible al escalar a millones de llamadas a la API. Este obstáculo económico ha intensificado la demanda de una API de imágenes de Google realmente barata, capaz de gestionar solicitudes masivas sin añadir una infraestructura compleja.
El lanzamiento del modelo gemini-3.1-flash-lite-image cambia la arquitectura de la generación programática de imágenes al establecer una nueva base económica. En lugar de tratar cada solicitud visual como un activo artístico premium, esta arquitectura trata la generación de imágenes de alta velocidad como un servicio básico. Esto permite a los ingenieros de software integrar la creación de imágenes fluida y en tiempo real directamente en aplicaciones multiinquilino y software social interactivo donde la eficiencia de costes es el principal indicador operativo.
Análisis profundo del rendimiento de Nano Banana 2 Lite
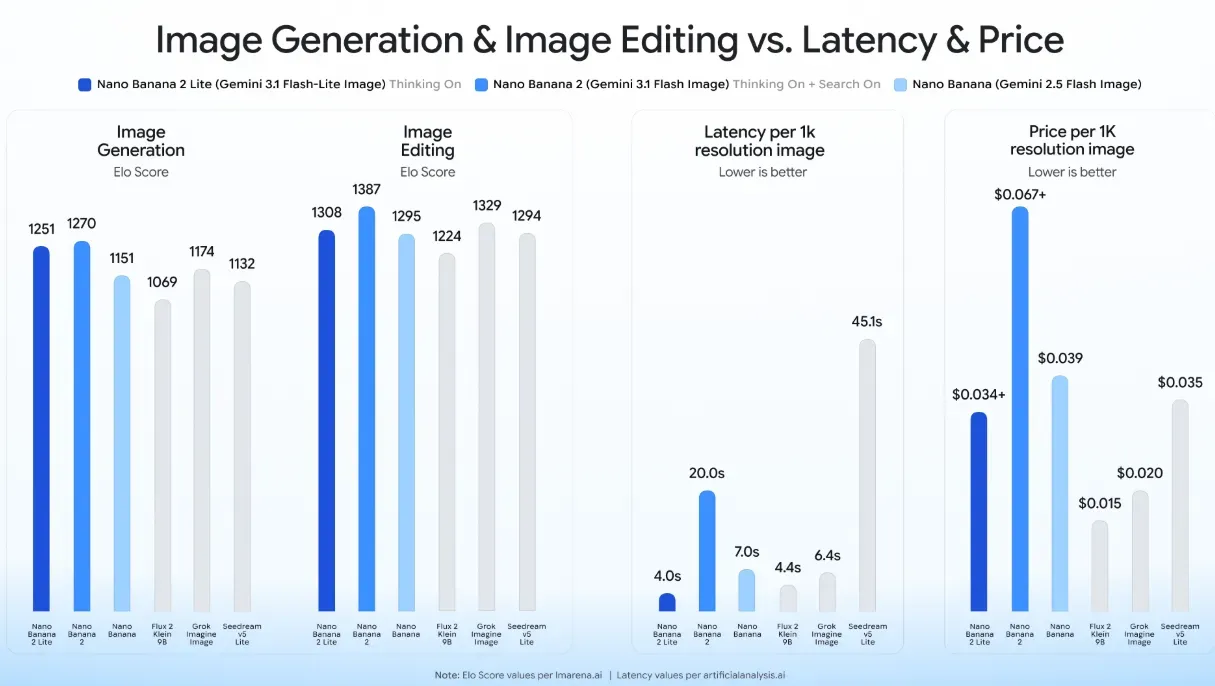
La denominación comercial de este modelo optimizado es Nano Banana 2 Lite. Este modelo está diseñado con un enfoque estricto en maximizar el rendimiento del procesamiento y minimizar la latencia de respuesta. Las pruebas en entornos reales y las especificaciones oficiales confirman que el modelo logra generar imágenes a partir de texto en tan solo 4 segundos. Este tiempo de respuesta rápido representa una mejora de velocidad de aproximadamente 5x respecto a los modelos estándar, transformando el flujo de trabajo del desarrollador de una operación asíncrona basada en colas a una experiencia de usuario síncrona y casi en tiempo real.
Métricas de rendimiento de Nano Banana 2 Lite
| Dimensión de parámetro | Especificación oficial / Métrica | Notas y paradigma operativo |
| Modalidades admitidas | Entrada: Texto, Imagen, Vídeo; Salida: Texto, Imagen | El audio no es compatible; el vídeo es solo de entrada. |
| Límites de contexto | Entrada máx: 65,536 tokens; Salida máx: 4,096 tokens | Optimizado para lógica de aplicaciones de alta frecuencia. |
| Capacidades principales | Generación de imágenes, imágenes/texto intercalados, edición de imágenes, edición multivuelta | No se admite la generación de imágenes desde vídeo. |
| Resolución de salida | Estrictamente 1K (aprox. 1 Megapíxel) | Consume exactamente 1,120 tokens de imagen de salida por cada generación 1K. |
| Relaciones de aspecto | 1:1, 1:4, 4:1, 1:8, 8:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9 | Cubre perfectamente los diseños estándar de comercio electrónico, redes sociales y banners. |
| Restricciones por prompt | Imágenes de entrada máx: 14 por prompt; Imágenes de salida máx: Limitado a 32,768 tokens de salida | El número de archivos está limitado por la ventana de contexto de 65,536 tokens. |
| Coste de tokens multimodal | Imagen de entrada: 1,120 tokens/imagen; Vídeo de entrada: 70 tokens/segundo (muestreado a 1 fps) | Se aplican cargos adicionales por modalidades de entrada y salida de texto. |
| Salvaguardas de concurrencia | Se admite el rendimiento aprovisionado | Crucial para plataformas empresariales para garantizar latencia de 4s bajo carga máxima. |
Las ganancias de rendimiento de Nano Banana 2 Lite sobre los modelos heredados se basan en actualizaciones arquitectónicas sustanciales. En comparación con el antiguo modelo gemini-2.5-flash-image, la nueva variante Lite ofrece avances técnicos específicos:
- Integración de conocimiento global: El modelo muestra una comprensión contextual muy precisa de ubicaciones, estructuras físicas y diseños espaciales abstractos, lo que lo hace altamente efectivo para wireframing de UI/UX rápido.
- Consistencia de personajes: Mantiene identidades de personajes estables y detalles estructurales de objetos en generaciones secuenciales. Esto permite a los ingenieros crear software de guion gráfico iterativo o funciones de prueba virtual para plataformas de comercio electrónico.
- Tipografía y localización en línea: El sistema renderiza texto legible y limpio directamente en los gráficos generados. Esto permite a los desarrolladores construir variantes de anuncios automatizados adaptadas a diferentes mercados geográficos al instante.
Decodificación de precios y mecánica de tokens de la API Nano Banana 2 Lite
| Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Precio estándar (por 1M de tokens, <= 200K entrada) |
| Entrada (texto, imagen, vídeo) | $0.25 |
| Salida de texto (respuesta y razonamiento) | $1.50 |
| Salida de imagen | $30 |
Entender los costes operativos requiere observar la estructura de tokens subyacente en lugar de basarse en promedios de marketing. Aunque la promoción estándar de la industria lista una tarifa plana de aproximadamente $0.034 por cada 1,000 imágenes, la estructura de facturación real de Google se basa en una infraestructura de tokens multimodal precisa. Las tarifas para desarrolladores del nivel de pago para Nano Banana 2 Lite se dividen en mecanismos de transacción distintos.
Bajo el uso del nivel de pago estándar a través de Google AI Studio o la plataforma Gemini Enterprise Agent, las entradas de texto, imagen o vídeo cuestan exactamente $0.25 por millón de tokens. Los tokens de salida de texto y razonamiento estructural se facturan a $1.50 por millón. Al generar una imagen estándar de resolución 1K (~1 megapixel), el sistema procesa una carga útil de salida fija equivalente a $30.00 por millón de tokens de imagen de salida. Esto se traduce directamente en un coste exacto por imagen de $0.0336.
Además, los ingenieros pueden implementar optimizaciones presupuestarias masivas mediante el uso de ejecución por lotes asíncrona. Google ofrece un descuento directo del 50% para solicitudes no urgentes procesadas dentro de una ventana de 24 horas. Esto reduce el coste de una imagen de resolución 1K a unos sorprendentes $0.0168, lo que la convierte en la opción definitiva para la generación de activos en segundo plano.
Comparación arquitectónica lado a lado: La familia de modelos creativos de Google
Para seleccionar el modelo más eficiente para tu stack de producción, es útil contrastar las estructuras de rendimiento y costes en toda la línea de imágenes creativas de Google. Cada variante de modelo apunta a un umbral operativo diferente, lo que requiere que los desarrolladores ajusten sus requisitos específicos al endpoint de la API adecuado.
| Métrica / Característica | Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Gemini 3.1 Flash Image (Nano Banana 2) | Gemini 3 Pro Image (Nano Banana Pro) |
| ID del modelo API | gemini-3.1-flash-lite-image | gemini-3.1-flash-image | gemini-3-pro-image |
| Precio tokens entrada | $0.25 / 1M tokens | $0.50 / 1M tokens | $2.00 / 1M tokens |
| Precio tokens salida imagen | $30.00 / 1M tokens | $60.00 / 1M tokens | $120.00 / 1M tokens |
| Coste imagen 1K est. | $0.03 | $0.07 | $0.13 |
| Coste imagen 1K lote | $0.02 | No disponible | No disponible |
| Latencia promedio | ~4 segundos | ~6–8 segundos | ~10–12 segundos |
| Mayor inconveniente | Límite estricto de resolución 1K; dificultad con párrafos de texto muy densos. | Carece de descuentos por lotes para operaciones intensivas. | Alta latencia y costes de salida elevados limitan su uso en bucles de alta concurrencia. |
| Mejor caso de uso | Flujos de trabajo de alto volumen, interacciones en tiempo real, banners localizados. | Aplicaciones de nivel medio que requieren edición conversacional profunda. | Creación de activos cinemáticos, diseño gráfico complejo, máxima fidelidad de texto. |
Script de integración rápida del SDK para gemini-3.1-flash-lite-image
La integración de la generación de imágenes de Google AI Studio en un flujo de trabajo existente se puede realizar directamente a través del SDK nativo de Google GenAI. El bloque de código a continuación demuestra cómo inicializar el cliente, configurar parámetros programáticos y ejecutar de forma segura una solicitud asíncrona de texto a imagen apuntando al endpoint gemini-3.1-flash-lite-image.
Python
plaintext1import os 2from google import genai 3from google.genai import types 4 5def generate_bulk_asset(prompt_text: str, output_path: str):""" 6 Inicializa el cliente de Google GenAI y ejecuta una solicitud de generación 7 de texto a imagen de baja latencia utilizando el modelo optimizado gemini-3.1-flash-lite-image. 8 """# Inicializar el cliente; espera que la variable de entorno GEMINI_API_KEY esté configurada 9 client = genai.Client() 10 11 print(f"Enviando solicitud de generación para el modelo: gemini-3.1-flash-lite-image") 12 13 try: 14 response = client.models.generate_images( 15 model='gemini-3.1-flash-lite-image', 16 prompt=prompt_text, 17 config=types.GenerateImagesConfig( 18 number_of_images=1, 19 output_mime_type="image/jpeg", 20 aspect_ratio="1:1", # Acepta relaciones de aspecto estándar como 1:1, 16:9, 4:3 21 person_generation="ALLOW_ADULT" 22 ) 23 ) 24 25 # Procesar y guardar el payload de la imagen generadafor i, generated_image in enumerate(response.generated_images): 26 image_bytes = generated_image.image.image_bytes 27 full_path = f"{output_path}_asset_{i}.jpg"with open(full_path, "wb") as f: 28 f.write(image_bytes) 29 print(f"Activo de imagen 1K guardado exitosamente en {full_path}") 30 31 except Exception as e: 32 print(f"Falló la ejecución de la API: {str(e)}") 33 34if __name__ == "__main__": 35 prompt = "Un mockup profesional de un robot compañero de escritorio elegante en una mesa de oficina, iluminación limpia" 36 generate_bulk_asset(prompt, "output_production")
Al desplegar este script a escala, las capas de seguridad y cumplimiento son gestionadas automáticamente por la infraestructura. Google incorpora marcas de agua imperceptibles SynthID y credenciales de contenido C2PA estructural directamente en los metadatos de cada imagen de salida de forma predeterminada. Esto garantiza que todos los activos generados programáticamente a través de tu flujo de trabajo permanezcan completamente rastreables y cumplan con los estándares empresariales sin necesidad de scripts de posprocesamiento personalizados.
Preparación para el futuro de tu stack de producción con capas de API unificadas
Si bien llamar al SDK nativo de Google funciona perfectamente en entornos aislados, escalar este flujo de trabajo de texto a imagen en aplicaciones empresariales multiinquilino a menudo requiere una capa de gestión de API unificada.
Plataformas de infraestructura y orquestación como Atlas Cloud han descentralizado oficialmente este flujo de trabajo proporcionando vías de integración listas para producción para esta variante de modelo específica. A través del hub Atlas Cloud Nano Banana 2 Lite text to image/edit model, los desarrolladores pueden ahora dirigir sus flujos de trabajo visuales de alta velocidad a través de una infraestructura de API unificada.
Conectarse a través de un hub como Atlas Cloud permite a tu equipo de desarrollo combinar la herramienta de vídeo rápida de 4 segundos de este modelo con opciones de respaldo de otros modelos. También te proporciona un lugar centralizado para estadísticas de uso y facturación simplificada. Esto significa que no tienes que añadir código extra desordenado a tus servidores principales.
Resolución de errores comunes de la API y límites de tasa
Definitivamente te encontrarás con limitaciones de servidor o cliente si expandes tu aplicación para manejar decenas de miles de solicitudes de imágenes a la vez. Gestionar estos cuellos de botella de forma fluida evitará que tu aplicación se bloquee y mantendrá el funcionamiento rápido y sencillo para los usuarios.
Gestión del error 429 Too Many Requests
El error más frecuente durante las ejecuciones ocupadas es el mensaje 429 Too Many Requests. Esto significa que tu aplicación superó los límites de velocidad compartidos asignados a las cuentas de desarrollo regulares de Google AI Studio. Para resolver esto, los desarrolladores deben construir un algoritmo de retroceso exponencial (exponential backoff) con jitter en sus bucles de solicitud, retrasando las llamadas posteriores cuando se detecta un estado 429. Para operaciones empresariales que requieren capacidad garantizada, los ingenieros pueden pasar a acuerdos de rendimiento aprovisionado (PT) dentro de la plataforma Gemini Enterprise Agent, que reserva asignación de hardware dedicada para garantizar un rendimiento constante.
Resolución de errores 400 Invalid Argument y 403 Forbidden
Un error 400 Invalid Argument suele significar que la configuración de tu vídeo tiene tamaños incorrectos o relaciones de aspecto erróneas. El plan Lite es muy estricto y solo permite salidas de vídeo 1K. Asegúrate de que tu relación de aspecto coincida con tamaños regulares como 1:1 o 16:9.
Por el contrario, un error 403 Forbidden significa que hay un problema con la clave API o un bloqueo de seguridad. Google utiliza filtros automáticos para verificar todo el texto. Si tu prompt infringe estas reglas de seguridad, el sistema bloqueará el vídeo. Deberás reescribir el texto para cumplir con las pautas de la plataforma.
Realidades de desarrollo: Integración nativa de flujos de trabajo de imagen con presupuesto
Desplegar un modelo optimizado en presupuesto significa reconocer sus limitaciones prácticas. Debido a que la arquitectura del modelo está ajustada para una velocidad excepcional y un coste bajo, conlleva concesiones explícitas:
- El techo estricto de resolución 1K significa que no puede producir gráficos nativos 4K listos para imprimir.
- Además, cuando se le asignan prompts altamente intrincados que contienen capas estructurales densas, el modelo puede experimentar ocasionalmente inestabilidad en la consistencia de los personajes a través de transiciones de escena ampliamente diferentes.
Para mitigar estos inconvenientes sin inflar tus costes operativos, puedes encadenar tu flujo de trabajo de generación en un proceso de edición de varias vueltas.
En lugar de intentar generar una escena compleja y perfecta en tu primer intento, escribe la lógica de tu aplicación para generar un borrador base rápido de 4 segundos. A partir de ahí, utiliza solicitudes de edición de imagen conversacional para modificar, reiluminar o intercambiar objetos específicos dentro del activo de forma programática.
Para aplicaciones multimedia avanzadas, esta salida de imagen 1K puede introducirse directamente en flujos de trabajo de generación de vídeo como Gemini Omni Flash, que procesa tareas de edición de vídeo a una tarifa asequible de $0.10 por segundo.
¿Es Nano Banana 2 Lite adecuado para tu stack?
Para agilizar tu evaluación arquitectónica, aquí tienes un desglose de qué equipos de desarrollo obtendrán el mayor ROI de Nano Banana 2 Lite (gemini-3.1-flash-lite-image) y quiénes deberían considerar los niveles premium estándar.
¿Para quién es ideal este modelo?
- Desarrolladores de aplicaciones de alta concurrencia: Si tu software maneja miles de solicitudes API automatizadas por minuto, como creadores de avatares de usuario en tiempo real, generadores de anuncios dinámicos instantáneos o sistemas de colocación de productos de comercio electrónico, este modelo está construido específicamente para tus requisitos de carga.
- Ingenieros de software sensibles a los costes: Equipos que apuntan a flujos de trabajo de micro-presupuesto donde mantener bajos los gastos operativos es una métrica de supervivencia principal. Aprovechar su nivel por lotes de $0.0168 elimina efectivamente el cuello de botella fiscal premium estándar.
- Arquitectos de aplicaciones interactivas: Los productos que requieren un bucle síncrono estricto donde los usuarios exigen una respuesta casi en tiempo real se beneficiarán inmensamente de su velocidad de generación inferior a 4 segundos.
¿Quién debería evitar este modelo?
- Diseñadores gráficos de alta fidelidad: Si tu aplicación depende del renderizado de gráficos impresos a gran escala, banners de resolución nativa 4K o materiales de marketing cinemáticos complejos, el límite estricto de resolución 1K limitará tu producción creativa.
- Comercializadores visuales de texto pesado: Aunque el modelo admite tipografía en línea, las aplicaciones que requieren párrafos de diseño densos y complejos incrustados de forma nativa dentro de las imágenes deben utilizar el nivel Gemini 3 Pro Image en su lugar para mantener una fidelidad de texto absoluta.
- Constructores multimedia centrados en audio: Los equipos que construyen bucles multimodales avanzados que dependen en gran medida de la sincronización de audio o la generación de imágenes directamente a partir de flujos de audio en vivo continuos deben buscar en otra parte, ya que el audio no es compatible con este nivel Lite específico.
Preguntas frecuentes (FAQ)
¿Cómo reduce gemini-3.1-flash-lite-image los costes del desarrollador en comparación con los niveles estándar?
El modelo reduce los costes estándar para desarrolladores exactamente en un 50% en comparación con el modelo estándar gemini-3.1-flash-image. Al optimizar la huella de tokens a $0.25 por 1 millón de tokens de entrada y $30.00 por 1 millón de tokens de salida de imagen, el precio de una imagen estándar de resolución 1K cae a $0.0336 en niveles de pago estándar. Para tareas de segundo plano no urgentes, el uso de la API por lotes reduce esta tasa a $0.0168 por imagen.
¿Puede Nano Banana 2 Lite manejar cargas de aplicaciones empresariales de alta concurrencia?
Sí, el modelo está construido específicamente para manejar demandas empresariales de alta concurrencia. Mientras que los niveles de desarrollador estándar comparten un pool de infraestructura común, los equipos empresariales pueden asegurar un rendimiento dedicado y altamente fiable mediante el despliegue de rendimiento aprovisionado a través de la plataforma Gemini Enterprise Agent. Esto evita completamente los límites de tasa compartidos y garantiza una velocidad de generación constante de 4 segundos durante los picos de tráfico.
¿La API de imágenes de Google más barata compromete la seguridad o el seguimiento de contenido?
La optimización de costes no elimina las funciones de seguridad empresariales ni los mecanismos de cumplimiento. Cada imagen generada por el modelo incluye automáticamente una marca de agua nativa SynthID incrustada directamente en la matriz de píxeles, junto con las credenciales de contenido estándar C2PA. Estos metadatos permiten a las plataformas empresariales mantener un seguimiento transparente y verificar completamente la autenticidad de todos los activos generados por IA antes de que lleguen a aplicaciones orientadas al público.






